
En los últimos 18 meses, la atención prestada al tráfico de bots ha pasado de centrarse en el rastreo y la indexación a centrarse en su impacto en el rendimiento básico de tu servidor, en tu factura de alojamiento y en tu capacidad para atender a clientes reales.
Lo sabemos porque hemos analizado más de 10 mil millones de solicitudes en toda la infraestructura administrada por Kinsta, y lo que descubrimos no fue una historia de ataques. Fue una historia de recursos.
Según Daniel Pataki, director técnico de Kinsta: «Desde el punto de vista de la infraestructura, no existe eso de “solo tráfico de bots”». «Cada solicitud supone un trabajo real. A gran escala, el rastreo ineficiente deja de ser un problema de tráfico y se convierte en un problema de recursos».
Este artículo explica por qué se produjo ese cambio, cuánto les cuesta realmente a los propietarios de sitios de WordPress y cómo debe cambiar la narrativa.
El modelo antiguo ya no funciona
La gestión tradicional de los bots se basaba en una premisa sencilla: bloquear los malos y dejar pasar a los buenos. Durante años, eso fue suficiente. Googlebot rastreaba tus páginas, indexaba tu contenido y seguía su camino. Los bots maliciosos intentaban colarse en tu página de inicio de sesión. Dos problemas muy diferentes, dos soluciones muy diferentes.
Lo que ninguno de los dos modelos tenía en cuenta era una tercera categoría: el tráfico automatizado que no es malicioso ni está bloqueado, pero que está causando un perjuicio cuantificable en el rendimiento de tu sitio a gran escala.
Los rastreadores de IA, que son bots diseñados no solo para indexar páginas para los resultados de búsqueda, sino también para recopilar contenido destinado al entrenamiento de modelos, la generación aumentada por recuperación y las consultas de los usuarios en tiempo real, operan a una escala totalmente diferente a la de sus predecesores. Solo GPTBot creció un 305 % entre mayo de 2024 y mayo de 2025. A principios de 2025, aproximadamente una de cada 200 visitas a la web era de un bot de IA. A finales de año, esa proporción había pasado a ser de una de cada 31.
A finales de 2025, los rastreadores de IA representaban el 4,2 % de todas las solicitudes HTML en la red de Cloudflare, una cifra que osciló entre el 2,4 % a principios de abril y el 6,4 % a finales de junio, casi triplicándose en un año.
Estos rastreadores son persistentes y frecuentes, y no se comportan como los bots tradicionales de los motores de búsqueda. Muchos generan grandes volúmenes de solicitudes a endpoints dinámicos que no están almacenados en caché, lo que supone un «trabajo de verdad» para tu servidor.
Qué significa «trabajo de verdad» para un sitio de WordPress
Aquí es donde se hace evidente el problema de la infraestructura, y es un aspecto que suele pasarse por alto en la mayoría de los análisis sobre el tráfico de bots.
Cuando un visitante carga una página almacenada en caché en un sitio de WordPress, tu servidor apenas hace nada. Devuelve un archivo HTML ya generado, igual que haría al servir una imagen o un archivo CSS. El servidor de origen apenas se da cuenta. De eso se trata el almacenamiento en caché.
Pero una parte importante de las solicitudes en un sitio web real de WordPress, y en las tiendas de WooCommerce en particular, no se pueden servir desde la caché. Estas solicitudes incluyen:
- Endpoints del carrito y proceso de pago (
?add-to-cart=,/cart,/checkout) - Páginas de productos filtrados con parámetros en la URL
- Consultas de búsqueda
- Interacciones con AJAX (añadir a la lista de deseos, actualizaciones de precios en tiempo real, ventanas emergentes dinámicas)
- Páginas basadas en sesiones que requieren que el servidor valide o cree un contexto de usuario
Cuando un bot accede a estos endpoints, esto es lo que ocurre realmente en tu servidor:
- Se reserva un hilo de PHP. Cada solicitud dinámica en WordPress ocupa un hilo de PHP durante todo el tiempo que dura el procesamiento, normalmente entre 200 y 500 ms, o más si la página es compleja. Ese hilo no está disponible para ninguna otra solicitud hasta que termine el proceso. Tu plan de alojamiento tiene un número fijo de ellos.
- Tu base de datos ejecuta una consulta. Las páginas dinámicas consultan tu base de datos cada vez que se cargan. Con un tráfico humano normal, esto es manejable. Pero ante una carga sostenida de bots que acceden a rutas sin caché, la base de datos ejecuta consultas constantemente. Si los bots acceden a variaciones únicas de URL que no dan resultados en la caché, cada una de ellas desencadena su propia cadena de consultas.
- Se genera una sobrecarga de sesión. Las páginas del carrito y del proceso de pago crean o validan sesiones incluso para los bots que nunca realizan una compra. Esto añade una sobrecarga de procesamiento en cada una de esas solicitudes.
- Los hilos de PHP se agotan. Cuando todos los hilos de PHP disponibles están ocupados, los visitantes legítimos no reciben respuesta de inmediato, por lo que sus solicitudes se acumulan en la cola. Si la cola se llena, empiezan a notar que las páginas tardan en cargarse, que los procesos de pago se atascan y que aparecen errores 504. Para un cliente real que intenta completar una compra, tu sitio parece que no funciona.
