
In den letzten 18 Monaten hat sich der Fokus beim Bot-Traffic vom Crawling und der Indexierung hin zu dessen Auswirkungen auf die Kernleistung deines Servers, deine Hosting-Kosten und deine Fähigkeit, echte Kunden zu bedienen, verlagert.
Wir wissen das, weil wir mehr als 10 Milliarden Anfragen in der von Kinsta verwalteten Infrastruktur analysiert haben – und was wir dabei festgestellt haben, war keine Geschichte über Angriffe. Es war eine Geschichte über Ressourcen.
„Aus Sicht der Infrastruktur gibt es so etwas wie ‚nur Bot-Traffic‘ nicht“, sagt Daniel Pataki, CTO bei Kinsta. „Jede Anfrage bedeutet echte Arbeit. In großem Maßstab ist ineffizientes Crawling kein Traffic-Problem mehr, sondern wird zu einem Ressourcenproblem.“
Dieser Artikel erklärt, warum dieser Wandel stattgefunden hat, was er WordPress-Seitenbetreiber tatsächlich kostet und wie sich die Sichtweise ändern muss.
Das alte Modell funktioniert nicht mehr
Das traditionelle Bot-Management basierte auf einer einfachen Prämisse: Die bösartigen blockieren und die guten durchlassen. Jahrelang reichte das aus. Googlebot crawlt deine Seiten, indexiert deine Inhalte und macht weiter. Bösartige Bots versuchten, sich Zugang zu deiner Anmeldeseite zu verschaffen. Zwei sehr unterschiedliche Probleme, zwei sehr unterschiedliche Lösungen.
Was keines der beiden Modelle berücksichtigte, war eine dritte Kategorie: automatisierter Traffic, der weder bösartig ist noch blockiert wird, aber in großem Umfang messbaren Schaden an der Leistung deiner Website verursacht.
KI-Crawler – also Bots, die nicht nur dazu dienen, Seiten für Suchergebnisse zu indexieren, sondern auch Inhalte für das Modelltraining, die abrufgestützte Generierung und Echtzeit-Anfragen von Nutzern zu erfassen – arbeiten in einem grundlegend anderen Maßstab als alles, was es bisher gab. Allein GPTBot verzeichnete zwischen Mai 2024 und Mai 2025 ein Wachstum von 305 %. Zu Beginn des Jahres 2025 war etwa jeder 200. Webbesuch ein KI-Bot. Bis zum Jahresende hatte sich dieses Verhältnis auf jeden 31. erhöht.
Ende 2025 machten KI-Crawler 4,2 % aller HTML-Anfragen im Cloudflare-Netzwerk aus – eine Zahl, die von 2,4 % Anfang April auf 6,4 % Ende Juni schwankte und sich innerhalb eines Jahres fast verdreifachte.
Diese Crawler sind hartnäckig und treten häufig auf, und sie verhalten sich nicht wie herkömmliche Suchmaschinen-Bots. Viele generieren große Mengen an Anfragen an nicht zwischengespeicherte, dynamische Endpunkte, was deinem Server „echte Arbeit“ beschert.
Was „echte Arbeit“ für eine WordPress-Seite bedeutet
Hier wird das Infrastrukturproblem deutlich – und genau das geht in den meisten Analysen zum Bot-Traffic unter.
Wenn ein Besucher eine zwischengespeicherte Seite auf einer WordPress-Seite lädt, hat dein Server kaum etwas zu tun. Er gibt eine vorgefertigte HTML-Datei zurück, genauso wie er ein Bild oder eine CSS-Datei ausliefern würde. Der Ursprungsserver merkt davon kaum etwas. Das ist ja gerade der Sinn des Cachings.
Aber ein erheblicher Teil der Anfragen auf einer echten WordPress-Seite und insbesondere in WooCommerce-Shops kann nicht aus dem Cache bedient werden. Zu diesen Anfragen gehören:
- Endpunkte für Warenkorb und Kasse (
?add-to-cart=,/cart,/checkout) - Gefilterte Produktseiten mit URL-Parametern
- Suchanfragen
- AJAX-gestützte Interaktionen (Hinzufügen zur Wunschliste, Live-Preisaktualisierungen, dynamische Popups)
- Sitzungsbasierte Seiten, bei denen der Server einen Benutzerkontext validieren oder erstellen muss
Wenn ein Bot diese Endpunkte aufruft, passiert auf deinem Server Folgendes:
- Ein PHP-Thread wird reserviert. Jede dynamische Anfrage in WordPress belegt einen PHP-Thread für die gesamte Dauer der Verarbeitung, typischerweise 200–500 ms, bei komplexen Seiten auch länger. Dieser Thread steht für keine andere Anfrage zur Verfügung, bis der Vorgang abgeschlossen ist. Dein Hosting-Paket verfügt über eine feste Anzahl davon.
- Deine Datenbank führt eine Abfrage durch. Dynamische Seiten fragen bei jedem einzelnen Laden deine Datenbank ab. Bei normalem Traffic durch menschliche Nutzer ist das überschaubar. Bei anhaltender Bot-Last, die nicht zwischengespeicherte Pfade trifft, führt die Datenbank ständig Abfragen durch. Wenn Bots auf einzigartige URL-Varianten stoßen, die zu keinen Cache-Treffern führen, löst jede einzelne eine eigene Abfragekette aus.
- Es entsteht ein Session-Overhead. Warenkorb- und Checkout-Seiten erstellen oder validieren Sessions sogar für Bots, die niemals konvertieren. Das verursacht bei jeder einzelnen dieser Anfragen zusätzlichen Verarbeitungsaufwand.
- PHP-Threads sind erschöpft. Wenn alle verfügbaren PHP-Threads belegt sind, werden legitime Besucher nicht sofort bedient, sodass ihre Anfragen in eine Warteschlange gelangen. Wenn sich die Warteschlange füllt, kommt es zu langsamen Seitenladungen, ins Stocken geratenen Kaufvorgängen und 504-Fehlern. Für einen echten Kunden, der versucht, einen Kauf abzuschließen, wirkt deine Website defekt.
