
Mit seinem wachsenden Marktanteil ist WordPress nach wie vor das beliebteste CMS für die Erstellung, Verwaltung und Entwicklung von Websites.
Dennoch macht WordPress nur einen Bruchteil der Entwicklung im Internet aus. Was ist mit all den Entwicklern, die nicht mit WordPress arbeiten? Auch sie erstellen, betreiben und verwalten Webanwendungen für ihr Unternehmen, ihre Kunden oder sich selbst.
Wir bei Kinsta haben mit Tausenden von Entwicklern und Hunderten von Agenturen zusammengearbeitet, deren Kunden Projekte auf WordPress aufgebaut haben. Viele haben auch Projekte, die nicht auf dem berühmten CMS basieren.
Bis heute hat sich Kinsta darauf konzentriert, verwaltete WordPress-Hosting-Lösungen zu entwickeln – was bedeutet, dass die Kunden (und ihre Kunden) nicht in der Lage waren, die Vorteile unserer Plattform für Nicht-WordPress-Projekte zu nutzen und alle Projekte unter „einem Dach“ zu hosten Das machte ihre Arbeit schwieriger und weniger effizient.
Also haben wir nach Möglichkeiten gesucht, wie wir ihnen das Leben leichter machen können.
Je mehr Feedback wir bekamen und je mehr wir mit unseren Kunden und Beta-Testern über ihre Projekte sprachen, desto mehr wurde uns klar, dass unsere Kunden mit einem grundlegenden Problem zu kämpfen hatten.
Aber es gibt eine Wendung in der Geschichte: Es waren nicht nur unsere Kunden.
Uns wurde klar, dass fast jeder Entwickler, jedes DevOps-Team und jede Agentur, die Webprojekte betreut, mit diesem Problem zu kämpfen hat. Alle haben damit zu kämpfen und sind auf der Suche nach einer besseren Lösung.
Entwickler sollten keine Zeit damit verschwenden, sich um das Hosting zu kümmern, sondern sich auf die Entwicklung konzentrieren
Was ist das Problem?
Der Mangel an Einfachheit einer Cloud-Hosting-Plattform.
Entwickler/innen wollen ihre Anwendungen schnell bereitstellen. Sie brauchen eine Plattform, die es ihnen ermöglicht, alles an einem Ort und unter einem Dach zu haben.
Eine Plattform, die einfach, übersichtlich und leicht zu bedienen ist und die Entwicklungsarbeit nicht auf eine einzige Technologie, ein Framework oder eine Bibliothek beschränkt.
Eine Plattform, die vom ersten Tag an leicht zu erlernen und zu nutzen ist, ohne dass spezielle Kurse oder plattformspezifische Zertifizierungen erforderlich sind.
Eine Plattform mit einem einfachen und transparenten Preismodell. (Hast du jemals versucht, die Preisgestaltung von AWS zu verstehen? Schwierig!)
Wir wussten, dass die containerisierte Architektur von Kinsta diese Anforderungen erfüllen und Entwicklern die Plattform und die Werkzeuge bieten würde, die sie für ihre Arbeit benötigen.
Darüber hinaus wussten wir, dass wir folgendes bieten:
- 8+ Jahre Erfahrung in der Hosting-Branche
- Unübertroffener Support
- Talentierte Entwickler und Ingenieurteams, die in der Lage sind, jedes technische Problem zu lösen
- DevOps-Teams, die unübertroffen sind, wenn es um die Orchestrierung, Verwaltung und Skalierung unserer Hosting-Plattform geht
Deshalb haben wir unsere neuen, verbesserten Hosting-Lösungen auf der gleichen Plattform aufgebaut, die auch unsere WordPress-Dienste so leistungsstark macht. Nach mehr als einem Jahr harter Arbeit, an der 320+ Kinstanians, 750+ Betatester und unzählige Iterationen beteiligt waren, haben wir sie nun der Öffentlichkeit zugänglich gemacht.
Einführung von Anwendungs-Hosting und Datenbank-Hosting Lösungen
Die Vision von Kinsta ist es, den Status quo zu verändern. Dies erreichen wir durch unser starkes Engagement, Entwicklern das beste Erlebnis zu bieten:
Wir entwickeln uns ständig weiter, um branchenführende Tools und Dienste für moderne Entwickler/innen anzubieten. Wir setzen uns dafür ein, Entwicklern und Unternehmen die beste Erfahrung zu bieten, indem wir auf Leistung und Benutzerfreundlichkeit setzen.