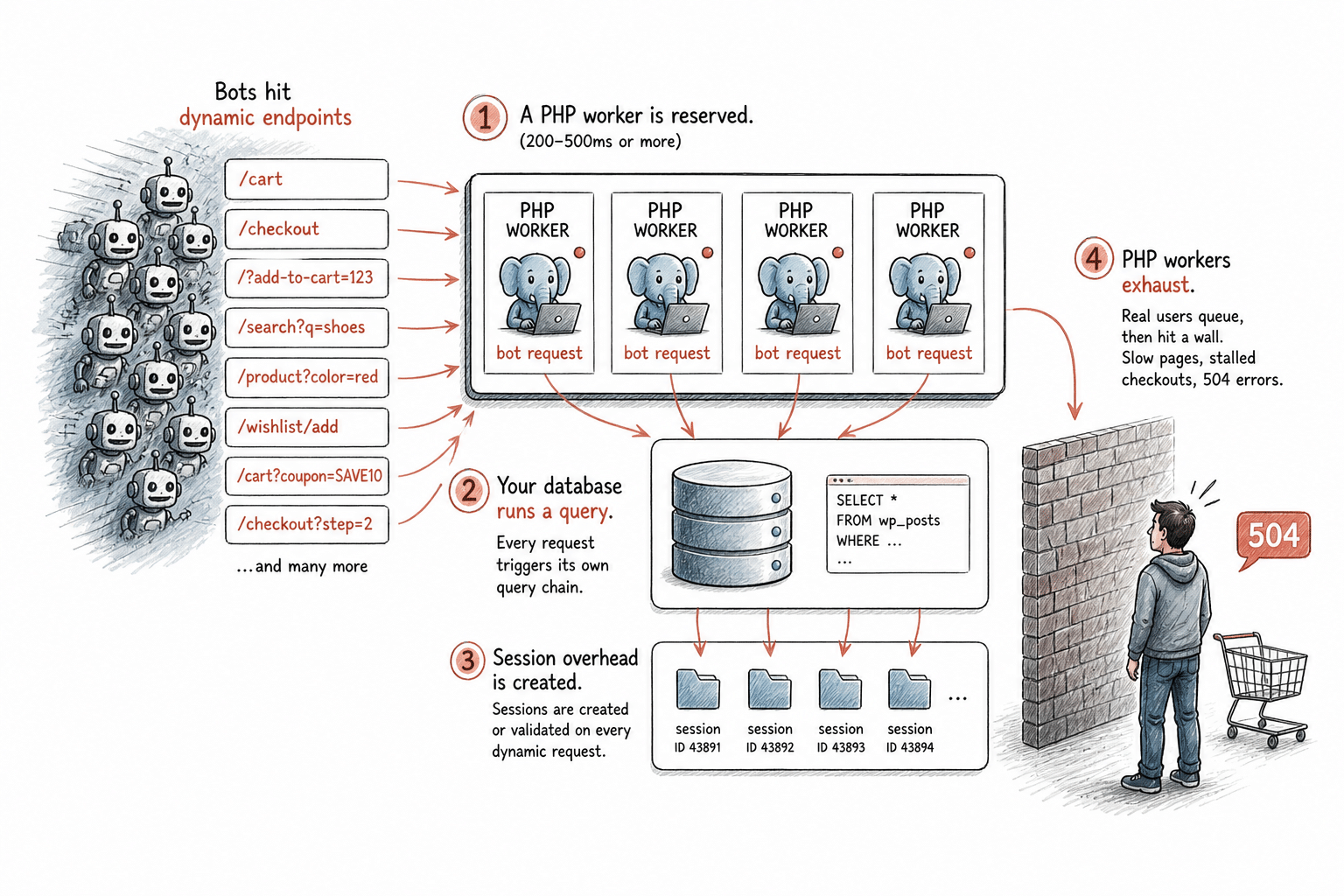
Este es el mecanismo por el que el tráfico de bots se convierte en un problema de infraestructura. No es algo teórico. Es la cadena concreta de acontecimientos que se produce cuando las solicitudes automatizadas inundan los endpoints dinámicos de una página de WordPress en funcionamiento.
Lo que realmente muestran los datos de infraestructura de Kinsta
Lo abstracto se vuelve concreto cuando analizas datos reales de la infraestructura que gestionamos a gran escala.
Un dato que nos ha llamado especialmente la atención es que un solo bot (ClaudeBot) generó 3,75 millones de solicitudes de añadir al carrito en un plazo de 24 horas. Eso supone aproximadamente una solicitud cada 23 milisegundos (día y noche), y el servidor las trata a todas como solicitudes nuevas porque los endpoints del carrito son dinámicos por naturaleza.