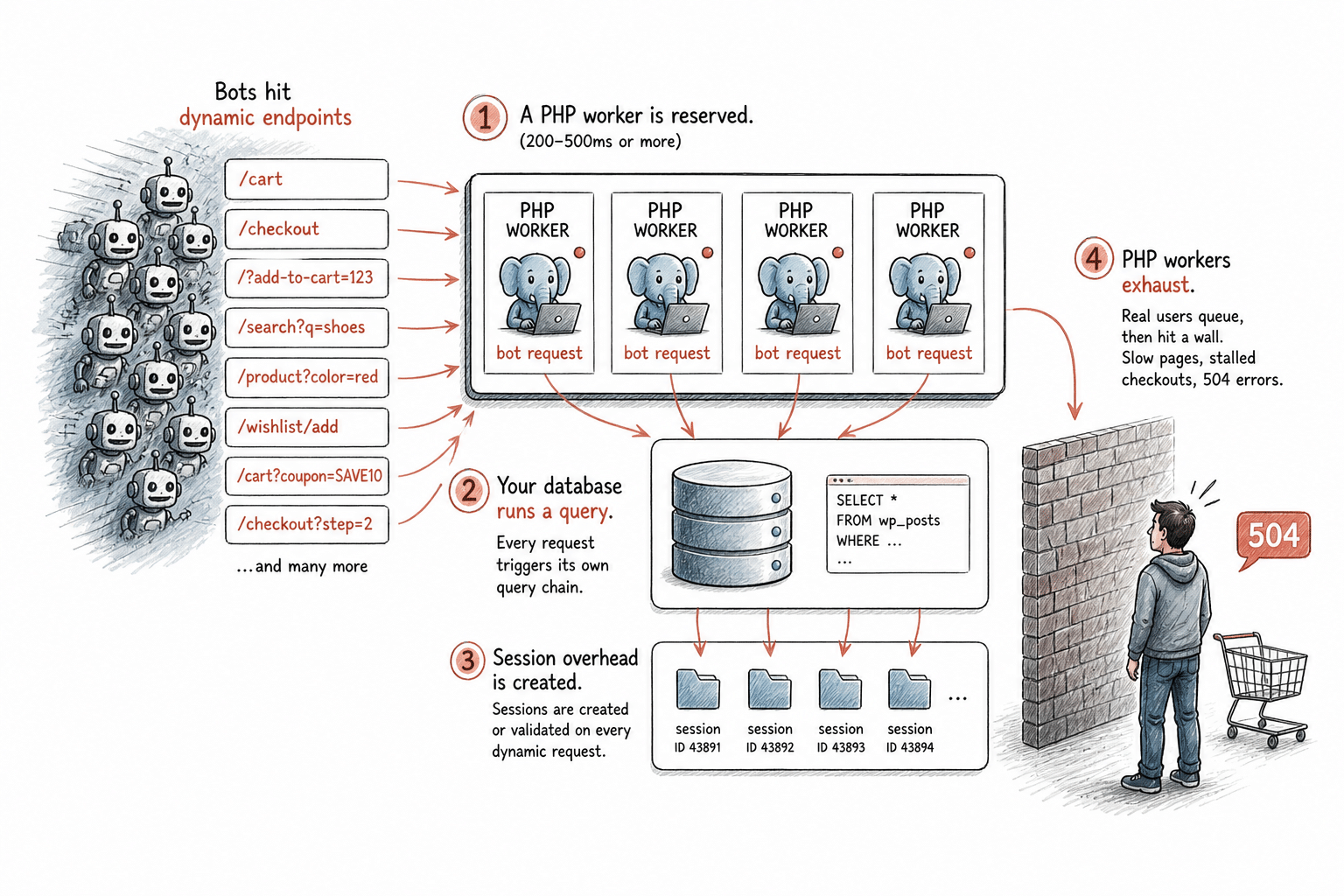
Das ist der Mechanismus, durch den Bot-Traffic zu einem Infrastrukturproblem wird. Das ist keine Theorie. Es ist die konkrete Abfolge von Ereignissen, die eintritt, wenn automatisierte Anfragen dynamische Endpunkte auf einer aktiven WordPress-Seite überfluten.
Was die Infrastrukturdaten von Kinsta tatsächlich zeigen
Das Abstrakte wird konkret, wenn man sich die realen Daten aus der Infrastruktur ansieht, die wir in großem Maßstab verwalten.
Ein Datenpunkt, den wir besonders auffällig fanden, ist, dass ein einzelner Bot (ClaudeBot) innerhalb von 24 Stunden 3,75 Millionen „In den Warenkorb“-Anfragen generierte. Das entspricht etwa einer Anfrage alle 23 Millisekunden (den ganzen Tag und die ganze Nacht), wobei jede vom Server als neue Anfrage behandelt wird, da Warenkorb-Endpunkte von Natur aus dynamisch sind.
