
Wolltest du schon mal Preise von mehreren Webseiten auf einmal vergleichen? Oder vielleicht automatisch eine Sammlung von Beiträgen aus deinem Lieblingsblog extrahieren? Mit Web Scraping ist das alles möglich.
Unter Web Scraping versteht man das Extrahieren von Inhalten und Daten aus Webseiten mithilfe von Software. Die meisten Preisvergleichsdienste nutzen zum Beispiel Web Scraper, um Preisinformationen von verschiedenen Online-Shops auszulesen. Ein anderes Beispiel ist Google, das das Internet routinemäßig scrapt oder „crawlt“, um Webseiten zu indexieren.
Natürlich sind das nur zwei von vielen Anwendungsfällen für Web Scraping. In diesem Artikel tauchen wir in die Welt der Web Scraper ein, erfahren, wie sie funktionieren und wie manche Webseiten versuchen, sie zu blockieren. Lies weiter, um mehr zu erfahren und fang an zu scrapen!
Was ist Web Scraping?
Web Scraping ist eine Sammlung von Verfahren, mit denen automatisch Daten aus dem Internet extrahiert werden.
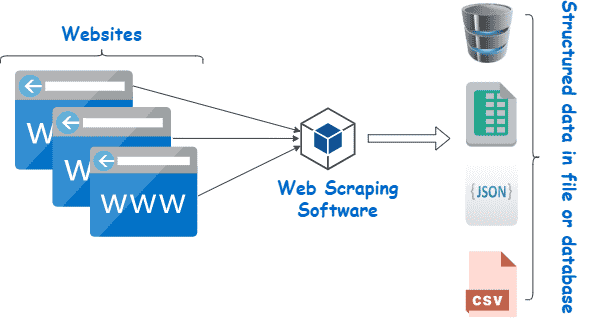
Andere Begriffe für Web Scraping sind „Content Scraping“ oder „Data Scraping“ Egal, wie man es nennt, Web Scraping ist ein äußerst nützliches Instrument zur Online-Datenerfassung. Zu den Anwendungsgebieten von Web Scraping gehören Marktforschung, Preisvergleiche, Überwachung von Inhalten und vieles mehr.
Aber was genau wird beim Web Scraping „gekratzt“ – und wie ist das möglich? Ist es überhaupt legal? Würde eine Webseite wollen, dass jemand kommt und ihre Daten ausspäht?
Die Antworten hängen von mehreren Faktoren ab. Bevor wir uns jedoch mit den Methoden und Anwendungsfällen befassen, wollen wir uns genauer ansehen, was Web Scraping ist und ob es ethisch vertretbar ist oder nicht.
Was können wir aus dem Web „scrapen“?
Es ist möglich, alle Arten von Webdaten zu scrapen. Von Suchmaschinen über RSS-Feeds bis hin zu Regierungsinformationen – die meisten Webseiten stellen ihre Daten für Scraper, Crawler und andere Formen der automatischen Datenerfassung zur Verfügung.
Hier sind einige gängige Beispiele.
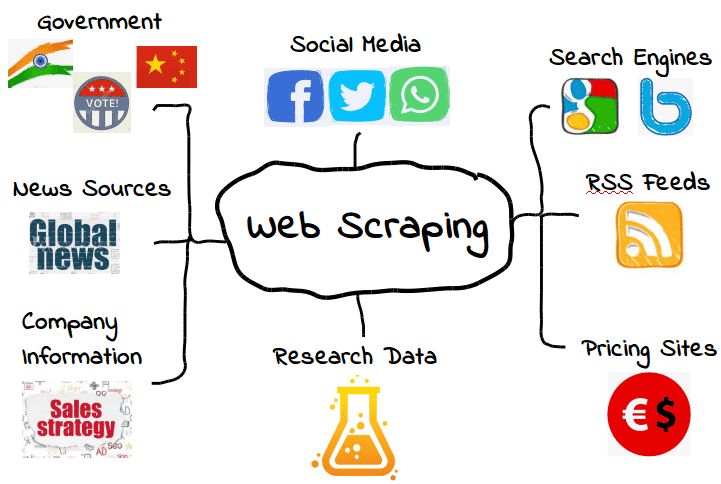
Das heißt aber nicht, dass diese Daten immer verfügbar sind. Je nach Webseite musst du vielleicht ein paar Tools und Tricks anwenden, um genau das zu bekommen, was du brauchst – vorausgesetzt, die Daten sind überhaupt zugänglich. Viele Web Scraper können zum Beispiel keine aussagekräftigen Daten aus visuellen Inhalten extrahieren.
