
Zoals elke site-eigenaar je waarschijnlijk zal vertellen, kunnen gegevensverlies en downtime catastrofaal zijn – zelfs in minimale doses. Ze kunnen zonder aankondiging ieder moment toeslaan, met verminderde productiviteit, toegankelijkheid en vertrouwen in je product of dienst als gevolg.
Om de integriteit van je site te beschermen, is het van vitaal belang beveiligingen in te bouwen tegen de mogelijkheid van downtime of gegevensverlies.
Dat is waar gegevensreplicatie om de hoek komt kijken.
Gegevensreplicatie is een geautomatiseerd back-upproces waarbij je gegevens herhaaldelijk vanuit de hoofddatabank naar een andere, afgelegen plaats worden gekopieerd om veilig bewaard te worden. Het is een integrale technologie voor elke site of app met een databaseserver. Je kunt de gerepliceerde database ook gebruiken om read-only SQL te verwerken, waardoor meer processen in het systeem kunnen draaien.
Het opzetten van replicatie tussen twee databases biedt fouttolerantie tegen onverwachte ongelukken. Het wordt beschouwd als de beste strategie om hoge beschikbaarheid te bereiken bij rampen.
In dit artikel duiken we in de verschillende strategieën die backend ontwikkelaars kunnen toepassen voor naadloze PostgreSQL replicatie.
Wat is PostgreSQL replicatie?
PostgreSQL replicatie kan je definiëren als het proces van het kopiëren van gegevens van een PostgreSQL databaseserver naar een andere server. De bron-databaseserver wordt ook wel de “primaire” server genoemd, terwijl de databaseserver die de gekopieerde gegevens ontvangt bekend staat als de “replica” server.
De PostgreSQL database volgt een rechtlijnig replicatiemodel, waarbij alle writes naar een primaire node gaan. De primaire node kan deze veranderingen dan toepassen en naar de secundaire nodes versturen.
Wat is een automatische failover?
Failover is een methode om gegevens te herstellen als de primaire server het om welke reden dan ook begeeft. Zolang je PostreSQL hebt geconfigureerd om je fysieke streaming replicatie te beheren, zullen jij – en je gebruikers – beschermd zijn tegen downtime als gevolg van een primaire server snafu.
Merk op dat het opzetten en opstarten van het failoverproces enige tijd in beslag kan nemen. Er zijn geen ingebouwde hulpmiddelen om serverfouten in PostgreSQL te monitoren en te scopen, dus je zult creatief moeten zijn.
Gelukkig hoeft je niet afhankelijk te zijn van PostgreSQL voor failover. Er zijn speciale tool die automatische failover en automatisch overschakelen naar de stand-by mogelijk maken, waardoor de downtime van de database korter wordt.
Door failover replicatie in te stellen, garandeer je bijna hoge beschikbaarheid door ervoor te zorgen dat stand-by’s beschikbaar zijn als de primaire server ooit instort.
Voordelen van het gebruik van PostgreSQL replicatie
Hier zijn een paar belangrijke voordelen van het gebruik van PostgreSQL replicatie:
- Gegevensmigratie: Je kunt PostgreSQL replicatie gebruiken voor gegevensmigratie, hetzij door een verandering van databaseserver hardware, hetzij door systeeminzet.
- Fouttolerantie: Als de primaire server uitvalt, kan de stand-by server als server fungeren omdat de bevatte gegevens voor zowel primaire als stand-by servers dezelfde zijn.
- Prestaties voor online transactieverwerking (OLTP): Je kunt de transactieverwerkingstijd en de querytijd van een OLTP systeem verbeteren door rapportage van querybelasting weg te nemen. Transactieverwerkingstijd is de duur die het kost om een bepaalde query uit te voeren voordat een transactie klaar is.
- Paralleltesten van systemen: Bij het upgraden van een nieuw systeem moet je er zeker van zijn dat het systeem goed overweg kan met bestaande gegevens, vandaar de noodzaak om vóór de invoering te testen met een productie database kopie.
Hoe PostgreSQL replicatie werkt
Over het algemeen geloven mensen dat wanneer je met een primaire en secundaire architectuur rommelt, er maar één manier is om backups en replicatie op te zetten. PostgreSQL deployments kunnen echter elk van deze drie methoden volgen:
- Streaming replicatie: repliceert gegevens van de primaire node naar het secundaire, kopieert vervolgens gegevens naar Amazon S3 of Azure Blob voor backupopslag.
- Volume-level replicatie: Repliceert gegevens op de opslaglaag, vanaf de primaire node naar de secundaire node, kopieert vervolgens gegevens naar Amazon S3 of Azure Blob voor backupopslag.
