
Je opent je Analytics-dashboard en ziet dat het verkeer is gedaald, het aantal conversies terugloopt of de laadtijd van je pagina is toegenomen. De rapporten maken duidelijk dát er iets is veranderd, maar zelden waarom.
Google Analytics laat in dat geval waarschijnlijk minder sessies zien. Performance tools kunnen aangeven dat pagina’s trager laden. Uptime monitoring bevestigt dat je site nog steeds online is. Elke tool laat een deel van het geheel zien, maar geen van hen verklaart wat de verandering daadwerkelijk heeft veroorzaakt.
De meeste analyticsplatforms richten zich op resultaten. Ze houden wat oppervlakkige cijfers bij zoals verkeer, betrokkenheid en prestatiescores. Deze cijfers helpen je trends te begrijpen, maar ze laten niet zien wat er gebeurt binnen de WordPress applicatie of de serveromgeving die de site aandrijft.
Met andere woorden, ze beschrijven de symptomen zonder de oorzaak te diagnosticeren. Om te begrijpen waarom er problemen optreden, heb je inzicht nodig in het systeem zelf. Dat is waar operationele gegevens belangrijk worden.
In dit artikel onderzoeken we waarom traditionele analysetools vaak stoppen bij rapportage op oppervlakteniveau, welke soorten gegevens de hoofdoorzaken blootleggen en hoe zichtbaarheid op hostingniveau de manier kan veranderen waarop WordPress prestaties en betrouwbaarheid worden beheerd.
Het verschil tussen resultaatanalyse en operationele analyses
De meeste analyticstools meten wat bezoekers aan de oppervlakte ervaren. Dit wordt vaak resultaatanalyse genoemd.
Resultaatanalyse houden statistieken bij zoals verkeersniveaus, betrokkenheid, laadtijden van pagina’s en zoekprestaties. Platforms zoals Google Analytics en veel tools voor het testen van de prestaties vallen in deze categorie. Ze helpen je te begrijpen hoe mensen met je site omgaan en of die ervaringen na verloop van tijd verbeteren of verslechteren.
Dit soort gegevens is handig om trends te ontdekken en marketingprestaties te evalueren. Wat het niet laat zien is wat er gebeurt binnen de WordPress applicatie of de serveromgeving die de site aandrijft.
Operationele analyses richten zich op het systeem achter de website. In plaats van bezoekersresultaten te meten, volgen ze signalen zoals aanvraagpatronen, serverbelasting, cachinggedrag, databaseprestaties en applicatiefouten. Deze statistieken laten zien hoe de site zich achter de schermen gedraagt.
Als de prestaties afnemen of er betrouwbaarheidsproblemen optreden, laten de resultaatanalyses het resultaat zien. Operationele analyses helpen de oorzaak te verklaren. Het effectief oplossen van WordPress problemen vereist meestal inzicht in beide lagen.
Waarom traditionele analysetools stoppen bij het symptoom
De meeste analyseplatforms zijn ontworpen om resultaten te rapporteren in plaats van systemen te diagnosticeren. Ze laten zien wat bezoekers ervoeren, hoe pagina’s presteerden en of de site online bleef. Die gegevens zijn nuttig voor het volgen van trends en het evalueren van prestaties, maar ze verklaren zelden wat een verandering heeft veroorzaakt.
Als de prestaties afnemen of er fouten optreden, benadrukken deze tools meestal het symptoom in plaats van het onderliggende probleem. De reden wordt duidelijker als je kijkt naar het soort gegevens dat ze verzamelen.
Ze meten gebruikersgedrag, niet systeemgedrag
Tools zoals Google Analytics richten zich op bezoekersactiviteiten. Ze houden statistieken bij zoals paginaweergaves, sessieduur, bouncepercentages en conversiepaden. Deze rapporten laten zien hoe mensen door je site bewegen, welke pagina’s de aandacht trekken en waar gebruikers afhaken.
Dit inzicht is waardevol voor marketing- en contentbeslissingen. Het onthult echter heel weinig over hoe WordPress of de server deze verzoeken hebben afgehandeld.
Analyticstools filteren ook veel bekende bots, maar hebben nog steeds moeite om geavanceerd geautomatiseerd verkeer te identificeren. Crawlers, scrapers en andere bots kunnen nog steeds verschijnen als sessies of paginaweergaves, wat betekent dat pieken in activiteit niet altijd een echte gebruikersvraag vertegenwoordigen.
Van buitenaf kan de site druk of langzaam lijken. Wat deze statistieken zelden laten zien is wat de server eigenlijk doet om die aanvragen af te handelen.