In den einfachsten Fällen kann Web Scraping über die API ( Application Programming Interface) einer Webseite erfolgen . Wenn eine Webseite ihre API zur Verfügung stellt, können Webentwickler sie nutzen, um automatisch Daten und andere nützliche Informationen in einem praktischen Format zu extrahieren. Es ist fast so, als würde der Webhost dir deine eigene „Pipeline“ zu seinen Daten zur Verfügung stellen. Das nenne ich Gastfreundschaft!
Natürlich ist das nicht immer der Fall – und viele Webseiten, die du scrapen willst, haben keine API, die du nutzen kannst. Und selbst Webseiten, die eine API haben , stellen dir die Daten nicht immer im richtigen Format zur Verfügung.
Daher ist Web Scraping nur dann notwendig, wenn die gewünschten Webdaten nicht in der Form vorliegen, die du brauchst. Egal, ob das bedeutet, dass die gewünschten Formate nicht verfügbar sind oder die Webseite einfach nicht alle Daten bereitstellt, mit Web Scraping kannst du bekommen, was du willst.
Das ist zwar schön und gut, aber es wirft auch eine wichtige Frage auf: Ist es legal, bestimmte Webdaten zu scrapen, wenn diese eingeschränkt sind? Wie wir gleich sehen werden, kann das eine Art Grauzone sein.
Ist Web Scraping legal?
Für manche Menschen kann sich Web Scraping fast wie Diebstahl anfühlen. Wer bist du denn, dass du die Daten eines anderen einfach „klaust“?
Glücklicherweise ist Web Scraping nicht grundsätzlich illegal. Wenn eine Webseite Daten veröffentlicht, sind sie in der Regel öffentlich zugänglich und können daher frei gescannt werden.
Da Amazon zum Beispiel die Produktpreise öffentlich zugänglich macht, ist es völlig legal, Preisdaten zu scrapen. Viele beliebte Shopping-Apps und Browser-Erweiterungen nutzen Web-Scraping für genau diesen Zweck, damit die Nutzer wissen, dass sie den richtigen Preis bekommen.
Aber nicht alle Webdaten sind für die Öffentlichkeit bestimmt, und das bedeutet, dass nicht alle Webdaten rechtmäßig abgegriffen werden können. Wenn es um persönliche Daten und geistiges Eigentum geht, kann Web-Scraping schnell zu bösartigem Web-Scraping werden, was zu Strafen wie einer DMCA-Abmahnung führen kann.
Was ist böswilliges Web-Scraping?
Böswilliges Web Scraping ist das Auslesen von Daten, deren Weitergabe der Herausgeber nicht beabsichtigt oder genehmigt hat. Obwohl es sich bei diesen Daten in der Regel entweder um persönliche Daten oder um geistiges Eigentum handelt, kann böswilliges Web Scraping auf alles zutreffen, was nicht für die Öffentlichkeit bestimmt ist.
Wie du dir vielleicht vorstellen kannst, gibt es bei dieser Definition eine Grauzone. Während viele Arten von personenbezogenen Daten durch Gesetze wie die General Data Protection Regulation (GDPR) und den California Consumer Privacy Act (CCPA) geschützt sind, gilt das für andere nicht. Das heißt aber nicht, dass es keine Situationen gibt, in denen das Scrapen nicht legal ist.

Nehmen wir zum Beispiel an, ein Webhoster macht „versehentlich“ seine Benutzerdaten öffentlich zugänglich. Dazu könnte eine vollständige Liste mit Namen, E-Mails und anderen Informationen gehören, die eigentlich öffentlich sind, aber vielleicht nicht weitergegeben werden sollen.
Auch wenn es technisch gesehen legal wäre, diese Daten abzugreifen, ist es wahrscheinlich nicht die beste Idee. Nur weil Daten öffentlich sind, heißt das nicht unbedingt, dass der Webhoster dem Scrapen zugestimmt hat, selbst wenn er sie durch mangelnde Vorsicht öffentlich gemacht hat.