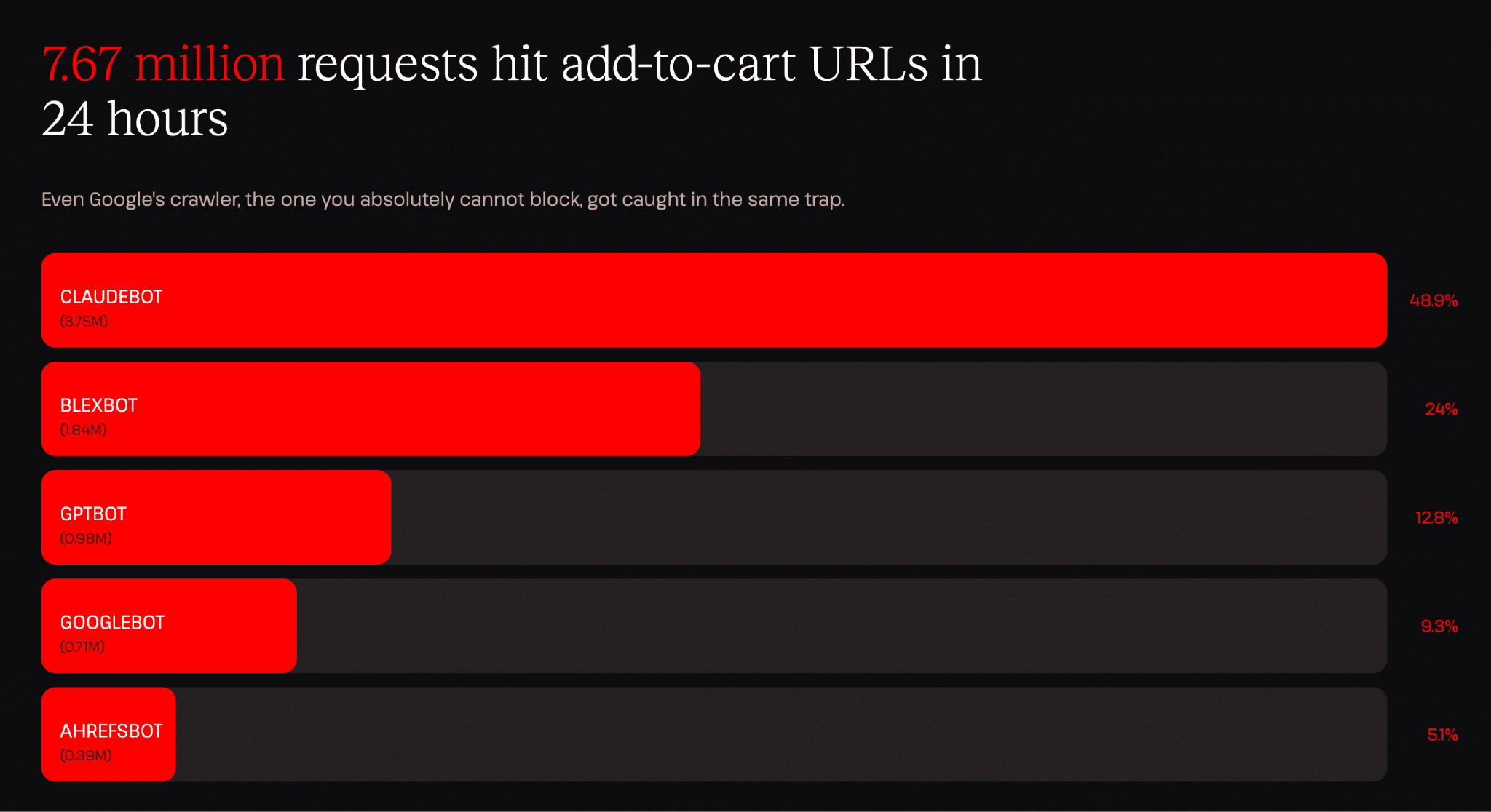
Para ponerte esto en contexto: las solicitudes de añadir al carrito están entre los endpoints más costosos que tiene una tienda de WooCommerce. Crean sesiones, ejecutan consultas y actualizan el estado del carrito. Cada una supone un trabajo de verdad. Los 3,75 millones de solicitudes que vimos procedentes de una sola fuente en un día es el tipo de patrón de tráfico que puede dejar un sitio fuera de servicio.
Un segundo dato subraya lo persistentes que pueden ser estos patrones: un bucle defectuoso generó 550 millones de solicitudes en 30 días, suficiente tráfico como para justificar su propia regla de mitigación dedicada en nuestra infraestructura. No se trata de un ataque DDoS ni de una campaña de malware, sino de un bot atascado en un bucle de rastreo, que solicita una y otra vez URLs que ya ha visitado.
No son casos aislados. Son patrones que observamos en toda nuestra plataforma.
El problema del bucle: los bots no están atacando, están atascados
Uno de los aspectos más subestimados del problema actual del tráfico de bots es que la mayor parte de lo que causa daños en la infraestructura no tiene nada de malicioso. Se trata de una automatización ineficaz a gran escala.
Los sitios web modernos, sobre todo las tiendas online, generan URLs ligeramente diferentes para lo que, en esencia, es la misma página:
- Un producto con un filtro de color añadido
- Una página de carrito con un token de sesión
- Una vista de categoría con un parámetro de ordenación
Para un humano, todas estas son «la misma página». Para un bot que sigue las URL, cada una parece una página nueva que rastrear.
