
Problemen met schalen komen zelden uit het niets. Ze bouwen zich meestal stilletjes op totdat een campagnelancering, een verkeerspiek, een tijdelijke drukte of een trage afrekenervaring iedereen dwingt om aandacht te besteden.
Sommige teams optimaliseren vroeg op basis van aannames. Anderen wachten tot vertragingen, klachten of stijgende kosten actie onvermijdelijk maken. Beide benaderingen brengen risico’s met zich mee. De ene kan je budget verspillen. De andere laat je site onvoorbereid wanneer de groei zich aandient.
Analytics geeft teams een betere manier om te beslissen wanneer ze in actie moeten komen. In dit artikel leggen we uit hoe je analytics kunt gebruiken als planningsinstrument om drempelwaarden, beperkingen en gebruikspatronen zichtbaar te maken voordat ze grotere problemen worden.
Waarom schaalbeslissingen vaak te laat worden genomen
Beslissingen over schalen worden vaak op het slechtst mogelijke moment genomen – nadat er al iets misgegaan is.
Een site vertraagt tijdens een campagne. De afrekenflow loopt vast bij piekverkeer. Interne teams melden problemen die ze niet goed kunnen verklaren. Wat een geplande aanpassing had kunnen zijn, wordt een nacht achter de laptop zitten op zoek naar een oplossing.
Dit reactieve patroon komt vaak voor omdat teams geen duidelijk beeld hebben van wanneer hun infrastructuur zijn grenzen nadert. Ze zien misschien wel het verkeer groeien, maar begrijpen niet hoe die groei invloed heeft op serverresources, cacheprestaties, bandbreedte of databaseactiviteit. Dus wachten ze tot de signalen te duidelijk zijn om te negeren.
Het tegenovergestelde gebeurt ook. Sommige teams upgraden te vroeg, uit bezorgdheid over toekomstige groei, ook als de data geen structurele druk laat zien. Dat leidt tot onnodige kosten, zeker als het echte probleem opgelost had kunnen worden met betere caching, schonere code of een andere workflow.
Reactief schalen zorgt voor een aantal problemen die groei moeilijker te managen maken:
Beslissingen worden onder druk genomen
Als schalen wordt afgedwongen door een vertraging, uitval of verkeerspiek, moeten teams problemen diagnosticeren terwijl het bedrijf de impact al voelt. Die druk leidt tot overhaaste keuzes en tijdelijke oplossingen die de echte oorzaak niet aanpakken.
Planning wordt giswerk
In plaats van trends te gebruiken als leidraad voor budgetten en tijdlijnen, koppelen teams infrastructuurbeslissingen aan noodsituaties. Dat maakt het moeilijker om te voorspellen wanneer extra capaciteit nodig is en de bijbehorende kosten te onderbouwen.
Vertrouwen brokkelt af
Als elke schaalbeslissing urgent voelt, gaan teams twijfelen aan hun eigen oordeel. Was het te laat, te vroeg, of om de verkeerde reden? Na verloop van tijd gaat infrastructuur aanvoelen als een terugkerend risico in plaats van iets dat je in de hand hebt.
Rapportage vertelt je wat er is gebeurd: operationele analytics vertelt je wat je nu moet doen
De meeste teams hebben toegang tot rapportages. Ze zien verkeerstrends, paginaweergaven, conversies en verwijzingsbronnen. Nuttige informatie, maar het vertelt slechts een deel van het verhaal.
Rapportage op oppervlakkig niveau laat resultaten zien. Het vertelt je hoeveel mensen je site bezochten, wat ze deden en of ze converteerden. Wat het niet laat zien, is hoe je infrastructuur achter de schermen met die activiteit omging. Die kloof wordt steeds belangrijker naarmate je groeit.