Diese „Grauzone“ hat dem Web Scraping einen etwas zwiespältigen Ruf eingebracht. Web Scraping ist zwar definitiv legal, kann aber leicht für böswillige oder unethische Zwecke genutzt werden. Daher sehen es viele Webhosts nicht gerne, wenn ihre Daten gescraped werden – unabhängig davon, ob es legal ist.
Eine andere Art von bösartigem Web-Scraping ist das „Over-Scraping“, bei dem Scraper in einem bestimmten Zeitraum zu viele Anfragen stellen. Zu viele Anfragen können eine enorme Belastung für Webhosts darstellen, die ihre Serverressourcen lieber für echte Menschen als für Scraping-Bots verwenden würden.
Generell solltest du Web Scraping nur sparsam einsetzen und nur dann, wenn du dir absolut sicher bist, dass die Daten für die Öffentlichkeit bestimmt sind. Denk daran: Nur weil Daten öffentlich zugänglich sind, heißt das nicht, dass es legal oder ethisch vertretbar ist, sie zu scrapen.
Wofür wird Web Scraping eingesetzt?
Im besten Fall dient Web Scraping vielen nützlichen Zwecken in vielen Branchen. Im Jahr 2021 wird fast die Hälfte des Web Scraping zur Unterstützung von E-Commerce-Strategien eingesetzt.
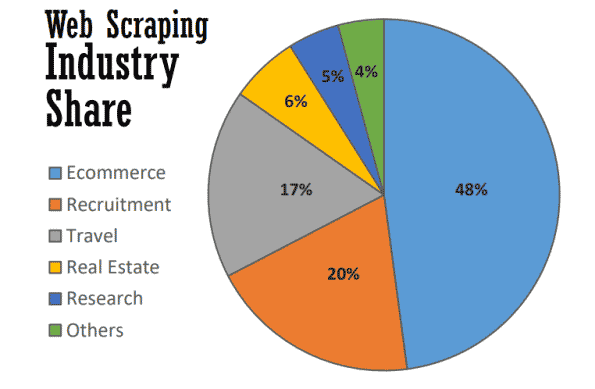
Web Scraping ist zum Rückgrat vieler datengesteuerter Prozesse geworden, von der Verfolgung von Marken über aktuelle Preisvergleiche bis hin zur Durchführung wertvoller Marktforschung. Hier sind einige der gängigsten Methoden.
Marktforschung
Was machen deine Kunden? Was ist mit deinen Leads? Wie sind die Preise deiner Konkurrenten im Vergleich zu deinen? Hast du Informationen, um eine erfolgreiche Inbound-Marketing- oder Content-Marketing-Kampagne zu erstellen?
Dies sind nur einige der Fragen, die die Eckpfeiler der Marktforschung bilden – und genau diese können mit Web Scraping beantwortet werden. Da viele dieser Daten öffentlich zugänglich sind, ist Web Scraping zu einem unschätzbaren Werkzeug für Marketingteams geworden, die ihren Markt im Auge behalten wollen, ohne zeitaufwändige manuelle Recherchen durchführen zu müssen.
Geschäftsautomatisierung
Viele der Vorteile von Web Scraping für die Marktforschung gelten auch für die Unternehmensautomatisierung.
Bei vielen Aufgaben der Geschäftsautomatisierung, die das Sammeln und Verarbeiten großer Datenmengen erfordern, kann Web Scraping von unschätzbarem Wert sein – vor allem, wenn dies sonst sehr mühsam wäre.
Nehmen wir zum Beispiel an, du musst Daten von zehn verschiedenen Webseiten sammeln. Selbst wenn du von jeder die gleiche Art von Daten sammelst, kann jede Webseite eine andere Extraktionsmethode erfordern. Anstatt die verschiedenen internen Prozesse auf jeder Webseite manuell zu durchlaufen, könntest du einen Web Scraper verwenden, um dies automatisch zu tun.
Lead-Generierung
Als ob Marktforschung und Geschäftsautomatisierung nicht schon genug wären, kannst du mit Web Scraping auch mit wenig Aufwand wertvolle Lead-Listen erstellen.
Auch wenn du deine Ziele genau festlegen musst, kannst du mit Web Scraping genügend Nutzerdaten sammeln, um strukturierte Lead-Listen zu erstellen. Die Ergebnisse können natürlich variieren, aber es ist bequemer (und vielversprechender) als die Erstellung eigener Lead-Listen.
Preisverfolgung
Das Extrahieren von Preisen – auch bekannt als Price Scraping – ist eine der häufigsten Anwendungen für Web Scraping.