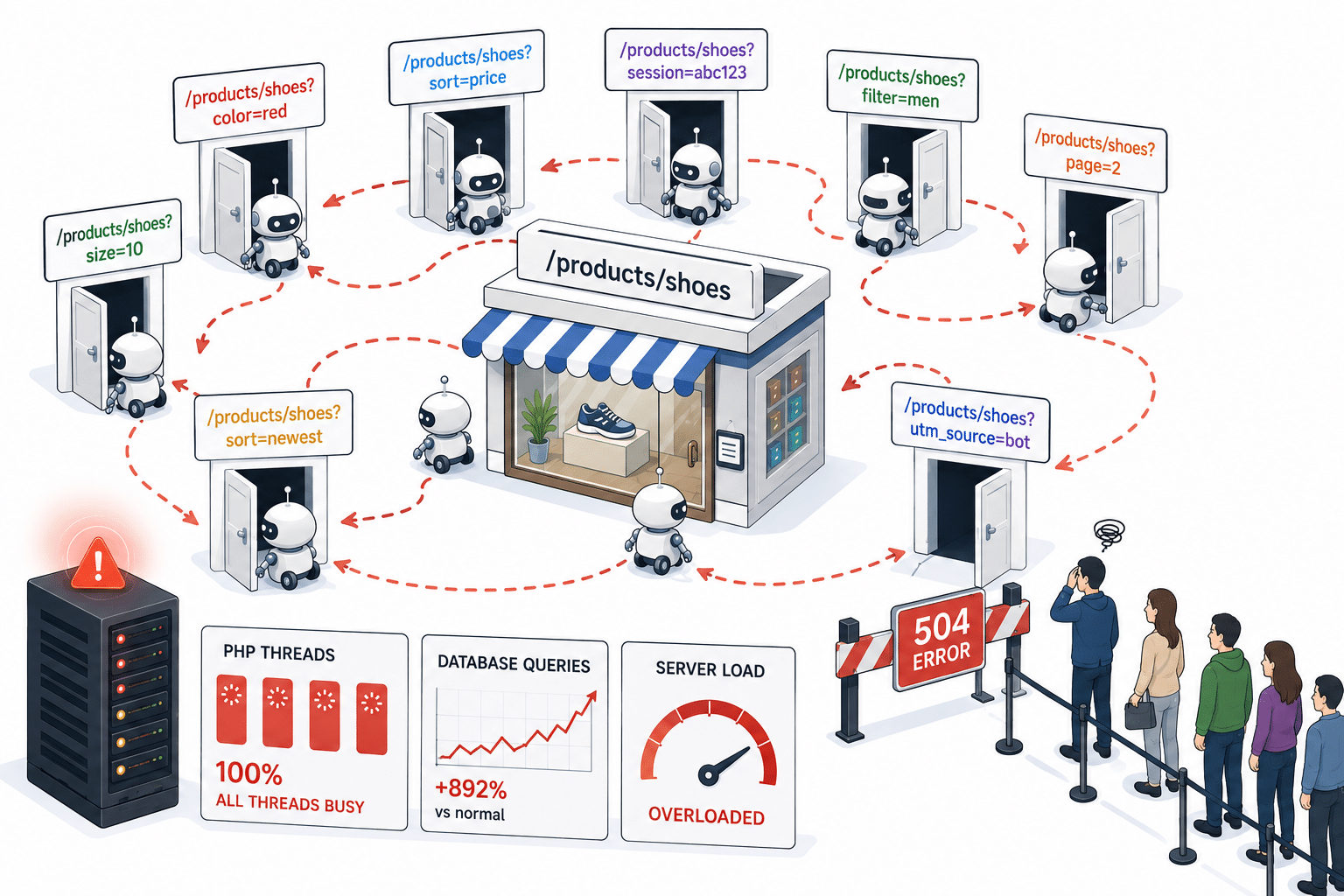
Así que el bot sigue el primer enlace. Esa página genera otra variante de la URL, a la que el bot sigue. Luego otra. Y otra más. No tiene ningún mecanismo para darse cuenta de que está dando vueltas en círculo, y algunos de estos bucles pasaron desapercibidos en la infraestructura supervisada durante varios días antes de que las reglas de mitigación los detectaran.
En el informe sobre tráfico de IA y bots que publicamos hace poco, David Belson, antiguo jefe de Análisis de Datos en Cloudflare, comentó: «Hay gente que ayer no tenía ni idea de lo que estaba haciendo, pero hoy ha programado un bot sobre la marcha y lo ha soltado. Ni siquiera se molestan en consultar el archivorobots.txt«.
Este comportamiento no siempre viene de gente con malas intenciones. Viene de sistemas de rastreo basados en IA que no se diseñaron teniendo en cuenta la navegación por facetas, la proliferación de parámetros en las URLs o las URLs generadas por sesión, que son funcionalidades habituales en los sitios web modernos de WordPress.
El propio Google identifica explícitamente la navegación por facetas y las URLs basadas en parámetros como una fuente de ineficiencia en el rastreo, señalando que los bots pueden explorar variaciones casi infinitas de la misma página.
La factura del servidor ahora es un problema de gestión de bots
Hasta hace poco, muchos planes de alojamiento se dimensionaban en función del número de visitas, lo que funcionaba razonablemente bien como indicador del uso real por parte de personas. Se partía de la base de que las visitas se correspondían, más o menos, con el número de personas que interactuaban con tu sitio.
Esa suposición ya no se sostiene.
El tráfico automatizado ha inflado las cifras de visitas de una forma que poco tiene que ver con la actividad real del negocio. Las solicitudes de los bots pueden generar visitas sin que eso se traduzca en interacción, conversiones o ingresos. Los propietarios de las páginas web recibían avisos de sobreconsumo en los planes basados en visitas debido a la actividad de los bots, algo que no podían controlar y que no habían solicitado.
Esto quedó tan claro como patrón sistémico que Kinsta lanzó planes de alojamiento basados en el ancho de banda como respuesta directa a un tipo de sitios web cuyas métricas de visitas habían empezado a desviarse significativamente de su consumo real de recursos. Si las visitas de un sitio web aumentaban pero el ancho de banda no seguía el ritmo, eso casi siempre era señal de que había bots. Pasar a un modelo basado en el ancho de banda desvinculó de forma efectiva la facturación de una métrica que los bots habían aprendido a inflar.
El problema de la facturación es cuantificable y se puede solucionar. Lo más complicado es que la mayoría de los propietarios de sitios web no se dan cuenta de que esto está pasando porque sus paneles de control no muestran el panorama completo.
Lo que tus estadísticas te dicen (y lo que no te dicen)
Una de las consecuencias del tráfico de bots a esta escala es que las herramientas de analítica estándar ya no son una fuente fiable para conocer el rendimiento real de tu sitio web.