Durch die Erweiterung unseres Angebots um neue Dienste haben Entwickler und DevOps-Teams jeder Art und Größe jetzt eine Fülle von Hosting-Lösungen für ihre Anwendungen, Datenbanken, Dienste und WordPress-Seiten zur Auswahl – und das mit mehr Flexibilität als je zuvor.
Im Einzelnen bietet Kinsta jetzt Folgendes an:
Schauen wir uns jedes dieser Angebote genauer an.
Managed WordPress Hosting (kurz und bündig)
Mit der Google Cloud Platform und ihrem Premium Tier Network haben wir einen Managed WordPress Hosting Service entwickelt, der mehr als 25.000 Unternehmen und 100.000 Websites mit allem versorgt, was sie für ihren Betrieb und ihr Wachstum brauchen.
Dank der Nutzung der leistungsstärksten CPUs und der globalen Verfügbarkeit der rechenoptimierten C2 VMs von Google, der 27 verfügbaren Rechenzentren und des blitzschnellen Kinsta CDN mit 300+ PoPs zur Bereitstellung statischer und dynamischer Inhalte für ein global verteiltes Publikum, bemerken Kunden, die von einem beliebigen Hoster zu Kinsta wechseln, fast sofort durchschnittlich 20% schnellere Ladezeiten.

Aber das sind noch nicht alle Vorteile.
Dank automatischer Backups, MyKinsta (unserem benutzerdefinierten und benutzerfreundlichen Dashboard für die Website-Verwaltung), dem eingebauten Anwendungsüberwachungs-Tool und dem unternehmensweiten Firewall- und DDoS-Schutz von Cloudflare können Website-Betreiber und -Entwickler mit der Gewissheit, dass ihre Websites sicher sind, nachts ruhig schlafen.
Sie wissen auch, dass Kinsta ihnen jeden Monat viele Stunden Arbeit erspart. Weniger Zeit für sich wiederholende, aber wichtige Aufgaben bedeutet weniger Overhead und weniger Wartungskosten für dein Unternehmen.
Arbeitet dein Unternehmen mit WordPress? Bist du ein WordPress-Entwickler und suchst einen Hoster mit Tools, die dir helfen, deine Arbeit zu rationalisieren? Schau dir unsere Managed WordPress Hosting-Lösungen an.
Anwendungs-Hosting (kurz und bündig)
Die Webentwicklung erlebt einen interessanten Moment, der zeigt, wie vielschichtig, nuanciert und komplex diese Welt heute ist. Unsere neue Anwendungs-Hosting Lösung vereinfacht die Arbeit moderner Webentwickler.
Wir machen es dir einfach, indem wir dich von der Einrichtung von Containern, der Verwaltung von Servern, der Sorge um das Betriebssystem, der Verwaltung von Backups, der Installation von SSL-Zertifikaten und dem Hinzufügen von benutzerdefinierten Domains befreien – von allem, was dich daran hindern könnte, dich ausschließlich auf die Entwicklung zu konzentrieren.
Wir haben eine Entwicklungsplattform entwickelt, die dir dabei hilft, deine Anwendungen so schnell wie möglich für die Nutzer bereitzustellen.
Das Anwendungs-Hosting von Kinsta ist das, was auf dem Markt üblicherweise als Platform-as-a-Service (PaaS) bezeichnet wird. Es verfügt über Tools, mit denen du deine Anwendungen von Code-Hosting-Diensten wie GitHub schnell und einfach bereitstellen kannst, sowie über Kapazitäten für den reibungslosen Betrieb in einer optimierten Umgebung, die für die Skalierung ausgelegt ist.
So stellst du eine Anwendung auf Kinsta bereit
Unsere Ingenieure und Produktmanager haben sich darauf konzentriert, einen optimierten Prozess für die Bereitstellung deiner Anwendungen zu entwickeln. Der Prozess erfordert nur 3 Schritte:
- Verbinde dich mit deinem GitHub-Konto und wähle ein Repository
- Stelle deine Anwendung automatisch (bei jedem Commit) oder manuell bereit
- Baue, skaliere und führe deine Prozesse separat aus
So einfach ist es!
Du brauchst dich nicht um die Einrichtung von Container-Images zu kümmern, denn wir erkennen und implementieren automatisch Anwendungen, die in dieser wachsenden Liste von Sprachen oder Frameworks erstellt wurden:
- Node.js
- PHP
- Django
- Rails
- Java
- Scala
- Go
(Hinweis: Wir stellen eine Liste mit einfachen „Hello World“-Repositories zusammen, die du auf Kinsta nutzen kannst, um den Dienst auszuprobieren.)