Hier ist ein Beispiel von der beliebten Amazon-Preisverfolgungs-App Camelcamelcamel. Die App sammelt regelmäßig Produktpreise und vergleicht sie dann in einem Diagramm über die Zeit.
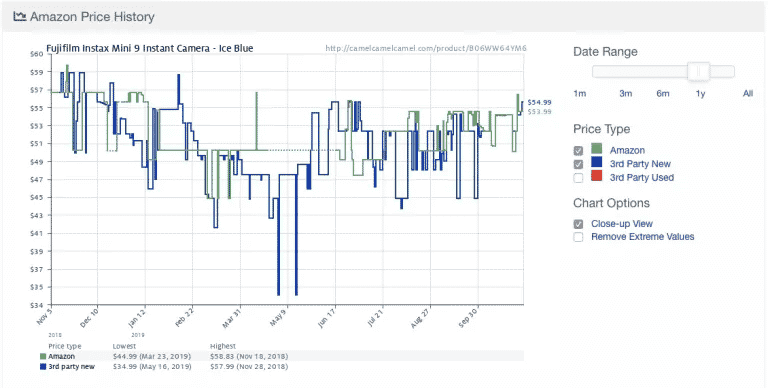
Die Preise können stark schwanken, sogar täglich (siehe den plötzlichen Preisverfall um den 9. Mai!). Mit dem Zugriff auf historische Preistrends können Nutzer/innen überprüfen, ob der Preis, den sie zahlen, ideal ist. In diesem Beispiel könnte der Nutzer eine Woche warten, in der Hoffnung, 10 US-Dollar zu sparen.
Trotz seines Nutzens ist das Preis-Scraping nicht unumstritten. Da viele Menschen Preisaktualisierungen in Echtzeit wünschen, werden einige Preisüberwachungs-Apps schnell bösartig, indem sie bestimmte Webseiten mit Serveranfragen überlasten.
Deshalb haben viele E-Commerce-Webseiten begonnen, zusätzliche Maßnahmen zu ergreifen, um Web Scraper komplett zu blockieren, die wir im nächsten Abschnitt behandeln.
Nachrichten und Inhalte
Es gibt nichts Wertvolleres, als immer auf dem Laufenden zu sein. Ob es darum geht, den Ruf eines Unternehmens zu überwachen oder Branchentrends zu verfolgen – Web Scraping ist ein wertvolles Instrument, um auf dem Laufenden zu bleiben.
Einige Nachrichten-Webseiten und Blogs bieten zwar bereits RSS-Feeds und andere einfache Schnittstellen an, aber sie sind nicht immer die Norm – und auch nicht mehr so verbreitet wie früher. Um genau die Nachrichten und Inhalte zu finden, die du brauchst, ist daher oft eine Form von Web Scraping erforderlich.
Markenüberwachung
Wenn du schon Nachrichten scannst, warum überprüfst du nicht auch deine Marke? Für Marken, über die viel berichtet wird, ist Web Scraping ein unschätzbares Werkzeug, um auf dem Laufenden zu bleiben, ohne unzählige Artikel und Nachrichtenseiten durchforsten zu müssen.
Web Scraping ist auch nützlich, um den Mindestpreis eines Produkts oder einer Dienstleistung einer Marke zu überprüfen. Obwohl es sich hierbei technisch gesehen um eine Form des Preis-Scraping handelt, ist dies eine wichtige Erkenntnis, die Marken dabei helfen kann, herauszufinden, ob ihre Preisgestaltung mit den Erwartungen der Kunden übereinstimmt.
Real Estate
Wenn du schon einmal nach einer Wohnung gesucht oder ein Haus gekauft hast, weißt du, wie viel es da zu sortieren gibt. Bei Tausenden von Angeboten auf verschiedenen Immobilien-Webseiten kann es schwierig sein, genau das zu finden, was du suchst.