Si tus cifras de visitas están subiendo, pero los ingresos, el tiempo de permanencia en la página y la tasa de rebote no varían en la misma proporción, es probable que los bots tengan algo que ver. Si tu servidor muestra una disminución del rendimiento que no se corresponde con los picos de tráfico que cabría esperar por el contenido o las acciones de marketing, merece la pena investigar el tráfico de bots hacia endpoints sin caché.
Kinsta filtra automáticamente los agentes de usuario de bots conocidos de las estadísticas y de los cálculos de uso del plan. Pero el tráfico automatizado que se asemeja mucho al comportamiento humano puede seguir apareciendo en tus métricas.
Los patrones a los que debes prestar atención:
- Solicitudes repetidas a los mismos tipos de URL, sobre todo rutas con muchos parámetros o basadas en sesiones
- Picos de tráfico en momentos que no se corresponden con ninguna actividad de publicación, promocional o estacional
- Deterioro del rendimiento del servidor (aumento del TTFB, errores por agotamiento de hilos de PHP) durante periodos de tráfico elevado que no se corresponden con acontecimientos del mundo real
- Aumento del número de visitas más rápido que el ancho de banda, las conversiones o las métricas de interacción
Ninguno de estos factores es concluyente por sí solo, pero cualquier combinación de ellos justifica una investigación antes de atribuir las cifras al crecimiento del negocio.
Por qué este problema es más complicado de lo que parece
Lo más habitual cuando te enfrentas a datos de tráfico de bots es bloquearlo todo. Otros quizá lo permitan todo, porque «la IA es el futuro».
¡Ninguna de las dos opciones funciona!
Bloquear sin distinción significa bloquear rastreadores verificados, incluido Googlebot, cuya cobertura de rastreo determina si tu contenido aparece o no en los resultados de búsqueda. Significa bloquear los bots de descubrimiento de IA que podrían estar mostrando tu contenido en resultados de búsqueda conversacional, recomendaciones basadas en IA o motores de respuestas. Para una tienda de WooCommerce o un editor de contenido, eso supone un coste de distribución significativo.
Permitir todo significa asumir costes de infraestructura que no generan ningún beneficio. Y en el caso de los endpoints dinámicos, que suelen ser los más afectados por los bots, esos costes no son insignificantes. Se acumulan y se multiplican, sobre todo bajo una carga automatizada constante.
La respuesta real está en algún punto intermedio, y requiere entender las diferencias entre las categorías de tráfico en lugar de tratar a todos los bots como si fueran lo mismo.
Como comentó Cristian López, editor jefe de HostingAdvice, en el informe: «El error es pensar que el tráfico de bots es un simple problema de “bloquear o permitir”. En realidad, se trata de política, visibilidad y control económico».