Wenn du mehr Kontrolle über ein benutzerdefiniertes Docker-Image haben möchtest, kannst du dein eigenes Dockerfile im Repository verwenden. So kannst du fast jede Sprache/jedes Framework verwenden und bist nicht auf die von unseren aktuellen Buildpacks unterstützten Sprachen beschränkt.
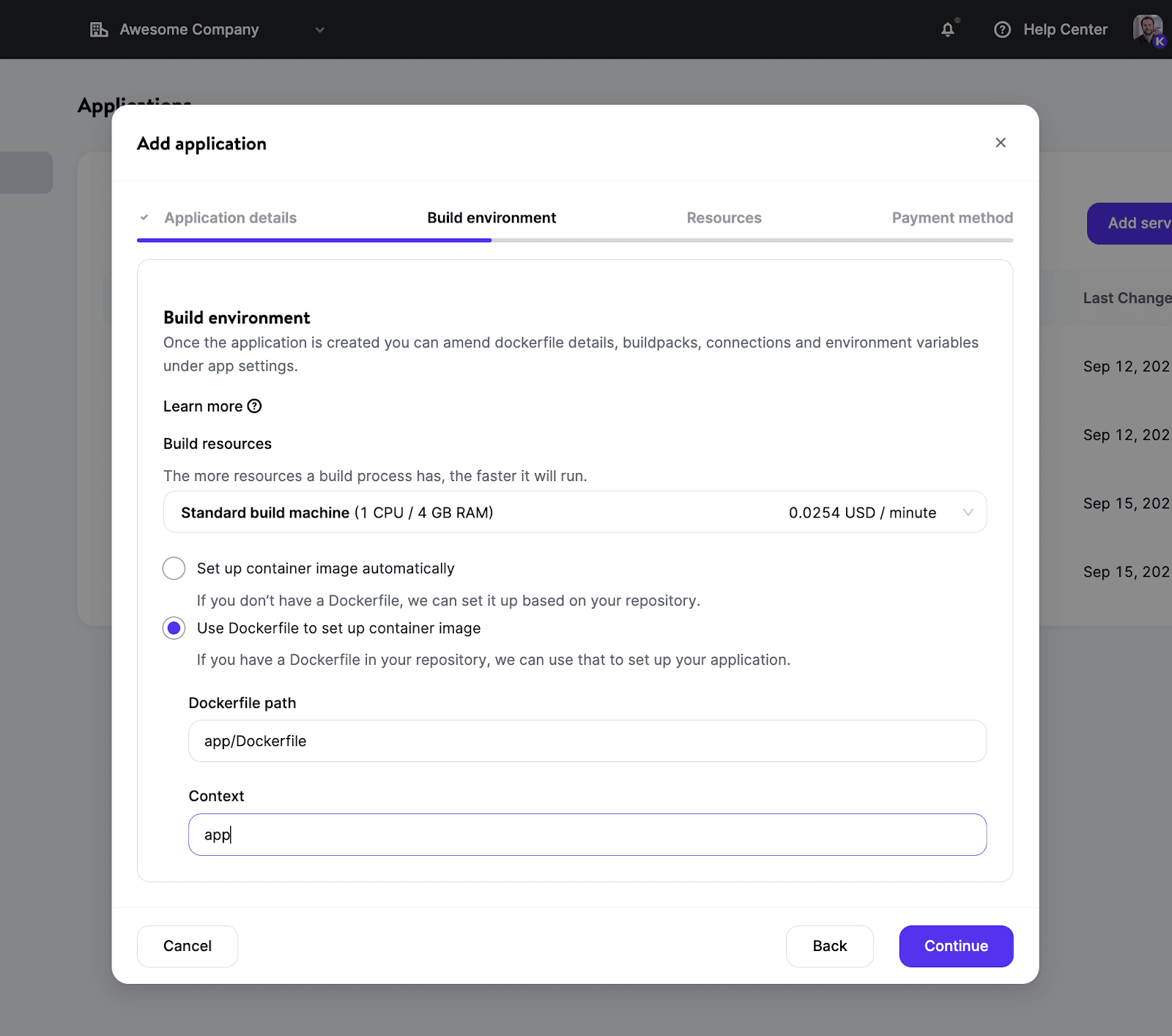
Sobald deine Build-Umgebung eingerichtet ist, hast du viele Möglichkeiten, die Ressourcengröße (dank verschiedener Pod-Typen) nach deinen Bedürfnissen zu wählen und die Anzahl der Instanzen für eine bessere Skalierbarkeit festzulegen.