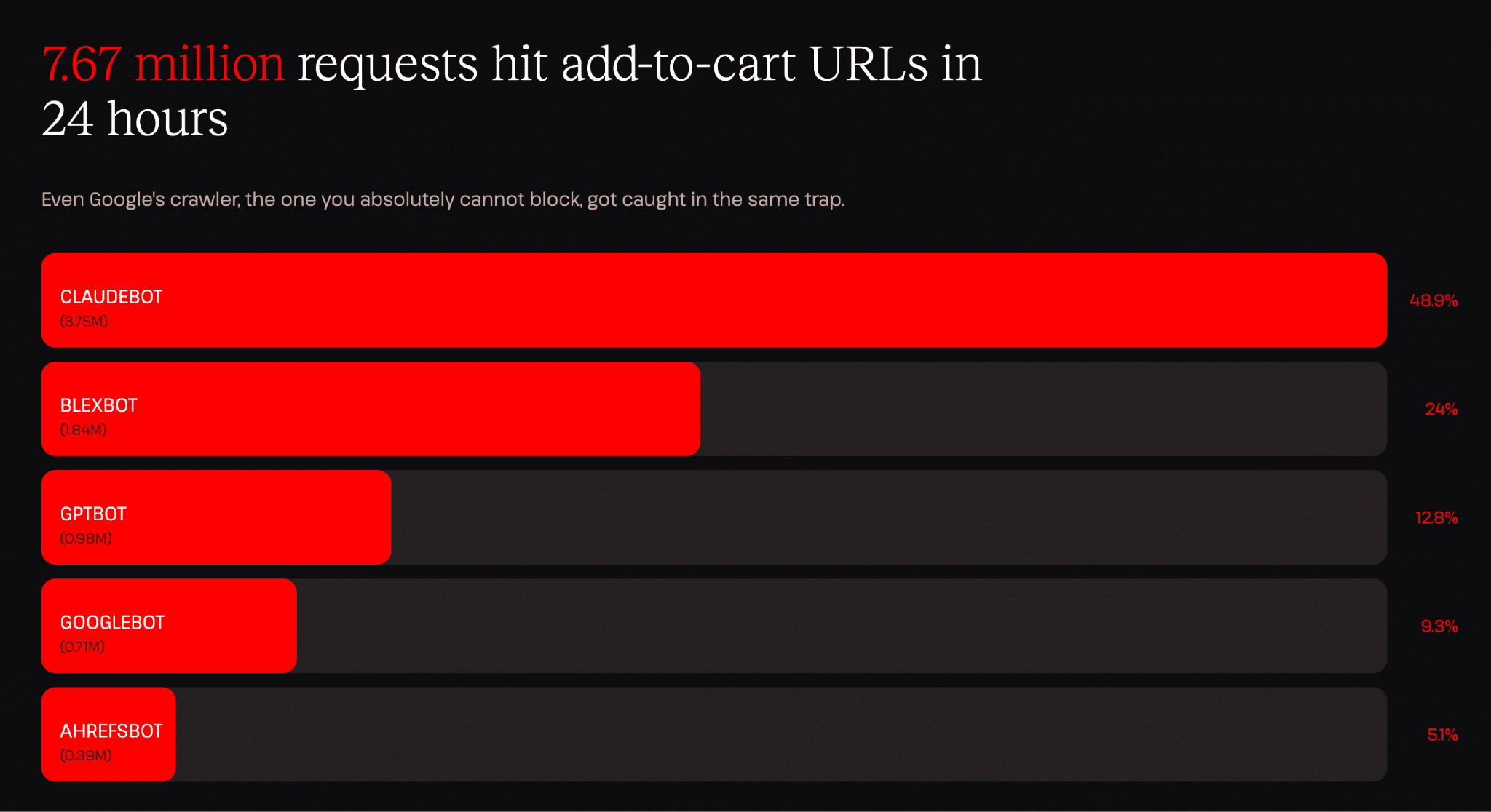
Um das in den Kontext zu setzen: „In den Warenkorb“-Anfragen gehören zu den ressourcenintensivsten Endpunkten eines WooCommerce-Shops. Sie erstellen Sitzungen, führen Abfragen durch und aktualisieren den Warenkorbstatus. Jede einzelne bedeutet echten Arbeitsaufwand. Die 3,75 Millionen Anfragen, die wir an einem Tag von einer einzigen Quelle verzeichneten, sind genau die Art von Traffic-Muster, die eine Website lahmlegen kann.
Ein zweiter Datenpunkt unterstreicht, wie hartnäckig diese Muster sein können: Ein fehlerhaftes Schleifenmuster erzeugte innerhalb von 30 Tagen 550 Millionen Anfragen – genug Traffic, um eine eigene, dedizierte Abwehrregel in unserer Infrastruktur zu rechtfertigen. Das ist kein DDoS-Angriff und keine Malware-Kampagne, sondern ein Bot, der in einer Crawling-Schleife feststeckt und immer wieder URLs abfragt, die er bereits gesehen hat.
Das sind keine Ausnahmefälle. Es sind Muster, die wir plattformweit beobachten.
Das Schleifenproblem: Bots greifen nicht an, sie stecken fest
Einer der am meisten unterschätzten Aspekte des aktuellen Problems mit Bot-Traffic ist, dass das meiste, was Schäden an der Infrastruktur verursacht, überhaupt nicht böswillig ist. Es handelt sich um ineffiziente Automatisierung in großem Maßstab.
Moderne Websites, insbesondere E-Commerce-Shops, generieren leicht unterschiedliche URLs für im Grunde dieselbe Seite:
- Ein Produkt mit einem angehängten Farbfilter
- Eine Warenkorbseite mit einem Session-Token
- Eine Kategorieansicht mit einem Sortierreihenfolge-Parameter
Für einen Menschen sind das alles „dieselbe Seite“. Für einen Bot, der URLs folgt, sieht jede davon wie eine brandneue Seite aus, die gecrawlt werden muss.
