
¿Alguna vez has querido comparar precios de varios sitios a la vez? ¿O tal vez extraer automáticamente una colección de posts de tu blog favorito? Todo es posible con el web scraping.
El web scraping se refiere al proceso de extracción de contenidos y datos de sitios web mediante software. Por ejemplo, la mayoría de los servicios de comparación de precios utilizan web scrapers para leer la información de precios de varias tiendas online. Otro ejemplo es Google, que rutinariamente scrapea o «rastrea» la web para indexar sitios web.
Por supuesto, estos son sólo dos de los muchos casos de uso del web scraping. En este artículo, nos sumergiremos en el mundo de los web scrapers, aprenderemos cómo funcionan y veremos cómo algunos sitios web intentan bloquearlos. ¡Sigue leyendo para saber más y empezar a scrapear!
¿Qué Es el Web Scraping?
El web scraping es un conjunto de prácticas utilizadas para extraer automáticamente — o «scrapear» — datos de la web.
Otros términos para referirse al web scraping son «scraping de contenidos» o «scraping de datos» Independientemente de cómo se llame, el web scraping es una herramienta extremadamente útil para la recopilación de datos online. Las aplicaciones del web scraping incluyen la investigación de mercado, la comparación de precios, la supervisión de contenidos y mucho más.
¿Pero qué es exactamente lo que «scrapea» el web scraping — y cómo es posible? ¿Es incluso legal? ¿Querría un sitio web que alguien viniera a scrapear sus datos?
Las respuestas dependen de varios factores. Sin embargo, antes de sumergirnos en los métodos y casos de uso, veamos más de cerca qué es el web scraping y si es ético o no.
¿Qué Podemos «Scrapear» de la Web?
Es posible scrapear todo tipo de datos de la web. Desde los motores de búsqueda y los feeds RSS hasta la información gubernamental, la mayoría de los sitios web ponen sus datos a disposición de los scrapers, crawlers y otras formas de recopilación automática de datos.
Estos son algunos ejemplos comunes.
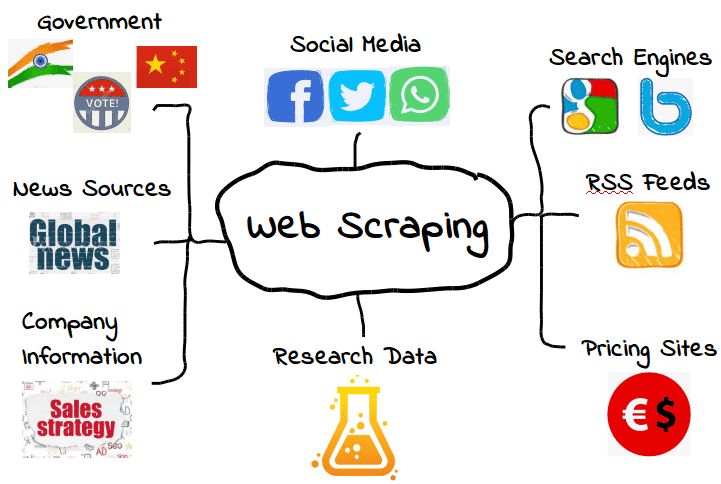
Sin embargo, eso no significa que estos datos estén siempre disponibles. Dependiendo del sitio web, puede que tengas que emplear algunas herramientas y trucos para obtener exactamente lo que necesitas — suponiendo que los datos sean accesibles en primer lugar. Por ejemplo, muchos scrapers web no pueden extraer datos significativos del contenido visual.
En los casos más sencillos, el scraping web puede hacerse a través de la API o interfaz de programación de aplicaciones de un sitio web. Cuando un sitio web pone a disposición su API, los desarrolladores web pueden utilizarla para extraer automáticamente datos y otra información útil en un formato conveniente. Es casi como si el host de la web te proporcionara tu propio «conducto» hacia sus datos. ¡Esto sí que es hospitalidad!
Por supuesto, no siempre es así — y muchos de los sitios web que quieres scrapear no tienen una API que puedas utilizar. Además, incluso los sitios web que tienen una API no siempre te proporcionarán los datos en el formato adecuado.