Prestatiecijfers tonen resultaten zonder context
Performance testing tools meten hoe snel pagina’s verschijnen en reageren voor bezoekers. Metrics als Largest Contentful Paint (LCP), Time to First Byte (TTFB) en frameworks als Core Web Vitals helpen je te controleren hoe snel een site aanvoelt vanuit het perspectief van de bezoeker.
Als deze cijfers verslechteren, geven ze aan dat er iets is veranderd. Prestatiemetingen wijzen echter zelden de oorzaak aan. Een hogere TTFB of langzamere LCP kan het gevolg zijn van veel onderliggende problemen, waaronder zware database queries, inefficiënte plugins, verkeerspieken, cachelagen die worden omzeild of beperkte server resources.
Het rapport toont de vertraging, maar laat meestal niet zien welk onderdeel de vertraging heeft veroorzaakt.
Monitoringstools richten zich alleen op uptime
Veel monitoringtools richten zich voornamelijk op beschikbaarheid door middel van uptimechecks.
Uptimemonitoring controleert of een site bereikbaar is en reageert op verzoeken. Dit helpt bij het detecteren van volledige uitval en bevestigt of de service online is.
Uptime is echter een botte meting. Een site kan technisch online blijven en toch trage antwoorden, irriterende fouten of verminderde prestaties leveren. Deze problemen verschijnen vaak lang voordat een volledige uitval optreedt.
Omdat uptimemonitoring zich richt op beschikbaarheid in plaats van systeemgedrag, geeft het beperkt inzicht in de omstandigheden die leiden tot vertragingen of storingen.
Waarom het oplossen van WordPress prestaties vaak giswerk wordt
Als analyticsprogramma’s alleen symptomen laten zien, wordt het oplossen van problemen een proces van eliminatie.
Je ziet eerst het effect: tragere pagina’s, lagere conversies of een plotselinge piek in de reactietijden van de server. Maar omdat de meeste dashboards niet laten zien wat de infrastructuur doet, blijft de echte oorzaak verborgen.
Site-eigenaren moeten vaak springen tussen verschillende tools om een theorie samen te stellen. Analyticsplatforms tonen veranderingen in het verkeer, prestatie-instrumenten benadrukken langzamere laadtijden en uptime-monitors bevestigen dat de site nog steeds online is. Elk hulpmiddel toont een klein deel van de puzzel, maar geen enkel geeft de volledige verklaring.
In de praktijk komen prestatieproblemen bij WordPress vaak neer op een handvol veelvoorkomende scenario’s:
- Verkeerspieken overweldigen PHP threads: WordPress genereert pagina’s dynamisch. Als er te veel aanvragen tegelijk binnenkomen, raken de beschikbare PHP threads overbelast, waardoor aanvragen in een wachtrij komen en laadtijden toenemen.
- Inefficiënte database queries geïntroduceerd door een plugin-update: Een plugin-update of nieuwe feature kan slecht geoptimaliseerde queries toevoegen die de database plotseling zwaarder belasten.
- Cachelagen die er niet in slagen om veelgevraagde pagina’s te leveren: Als caching niet meer goed werkt of wordt omzeild, moet de server pagina’s herhaaldelijk opnieuw opbouwen in plaats van cacheversies te serveren.
- Bots die overmatig veel aanvragen genereren: Geautomatiseerd verkeer van crawlers, scrapers of kwaadwillende bots kan grote hoeveelheden aanvragen genereren die de systeembronnen belasten. In veel analyseplatforms verschijnt dit verkeer nog steeds in dashboards als bezoeken of sessies, waardoor verkeerspieken legitiem kunnen lijken, zelfs als ze niet door echte gebruikers worden veroorzaakt.
- Achtergrondtaken die serverbronnen opslokken: Geplande taken, imports, backups of indexeringsprocessen kunnen stilletjes CPU en geheugen op de achtergrond verbruiken.
Zonder inzicht in het gedrag van de server is het meestal met vallen en opstaan om de hoofdoorzaak te achterhalen. Teams schakelen plugins uit, bekijken logbestanden of voeren prestatietests uit om het probleem te isoleren. In veel gevallen vereist het oplossen van het probleem onderzoek door ontwikkelaars, simpelweg omdat de beschikbare analysetools niet laten zien wat het systeem werkelijk doet (of waaraan het wordt blootgesteld).
Hoe echte diagnostische analytics eruit zien bij WordPress hosting
Operationele analytics richten zich op hoe een WordPress site zich achter de schermen gedraagt. In plaats van alleen te rapporteren wat bezoekers ervaren, wordt bijgehouden hoe de applicatie en infrastructuur reageren op echt verkeer in realtime.
Dit soort zichtbaarheid maakt van analytics een hulpmiddel om problemen op te lossen. Wanneer de prestaties veranderen, kunnen de gegevens direct naar de onderliggende oorzaak wijzen in plaats van teams blindelings op onderzoek uit te laten gaan.