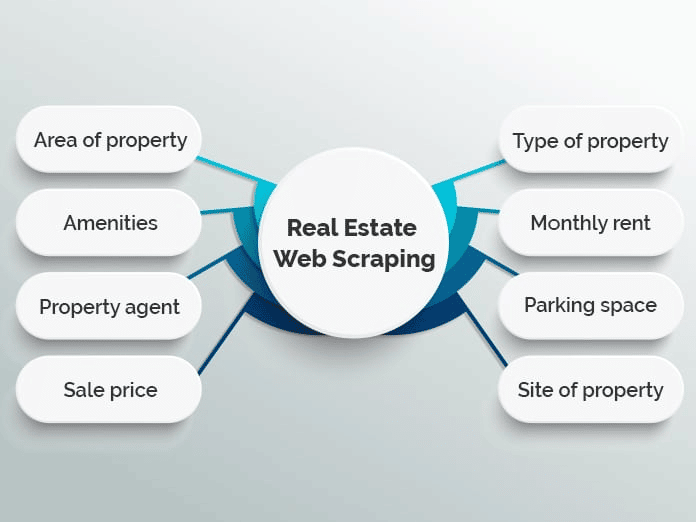
Viele Webseiten nutzen Web Scraping, um Immobilienangebote in einer einzigen Datenbank zusammenzufassen und so die Suche zu erleichtern. Beliebte Beispiele sind Zillow und Trulia, aber es gibt auch viele andere, die ein ähnliches Modell verfolgen.
Das Zusammenfassen von Angeboten ist jedoch nicht die einzige Anwendung für Web Scraping im Immobilienbereich. Immobilienmakler können Scraping-Anwendungen zum Beispiel nutzen, um den Überblick über die durchschnittlichen Miet- und Verkaufspreise, die Art der verkauften Immobilien und andere wichtige Trends zu behalten.
(cta)
Wie funktioniert Web Scraping?
Web Scraping hört sich vielleicht kompliziert an, aber es ist eigentlich ganz einfach.
Es gibt zwar unterschiedliche Methoden und Tools, aber du musst nur einen Weg finden, (1) deine Ziel-Webseite(n) automatisch zu durchsuchen und (2) die Daten zu extrahieren, sobald du dort bist. Normalerweise werden diese Schritte mit Scrapern und Crawlern durchgeführt.
Scraper und Crawler
Im Prinzip funktioniert Web Scraping fast genauso wie ein Pferd und ein Pflug.

Während das Pferd den Pflug führt, dreht sich der Pflug und bricht die Erde auf, um Platz für neues Saatgut zu schaffen und gleichzeitig unerwünschtes Unkraut und Ernterückstände in den Boden zurückzuarbeiten.
Abgesehen vom Pferd ist das Schaben von Bahnen nicht viel anders. Hier übernimmt ein Crawler die Rolle des Pferdes und führt den Scraper – quasi unseren Pflug – durch unsere digitalen Felder.
Hier ist, was die beiden tun.
- Crawler (manchmal auch als Spider bezeichnet) sind Programme, die das Internet nach Inhalten durchsuchen und diese indizieren. Obwohl Crawler Web Scraper anleiten, werden sie nicht ausschließlich für diesen Zweck eingesetzt. Suchmaschinen wie Google nutzen Crawler zum Beispiel, um den Index und das Ranking von Webseiten zu aktualisieren. Crawler sind in der Regel als vorgefertigte Tools erhältlich, bei denen du eine bestimmte Webseite oder einen Suchbegriff angeben kannst.
- Scraper machen die Drecksarbeit, um schnell relevante Informationen aus Webseiten zu extrahieren. Da Webseiten in HTML strukturiert sind, verwenden Scraper reguläre Ausdrücke (Regex), XPath, CSS-Selektoren und andere Locators, um bestimmte Inhalte schnell zu finden und zu extrahieren. Du könntest deinem Web Scraper zum Beispiel einen regulären Ausdruck geben, der einen Markennamen oder ein Schlüsselwort enthält.
Wenn das ein wenig überwältigend klingt, mach dir keine Sorgen. Die meisten Web-Scraping-Tools verfügen über integrierte Crawler und Scraper, mit denen du selbst die kompliziertesten Aufgaben leicht erledigen kannst.
Grundlegender Web Scraping Prozess
Im Grunde genommen besteht Web Scraping nur aus ein paar einfachen Schritten:
- Gib die URLs der Webseiten und Seiten an, die du scrapen willst
- Stelle eine HTML-Anfrage an die URLs (d.h. „besuche“ die Seiten)
- Verwende Locators wie reguläre Ausdrücke, um die gewünschten Informationen aus dem HTML zu extrahieren
- Speichere die Daten in einem strukturierten Format (z. B. CSV oder JSON)
Wie wir im nächsten Abschnitt sehen werden, kann eine Vielzahl von Web Scraping-Tools verwendet werden, um diese Schritte automatisch durchzuführen.