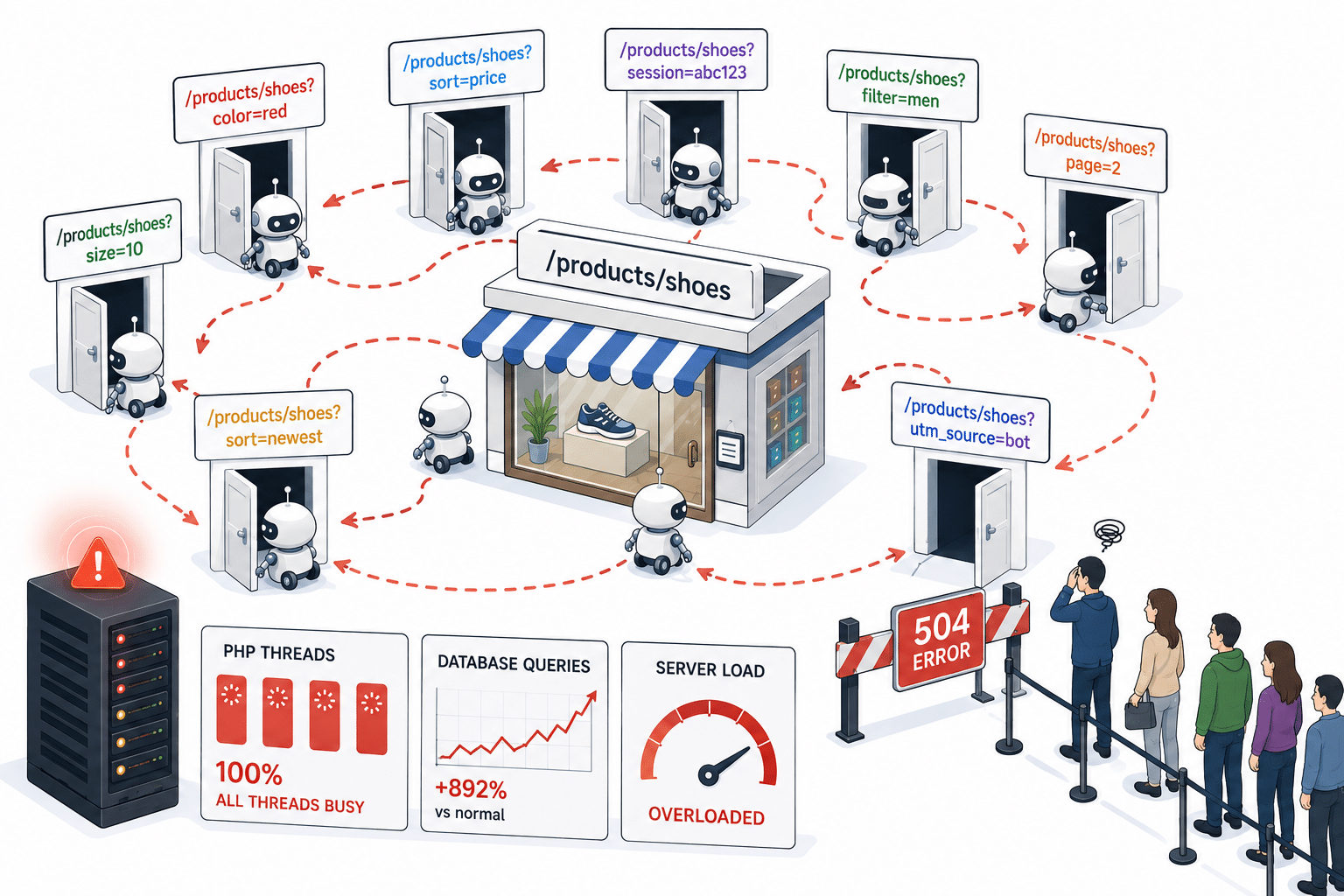
Also folgt der Bot dem ersten Link. Diese Seite generiert eine weitere URL-Variante, der der Bot folgt. Dann noch eine. Und noch eine. Er verfügt über keinen Mechanismus, um zu erkennen, dass er sich im Kreis dreht, und einige dieser Schleifen liefen auf der überwachten Infrastruktur mehrere Tage lang unentdeckt, bevor sie von Abwehrregeln abgefangen wurden.
In dem kürzlich veröffentlichten Bericht zu KI- und Bot-Traffic erklärte David Belson, ehemaliger Leiter des Bereichs Data Insights bei Cloudflare: „Da gibt es jemanden, der gestern noch keine Ahnung hatte, was er da eigentlich tat, aber heute aus einer Laune heraus einen Bot programmiert und losgeschickt hat. Der macht sich nicht einmal die Mühe, robots.txt zu überprüfen.“
Dieses Verhalten geht nicht immer auf böswillige Akteure zurück. Es stammt von KI-Crawler-Systemen, die nicht unter Berücksichtigung von facettierter Navigation, der Ausbreitung von URL-Parametern oder sitzungsgenerierten URLs entwickelt wurden – alles Standardfunktionen moderner WordPress-Seiten.
Google selbst identifiziert facettierte Navigation und parameterbasierte URLs ausdrücklich als Ursache für ineffizientes Crawling und weist darauf hin, dass Bots nahezu unendliche Variationen derselben Seite durchsuchen können.
Deine Serverrechnung ist jetzt ein Problem des Bot-Managements
Bis vor kurzem orientierten sich viele Hosting-Pakete an der Besucherzahl, was als Näherungswert für die tatsächliche Nutzung durch Menschen recht gut funktionierte. Man ging davon aus, dass die Besucherzahlen in etwa mit der Interaktion der Nutzer auf deiner Website korrelierten.
Diese Annahme hat sich nicht mehr bewährt.
Automatisierter Traffic hat die Besucherzahlen in einer Weise in die Höhe getrieben, die mit der tatsächlichen Geschäftstätigkeit kaum noch etwas zu tun hat. Bot-Anfragen können Besucherzahlen generieren, ohne dass es zu entsprechender Interaktion, Konversionen oder Umsatz kommt. Website-Betreiber erhielten bei besuchszahlbasierten Tarifen Überschreitungsbenachrichtigungen, die durch Bot-Aktivitäten verursacht wurden, die sie weder kontrollieren konnten noch selbst eingeladen hatten.
Dies zeigte sich so deutlich als systemisches Muster, dass Kinsta bandbreitenbasierte Hosting-Tarife einführte – als direkte Reaktion auf eine Kategorie von Websites, deren Besuchszahlen sich zunehmend deutlich von ihrem tatsächlichen Ressourcenverbrauch abkoppelten. Wenn die Besucherzahlen einer Website stiegen, die Bandbreite aber nicht Schritt hielt, war das fast immer ein Anzeichen für Bots. Der Wechsel zu einem bandbreitenbasierten Modell entkoppelte die Abrechnung effektiv von einer Kennzahl, die Bots zu manipulieren gelernt hatten.
Das Abrechnungsproblem ist messbar und behebbar. Das schwierigere Problem ist, dass die meisten Website-Betreiber gar nicht merken, dass all das passiert, weil ihre Dashboards nicht das volle Bild zeigen.
Was dir deine Analysedaten sagen (und was nicht)
Eine Folge des Bot-Traffics in dieser Größenordnung ist, dass Standard-Analysetools zu unzuverlässigen Indikatoren für die tatsächliche Leistung deiner Website geworden sind.