- Incrementele backups: repliceert gegevens van de primaire node terwijl een nieuwe secundaire node wordt gebouwd vanuit Amazon S3 of Azure Blob opslag, waardoor streaming rechtstreeks vanaf de primaire node mogelijk wordt.
Methode 1: streaming
PostgreSQL streaming replicatie, ook bekend als WAL replicatie, kan naadloos opgezet worden nadat PostgreSQL op alle servers geïnstalleerd is. Deze aanpak van replicatie is gebaseerd op het verplaatsen van de WAL bestanden van de primaire naar de doeldatabase.
Je kunt PostgreSQL streaming replicatie implementeren door een primair-secundaire configuratie te gebruiken. De primaire server is de hoofdinstantie die de primaire database en al zijn bewerkingen afhandelt. De secundaire server fungeert als aanvullende instantie en voert alle veranderingen aan de primaire database op zichzelf uit, waarbij hij een identieke kopie genereert. De primaire is de lees/schrijf-server terwijl de secundaire server alleen-lezen is.
Voor deze methode moet je zowel de primaire node als de standby node configureren. De volgende secties zullen de stappen verduidelijken die nodig zijn om ze gemakkelijk in te stellen.
Het instellen van de primaire node
Je kunt de primaire node instellen voor streaming replicatie door de volgende stappen uit te voeren:
Stap 1: Initialiseer de database
Om de database te initialiseren, kun je gebruik maken van het initdb utility commando. Vervolgens kun je een nieuwe gebruiker met replicatiebevoegdheden maken met behulp van de volgende opdracht:
CREATE USER 'example_username' REPLICATION LOGIN ENCRYPTED PASSWORD 'example_password';De gebruiker zal een wachtwoord en een gebruikersnaam moeten opgeven voor de gegeven query. Het replicatie keyword wordt gebruikt om de gebruiker de vereiste rechten te geven. Een voorbeeld query zou er ongeveer zo uitzien:
CREATE USER 'rep_username' REPLICATION LOGIN ENCRYPTED PASSWORD 'rep_password';Stap 2: Streaming eigenschappen configureren
Vervolgens kun je de streaming eigenschappen configureren met het PostgreSQL configuratiebestand (postgresql.conf) dat als volgt gewijzigd kan worden:
wal_level = logical
wal_log_hints = on
max_wal_senders = 8
max_wal_size = 1GB
hot_standby = onHier volgt wat achtergrondinformatie rond de parameters die in de vorige snippet gebruikt werden:
wal_log_hints: Deze parameter is nodig voor depg_rewindcapability die van pas komt als de stand-by server niet meer synchroon loopt met de primaire server.wal_level: Je kunt deze parameter gebruiken om PostgreSQL streaming replicatie in te schakelen, met mogelijke waarden alsminimal,replica, oflogical.max_wal_size: Hiermee kun je de grootte opgeven van de WAL bestanden die in logbestanden kunnen worden bewaard.hot_standby: Je kunt deze parameter gebruiken voor een read-on verbinding met de secundaire als hij op ON is gezet.max_wal_senders: Je kuntmax_wal_sendersgebruiken om het maximum aantal gelijktijdige verbindingen op te geven dat met de stand-by servers tot stand kan worden gebracht.
Stap 3: Maak een nieuwe entry
Nadat je de parameters in het postgresql.conf bestand gewijzigd hebt, kun je met een nieuwe replicatie entry in het pg_hba.conf bestand de servers in staat stellen een verbinding met elkaar op te zetten voor replicatie.
Je vindt dit bestand meestal in de data map van PostgreSQL. Je kunt hiervoor het volgende codefragment gebruiken:
host replication rep_user IPaddress md5Zodra het codefragment wordt uitgevoerd, staat de primaire server een gebruiker genaamd rep_user toe verbinding te maken en als de stand-by server te fungeren door het opgegeven IP te gebruiken voor replicatie. Bijvoorbeeld:
host replication rep_user 192.168.0.22/32 md5Stand-by node instellen
Om de stand-by node in te stellen voor streaming replicatie, volg je deze stappen:
Stap 1: Maak een backup van de primaire node
Om de standby node in te stellen, maak je gebruik van de pg_basebackup tool om een backup van de primaire node te genereren. Deze zal dienen als startpunt voor de stand-by node. Je kunt dit hulpprogramma gebruiken met de volgende syntaxis:
pg_basebackp -D -h -X stream -c fast -U rep_user -WDe parameters die in de bovenstaande syntaxis gebruikt worden zijn als volgt:
-h: Je kunt dit gebruiken om de primaire host te vermelden.-D: Deze parameter geeft de directory aan waarin je momenteel werkt.-C: Je kunt dit gebruiken om de checkpoints in te stellen.-X: Deze parameter kun je gebruiken om de nodige transactielogbestanden op te nemen.-W: Je kunt deze parameter gebruiken om de gebruiker om een wachtwoord te vragen voordat hij verbinding maakt met de database.