Een verkeerspiek ziet er misschien uit als een succes in een rapportagedashboard, maar het vertelt je niet of je server onder druk stond, of PHP threads hun limiet bereikten, of dat caching ervoor zorgde dat alles soepel bleef lopen. Twee sites kunnen dezelfde stijging in bezoek zien en toch totaal verschillende uitkomsten hebben, afhankelijk van hoe hun resources worden benut.
Operationele analytics biedt meer diepgang. In plaats van alleen resultaten te tonen, laat het zien wat er onder de oppervlakte gebeurt. Teams zien hoe verzoeken worden afgehandeld, hoe resources worden gebruikt en waar de druk oploopt. Metrics zoals bandbreedtegebruik, cache-efficiëntie, PHP thread-activiteit en responsgedrag geven een concreter beeld van hoe je infrastructuur omgaat met de werkelijke vraag.
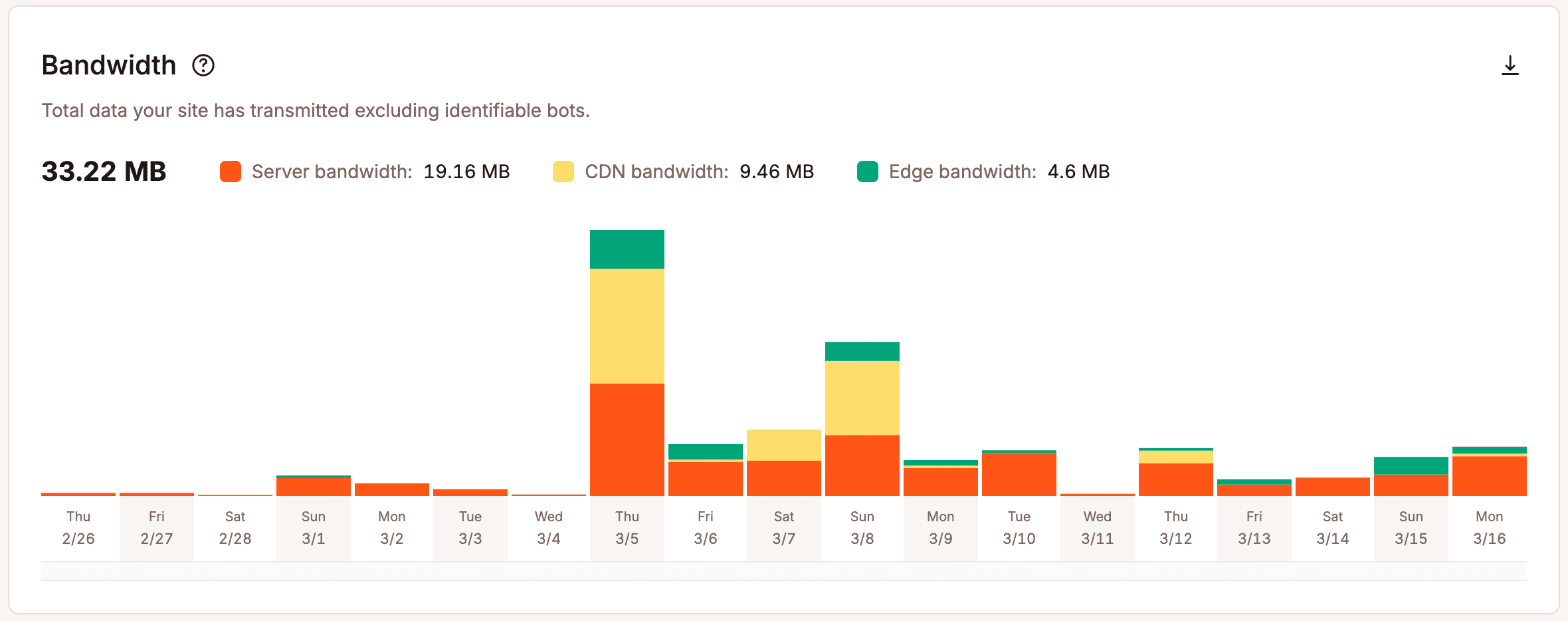
Zonder die zichtbaarheid worden schaalbeslissingen subjectief. Teams reageren op losstaande incidenten, vertrouwen op hun gevoel of plannen voor worst-case scenario’s zonder te weten hoe realistisch die zijn.