Einen detaillierten Einblick in alle Funktionen findest du in unserer Dokumentation zum Anwendungs-Hosting.
Leistungsstarke Analysen zur Überwachung deiner Anwendungen
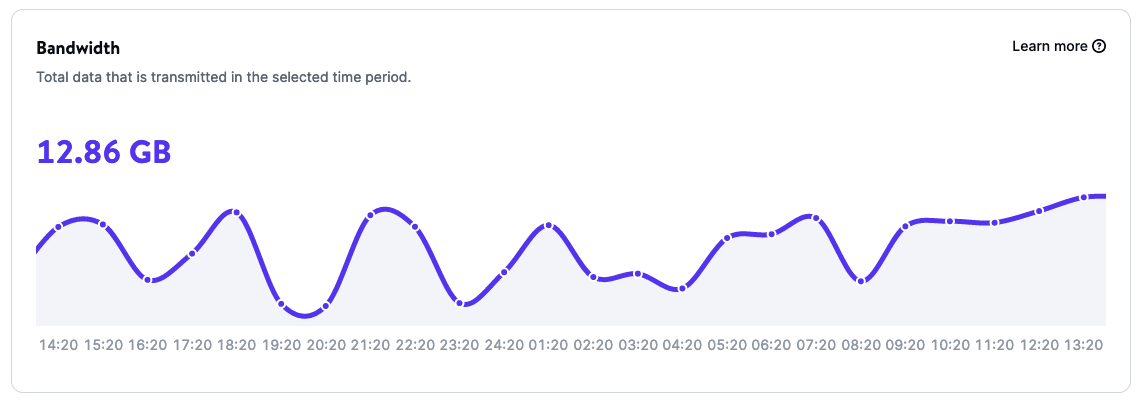
Dank der Analytics-Seiten für deine Anwendungen erhältst du Berichte über die Nutzung deiner Anwendungen, die Folgendes beinhalten:
- Bandbreite
- Build Zeit
- Laufzeit
- CPU-Nutzung
- Speicherverbrauch
Wie sieht es mit der Preisgestaltung aus?
Anwendungs-Hosting bietet ressourcenbasierte Optionen, d.h. du zahlst nur für deine Nutzung und nicht für mehr. Und die ersten 20 Dollar gehen sowohl für neue als auch für bestehende Kunden auf uns.
Erfahre mehr über Anwendungs-Hosting bei Kinsta und stelle deine erste Anwendung in einem unserer 24 Rechenzentren bereit.
Datenbank-Hosting (kurz und bündig)
Datenbanken sind ein wichtiger Bestandteil vieler Webprojekte. Es gibt zwar Anwendungen, die keine brauchen, aber die große Mehrheit benötigt eine Datenbank.
Dank der Datenbank-Hosting-Lösung von Kinsta kannst du mit wenigen Klicks eine Datenbank einrichten und dich entweder mit einer von Kinsta gehosteten Anwendung oder einem externen Dienst mit deiner Datenbank verbinden.
Wir unterstützen derzeit verschiedene Datenbanktypen, für die du die Version auswählen kannst, die am besten zu deinen Projektanforderungen passt. Im Einzelnen kannst du folgende hosten:
- MySQL
- MariaDB
- Redis
- PostgreSQL
Und wir arbeiten daran, in naher Zukunft weitere hinzuzufügen!