Stap 2: Replicatie configuratiebestand instellen
Vervolgens moet je controleren of het replicatie configuratiebestand bestaat. Als dat niet zo is, kun je het replicatie configuratiebestand genereren als recovery.conf.
Je moet dit bestand aanmaken in de gegevensmap van de PostgreSQL installatie. Je kunt het automatisch genereren door de -R optie te gebruiken binnen de tool pg_basebackup.
Het recovery.conf bestand moet de volgende commando’s bevatten:
standby_mode = 'on'primary_conninfo = 'host=<master_host> port=<postgres_port> user=<replication_user> password=<password> application_name="host_name"'recovery_target_timeline = 'latest'
De parameters die in de bovengenoemde commando’s gebruikt worden zijn als volgt:
primary_conninfo: Je kunt dit gebruiken om een verbinding te maken tussen de primaire en secundaire servers door gebruik te maken van een verbindingsstring.standby_mode: Deze parameter kan ervoor zorgen dat de primaire server als stand-by start als hij ingeschakeld wordt.recovery_target_timeline: Je kunt dit gebruiken om de hersteltijd in te stellen.
Om een verbinding op te zetten moet je de gebruikersnaam, het IP adres, en het wachtwoord opgeven als waarden voor de parameter primary_conninfo. Bijvoorbeeld:
primary_conninfo = 'host=192.168.0.26 port=5432 user=rep_user password=rep_pass'Stap 3: Herstart de secundaire server
Tenslotte kun je de secundaire server herstarten om het configuratieproces te voltooien.
Streaming replicatie komt echter met verschillende uitdagingen, zoals:
- Verschillende PostgreSQL clients (geschreven in verschillende programmeertalen) converseren met een enkel eindpunt. Als de primaire node uitvalt, blijven deze clients dezelfde DNS of IP naam opnieuw proberen. Dit maakt failover zichtbaar voor de toepassing.
- PostgreSQL replicatie wordt niet geleverd met ingebouwde failover en monitoring. Als de primaire node faalt, moet je een secundaire promoveren tot de nieuwe primaire. Deze promotie moet zo worden uitgevoerd dat cliënten naar slechts één primaire node schrijven, en ze geen inconsistenties in de gegevens waarnemen.
- PostgreSQL repliceert zijn hele toestand. Als je een nieuwe secundaire node moet ontwikkelen, moet de secundaire de hele geschiedenis van toestandsverandering van de primaire node herhalen, wat veel middelen kost en het kostbaar maakt om nodes in de kop te elimineren en nieuwe te maken.
Methode 2: Replicated block device
De replicated block device benadering maakt gebruik van disk mirroring (ook bekend als volumereplicatie). Bij deze aanpak worden veranderingen naar een persistent volume geschreven dat synchroon naar een ander volume gespiegeld wordt.
Het extra voordeel van deze aanpak is de compatibiliteit en de duurzaamheid van de gegevens in cloudomgevingen met alle relationele databases, waaronder PostgreSQL, MySQL, en SQL Server, om er een paar te noemen.
De disk-mirroring aanpak van PostgreSQL replicatie vereist echter dat je zowel WAL log- als tabelgegevens repliceert. Omdat elk schrijven naar de database nu synchroon over het netwerk moet gaan, kun je je niet veroorloven ook maar een enkele byte te verliezen, want dat zou je database in een corrupte toestand kunnen achterlaten.
Deze aanpak wordt gewoonlijk toegepast met Azure PostgreSQL en Amazon RDS.
Methode 3: WAL
WAL bestaat uit segmentbestanden (standaard 16 MB). Elk segment heeft een of meer records. Een log sequence record (LSN) is een pointer naar een record in WAL, die je de positie/plaats laat weten waar het record in het logbestand is opgeslagen.
Een stand-by server maakt gebruik van WAL segmenten – in PostgreSQL terminologie ook wel XLOGS genoemd – om voortdurend veranderingen van zijn primaire server te repliceren. Je kunt write-ahead logging gebruiken om duurzaamheid en atomiciteit in een DBMS te verlenen door blokken van byte-array gegevens (elk met een unieke LSN) te serialiseren naar stabiele opslag voordat ze in een database worden toegepast.
Het toepassen van een mutatie op een database kan leiden tot verschillende bewerkingen aan het bestandssysteem. Een vraag die opkomt is hoe een database atomiciteit kan garanderen bij een serverstoring door een stroomstoring terwijl hij midden in een bestandssysteemupdate zat. Als een database opstart, begint hij een startup- of replayproces dat de beschikbare WAL segmenten kan lezen en ze vergelijkt met de LSN die op elke gegevenspagina zijn opgeslagen (elke gegevenspagina is gemarkeerd met de LSN van het laatste WAL record dat op de pagina betrekking heeft).