De signalen die aangeven dat het tijd is om te optimaliseren of te schalen
De echte vraag is niet: “Kunnen we de site sneller maken?” De meeste teams vinden altijd wel iets om bij te stellen, op te ruimen of te verbeteren.
De betere vraag is: “Wat vertellen de data ons om nú te doen?”
Analytics helpt teams onderscheid te maken tussen een tijdelijk probleem en een echt capaciteitsvraagstuk. In plaats van te handelen op basis van vage zorgen, kun je kijken naar meetbare signalen die aangeven wanneer optimalisatie of schalen aandacht verdient.
Verkeerstrends die aanhoudend stijgen
Een enkele verkeerspiek betekent niet dat een site meer resources nodig heeft. Het kan komen door een eenmalige e-mailcampagne, een sociale vermelding, een PR-moment of een seizoensgebonden piek. Die momenten zijn de moeite van het bekijken waard, maar wijzen niet automatisch op een structurele behoefte aan schalen.
Aanhoudende groei vertelt een ander verhaal. Als bezoeken, verzoeken of ingelogde activiteit in de loop van de tijd blijven toenemen, is het zinvol om je huidige opzet kritisch tegen het licht te houden. Herhaalde stijgingen verhogen geleidelijk de druk op serverresources, databaseactiviteit, cachinglayers en bandbreedte.
Trenddata helpt teams vooruit te plannen. Als het verkeer maand na maand toeneemt, kun je prestaties testen, zwakke plekken identificeren en verbeteringen doorvoeren voordat de groei de site inhaalt.
Resourcegebruik dat op overbelasting wijst
Verkeer alleen laat niet zien hoe hard je site werkt. Zelfs een bescheiden aantal bezoekers kan de site overbelasten als dynamische pagina’s, zware databasequery’s, zwakke caching of achtergrondprocessen buitensporig veel resources verbruiken.