Wenn deine Besucherzahlen steigen, sich aber Umsatz, Verweildauer auf der Seite und Absprungverhalten nicht proportional dazu entwickeln, sind Bots wahrscheinlich mit im Spiel. Wenn dein Server Leistungseinbußen aufweist, die nicht mit den Traffic-Spitzen korrelieren, die du aufgrund von Inhalten oder Marketingaktivitäten erwarten würdest, lohnt es sich, den Bot-Traffic zu nicht zwischengespeicherten Endpunkten zu untersuchen.
Kinsta filtert bekannte Bot-User-Agents automatisch aus den Analysen und den Berechnungen zur Planauslastung heraus. Aber automatisierter Traffic, der dem menschlichen Verhalten sehr ähnlich ist, kann dennoch in deinen Metriken auftauchen.
Die Muster, auf die du achten solltest:
- Wiederholte Anfragen an dieselben URL-Typen, insbesondere parameterreiche oder sitzungsbasierte Pfade
- Traffic-Spitzen zu Zeiten, die nicht mit Veröffentlichungen, Werbeaktionen oder saisonalen Aktivitäten zusammenhängen
- Leistungseinbußen des Servers (höhere TTFB-Werte, PHP-Thread-Erschöpfungsfehler) während Phasen mit erhöhtem Traffic, die nicht mit realen Ereignissen zusammenhängen
- Besucherzahlen, die schneller steigen als die Bandbreite, Konversionen oder Engagement-Kennzahlen
Keines dieser Anzeichen ist für sich genommen ausschlaggebend, aber jede Kombination rechtfertigt eine Untersuchung, bevor man die Zahlen dem Geschäftswachstum zuschreibt.
Warum das Problem schwieriger ist, als es aussieht
Der häufigste Reflex beim Anblick von Bot-Traffic-Daten ist, einfach alles zu blockieren. Andere lassen vielleicht alles zu, weil „KI die Zukunft ist“.
Beides funktioniert nicht!
Wahlloses Blockieren bedeutet, dass auch verifizierte Crawler blockiert werden, darunter Googlebot, dessen Crawling-Abdeckung darüber entscheidet, ob deine Inhalte überhaupt in den Suchergebnissen erscheinen. Es bedeutet, KI-Entdeckungs-Bots zu blockieren, die deine Inhalte möglicherweise in dialogorientierten Suchergebnissen, KI-gestützten Empfehlungen oder Antwort-Engines anzeigen. Für einen WooCommerce-Shop oder einen Content-Anbieter sind das erhebliche Vertriebskosten.
Alles durchzulassen bedeutet, Infrastrukturkosten in Kauf zu nehmen, die keinen Ertrag bringen. Und bei den dynamischen Endpunkten, die von Bots besonders stark beansprucht werden, sind diese Kosten nicht marginal. Sie summieren sich und verstärken sich, insbesondere bei anhaltender automatisierter Auslastung.
Die eigentliche Antwort liegt irgendwo dazwischen und erfordert ein Verständnis für die Unterschiede zwischen den Traffic-Kategorien, anstatt alle Bots als eine einzige Klasse zu behandeln.
Wie Cristian Lopez, Chefredakteur bei HostingAdvice, in dem Bericht erklärte: „Das Missverständnis besteht darin, zu glauben, Bot-Traffic sei ein einfaches ‚Blockieren-oder-Zulassen‘-Problem. In Wirklichkeit geht es um Richtlinien, Transparenz und wirtschaftliche Kontrolle.“