Allerdings ist es nicht immer so einfach – vor allem, wenn du Web Scraping in größerem Umfang durchführst. Eine der größten Herausforderungen beim Web Scraping ist es, deinen Scraper auf dem neuesten Stand zu halten, wenn Webseiten ihr Layout ändern oder Anti-Scraping-Maßnahmen ergreifen (nicht alles kann immergrün sein). Das ist zwar nicht allzu schwierig, wenn du nur ein paar Webseiten auf einmal scannst, aber wenn du mehr scannst, kann es schnell zu einem Problem werden.
Um die zusätzliche Arbeit zu minimieren, ist es wichtig zu wissen, wie Webseiten versuchen, Scraper zu blockieren – das erfahren wir im nächsten Abschnitt.
Web Scraping Tools
Viele Web-Scraping-Funktionen sind in Form von Web-Scraping-Tools leicht verfügbar. Es gibt zwar viele Tools, aber sie unterscheiden sich stark in Qualität, Preis und (leider) auch in ihrer Ethik.
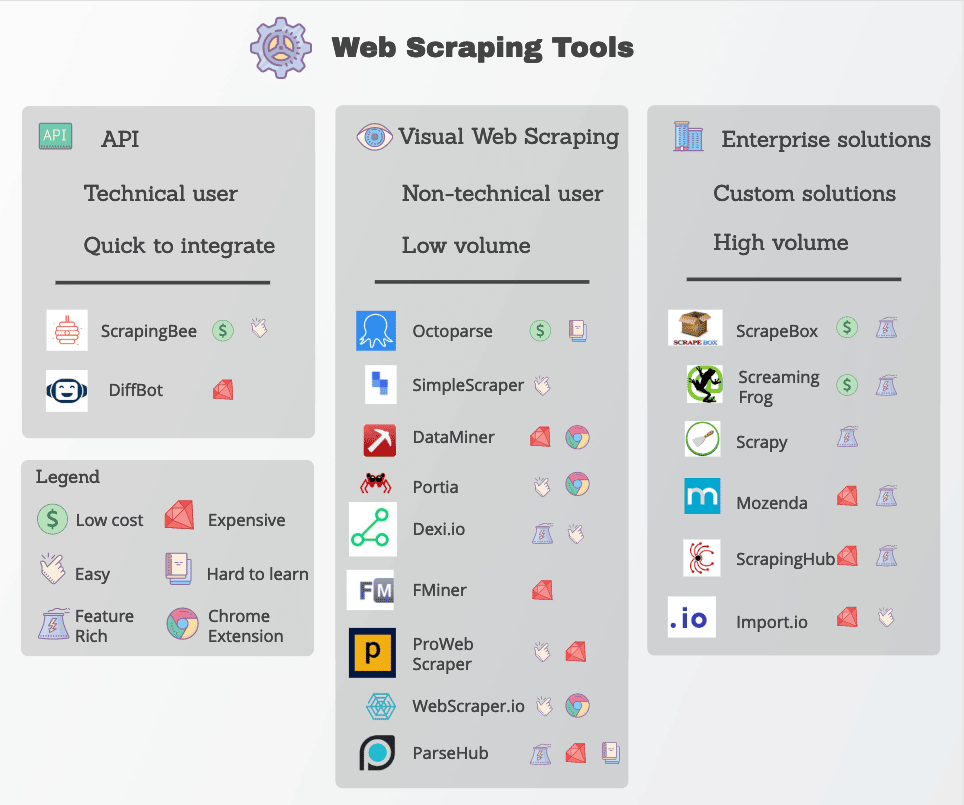
Ein guter Web Scraper wird auf jeden Fall in der Lage sein, die benötigten Daten zuverlässig zu extrahieren, ohne dass du auf zu viele Anti-Scraping-Maßnahmen stößt. Hier sind einige wichtige Funktionen, auf die du achten solltest.
- Präzise Locators: Web Scraper verwenden Locatoren wie reguläre Ausdrücke und CSS-Selektoren, um bestimmte Daten zu extrahieren. Das Tool, das du auswählst, sollte dir mehrere Optionen bieten, um zu spezifizieren, wonach du suchen willst.