Analytics op hostingniveau laat zien waar de druk toeneemt. Denk hierbij aan PHP thread-gebruik, bandbreedtegebruik, cache hit- en missratio’s, databaseactiviteit, responscodes en het aantal verzoeken.
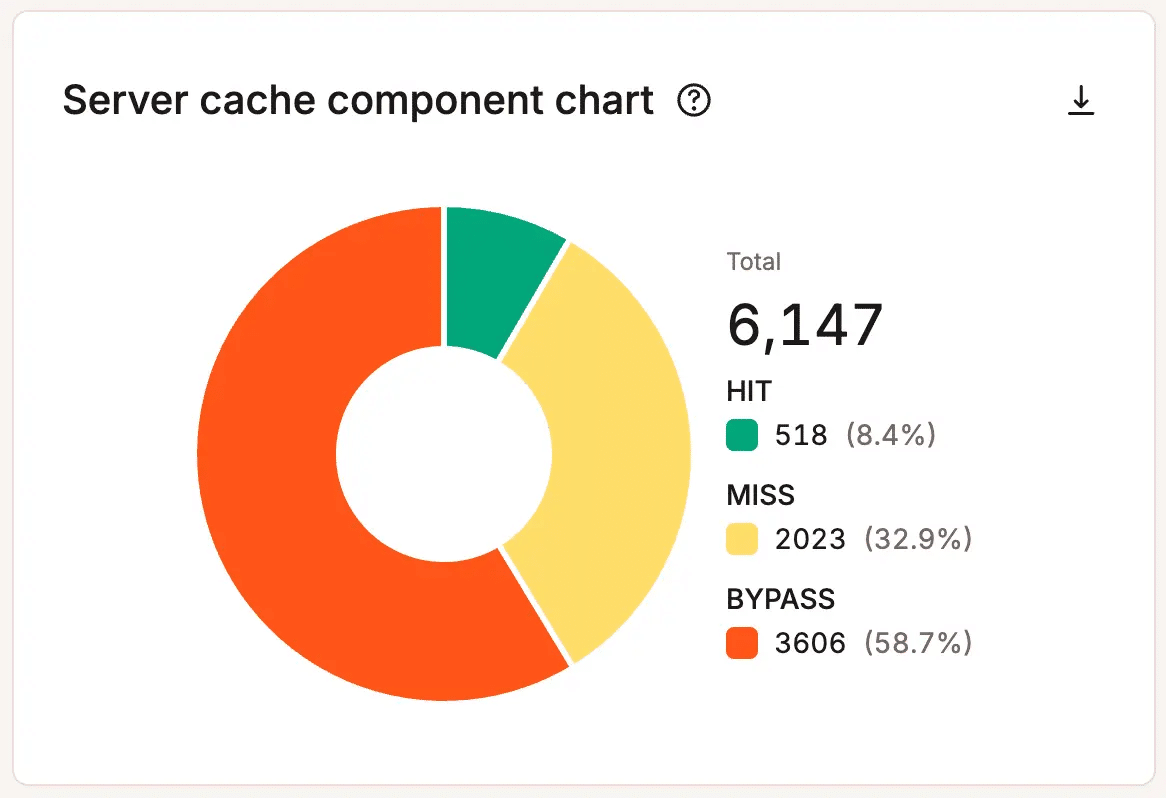
Let op patronen, niet op eenmalige pieken. Een korte PHP thread-piek tijdens een druk moment hoeft geen probleem te zijn. Maar herhaalde pieken, stijgende bandbreedtebehoefte of structureel zwakke cacheprestaties kunnen erop wijzen dat je site optimalisatie nodig heeft, dat de workflow herzien moet worden, of dat meer capaciteit de juiste stap is.
Prestatieproblemen die optreden onder specifieke omstandigheden
Sommige prestatieproblemen duiken alleen op als je site onder druk staat. Een site kan snel aanvoelen op een gewone dag, maar vertragen tijdens een productlancering, fondsenwervingscampagne, inschrijvingsperiode, Black Friday-actie of grote contentcampagne.
Die momenten onthullen vaak de werkelijke grenzen van je huidige setup.
Analytics helpt teams te bepalen of een probleem tijdelijk, terugkerend of structureel is. Als prestaties alleen dalen tijdens zeldzame verkeerspieken, is betere campagnevoorbereiding waarschijnlijk voldoende. Als vertragingen optreden zodra de vraag stijgt, heeft de site waarschijnlijk diepgaandere optimalisatie nodig – of een meer schaalbare hostingsetup.
Fouten en afwijkingen als vroege waarschuwingssignalen
Fouten, mislukte verzoeken en ongewone activiteit kunnen teams waarschuwen voordat bezoekers de volledige impact ervaren.