En consecuencia, el web scraping sólo es necesario cuando los datos de la web que quieres no están disponibles en la forma que necesitas. Tanto si eso significa que los formatos que quieres no están disponibles, como si el sitio web simplemente no proporciona todo el alcance de los datos, el web scraping permite obtener lo que quieres.
Aunque eso está muy bien, también plantea una cuestión importante: Si ciertos datos de la web están restringidos, ¿es legal scrapearlos? Como veremos en breve, puede ser una zona un poco gris.
¿Es Legal el Web Scraping?
Para algunas personas, la idea de scrapear la web puede parecer casi un robo. Después de todo, ¿quién eres tú para «coger» los datos de otra persona?
Afortunadamente, no hay nada intrínsecamente ilegal en el web scraping. Cuando un sitio web publica datos, normalmente están disponibles para el público y, por tanto, son libres de ser scrapeados.
Por ejemplo, dado que Amazon pone a disposición del público los precios de los productos, es perfectamente legal scrapear los datos de los precios. Muchas aplicaciones de compra populares y extensiones de navegador utilizan el web scraping con este mismo propósito, para que los usuarios sepan que están obteniendo el precio correcto.
Sin embargo, no todos los datos de la web están hechos para el público, lo que significa que no todos los datos de la web son legales para scrapear. Cuando se trata de datos personales y de propiedad intelectual, el web scraping puede convertirse rápidamente en web scraping malicioso, lo que puede dar lugar a sanciones como un aviso de retirada de la DMCA.
¿Qué Es el Web Scraping Malicioso?
El web scraping malintencionado es el web scraping que el editor no pretendía o no consintió compartir. Aunque estos datos suelen ser datos personales o de propiedad intelectual, el scraping malicioso puede aplicarse a cualquier cosa que no esté destinada al público.
Como puedes imaginar, esta definición tiene una zona gris. Mientras que muchos tipos de datos personales están protegidos por leyes como el Reglamento General de Protección de Datos (GDPR) y la Ley de Privacidad del Consumidor de California (CCPA), otros no lo están. Pero eso no significa que no existan situaciones en las que no sea legal su scrapeado.

Por ejemplo, supongamos que un alojamiento web pone «accidentalmente» a disposición del público la información de sus usuarios. Eso podría incluir una lista completa de nombres, correos electrónicos y otra información que es técnicamente pública, pero que tal vez no estaba destinada a ser compartida.
Aunque también sería técnicamente legal scrapear estos datos, probablemente no sea la mejor idea. El hecho de que los datos sean públicos no significa necesariamente que el administrador de la web haya consentido que se hayan scrapeado, aunque su falta de supervisión los haya hecho públicos.
Esta «zona gris» ha dado al «web scraping» una reputación algo mixta. Aunque el web scraping es definitivamente legal, puede utilizarse fácilmente con fines maliciosos o poco éticos. Por ello, a muchos proveedores de servicios web no les gusta que sus datos sean scrapeados, independientemente de que sea legal.
Otro tipo de web scraping malintencionado es el «over-scraping», en el que los scrapeadores envían demasiadas solicitudes en un periodo determinado. Demasiadas solicitudes pueden suponer una gran carga para los proveedores de servicios web, que prefieren gastar los recursos del servidor en personas reales que en bots de scrapeado.
Como regla general, utiliza el web scraping con moderación y sólo cuando estés completamente seguro de que los datos son de uso público. Recuerda que el hecho de que los datos estén disponibles públicamente no significa que sea legal o ético scrapearlos.
¿Para Qué Se Utiliza el Web Scraping?
En el mejor de los casos, el web scraping sirve para muchos propósitos útiles en muchas industrias. En 2021, casi la mitad del web scraping se utiliza para reforzar las estrategias de comercio electrónico.
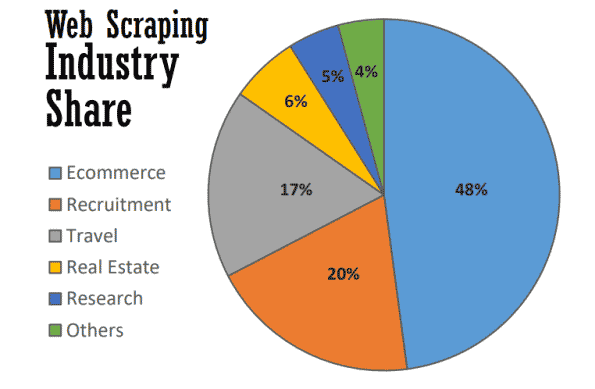
El web scraping se ha convertido en la columna vertebral de muchos procesos basados en datos, desde el seguimiento de las marcas y las comparaciones de precios actualizadas hasta la realización de valiosos estudios de mercado. He aquí algunos de los más comunes.