Verifizierte Bots, darunter Googlebot, Bing und legitime Überwachungstools, sollten grundsätzlich zugelassen werden, wobei möglicherweise Pfadbeschränkungen für Endpunkte gelten, die keinen Crawling-Wert haben (deine Checkout-Seite trägt nichts zu deinen Suchrankings bei). Unverifizierte Bots ohne identifizierende Informationen oder Zweck erfordern eine genauere Prüfung. KI-Trainings-Crawler, die hohe Anfragemengen an dynamische Endpunkte generieren, stellen eine spezielle Kategorie dar, die je nach Art deiner Website und deinen Prioritäten eine Blockierung oder Ratenbegrenzung rechtfertigen kann.
In unserem Bericht zu KI- und Bot-Traffic haben wir ein interaktives Entscheidungsmodell entwickelt, das den richtigen Ansatz für verschiedene Website-Typen aufzeigt. Das folgende Beispiel zeigt die empfohlene Konfiguration für einen WooCommerce-Shop, bei der der Schwerpunkt auf der Leistung und Stabilität der Website liegt:
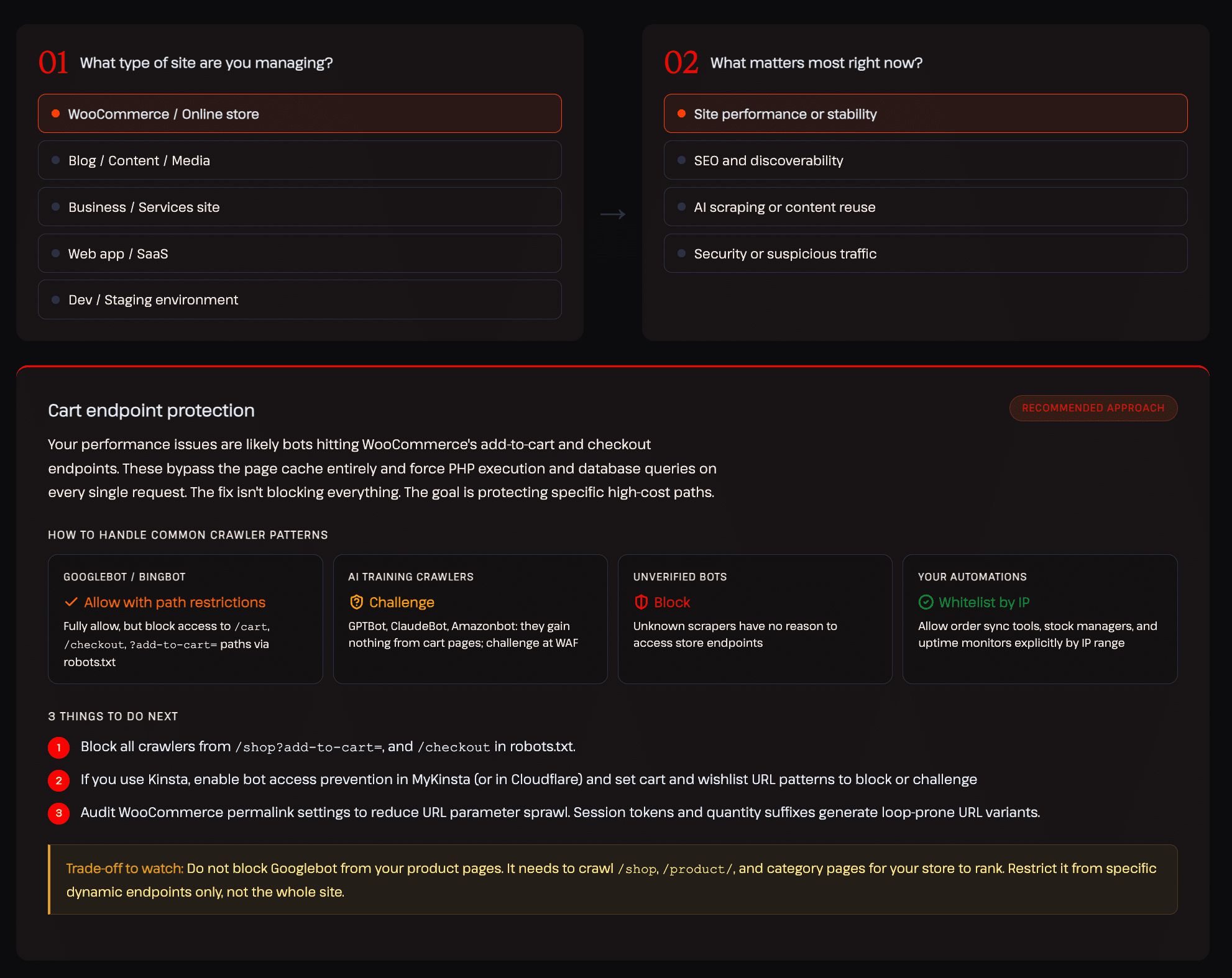
Genau diese differenzierte, kategoriespezifische Kontrolle bieten die meisten bestehenden Tools nicht.
Der Ansatz von Kinsta zum Bot-Schutz
Was wir mit dem Bot-Schutz von Kinsta entwickelt haben, wurde speziell für die oben beschriebenen infrastrukturellen Herausforderungen konzipiert.
Das System klassifiziert den Traffic in Kategorien wie verifizierte Bots, wahrscheinlich Menschen, wahrscheinlich Bots, automatisierter Traffic und böswilliger Traffic und ermöglicht es dir, Schutzstufen festzulegen, die den tatsächlichen Anforderungen deiner Website entsprechen.

Die Stufen sind nicht binär. „Block automations“ zielt auf bestätigten automatisierten Datenverkehr ab, während verifizierte Bots unberührt bleiben. „Challenge bots“ fügt einen Verifizierungsschritt für nicht verifizierte Automatisierungen hinzu, ohne legitime Besucher zu stören. „Challenge everyone“ ist für Zeiten mit akutem Datentrafficdruck verfügbar, bringt aber die zu erwartenden Kompromisse mit sich.
Entscheidend ist, dass das Tool auf Cloudflares Bot-Scoring auf Enterprise-Niveau basiert – einer Echtzeit-Klassifizierung mittels maschinellem Lernen, die jedem Besucher anhand von Verhaltenssignalen und nicht nur anhand von User-Agent-Strings eine Punktzahl von 1 bis 99 zuweist. Das ist wichtig, weil der Abgleich von User-Agents allein zunehmend unwirksam ist, da mittlerweile 12,9 % der KI-Bots „robots.txt“-Anweisungen ignorieren – ein Anstieg von 3,3 % gegenüber dem vorangegangenen Quartal. Die verhaltensbasierte Klassifizierung erfasst das, was User-Agent-basierte Regeln übersehen.
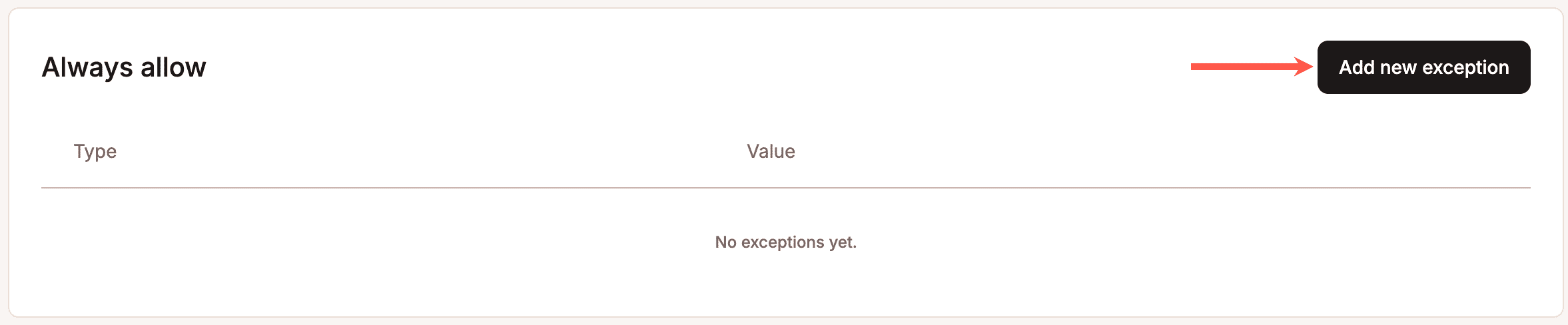
Außerdem gibt es ein „Always Allow“-Ausnahmesystem für vertrauenswürdige Integrationen, Überwachungsdienste und geschäftskritische Automatisierungen, die nicht von den Schutzregeln erfasst werden sollten – denn übermäßiges Blockieren verursacht ebenfalls echte Kosten, insbesondere für WooCommerce-Shops, die auf automatisierte Bestellsynchronisation, Zahlungsgateway-Integrationen oder Verfügbarkeitsüberwachung angewiesen sind.