- Datenqualität: Die meisten Webdaten sind unstrukturiert – selbst wenn sie für das menschliche Auge übersichtlich dargestellt werden. Die Arbeit mit unstrukturierten Daten ist nicht nur unübersichtlich, sie liefert auch selten gute Ergebnisse. Achte auf Scraping-Tools, die Rohdaten vor der Übermittlung bereinigen und sortieren.
- Datenlieferung: Je nach deinen bestehenden Tools oder Arbeitsabläufen benötigst du die gescrapten Daten wahrscheinlich in einem bestimmten Format wie JSON, XML oder CSV. Anstatt die Rohdaten selbst zu konvertieren, solltest du nach Tools suchen, die die Daten in den von dir benötigten Formaten bereitstellen.
- Anti-Scraping-Verfahren: Web Scraping ist nur so effektiv wie seine Fähigkeit, Sperren zu umgehen. Du musst vielleicht zusätzliche Tools wie Proxys und VPNs einsetzen, um Webseiten zu entsperren, aber viele Web-Scraping-Tools schaffen das, indem sie kleine Änderungen an ihren Crawlern vornehmen.
- Transparente Preise: Auch wenn einige Web Scraping Tools kostenlos sind, haben robustere Optionen ihren Preis. Achte genau auf die Preisgestaltung, vor allem, wenn du viele Webseiten scrapen willst.
- Kundenbetreuung: Die Verwendung eines vorgefertigten Tools ist zwar äußerst praktisch, aber du wirst nicht immer in der Lage sein, Probleme selbst zu beheben. Vergewissere dich daher, dass dein Anbieter auch einen zuverlässigen Kundensupport und Ressourcen zur Fehlerbehebung anbietet.
Beliebte Web Scraping Tools sind Octoparse, Import.io und Parsehub.
Schutz vor Web Scraping
Drehen wir den Spieß mal ein bisschen um: Angenommen, du bist ein Webhost, willst aber nicht, dass andere Leute all diese cleveren Methoden nutzen, um deine Daten zu scrapen. Was kannst du tun, um dich zu schützen?
Neben grundlegenden Sicherheitsplugins gibt es ein paar wirksame Methoden, um Web Scraper und Crawler zu blockieren.
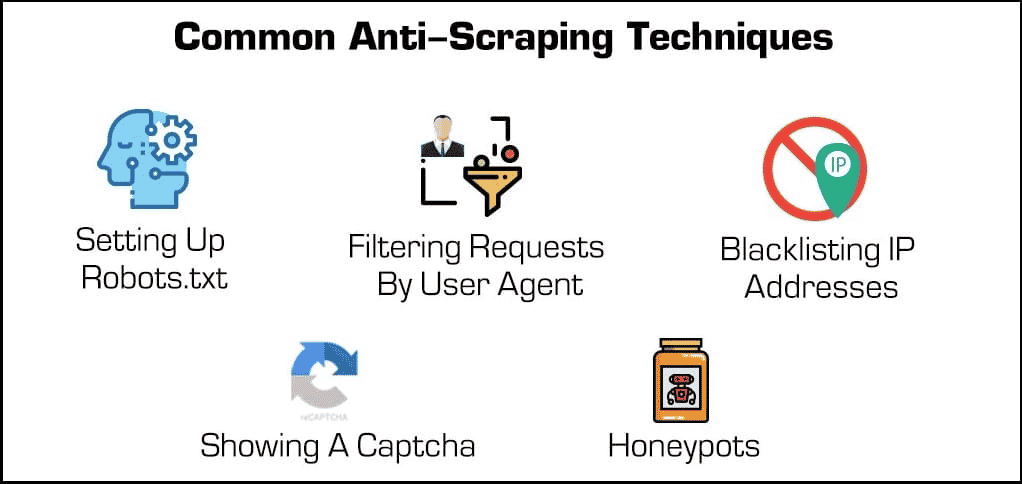
- Blockieren von IP-Adressen: Viele Webhoster verfolgen die IP-Adressen ihrer Besucher/innen. Wenn ein Hoster feststellt, dass ein bestimmter Besucher viele Serveranfragen generiert (wie z. B. bei einigen Web-Scrapern oder Bots), kann er die IP-Adresse vollständig sperren. Scraper können diese Sperren jedoch umgehen, indem sie ihre IP-Adresse über einen Proxy oder ein VPN ändern.