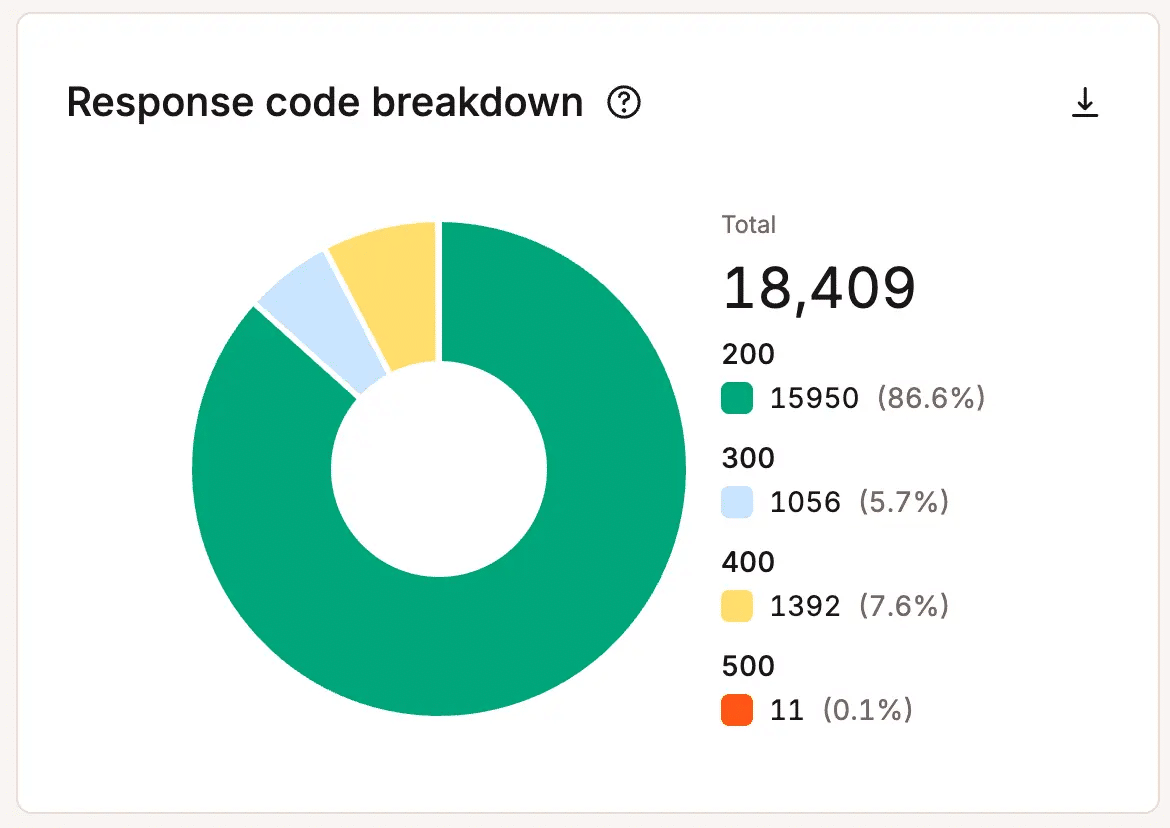
Stijgende foutpercentages kunnen wijzen op overbelasting van de infrastructuur, applicatieproblemen, knelpunten in resources of mislukte processen. Ongebruikelijke verkeerspatronen kunnen duiden op bots, ongeldige verzoeken of onverwachte vraag die resources verbruikt zonder bedrijfswaarde te leveren.
Deze signalen geven teams de kans om vroeg in te grijpen. Door fouten en afwijkingen in context te bekijken, kun je de oorzaak onderzoeken, onnodige belasting verminderen en de gebruikerservaring beschermen voordat kleine waarschuwingssignalen uitgroeien tot zichtbare problemen.
Hoe analytics slimmere schaalbeslissingen ondersteunt
Analytics helpt teams om van “iets voelt niet goed” naar “dit is wat de data laten zien” te gaan. Die verschuiving maakt schaalbeslissingen praktischer, minder reactief en makkelijker te onderbouwen.
Het helpt teams ook om de juiste volgende stap te kiezen. Niet elke vertraging of piek rechtvaardigt een groter hostingpakket. Soms is optimalisatie de betere keuze. Andere keren wijzen de data op een workflowprobleem, een resource-intensief proces of een bredere infrastructuurwijziging.
Weten of je moet optimaliseren vóór je gaat upgraden
Meer capaciteit is niet altijd de beste eerste stap. Als analytics wijst op slechte cache-efficiëntie, ongewoon zware verzoeken, inefficiënte code of resource-intensieve achtergrondtaken, kan het team de prestaties verbeteren zonder van pakket te wisselen.
Dat kan betekenen: cachingregels finetunen, plugins of aangepaste code opschonen, databasequery’s herzien of processen aanpassen die vermijdbare belasting veroorzaken. In die gevallen helpt analytics teams te voorkomen dat ze betalen voor extra capaciteit terwijl betere efficiëntie het probleem al oplost.