Por lo general, se debería permitir el acceso a los bots verificados, como Googlebot, Bing y las herramientas de monitorización legítimas, aunque se pueden aplicar restricciones de ruta a los endpoints que no aporten nada al rastreo (tu página de pago, por ejemplo, no contribuye en nada a tu posicionamiento en los buscadores). Los bots no verificados que no tengan información identificativa ni un propósito claro merecen más atención. Los rastreadores de entrenamiento de IA que generan un gran volumen de solicitudes a endpoints dinámicos constituyen una categoría específica que puede justificar el bloqueo o la limitación de la tasa de solicitudes, dependiendo del tipo de tu sitio web y de tus prioridades.
En nuestro informe sobre tráfico de IA y bots, hemos creado un framework interactivo que te guía por el enfoque adecuado para cada tipo de sitio web. El ejemplo que aparece a continuación muestra la configuración recomendada para una tienda de WooCommerce, centrada en el rendimiento y la estabilidad del sitio:
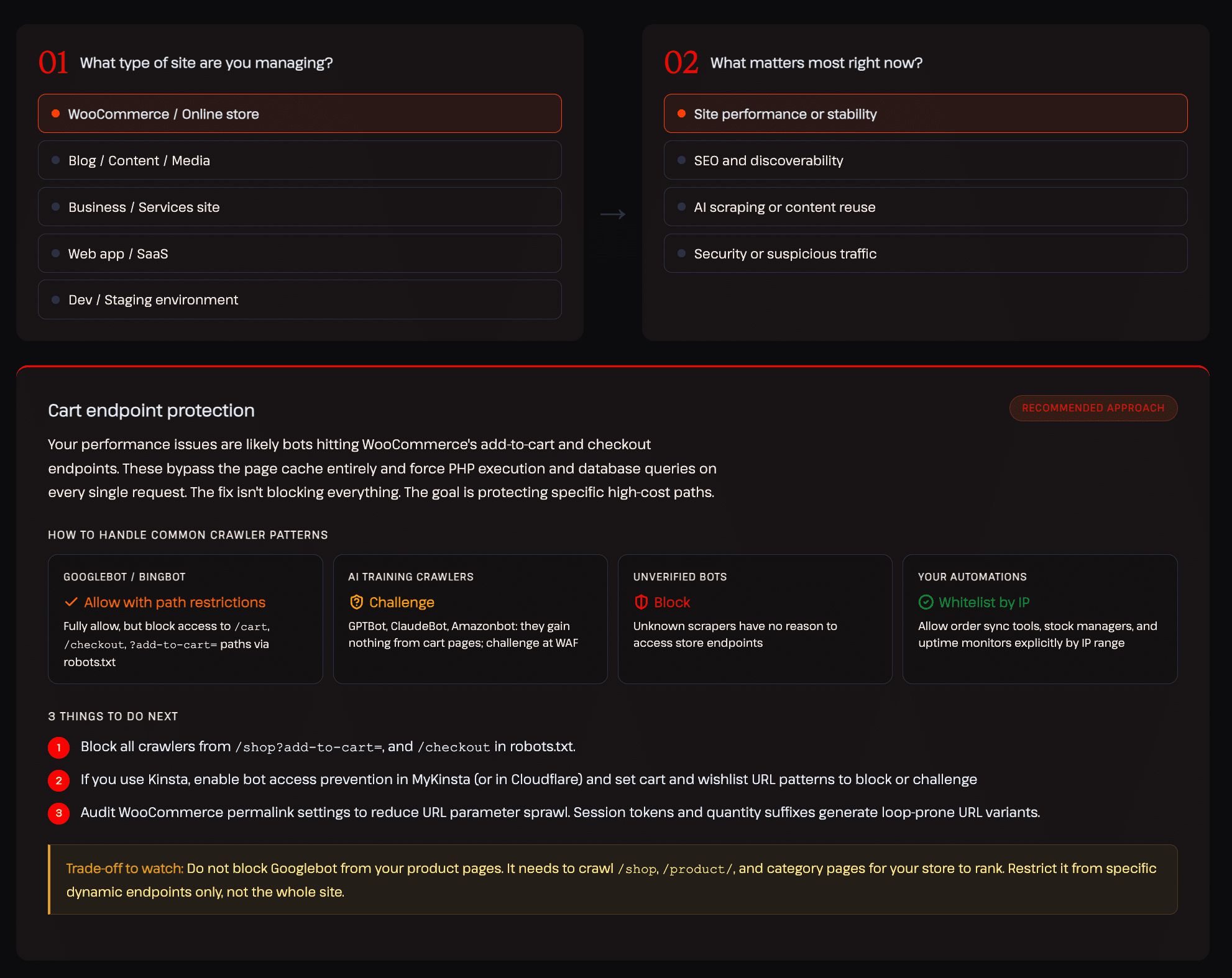
Ese tipo de control matizado y que tiene en cuenta las categorías es precisamente lo que la mayoría de las herramientas existentes no te ofrecen.
El enfoque de protección contra bots de Kinsta
Lo que hemos creado con la protección contra bots de Kinsta se diseñó específicamente para hacer frente a los retos de infraestructura que hemos descrito anteriormente.
El sistema clasifica el tráfico en categorías como bots verificados, probablemente humanos, probablemente bots, tráfico automatizado y tráfico malicioso, y te permite establecer niveles de protección que se adapten a las necesidades reales de tu sitio web.

Los niveles no son binarios. La opción «Bloquear automatizaciones» se centra en el tráfico automatizado confirmado, sin afectar a los bots verificados. «Desafiar a los bots» añade un paso de verificación para las automatizaciones no verificadas sin molestar a los visitantes legítimos. La opción «Desafiar a todos» está disponible para periodos de gran presión de tráfico, pero tiene las desventajas que cabría esperar.
Lo más importante es que la herramienta se basa en el sistema de puntuación de bots de nivel empresarial de Cloudflare, una clasificación en tiempo real basada en aprendizaje automático que asigna a cada visitante una puntuación del 1 al 99 según señales de comportamiento, y no solo según las cadenas de agente de usuario. Esto es importante porque la simple comparación de agentes de usuario es cada vez menos eficaz, ya que el 12,9 % de los bots de IA ahora ignoran las directivas robots.txt, frente al 3,3 % de tan solo un trimestre antes. La clasificación basada en el comportamiento detecta lo que se les escapa a las reglas basadas en el agente de usuario.
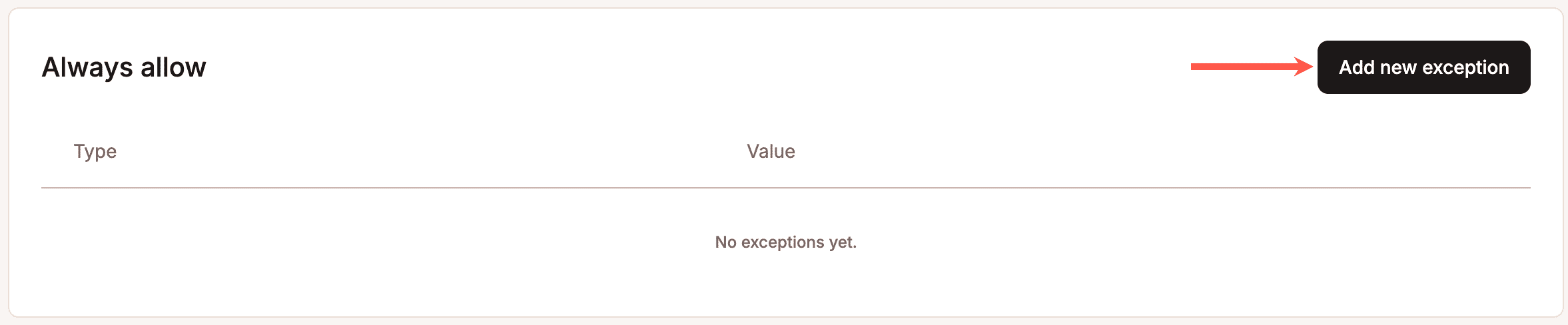
También hay un sistema de excepciones Permitir Siempre para integraciones de confianza, servicios de monitorización y automatizaciones críticas para el negocio que no deberían verse afectadas por las reglas de protección, ya que el bloqueo excesivo también supone un coste real, sobre todo para las tiendas de WooCommerce que dependen de la sincronización automática de pedidos, las integraciones con pasarelas de pago o los monitores de disponibilidad.