Verschillende soorten statistieken zijn bijzonder nuttig bij het diagnosticeren van WordPress prestatieproblemen.
Aanvraagvolume en verkeerspatronen
Gegevens over aanvragen laten zien hoeveel aanvragen de server verwerkt en wanneer die aanvragen plaatsvinden. Verkeer komt zelden aan in een perfect gestage stroom. Pieken tijdens productlanceringen, marketingcampagnes of zoekmachine crawls kunnen de vraag op de server snel doen toenemen.
Als je de aanvraagpatronen ziet, is het makkelijker om te begrijpen of een vertraging te maken heeft met een toename van legitiem verkeer of met geautomatiseerde aanvragen die worden gegenereerd door bots en crawlers.
PHP threads gebruik
WordPress vertrouwt op PHP om dynamische pagina’s te genereren. Elk inkomend verzoek vereist een PHP thread om de code te verwerken en de pagina af te leveren.
Als de vraag groter is dan het aantal beschikbare threads, komen de verzoeken in een wachtrij. Bezoekers kunnen tragere laadtijden ervaren, ook al blijft de site technisch online.
Analytics die het gebruik van PHP threads bijhouden, maken deze knelpunten zichtbaar en laten zien wanneer de applicatie zijn verwerkingslimieten nadert of bereikt.
Cache-efficiëntie
Caching speelt een grote rol bij de prestaties van WordPress. Wanneer pagina’s in de cache staan, kan de server ze direct afleveren zonder WordPress te starten of de database te bevragen.
Operationele analytics die de cache hit en miss ratio’s laten zien, laten zien of caching werkt zoals verwacht. Een plotselinge toename in cache misses geeft vaak aan dat er onnodig dynamische verzoeken worden gegenereerd, wat de serverbelasting kan verhogen en de aflevering van pagina’s kan vertragen.
Foutopsporing en responscodes
Server responscodes en foutenlogboeken bieden een andere belangrijke laag diagnostische gegevens.
Het bijhouden van HTTP responses zoals 500 errors, samen met PHP waarschuwingen of applicatiefouten, kan snel falende processen onthullen. In veel gevallen wijzen deze signalen direct naar een zich misdragende plugin, themaconflict of script dat het probleem veroorzaakt.
Waarom analyses op hostingniveau oorzaken tonen in plaats van symptomen
Front-end analysetools laten zien wat bezoekers ervaren nadat een pagina is geladen. Hostinganalyses kijken naar wat er in het systeem gebeurt voordat de resultaten verschijnen in de statistieken voor de gebruiker.
Omdat ze de infrastructuur zelf observeren, kunnen hostinganalytics veranderingen in de prestaties van de site koppelen aan de activiteit die ze heeft veroorzaakt.
Deze zichtbaarheid maakt verschillende dingen veel gemakkelijker te identificeren.
- Verkeerspieken in verband brengen met het gebruik van serverresources: Als het verkeer plotseling toeneemt, kunnen serverresources zoals CPU, geheugen of PHP threads verzadigd raken. Hostinganalyses maken het mogelijk om te zien of de stijgende vraag direct samengaat met prestatievertragingen.
- Identificeren wanneer niet-gecachete verzoeken de verwerkingsbelasting verhogen: Als pagina’s in de cache niet meer correct worden weergegeven, moet de server elke pagina dynamisch genereren. Analytics die het gedrag van de cache bijhouden, kunnen onthullen wanneer ongecacheerde verzoeken meer verwerkingskracht beginnen te verbruiken.
- Trage PHP-uitvoering of databaseproblemen opsporen: Sommige prestatieproblemen ontstaan door inefficiënte code of database queries. Metrics op infrastructuurniveau helpt bij het ontdekken van trage uitvoeringspatronen die niet verschijnen in standaard analytics dashboards.
- Botverkeer of kwaadaardige verzoeken eerder opsporen: Geautomatiseerd verkeer kan grote hoeveelheden aanvragen genereren lang voordat het duidelijk wordt in bezoekersrapporten. Hostinganalyses maken het eenvoudiger om ongebruikelijke verkeerspatronen te herkennen en te reageren voordat de prestaties verslechteren.
Met dit niveau van zichtbaarheid zijn analytics meer dan alleen rapportagetools en laten ze je actief weten welk onderdeel van het systeem is veranderd, zodat je de oorzaak direct kunt onderzoeken.
Analytics als operationele tool
Veel organisaties behandelen analytics primair als een marketingtool. Teams gebruiken dashboards om campagnes bij te houden, SEO-prestaties te monitoren en de interactie tussen bezoekers en de site te analyseren.
Deze inzichten zijn waardevol, maar analytics kan een veel bredere rol vervullen.