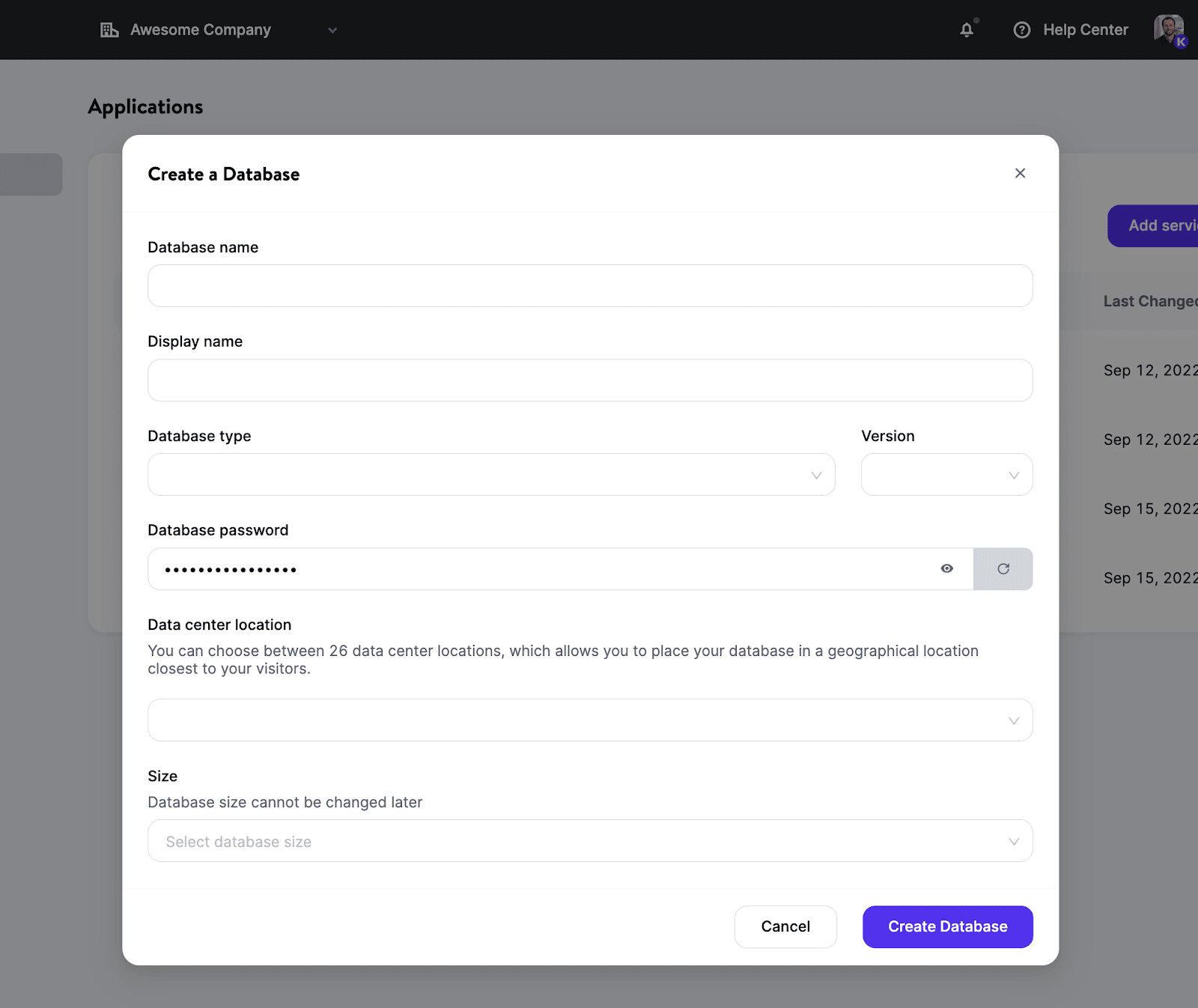
So stellst du eine Datenbank bei Kinsta bereit
Du kannst eine neue Datenbank einrichten und sie in wenigen Minuten zur Verfügung stellen. Du musst dich nicht um die Verwaltung von Servern, Clustern und Containern oder um andere Aufgaben kümmern, für die normalerweise DevOps zuständig ist.
Hier ist der Ablauf:
- Wähle den Datenbanktyp und die Version, die du bevorzugst.
- Wähle einen Standort aus den 24 Rechenzentren, die derzeit verfügbar sind.
- Konfiguriere die Ressourcen für deine Datenbank.
Voilà: Du hast jetzt eine frisch erstellte, containerisierte Datenbank (ohne geteilte Ressourcen!) für deine Projekte.
Wenn du eine interne Verbindung zwischen deiner Anwendung und deiner Datenbank herstellst, befinden sich beide im selben Cluster und kommunizieren über eine sichere Verbindung, die eine bessere Leistung als externe Verbindungen bietet.
Außerdem entstehen dir keine Kosten für den internen Datenverkehr, da die Anfragen im selben Netzwerk bleiben!
Weitere Informationen findest du in unserer Dokumentation zum Thema Datenbank-Hosting.