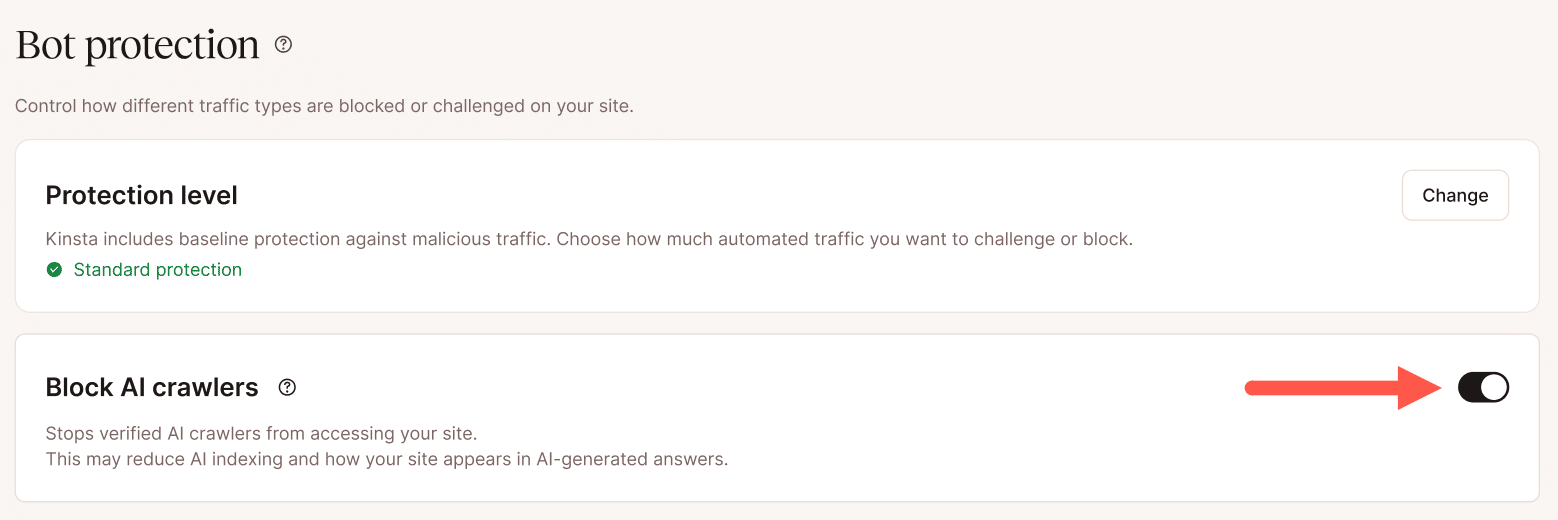
Der Schalter zum Blockieren von KI-Crawlern zielt speziell auf KI-Trainings-Bots ab, ohne Suchmaschinen-Crawler wie Googlebot oder Bingbot zu beeinträchtigen. Für Websites, bei denen KI-Crawler-Aktivitäten als Leistungsfaktor identifiziert wurden, ist dies eine einfache Abhilfemaßnahme, die keine Konfiguration einzelner Regeln erfordert.
Zu wissen, dass es das Tool gibt, ist eine Sache. Zu wissen, wann und wie man es einsetzt, ist eine andere.
Was tun, wenn Bot-Traffic dein Problem ist
Wenn du die oben beschriebenen Muster feststellst, findest du hier einen praktischen Ansatzpunkt, geordnet nach Auswirkung:
Erstens: Überprüfe die Quelle. Nutze die Aufschlüsselung der Anfragen in der Bot-Schutz-Ansicht von MyKinsta, um zu verstehen, wie der Traffic auf deiner Website klassifiziert wird.
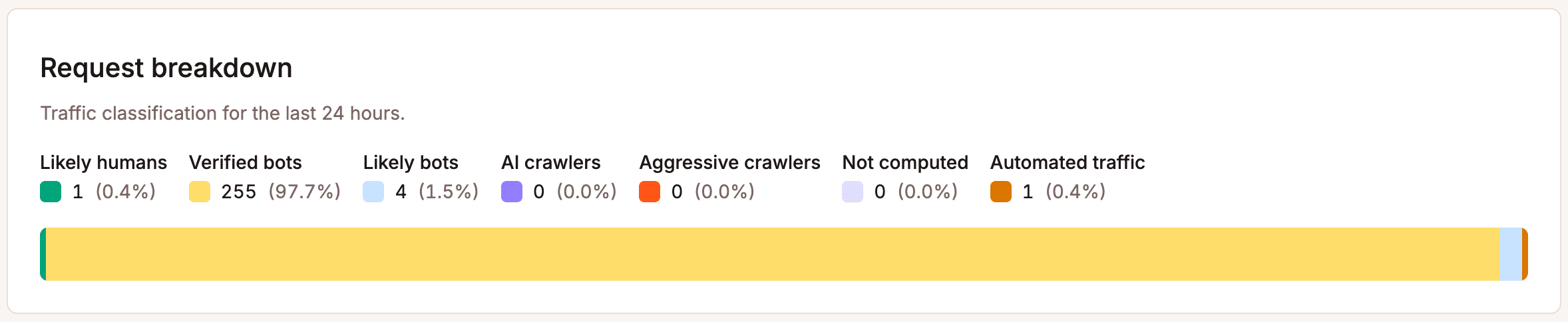
Wenn ein erheblicher Teil automatisiert oder nicht verifiziert ist, ist das dein Signal zum Handeln. Überspringe diesen Schritt nicht, denn Schutzmaßnahmen vorzunehmen, ohne zu wissen, wogegen du dich schützt, führt zu Fehlkonfigurationen.
Zweitens: Passe die Schutzstufe an den Website-Typ an. Ein WooCommerce-Shop hat andere Prioritäten als eine Content-Website, die wiederum andere Prioritäten hat als eine Staging-Umgebung. Das Blockieren von automatisiertem Datentraffic und das Überprüfen potenzieller Bots ist für einen Shop mit dynamischen Endpunkten sinnvoll. Eine Content-Website könnte es vorrangig zulassen, dass KI-Entdeckungs-Bots zugreifen, während KI-Trainings-Crawler blockiert werden. Eine Staging-Umgebung sollte in jedem Fall vollständig abgesichert sein.