Weten wanneer een upgrade gerechtvaardigd is
Op een bepaald punt is optimalisatie niet meer voldoende. Als de data structurele druk op resources laten zien, terugkerende vertragingen bij normale groei, stijgende bandbreedtebehoefte of duidelijke gebruiksplafonds, dan is een upgrade makkelijker te onderbouwen.
De grafiek hieronder laat bijvoorbeeld zien dat deze site in minder dan 30 dagen 69 keer het maximale aantal toegewezen PHP threads bereikte.
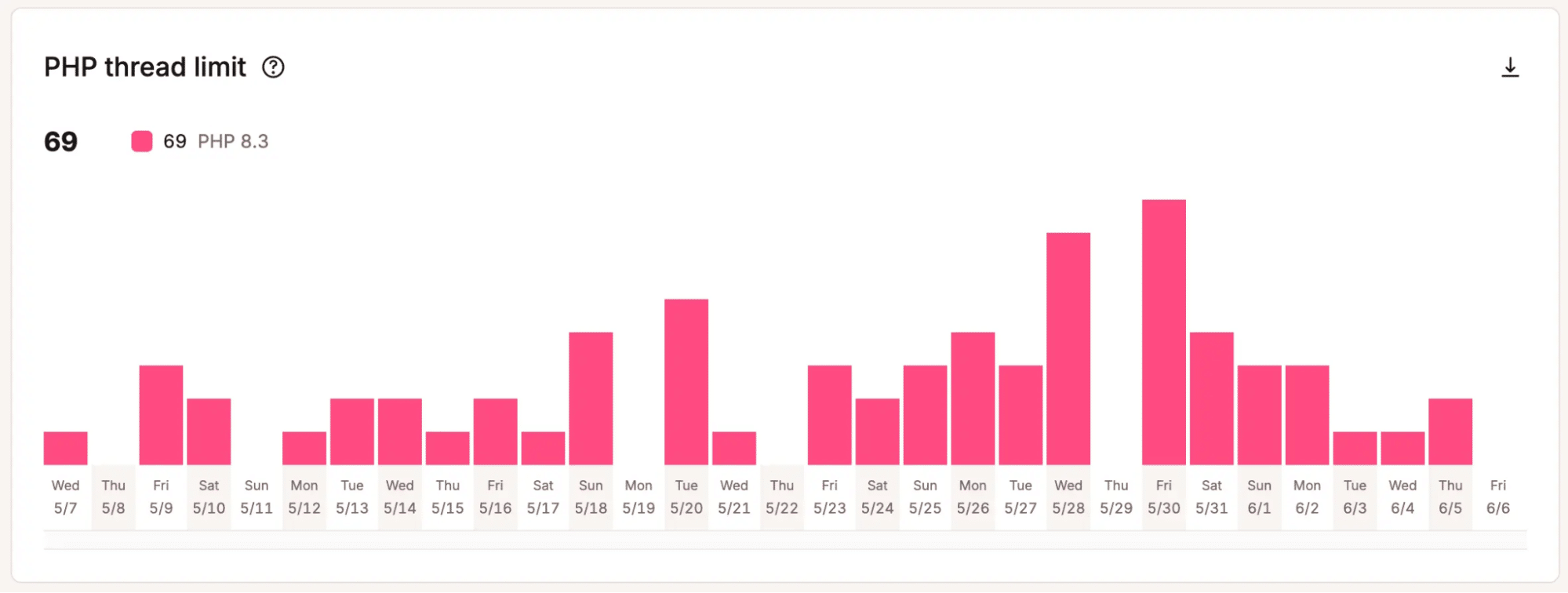
Dat is precies de informatie die teams nodig hebben om te beslissen of extra capaciteit de investering waard is. In plaats van af te gaan op een gevoel, kun je wijzen op patronen die aantonen dat de huidige opzet zijn grenzen bereikt.