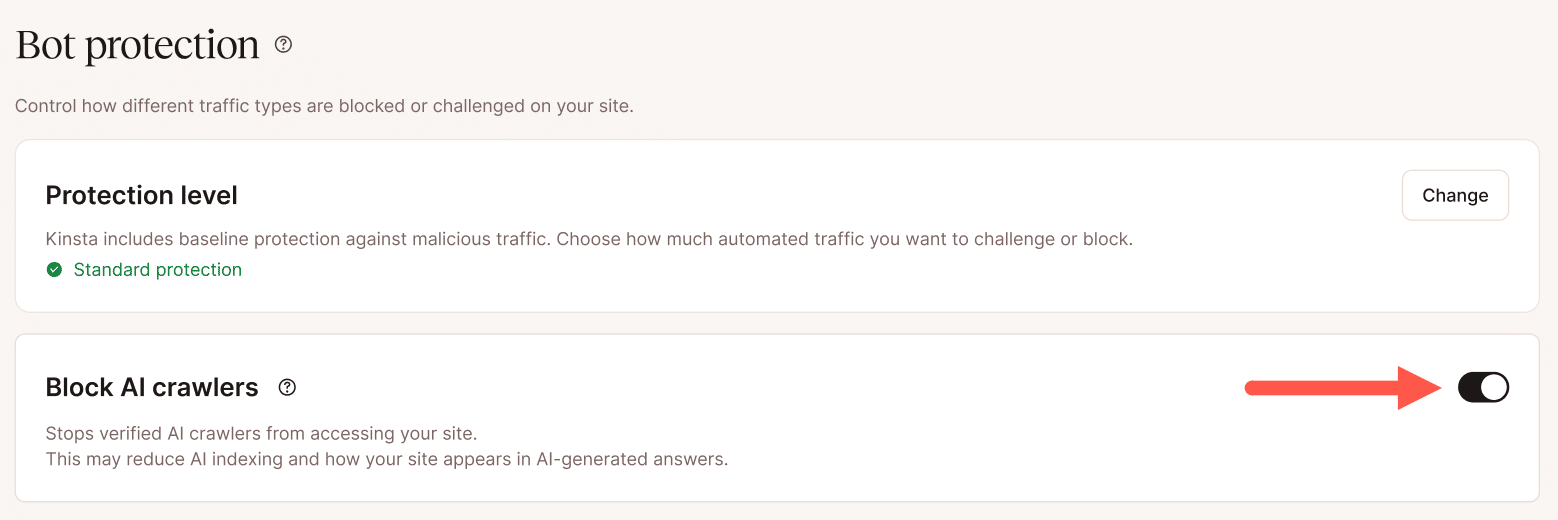
El interruptor para bloquear los rastreadores de IA se centra específicamente en los bots de entrenamiento de IA sin afectar a los rastreadores de los motores de búsqueda, como Googlebot o Bingbot. Para los sitios web que hayan identificado la actividad de los rastreadores de IA como un factor que mejora el rendimiento, esta es una medida de mitigación que se aplica en un solo paso y que no requiere configurar reglas individuales.
Una cosa es saber que la herramienta existe. Otra muy distinta es saber cuándo y cómo usarla.
Qué hacer si el tráfico de bots es tu problema
Si observas los patrones descritos anteriormente, aquí tienes un punto de partida práctico, ordenado por impacto:
Primero: verifica la fuente. Usa el gráfico de desglose de solicitudes en la vista de protección contra bots de MyKinsta para entender cómo se clasifica el tráfico de tu sitio web.
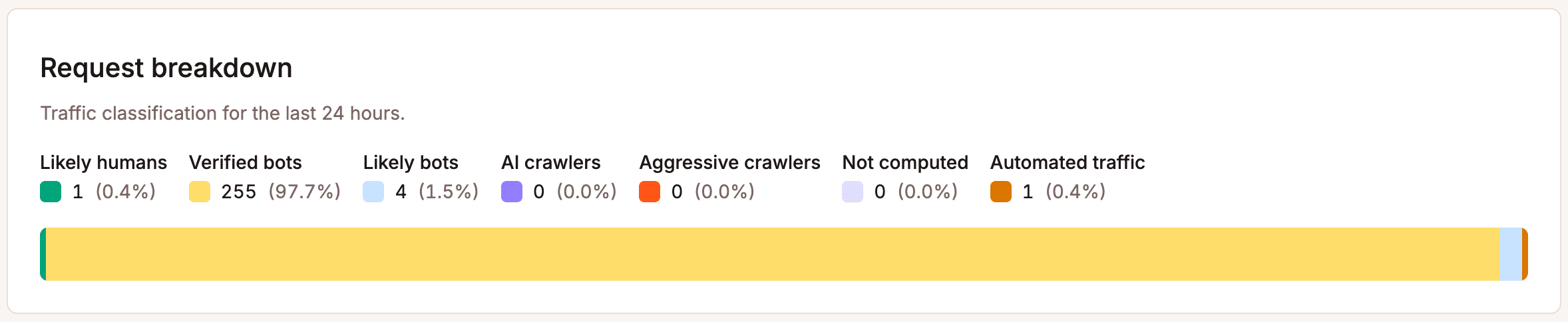
Si una parte importante es automatizada o no verificada, esa es tu señal para actuar. No te saltes este paso, ya que realizar cambios en la protección sin saber contra qué te estás protegiendo lleva a configuraciones erróneas.