Log shipping-gebaseerde replicatie (blokniveau)
Streaming replicatie verfijnt het log shipping proces. In plaats van te wachten op de WAL switch, worden de records verzonden terwijl ze worden aangemaakt, waardoor de replicatie vertraging afneemt.
Streaming replicatie overtroeft ook log shipping omdat de standby server over het netwerk met de primaire server in verbinding staat door gebruik te maken van een replicatieprotocol. De primaire server kan dan WAL records direct over deze verbinding versturen zonder afhankelijk te zijn van door de eindgebruiker verstrekte scripts.
Log shipping-gebaseerde replicatie (bestandsniveau)
Log shipping wordt gedefinieerd als het kopiëren van logbestanden naar een andere PostgreSQL server om een andere stand-by server te genereren door WAL bestanden opnieuw af te spelen. Deze server is geconfigureerd om in herstelmodus te werken, en zijn enige doel is om eventuele nieuwe WAL bestanden toe te passen als ze opduiken.
Deze secundaire server wordt dan een warme backup van de primaire PostgreSQL server. Hij kan ook ingesteld worden als leesreplica, waarbij hij alleen-lezen queries kan aanbieden, ook wel hot stand-by genoemd.
Continu WAL archivering
Het kopiëren van WAL bestanden terwijl ze gemaakt worden naar een andere plaats dan de pg_wal subdirectory om ze te archiveren wordt WAL archivering genoemd. PostgreSQL zal een door de gebruiker gegeven script aanroepen om te archiveren, telkens als een WAL bestand wordt aangemaakt.
Het script kan gebruik maken van het scp commando om het bestand te dupliceren naar een of meer plaatsen, zoals een NFS mount. Eenmaal gearchiveerd kunnen de WAL segmentbestanden gebruikt worden om de database op elk willekeurig moment te herstellen.
Andere log-gebaseerde configuraties zijn onder andere:
- Synchrone replicatie: Voordat elke synchrone replicatietransactie vastgelegd wordt, wacht de primaire server tot stand-by’s bevestigen dat ze de gegevens gekregen hebben. Het voordeel van deze configuratie is dat er geen conflicten ontstaan door parallelle schrijfprocessen.
- Synchrone replicatie met meerdere masters: Hier kan elke server schrijfverzoeken aannemen, en gewijzigde gegevens worden van de oorspronkelijke server naar elke andere server doorgestuurd voordat elke transactie vastgelegd wordt. Het maakt gebruik van het 2PC protocol en houdt zich aan de alles-of-niets regel.
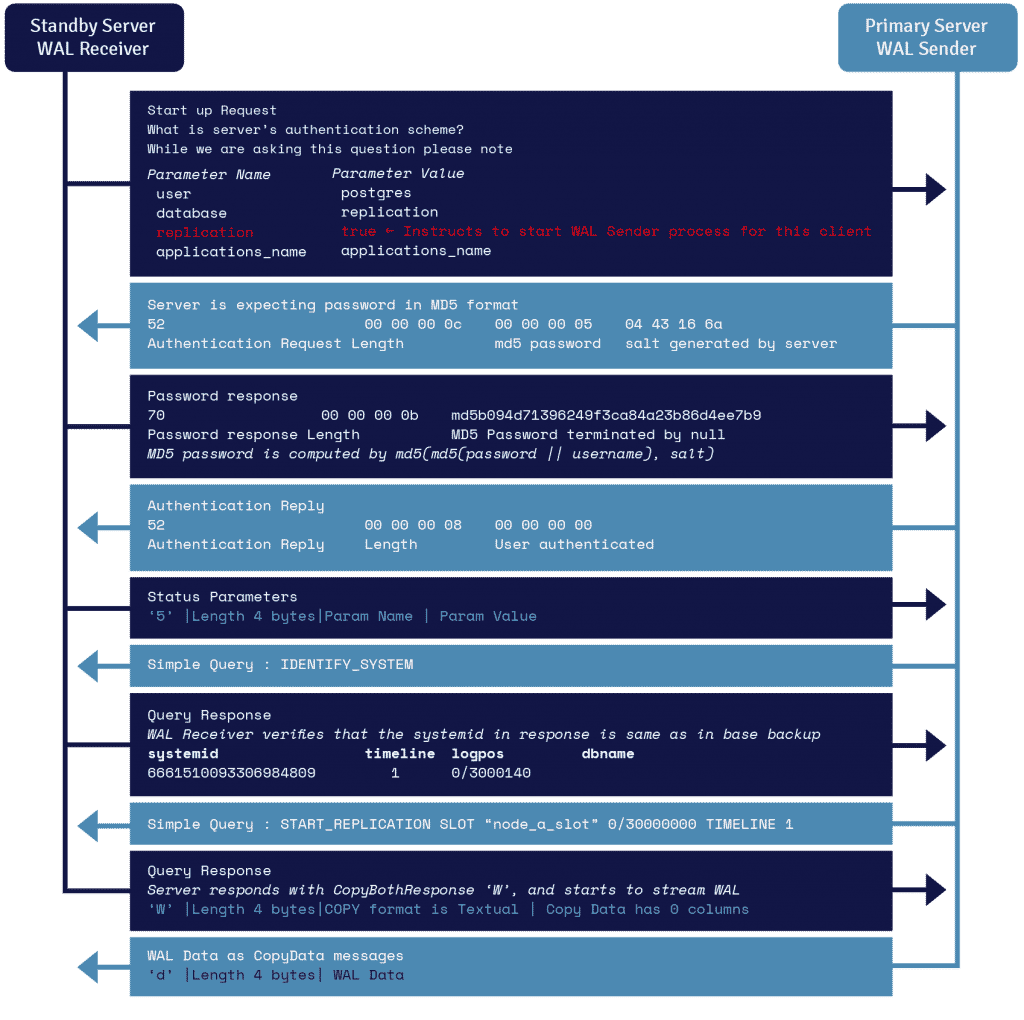
Gegevens van het WAL streaming protocol
Een proces bekend als WAL receiver, dat op de stand-by server draait, maakt gebruik van de verbindingsgegevens die in de primary_conninfo parameter van recovery.conf staan en verbindt zich met de primaire server door gebruik te maken van een TCP/IP verbinding.
Om streaming replicatie te starten kan het frontend binnen het opstartbericht de replicatie parameter zenden. Een Booleaanse waarde van true, yes, 1, of ON laat de backend weten dat hij in fysieke replicatie WAL sender mode moet gaan.