Weten hoe je de beslissing intern onderbouwt
Schaalbeslissingen blijven zelden binnen het technische team. Management, finance, marketing en operations willen begrijpen waarom de verandering nodig is, en waarom nu.
Analytics helpt teams een heldere business case op te bouwen. In plaats van te leunen op meningen, kun je wijzen op concrete data en infrastructuuruitgaven koppelen aan sitebetrouwbaarheid, campagnegereedheid, gebruikerservaring en omzetbescherming. Zo verschuift het gesprek van technische voorkeur naar meetbaar risico, timing en verwachte impact.
Waarom reactieve hosting schalen bemoeilijkt
Reactieve hosting maakt groei moeilijker te managen omdat teams de grenzen pas zien als ze de impact al voelen.
Veel hostingomgevingen geven teams slechts beperkt zicht op de werkelijke capaciteitsdrempelwaarden. Je kent misschien de limieten van je pakket, maar je kunt niet altijd zien hoe dicht de site bij overbelasting zit – of welke onderdelen van de stack de meeste druk veroorzaken.
Dat leidt tot een frustrerend patroon. De site wordt trager, een campagne presteert ondermaats of er komen supporttickets binnen. Dan gaat het team op onderzoek uit, neemt contact op met de host en overweegt een upgrade nadat het probleem al impact heeft gehad op het bedrijf.
Dit model voegt onzekerheid toe. Het maakt infrastructuur moeilijker te voorspellen, te onderbouwen en op te vertrouwen. Voor groeiende teams maakt dat gebrek aan inzicht schalen tot een reactie in plaats van een gepland onderdeel van groei.
Hoe Kinsta teams helpt met meer vertrouwen te schalen
Kinsta geeft teams een duidelijker beeld van hoe hun WordPress sites presteren onder werkelijke belasting. Met MyKinsta analytics volg je verkeerspatronen, resourcegebruik, prestatiesignalen en opkomende knelpunten, zonder hosting als een black box te hoeven behandelen.
Die zichtbaarheid maakt schalen minder reactief. Teams zien trends eerder, plannen groei met meer vertrouwen en nemen infrastructuurbeslissingen op basis van echte data.
Analytics die werkelijke beperkingen zichtbaar maakt