Als de analytics ook inzicht geven op systeemniveau, worden ze onderdeel van de operationele toolkit die wordt gebruikt om de gezondheid en prestaties van een WordPress site te beheren. In plaats van alleen resultaten te meten, helpen de gegevens teams te begrijpen hoe de applicatie en infrastructuur zich gedragen onder echte omstandigheden.
Dit soort operationele inzichten helpt teams:
- Prestatieproblemen snel te diagnosticeren
- De grenzen van de infrastructuur begrijpen
- Problemen detecteren voordat ze uitvallen
- Geïnformeerde beslissingen te nemen over schalen
Wanneer analytics dit niveau van systeemzichtbaarheid bieden, worden ze onderdeel van het dagelijkse beheer van een WordPress omgeving en niet zomaar een set rapportagedashboards waar je periodiek een blik op werpt.
Hoe analytics van managed hosting dieper inzicht geeft
Moderne managed hostingplatforms bieden steeds meer analyses die verder gaan dan de basic uptime- en verkeersrapportage. In plaats van alleen oppervlakkige statistieken te tonen, laten ze zien hoe de infrastructuur die een WordPress site ondersteunt zich gedraagt onder echte verkeersomstandigheden.
Dit soort zichtbaarheid helpt teams om gebruikersproblemen te koppelen aan wat er binnen het systeem gebeurt.
Nuttige analyses op hostingniveau bevatten vaak gegevens zoals:
- Trends in aanvragen en bandbreedte: Laat zien hoe verkeersniveaus in de loop van de tijd veranderen en hoeveel aanvragen de server verwerkt tijdens piekperioden.
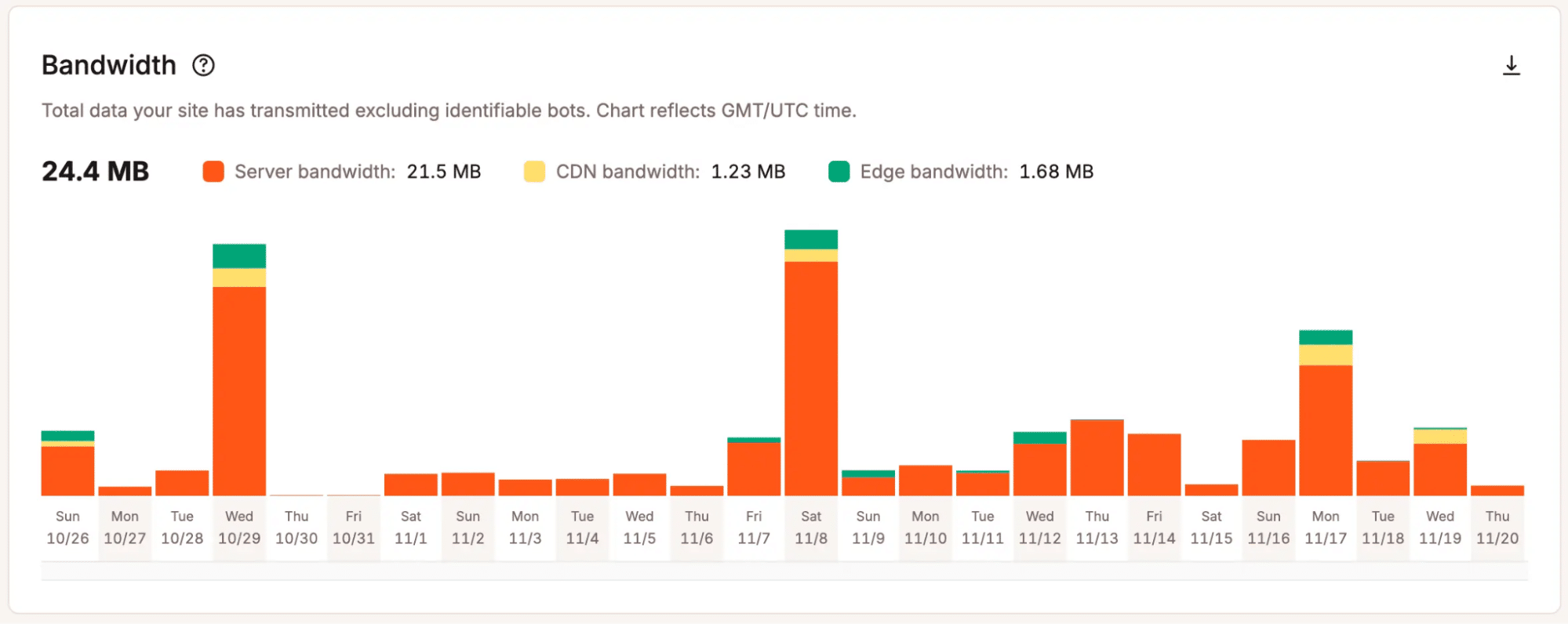
Bekijk bandbreedtegebruik in MyKinsta. - Gegevens over cacheprestaties: Toont of pagina’s efficiënt uit de cache worden geserveerd of dat dynamische verzoeken de verwerkingsbelasting verhogen.