WAL sender is weer een ander proces dat op de primaire server draait en belast is met het verzenden van de WAL records naar de stand-by server als ze gegenereerd worden. De WAL ontvanger bewaart de WAL records in WAL alsof ze door clientactiviteit van lokaal verbonden clients zijn aangemaakt.
Zodra de WAL records de WAL segmentbestanden bereiken, blijft de stand-by server voortdurend de WAL herhalen, zodat primaire en stand-by synchroon lopen.
Elementen van PostgreSQL replicatie
In dit onderdeel krijg je een dieper inzicht in de veelgebruikte modellen (single-master en multi-master replicatie), typen (fysieke en logische replicatie), en modi (synchroon en asynchroon) van PostgreSQL replicatie.
Modellen van PostgreSQL databasereplicatie
Schaalbaarheid betekent het toevoegen van meer resources/hardware aan bestaande nodes om de mogelijkheden van de database te vergroten om meer gegevens op te slaan en te verwerken, wat horizontaal en verticaal kan worden bereikt. PostgreSQL replicatie is een voorbeeld van horizontale schaalbaarheid die veel moeilijker te realiseren is dan verticale schaalbaarheid. We kunnen horizontale schaalbaarheid vooral bereiken door single-master replicatie (SMR) en multi-master replicatie (MMR).
Met single-master replicatie kunnen gegevens alleen op een enkele node gewijzigd worden, en deze wijzigingen worden naar een of meer nodes gerepliceerd. De gerepliceerde tabellen in de replica database mogen geen wijzigingen aannemen, behalve die van de primaire server. Zelfs als ze dat wel doen, worden de wijzigingen niet naar de primaire server gerepliceerd.
Meestal is SMR voldoende voor de toepassing omdat het minder ingewikkeld is om in te stellen en te beheren, met geen kans op conflicten. Single-master replicatie is ook unidirectioneel, omdat de replicatiegegevens hoofdzakelijk in één richting stromen, van de primaire naar de replica database.
In sommige gevallen kan SMR alleen niet voldoende zijn, en moet je MMR implementeren. MMR staat toe dat meer dan één node als primaire node fungeert. Veranderingen aan tabelrijen in meer dan één aangewezen primair gegevensbestand worden gerepliceerd naar hun pendant tabellen in elk ander primair gegevensbestand. In dit model worden vaak conflictresolutieschema’s gebruikt om problemen als dubbele primaire sleutels te vermijden.
Er zijn een paar voordelen aan het gebruik van MMR, namelijk:
- Bij uitval van een host kunnen andere hosts nog steeds update en insertion diensten verlenen.
- De primaire nodes zijn verspreid over verschillende plaatsen, zodat de kans op uitval van alle primaire nodeserg klein is.
- Mogelijkheid om een wide area netwerk (WAN) van primaire databases in te zetten, die geografisch dicht bij groepen clients kunnen liggen, en toch over het hele netwerk de consistentie van de gegevens bewaren.