Segundo: adapta el nivel de protección al tipo de sitio. Una tienda de WooCommerce tiene prioridades distintas que un sitio de publicación de contenidos, que a su vez tiene otras prioridades que un entorno de staging. Bloquear el tráfico automatizado y poner trabas a los posibles bots tiene sentido para una tienda con puntos de acceso dinámicos. Un sitio de contenidos podría dar prioridad a permitir el acceso a los bots de descubrimiento de IA, mientras que bloquearía los rastreadores de entrenamiento de IA. En cualquier caso, un entorno de staging debería estar totalmente bloqueado.
Tercero: protege primero las rutas más costosas. Antes de aplicar reglas de protección generales, piensa si tus endpoints más costosos, como el carrito, la proceso de pago y los controladores AJAX, son accesibles para rastreadores que no tienen por qué estar ahí. Bloquear los user-agents de bots conocidos en /cart y ?add-to-cart= a través de robots.txt es un buen punto de partida; pero aplicarlo a nivel del WAF (y no solo indicarlo) es lo que realmente evita la sobrecarga.
Cuarto: monitoriza y luego ajusta. Los patrones de tráfico de los bots cambian más rápido de lo que la mayoría de los propietarios de sitios web se dan cuenta. La cuota de tráfico de GPTBot se triplicó en solo un año. Establecer reglas de protección una vez y olvidarte de ellas no es una estrategia. El gráfico de resultados de protección contra bots de MyKinsta muestra lo que se bloquea, se revisa y se permite a lo largo del tiempo.
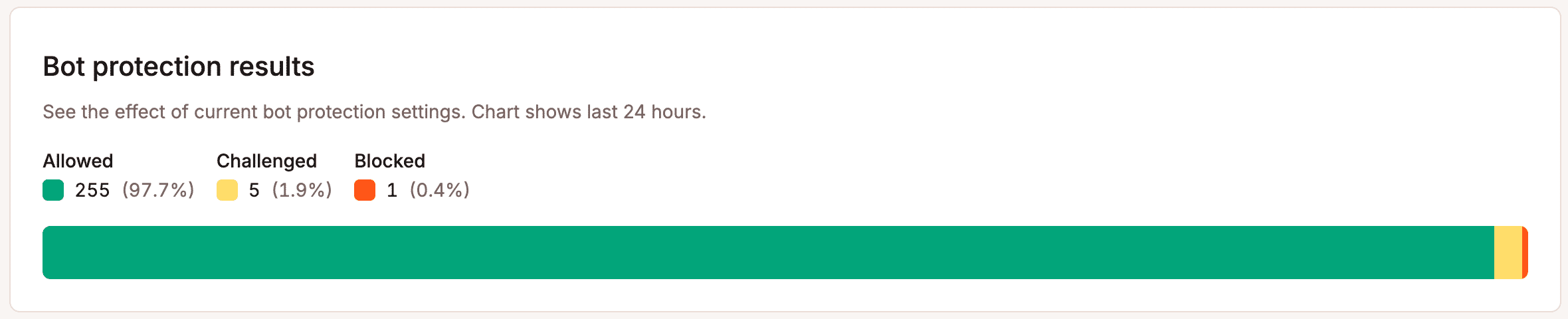
Estos datos deberían servirte de guía a la hora de ajustar tu configuración.
Si los bots están superando el límite de visitas en un plan basado en visitas, quizá también te interese revisar los planes de alojamiento basados en ancho de banda de Kinsta. Cambiar a un plan basado en ancho de banda no resuelve el problema subyacente de los bots, pero puede reflejar mejor el coste real de infraestructura de tu composición de tráfico, que suele ser bastante más bajo de lo que sugieren los recuentos de visitas.
El panorama general: este problema se va a complicar
El tráfico de agentes ya está apareciendo en los registros de la infraestructura. Google ha anunciado un agente de usuario específico para cuando sus agentes de IA interactúen con los sitios web. Se trata de sistemas automatizados que hacen clic en enlaces, rellenan formularios y realizan solicitudes que se parecen cada vez más al comportamiento de una sesión humana.
Las señales que ahora mismo sirven para clasificar los bots, como las cadenas de agente de usuario, la frecuencia de las solicitudes y la puntuación de comportamiento, se vuelven más difíciles de aplicar con claridad a medida que la línea entre la interacción automatizada y la humana se difumina cada vez más.
La mayoría de los propietarios de sitios web no pueden seguir el ritmo por sí solos. El comportamiento de los bots evoluciona más rápido de lo que las reglas manuales pueden adaptarse. Lo que funcionaba hace tres meses puede que ya no sea suficiente. Y el coste de equivocarse — en recursos del servidor, en sobrecostes de facturación, en clientes reales que se encuentran con errores 504 al finalizar la compra— es real e inmediato.
Ahí es donde entra en juego una infraestructura que se encarga de ello por ti. La plataforma de Kinsta bloquea entre el 15 % y el 20 % del tráfico malicioso antes de que llegue a tu sitio web, se aloja en la red empresarial de Cloudflare y te ofrece controles de protección contra bots que se adaptan al comportamiento real de tu sitio web. A medida que el tráfico de bots sigue evolucionando, la diferencia entre una plataforma de alojamiento que trata esto como un problema de infraestructura y otra que lo considera una cuestión secundaria será cada vez más difícil de ignorar.
Los sitios que se manejen bien en esto no serán los que más bloqueen. Serán los que funcionen con una infraestructura diseñada para gestionar mejor los bots.