Kinsta helpt teams te zien waar de grenzen zich beginnen af te tekenen. MyKinsta analytics toont signalen zoals verkeerstrends, bandbreedtegebruik, cacheprestaties, responscodes en resourceactiviteit, zodat teams een concreet beeld krijgen van hoe hun site met de vraag omgaat.
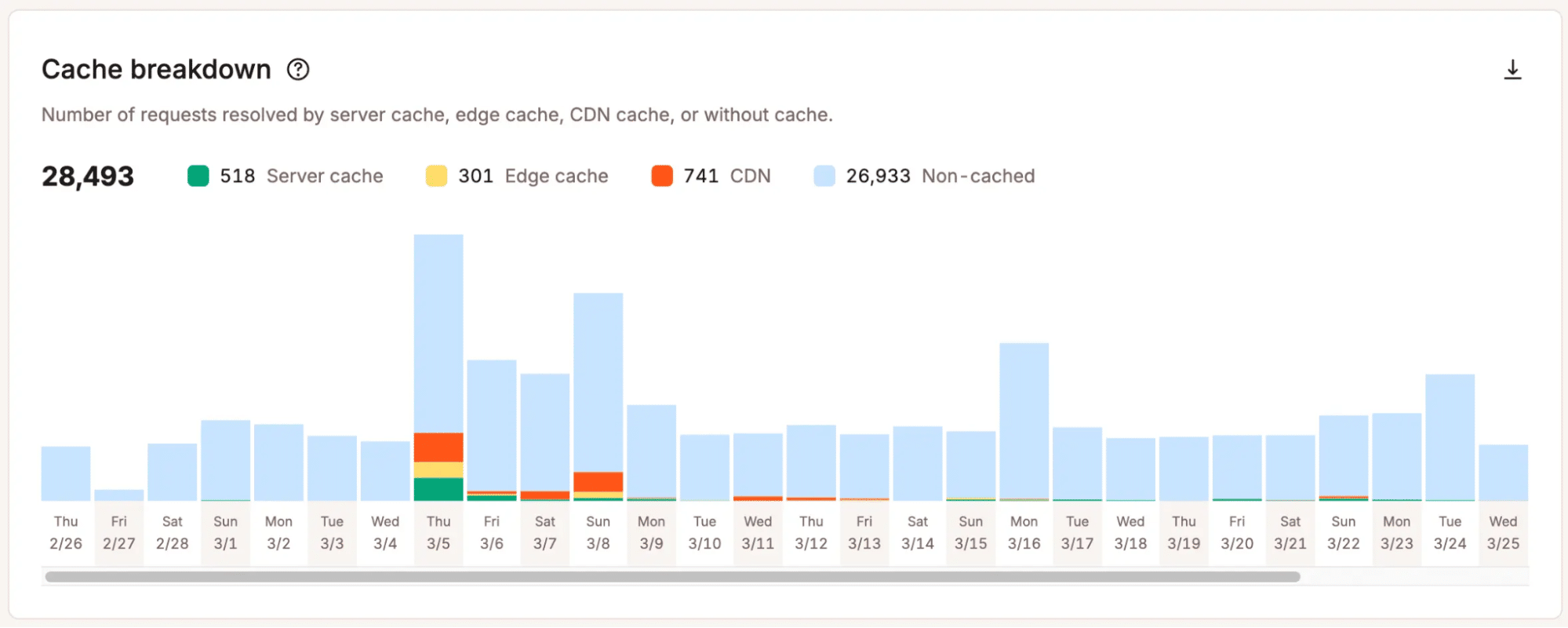
Die duidelijkheid is essentieel, want schaalbeslissingen mogen niet berusten op aannames. Als je ziet waar de druk toeneemt, kun je gericht beslissen: optimaliseren, van pakket wisselen of een diepere technische analyse uitvoeren.
Een platform gebouwd voor weloverwogen beslissingen
Groei brengt vaak vragen mee over budgetten, lanceertijdlijnen en de noodzaak om nieuwe uitgaven te onderbouwen. Kinsta ondersteunt die gesprekken met concrete data over sitegebruik en prestaties.
Dat maakt infrastructuurplanning makkelijker uit te leggen. In plaats van meer capaciteit te vragen omdat de site “traag aanvoelt”, koppel je de beslissing aan meetbare trends, terugkerende belasting of specifieke groeibehoeften.
Voorspelbaarheid als groeivoordeel
Schalen voelt minder stressvol als je ziet wat er verandert voordat het urgent wordt. Met beter inzicht in gebruikspatronen en prestatiesignalen bereid je je met meer vertrouwen voor op campagnes, seizoensgebonden vraag en groei op de lange termijn.
Die voorspelbaarheid geeft teams een hostingplatform dat ze begrijpen, kunnen plannen en vertrouwen, ook als de groei doorzet.
Behandel analytics niet langer als bijzaak
Analytics werkt het beste als het je planning vormgeeft, niet alleen als je achteraf de prestaties evalueert.
Als je trends, gebruikspatronen en vroege tekenen van overbelasting kunt zien, kun je schaalbeslissingen beter timen en duidelijker onderbouwen. Je hoeft niet te gokken wanneer je moet handelen, of te reageren onder druk. Je maakt weloverwogen keuzes op basis van wat je site werkelijk doet.
Dat maakt groei voorspelbaarder – en een stuk minder stressvol.
Verken MyKinsta om je gebruikspatronen, prestatiesignalen en schaalbehoefte beter te begrijpen voordat ze urgent worden.