Het nadeel van het toepassen van MMR is echter de complexiteit en de moeilijkheid om conflicten op te lossen.
Verschillende takken en toepassingen bieden MMR oplossingen aan omdat PostgreSQL die niet van nature ondersteunt. Deze oplossingen kunnen open-source, gratis, of betaald zijn. Eén zo’n uitbreiding is bidirectionele replicatie (BDR) die asynchroon is en gebaseerd is op de PostgreSQL logische decoderingsfunctie.
Omdat de BDR toepassing transacties op andere nodes herhaalt, kan de herhaaloperatie mislukken als er een conflict is tussen de transactie die wordt toegepast en de transactie die op de ontvangende node is vastgelegd.
Soorten PostgreSQL replicatie
Er zijn twee soorten PostgreSQL replicatie: logische en fysieke replicatie.
Een eenvoudige logische bewerking initdb zou de fysische bewerking uitvoeren van het aanmaken van een basismap voor een cluster. Evenzo zou een eenvoudige logische bewerking CREATE DATABASE de fysieke bewerking uitvoeren van het maken van een submap in de basismap.
Fysieke replicatie heeft meestal te maken met bestanden en mappen. Het weet niet wat deze bestanden en mappen voorstellen. Deze methoden worden gebruikt om een volledige kopie van de hele gegevens van een enkele cluster bij te houden, meestal op een andere machine, en gebeuren op het niveau van het bestandssysteem of de schijf en gebruiken exacte blokadressen.
Logische replicatie is een manier om gegevensentiteiten en hun wijzigingen te reproduceren, op basis van hun replicatie-identiteit (meestal een primaire sleutel). In tegenstelling tot fysieke replicatie heeft het te maken met databanken, tabellen, en DML operaties en gebeurt het op het niveau van de databasecluster. Het gebruikt een publish en subscribe model waarbij een of meer subscribers geabonneerd zijn op een of meer publications op een publisher node.
Het replicatieproces begint met het maken van een momentopname van de gegevens op de publisher database en kopieert die dan naar de subscriber. Subscribers halen gegevens uit de publications waarop ze “geabonneerd” zijn en kunnen gegevens later opnieuw publiceren om cascade replication of complexere configuraties mogelijk te maken. De subscriber past de gegevens toe in dezelfde volgorde als de publisher, zodat transactionele consistentie gegarandeerd is voor publications binnen een enkel “abonnement”, ook bekend als transactionele replicatie.
De typische gebruikssituaties voor logische replicatie zijn:
- Stapsgewijze veranderingen in een enkele database (of een deelverzameling van een database) naar de abonnees zenden wanneer ze zich voordoen.
- Het delen van een subset van de database tussen meerdere databases.
- Het afvuren van afzonderlijke veranderingen triggeren als ze bij de subscriber aankomen.
- Consolideren van meerdere databses tot één.
- Toegang tot gerepliceerde gegevens verlenen aan verschillende groepen gebruikers.
De subscriber database gedraagt zich op dezelfde manier als elke andere PostgreSQL instantie en kan gebruikt worden als publisher voor andere databases door zijn publicaties te definiëren.
Als de subscriber door de toepassing als alleen-lezen wordt behandeld, zullen er geen conflicten zijn van een enkele subcriber. Anderzijds kunnen er conflicten ontstaan als er door een toepassing of door andere subcribers andere schrijfbewerkingen op dezelfde set tabellen worden uitgevoerd.
PostgreSQL ondersteunt beide mechanismen gelijktijdig. Logische replicatie maakt uitgebreide controle mogelijk over zowel gegevensreplicatie als beveiliging.
Replicatietypen
Er zijn hoofdzakelijk twee replicatiewijzen in PostgreSQL: synchroon en asynchroon. Synchrone replicatie staat toe dat gegevens tegelijk naar de primaire en de secundaire server worden geschreven, terwijl asynchrone replicatie ervoor zorgt dat de gegevens eerst naar de host worden geschreven en dan naar de secundaire server worden gekopieerd.
Bij replicatie in synchrone modus worden transacties op de primaire database pas als voltooid beschouwd als die veranderingen naar alle replica’s zijn gerepliceerd. De replicaservers moeten allemaal de hele tijd beschikbaar zijn om de transacties op de primaire te kunnen voltooien. De synchrone replicatiemodus wordt gebruikt in hoogwaardige transactie-omgevingen met onmiddellijke failover eisen.
In de asynchrone modus kunnen transacties op de primaire server voltooid worden verklaard als de veranderingen alleen op de primaire server zijn gedaan. Deze veranderingen worden dan later in de tijd gerepliceerd in de replica’s. De replicaservers kunnen gedurende een bepaalde tijd uit-synchroon blijven, een replicatie-vertraging genoemd. In het geval van een crash kan gegevensverlies optreden, maar de overhead die asynchrone replicatie oplevert is gering, dus in de meeste gevallen aanvaardbaar (de host wordt er niet door overbelast). Fail-over van de primaire database naar de secundaire database duurt langer dan bij synchrone replicatie.