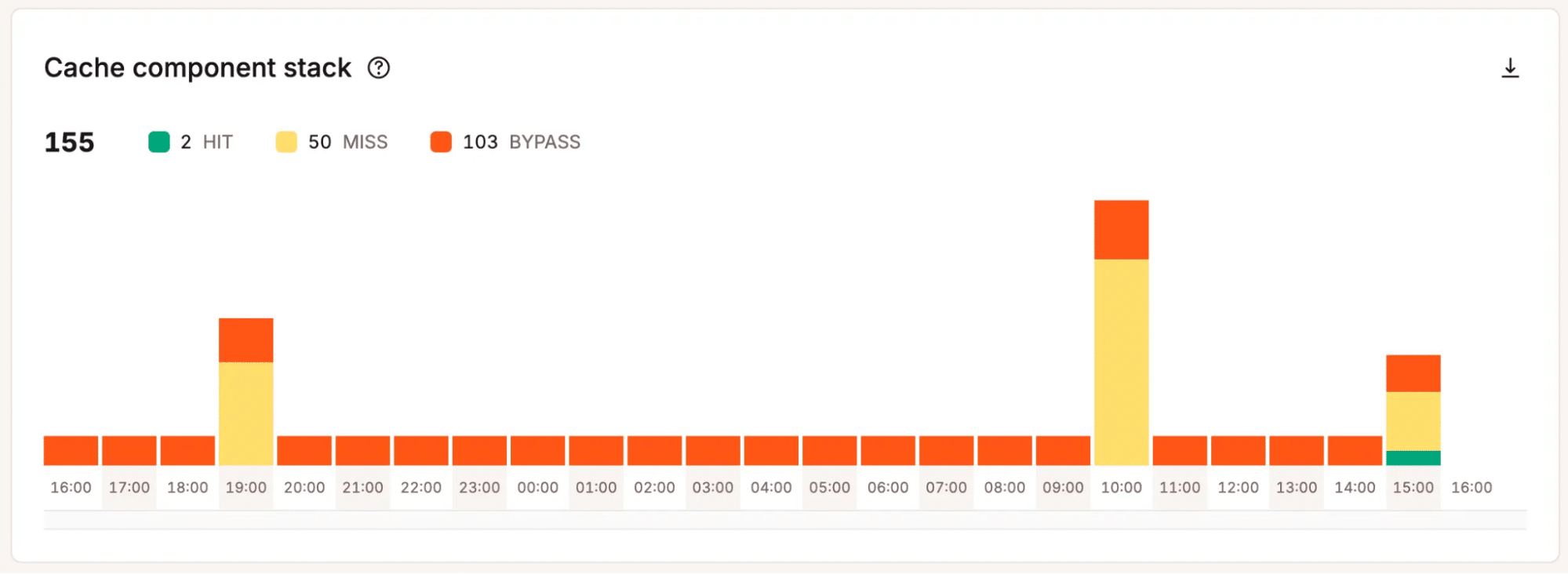
Inzicht krijgen in cacheprestaties in MyKinsta. - PHP threads activiteit: Geeft aan hoe intensief WordPress beschikbare PHP threads gebruikt en of verzoeken in de wachtrij beginnen te komen.