Leistungsstarke Analysen zur Überwachung deiner Datenbank
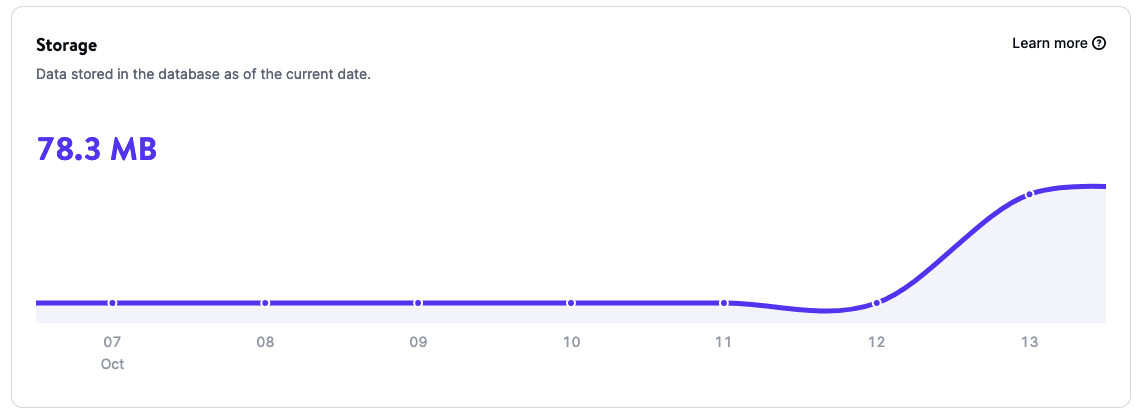
Dank Datenbank Analytics erhältst du Einblicke in die Nutzungsdaten deiner Datenbank, darunter:
- Speicher
- Laufzeit
- CPU-Auslastung
- Speicherverbrauch
Wie sieht es mit der Preisgestaltung aus?
Wie beim Anwendungs-Hosting gibt es auch beim Datenbank-Hosting ein Abrechnungssystem, bei dem die Nutzung nach Größe und Laufzeit der Datenbank berechnet wird.
Erfahre mehr über Datenbank-Hosting bei Kinsta und stelle deine erste Datenbank in einem unserer 24 Rechenzentren bereit. Und vergiss nicht: Du bekommst $20 Rabatt auf deinen ersten Monat.
Was kommt als Nächstes?
Dies ist erst der Anfang der neuen Ära von Kinsta. Unsere Entwicklungs- und Technikteams arbeiten hart an neuen Funktionen, beheben Fehler und arbeiten an der Optimierung, indem sie genau auf dein Feedback hören.
Zu den neuen Lösungen, an denen wir arbeiten, gehören statisches Website-Hosting, maschinelles Lernen, Cloud-Anwendungen und Function-as-a-Service at the Edge – um nur einige der spannenden Dinge auf unserer Roadmap zu nennen. Darüber hinaus konzentrieren wir uns weiterhin darauf, unsere Managed WordPress-Lösungen noch besser zu machen und sie mit neuen Funktionen zu verbessern, wie z.B. dem Edge-Caching, das die Zeit, die für die Bereitstellung von gecachetem WordPress-HTML benötigt wird, um durchschnittlich mehr als 50 % reduziert!
Es sind großartige Zeiten, um als Entwickler/in zu arbeiten, und wir sind gespannt auf das, was uns hier bei Kinsta noch bevorsteht!
Zusammenfassung
Durch die Erweiterung der Hosting-Lösungen von Kinsta erweitern wir die Möglichkeiten, Unternehmen und Entwickler zu unterstützen, unabhängig von der Technologie, mit der sie arbeiten. Der Vorsitzende des Vorstands von Kinsta hat es so zusammengefasst:
Wir bauen eine Plattform auf, auf der Entwickler/innen alles finden, was sie brauchen, um einen Webservice mit Leichtigkeit zu betreiben, damit sie sich darauf konzentrieren können, ihre beste Arbeit zu erstellen und mit der Welt zu teilen.
Um dieses neue Kapitel in der Geschichte von Kinsta zu feiern, kann jeder – Neu- und Bestandskunden – unser Anwendungs-Hosting und Datenbank-Hosting mit einem Rabatt von $20 im ersten Monat testen.
Willkommen beim neuen Kinsta – der Plattform für moderne Entwickler, die ihre Ideen in lebendige, skalierbare Anwendungen verwandeln, so wie du es dir immer vorgestellt hast.
Einfach, schnell und mit allem an einem Ort.
Vielen Dank an all unsere großartigen Kunden, die uns ihr Vertrauen geschenkt haben und uns auf diesem Weg unterstützen!

Chefredakteur bei Kinsta und Content Marketing Berater für WordPress Plugin-Entwickler. Verbinde dich mit Matteo auf Twitter.