Hoe PostgreSQL replicatie op te zetten
In dit onderdeel laten we zien hoe je het PostgreSQL replicatieproces opzet op een Linux besturingssysteem. In dit geval gebruiken we Ubuntu 18.04 LTS en PostgreSQL 10.
Laten we er eens naar kijken!
Installatie
Je begint met de installatie van PostgreSQL op Linux met deze stappen:
- Eerst moet je de PostgreSQL sign key importeren door het onderstaande commando in de terminal te typen:
wget -q https://www.postgresql.org/media/keys/ACCC4CF8.asc -O- | sudo apt-key add - - Voeg nu de PostgreSQL repository toe door het onderstaande commando in de terminal te typen:
echo "deb http://apt.postgresql.org/pub/repos/apt/ bionic-pgdg main" | sudo tee /etc/apt/sources.list.d/postgresql.list - Werk de Repository Index bij door het volgende commando in de terminal te typen:
sudo apt-get update - Installeer het PostgreSQL pakket met het apt commando:
sudo apt-get install -y postgresql-10 - Stel tenslotte het wachtwoord voor de PostgreSQL gebruiker in met het volgende commando:
sudo passwd postgres
De installatie van PostgreSQL is verplicht voor zowel de primaire als de secundaire servers voordat het PostgreSQL replicatieproces wordt gestart.
Zodra je PostgreSQL op beide servers hebt ingesteld, kun je verder gaan met de replicatiesetup van de primaire en de secundaire server.
Replicatie instellen in de primaire server
Voer deze stappen uit als je PostgreSQL op zowel de primaire als de secundaire server geïnstalleerd hebt.
- Log eerst in op de PostgreSQL database met het volgende commando:
su - postgres - Maak een replicatiegebruiker aan met het volgende commando:
psql -c "CREATEUSER replication REPLICATION LOGIN CONNECTION LIMIT 1 ENCRYPTED PASSWORD'JOUW_WACHTWOORD';" - Bewerk pg_hba.cnf met een willekeurig nano programma in Ubuntu en voeg de volgende configuratie toe:
nano /etc/postgresql/10/main/pg_hba.confOm het bestand in te stellen, gebruik je het volgende commando:
host replication replication MasterIP/24 md5 - Open en bewerk postgresql.conf en zet de volgende configuratie in de primaire server:
nano /etc/postgresql/10/main/postgresql.confGebruik de volgende configuratie-instellingen:
listen_addresses = 'localhost,MasterIP'wal_level = replicawal_keep_segments = 64max_wal_senders = 10 - Herstart tenslotte PostgreSQL in de primaire hoofdserver:
systemctl restart postgresqlJe hebt nu de setup in de primaire server voltooid.
Replicatie instellen in de secundaire server
Volg deze stappen om replicatie in de secundaire server in te stellen:
- Log in op PostgreSQL RDMS met het onderstaande commando:
su - postgres - Stop de PostgreSQL dienst om ons in staat te stellen eraan te werken met het onderstaande commando:
systemctl stop postgresql - Bewerk het bestand pg_hba.conf met dit commando en voeg de volgende configuratie toe:
// "Edit" commandnano /etc/postgresql/10/main/pg_hba.conf// "Configuration" commandhost replication replication MasterIP/24 md5 - Open en bewerk postgresql.conf in de secundaire server en zet de volgende configuratie of maak het commentaar ongedaan als het commentaar is:
nano /etc/postgresql/10/main/postgresql.conflisten_addresses = 'localhost,SecondaryIP'wal_keep_segments = 64wal_level = replicahot_standby = onmax_wal_senders = 10SecondaryIPis het adres van de secundaire server - Open de PostgreSQL gegevensmap in de secundaire server en verwijder alles:
cd /var/lib/postgresql/10/mainrm -rfv * - Kopieer de PostgreSQL directory bestanden van de primaire server naar de PostgreSQL directorymap van de secundaire server en schrijf dit commando in de secundaire server:
pg_basebackup -h MasterIP -D /var/lib/postgresql/11/main/ -P -Ureplication --wal-method=fetch - Voer het PostgreSQL wachtwoord van de primaire server in en druk op enter. Voeg vervolgens het volgende commando toe voor de herstelconfiguratie:
// "Edit" Command nano /var/lib/postgresql/10/main/recovery.conf // Configurationstandby_mode = 'on' primary_conninfo = 'host=MasterIP port=5432 user=replication password=JOUW_WACHTWOORD' trigger_file = '/tmp/MasterNow'Hier is
YOUR_PASSWORDhet wachtwoord voor de replicatiegebruiker in de primaire server die PostgreSQL aanmaakte - Als het wachtwoord ingesteld is, moet je de secundaire PostgreSQL database opnieuw starten omdat die gestopt was:
systemctl start postgresqlJe opstelling testen
Nu we de stappen hebben uitgevoerd, laten we het replicatieproces testen en de database van de secundaire server observeren. Hiertoe maken we een tabel aan in de primaire server en kijken of die ook op de secundaire server wordt weergegeven.