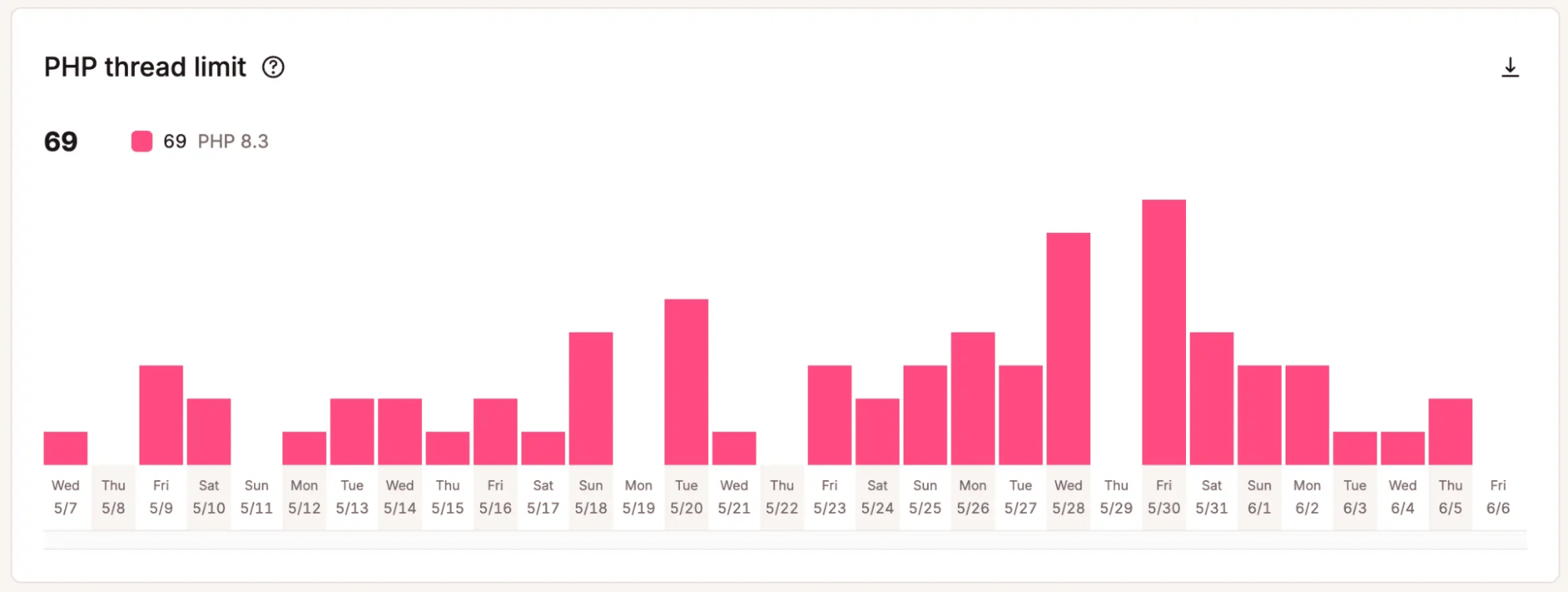
Krijg inzicht in PHP threads activiteit in MyKinsta. - Databank gebruikspatronen: Markeert query-activiteit en databasebelasting, wat inefficiënte code of plugingedrag kan laten zien.
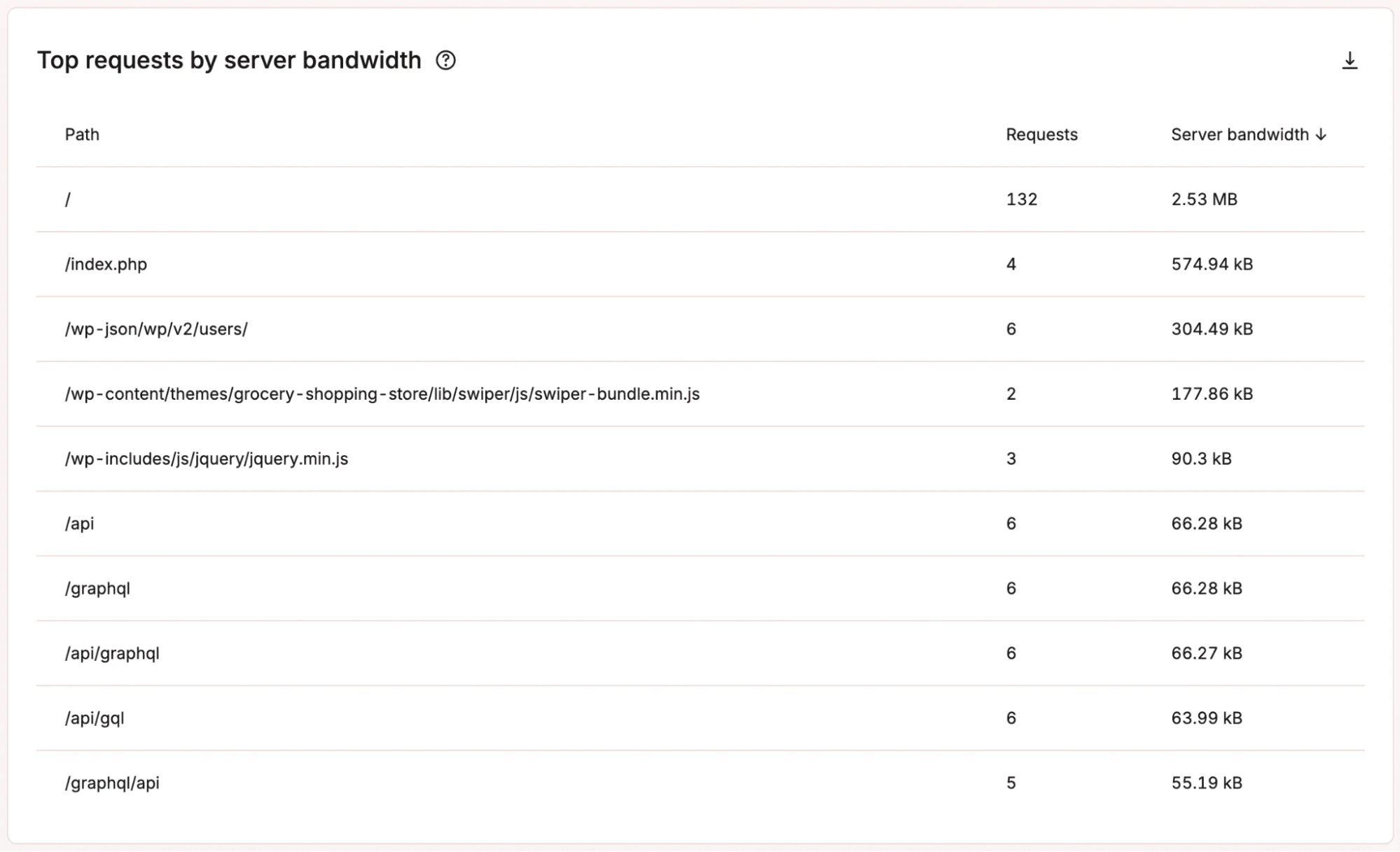
Bekijk de topverzoeken per serverbandbreedte in MyKinsta. - Responscode monitoring: Volgt HTTP-statuscodes om