- Einrichten von robots.txt: Mit einer robots.txt-Datei kann ein Webhost Scrapern, Crawlern und anderen Bots mitteilen, worauf sie zugreifen können und worauf nicht. Manche Webseiten verwenden eine robots.txt-Datei, um ihre Privatsphäre zu wahren, indem sie Suchmaschinen mitteilen, dass sie nicht indiziert werden sollen. Die meisten Suchmaschinen respektieren diese Dateien, aber viele böswillige Web Scraper tun das nicht.
- Anfragen filtern: Jedes Mal, wenn jemand eine Webseite besucht, „fordert“ er eine HTML-Seite vom Webserver an. Diese Anfragen sind oft für Webhoster sichtbar, die bestimmte Identifizierungsfaktoren wie IP-Adressen und Benutzeragenten wie Webbrowser einsehen können. Wir haben bereits über das Blockieren von IPs gesprochen, aber Webhoster können auch nach dem User Agent filtern.
Wenn ein Webhoster zum Beispiel bemerkt, dass viele Anfragen von ein und demselben Nutzer mit einer längst veralteten Version von Mozilla Firefox gestellt werden, kann er diese Version einfach blockieren und damit auch den Bot. Diese Blockierfunktionen sind in den meisten Managed Hosting-Angeboten enthalten.
- Ein Captcha anzeigen: Musstest du schon einmal eine merkwürdige Textfolge eintippen oder auf mindestens sechs Segelboote klicken, bevor du eine Seite aufrufen konntest? Dann bist du auf ein „Captcha“ gestoßen oder complete automated public Turing test for telling computers and humans apart. Sie mögen zwar einfach sein, aber sie sind unglaublich effektiv beim Herausfiltern von Web-Scrapern und anderen Bots.
- Honeypots: Ein „Honeypot“ ist eine Art Falle, um unerwünschte Besucher anzulocken und zu identifizieren. Im Fall von Web-Scrapern kann ein Webhost unsichtbare Links auf seiner Webseite einbauen. Auch wenn menschliche Nutzer/innen dies nicht bemerken, besuchen Bots diese Links automatisch, wenn sie durch die Seite scrollen, so dass Webhosts ihre IP-Adressen oder User Agents sammeln (und blockieren) können.
Drehen wir den Spieß nun wieder um. Was kann ein Scraper tun, um diese Schutzmechanismen zu überwinden?
Während einige Anti-Scraping-Maßnahmen schwer zu umgehen sind, gibt es ein paar Methoden, die oft funktionieren. Dazu gehört, dass du die Erkennungsmerkmale deines Scrapers auf irgendeine Weise veränderst.
- Verwende einen Proxy oder ein VPN: Da viele Webhosts Web Scraper anhand ihrer IP-Adresse blockieren, ist es oft notwendig, mehrere IP-Adressen zu verwenden, um den Zugang zu garantieren. Proxys und virtuelle, private Netzwerke (VPNs) sind ideal für diese Aufgabe, auch wenn sie ein paar wichtige Unterschiede aufweisen.
- Besuche deine Ziele regelmäßig: Die meisten (wenn überhaupt) Web Scraper teilen dir mit, wenn sie blockiert wurden. Deshalb ist es wichtig, dass du regelmäßig nachschaust, von wo aus du scrappst, um zu sehen, ob du blockiert wurdest oder ob sich die Formatierung der Webseite geändert hat. Beachte, dass eines von beidem irgendwann garantiert eintritt.
Natürlich sind all diese Maßnahmen nicht notwendig, wenn du Web Scraping verantwortungsbewusst einsetzt. Wenn du dich für Web Scraping entscheidest, denke daran, sparsam damit umzugehen und deine Webhosts zu respektieren!
Zusammenfassung
Web Scraping ist ein mächtiges Werkzeug, stellt aber auch eine große Gefahr für viele Webhoster dar. Unabhängig davon, auf welcher Seite des Servers du stehst, hat jeder ein Interesse daran, dass Web Scraping verantwortungsvoll und natürlich zum Guten eingesetzt wird.
Wenn du als Webhoster Web Scraper kontrollieren willst, bist du bei den Managed Hosting-Angeboten von Kinsta an der richtigen Adresse. Du kannst Bots einschränken und wertvolle Daten und Ressourcen mit zahlreichen Tools zur Zugriffskontrolle schützen.
Wenn du mehr wissen willst, vereinbare eine kostenlose Demo oder kontaktiere noch heute einen Webhosting-Experten von Kinsta.