Laten we aan de slag gaan.
- Omdat we de tabel in de primaire server maken, moet je inloggen op de primaire server:
su - postgres psql - Nu maken we een eenvoudige tabel met de naam ’testtable’ en voegen gegevens in de tabel in door de volgende PostgreSQL queries in de terminal uit te voeren:
CREATE TABLE testtable (websites varchar(100)); INSERT INTO testtable VALUES ('section.com'); INSERT INTO testtable VALUES ('google.com'); INSERT INTO testtable VALUES ('github.com'); - Observeer de PostgreSQL database van de secundaire server door in te loggen op de secundaire server:
su - postgres psql - Nu controleren we of de tabel ’testtable’ bestaat, en kunnen de gegevens teruggeven door de volgende PostgreSQL query’s in de terminal uit te voeren. Dit commando geeft in wezen de hele tabel weer.
select * from testtable;
Dit is de uitvoer van de test tabel:
| websites |
-------------------
| section.com |
| google.com |
| github.com |
--------------------Je zou dezelfde gegevens moeten kunnen waarnemen als die in de primaire server.
Als je het bovenstaande ziet, dan heb je het replicatieproces met succes uitgevoerd!
Wat zijn de stappen voor een PostgreSQL handmatige failover?
Laten we de stappen voor een PostgreSQL handmatige failover eens doornemen:
- Crash de primaire server.
- Promoveer de stand-by server door op de stand-by server het volgende commando uit te voeren:
./pg_ctl promote -D ../sb_data/ server promoting - Maak verbinding met de gepromoveerde stand-by server en voeg een rij in:
-bash-4.2$ ./edb-psql -p 5432 edb Password: psql.bin (10.7) Type "help" for help. edb=# insert into abc values(4,'Four');
Als de insert goed werkt, dan is de standby, voorheen een alleen-lezen server, gepromoveerd tot de nieuwe primaire server.
Zo automatiseer je failovers in PostgreSQL
Het instellen van automatische failover is eenvoudig.
Je hebt de EDB PostgreSQL failover manager (EFM) nodig. Na het downloaden en installeren van EFM op elke primaire en stand-by node, kun je een EFM Cluster maken, die bestaat uit een primaire node, een of meer stand-by nodes, en een optionele Witness node die assertions bevestigt in geval van storing.
EFM monitort voortdurend de systeemgezondheid en stuurt e-mail waarschuwingen op basis van systeemgebeurtenissen. Bij een storing schakelt het automatisch over op de meest actuele stand-by en herconfigureert alle andere stand-by servers om de nieuwe primaire node te herkennen.
Het herconfigureert ook load balancers (zoals pgPool) en voorkomt dat “split-brain” (wanneer twee knooppunten elk denken dat ze primair zijn) optreedt.
Samenvatting
Door de grote hoeveelheden gegevens zijn schaalbaarheid en beveiliging twee van de belangrijkste criteria geworden bij databasebeheer, vooral in een transactie-omgeving. Hoewel we de schaalbaarheid verticaal kunnen verbeteren door meer resources/hardware aan bestaande nodes toe te voegen, is dat niet altijd mogelijk, vaak door de kosten of beperkingen van het toevoegen van nieuwe hardware.
Vandaar dat horizontale schaalbaarheid nodig is, wat inhoudt dat meer nodes aan bestaande netwerknodes worden toegevoegd in plaats van de functionaliteit van bestaande knooppunten te verbeteren. Dit is waar PostgreSQL replicatie in beeld komt.
In dit artikel hebben we de soorten PostgreSQL replicaties besproken, de voordelen, de replicatiemodes, de installatie, en PostgreSQL failover tussen SMR en MMR. Nu zijn we benieuwd naar jou.
Welke implementeer je meestal? Welke databasefunctie is voor jou het belangrijkst en waarom? We zouden graag je antwoord willen lezen! Deel ze in de comments hieronder.

Salman Ravoof is een autodidactische webdeveloper, schrijver, creator en een groot bewonderaar van Free and Open Source Software (FOSS). Naast techniek is hij enthousiast over wetenschap, filosofie, fotografie, kunst, katten en eten. Lees meer over hem op zijn website en kom in contact met Salman op X.