fouten of falende processen aan het licht te brengen voordat ze escaleren tot grotere problemen.
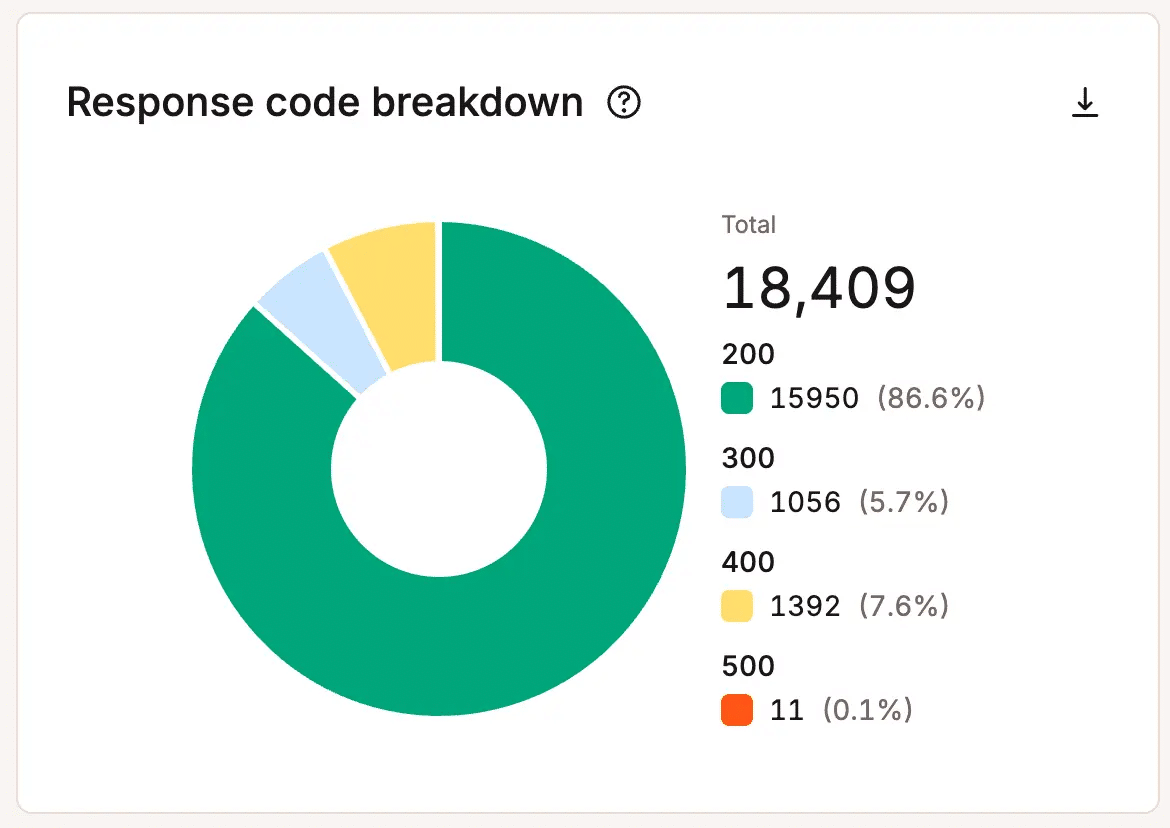
HTTP-statuscodes volgen om fouten te zien voordat ze grotere problemen veroorzaken. - Geografische verkeersverdeling: Helpt te identificeren waar verzoeken vandaan komen en of ongebruikelijke verkeerspatronen de prestaties kunnen beïnvloeden.