Drittens: Schütze zuerst die kritischen Pfade. Bevor du pauschale Schutzregeln anwendest, überlege, ob deine kostenintensivsten Endpunkte – wie Warenkorb, Kasse und AJAX-Handler – für Crawler zugänglich sind, die dort nichts zu suchen haben. Das Blockieren bekannter Bot-User-Agents von /cart und ?add-to-cart= über robots.txt ist ein erster Schritt; die Durchsetzung auf WAF-Ebene (und nicht nur die Signalisierung) ist es, was die Belastung tatsächlich verhindert.
Viertens: Überwachen, dann anpassen. Die Muster des Bot-Traffics ändern sich schneller, als den meisten Website-Betreibern bewusst ist. Der Traffic-Anteil von GPTBot hat sich innerhalb eines einzigen Jahres verdreifacht. Schutzregeln einmal festzulegen und sie dann zu ignorieren, ist keine Strategie. Das Diagramm zu den Bot-Schutz-Ergebnissen in MyKinsta verfolgt, was im Laufe der Zeit blockiert, überprüft und zugelassen wird.
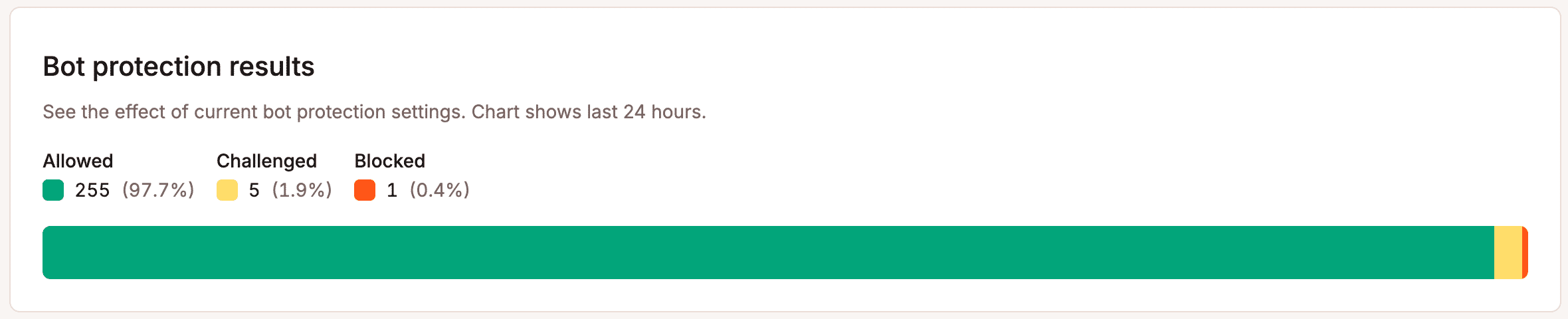
Diese Daten sollten dir als Grundlage dienen, um deine Einstellungen anzupassen.
Wenn Bots bei einem besuchsbasierten Tarif zu Überschreitungen der Besuchszahl führen, lohnt es sich möglicherweise, parallel dazu die bandbreitenbasierten Hosting-Tarife von Kinsta in Betracht zu ziehen. Der Wechsel zu einem bandbreitenbasierten Tarif löst zwar nicht das zugrunde liegende Bot-Problem, spiegelt aber die tatsächlichen Infrastrukturkosten deines Traffic-Mixes besser wider, die oft deutlich niedriger sind, als die Besucherzahlen vermuten lassen.
Das große Ganze: Dieses Problem wird noch schwieriger werden
Agentischer Traffic taucht bereits in den Infrastruktur-Logs auf. Google hat einen speziellen User-Agent angekündigt, der zum Einsatz kommt, wenn seine KI-Agenten mit Websites interagieren. Dabei handelt es sich um automatisierte Systeme, die auf Links klicken, Formulare ausfüllen und Anfragen stellen, die dem Verhalten menschlicher Nutzer immer ähnlicher werden.
Die Signale, die derzeit zur Bot-Klassifizierung dienen – wie User-Agent-Strings, Anfragehäufigkeit und Verhaltensbewertung –, lassen sich immer schwerer eindeutig anwenden, da die Grenze zwischen automatisierter und menschlicher Interaktion immer mehr verschwimmt.
Die meisten Website-Betreiber können da alleine nicht mithalten. Das Bot-Verhalten entwickelt sich schneller, als manuelle Regeln angepasst werden können. Was vor drei Monaten noch funktioniert hat, reicht heute vielleicht schon nicht mehr aus. Und die Kosten, die entstehen, wenn man hier Fehler macht – in Form von Serverressourcen, Abrechnungsüberschreitungen oder echten Kunden, die beim Bezahlvorgang auf 504-Fehler stoßen –, sind real und unmittelbar.
Hier kommt eine Infrastruktur ins Spiel, die das für dich übernimmt. Die Plattform von Kinsta blockiert 15–20 % des böswilligen Datenverkehrs, bevor er überhaupt deine Website erreicht, läuft auf dem Enterprise-Netzwerk von Cloudflare und bietet dir Bot-Schutzfunktionen, die sich an das tatsächliche Verhalten deiner Website anpassen. Da sich der Bot-Traffic ständig weiterentwickelt, wird der Unterschied zwischen einer Hosting-Plattform, die dies als Infrastrukturproblem behandelt, und einer, die es als Nebensache betrachtet, immer schwerer zu ignorieren sein.
Die Websites, die damit gut zurechtkommen, werden nicht diejenigen sein, die am meisten blockieren. Es werden diejenigen sein, die auf einer Infrastruktur laufen, die speziell dafür ausgelegt ist, Bots optimal zu bewältigen.

Joel ist Frontend-Entwickler und arbeitet bei Kinsta als Technical Editor. Er ist ein leidenschaftlicher Lehrer mit einer Vorliebe für Open Source und hat über 200 technische Artikel geschrieben, die sich hauptsächlich um JavaScript und seine Frameworks drehen.