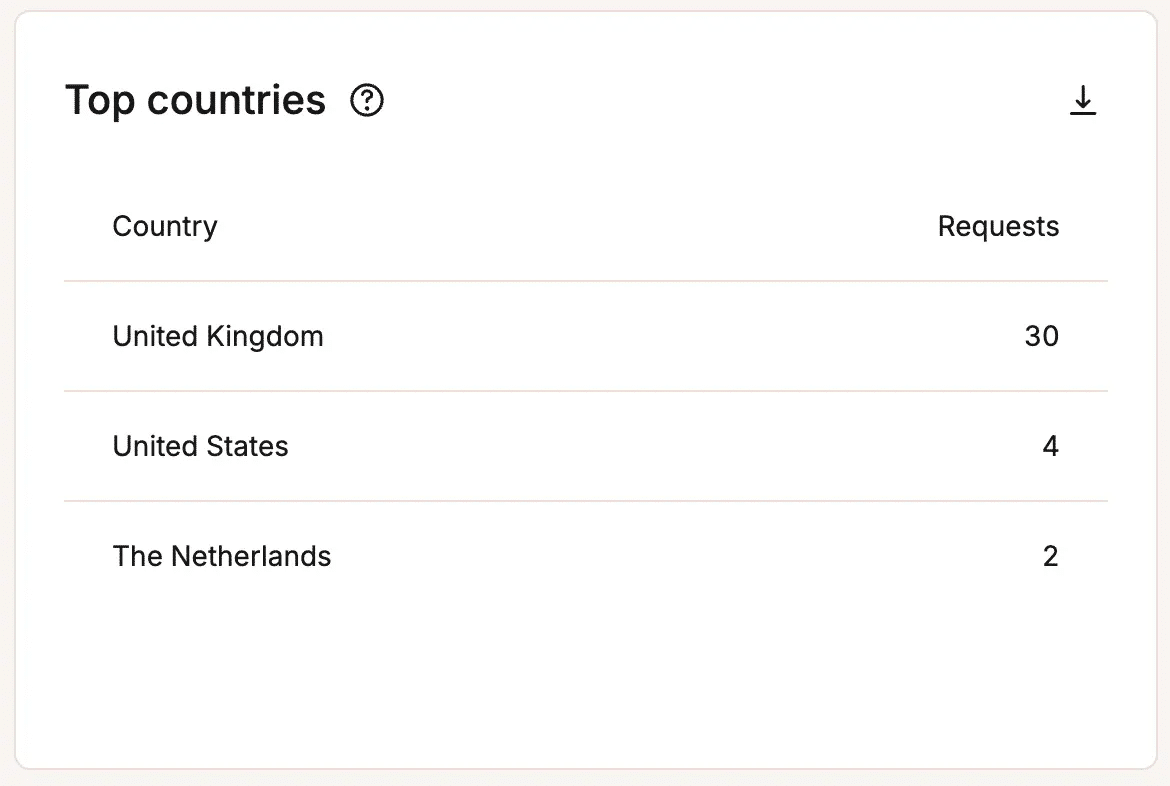
Geografische verkeersverdeling in MyKinsta identificeren.
Het MyKinsta dashboard is ontworpen rond dit soort zichtbaarheid op infrastructuurniveau. In plaats van hosting te behandelen als een zwarte doos, laat het operationele metrics zien die aantonen hoe een WordPress site interageert met het onderliggende platform.
Je kunt meer van deze statistieken bekijken in onze documentatie. Site-eigenaren en ontwikkelteams kunnen dan verder gaan dan oppervlakkige rapportages en beginnen met het diagnosticeren van prestatieveranderingen direct binnen de hostingomgeving.
Weten wat er is gebeurd is niet genoeg
De meeste analysetools zijn uitstekend in het tonen van resultaten. Maar als de prestaties afnemen of er betrouwbaarheidsproblemen optreden, vertellen die rapporten maar een deel van het verhaal.
Platforms als Kinsta maken dit soort inzicht makkelijker toegankelijk. De analyses die beschikbaar zijn in het MyKinsta dashboard laten zien hoe een WordPress site zich gedraagt op infrastructuurniveau, waardoor ontwikkelaars, bureaus en site-eigenaren duidelijker inzicht krijgen in prestaties en betrouwbaarheid.
Als je analyses wilt die niet alleen uitleggen wat er is gebeurd, maar ook waarom, kijk dan eens naar de managed WordPress hostingpakketten van Kinsta. Er is nog nooit een beter moment geweest dan nu om controle te nemen over de activiteiten van je site.