Estudio de Mercado
¿Qué hacen tus clientes? ¿Y tus clientes potenciales? ¿Cómo son los precios de tus competidores en comparación con los tuyos? ¿Tienes información para crear una campaña exitosa de inbound marketing o marketing de contenidos?
Éstas son sólo algunas de las preguntas que constituyen la piedra angular de la investigación de mercado — y las mismas que pueden responderse con el web scraping. Dado que muchos de estos datos están disponibles públicamente, el web scraping se ha convertido en una herramienta inestimable para los equipos de marketing que buscan vigilar su mercado sin tener que realizar una investigación manual que requiere mucho tiempo.
Automatización del Negocio
Muchas de las ventajas del web scraping para la investigación de mercado también se aplican a la automatización empresarial.
Cuando muchas tareas de automatización empresarial requieren la recopilación y el procesamiento de grandes cantidades de datos, el web scraping puede ser muy valioso — especialmente si hacerlo de otro modo es engorroso.
Por ejemplo, supongamos que necesitas reunir datos de diez sitios web diferentes. Aunque recojas el mismo tipo de datos de cada uno, cada sitio web puede requerir un método de extracción diferente. En lugar de pasar manualmente por diferentes procesos internos en cada sitio web, podrías utilizar un web scraper para hacerlo automáticamente.
Generación de Leads
Como si la investigación de mercado y la automatización del negocio no fueran suficientes, el web scraping también puede generar valiosas listas de clientes potenciales con poco esfuerzo.
Aunque tendrás que establecer tus objetivos con cierta precisión, puedes utilizar el web scraping para generar suficientes datos de usuarios para crear listas de leads estructuradas. Los resultados pueden variar, por supuesto, pero es más conveniente (y más prometedor) que crear listas de leads por tu cuenta.
Seguimiento de Precios
La extracción de precios — también conocida como scraping de precios — es una de las aplicaciones más comunes del web scraping.
He aquí un ejemplo de la popular aplicación de seguimiento de precios de Amazon Camelcamelcamel. La aplicación extrae regularmente los precios de los productos y luego los compara en un gráfico a lo largo del tiempo.
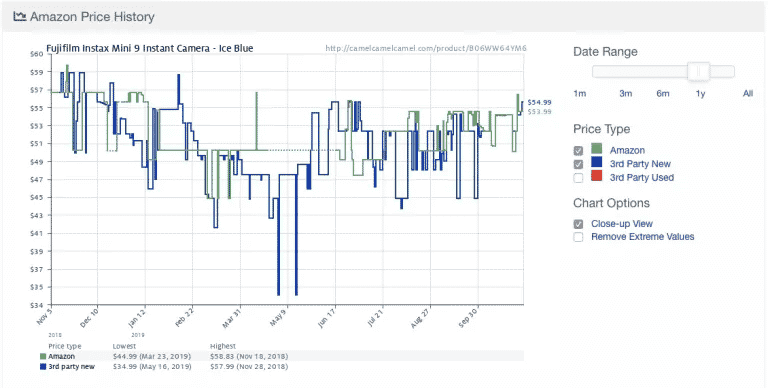
Los precios pueden fluctuar mucho, incluso a diario (¡mira la repentina caída de los precios en torno al 9 de mayo!). Con el acceso a las tendencias históricas de los precios, los usuarios pueden comprobar si el precio que están pagando es el ideal. En este ejemplo, el usuario podría optar por esperar una semana más o menos con la esperanza de ahorrar 10$.
A pesar de su utilidad, el scraping de precios conlleva cierta controversia. Como mucha gente quiere actualizaciones de precios en tiempo real, algunas aplicaciones de seguimiento de precios se convierten rápidamente en maliciosas al sobrecargar ciertos sitios web con peticiones al servidor.
Como resultado, muchos sitios web de comercio electrónico han empezado a tomar medidas adicionales para bloquear totalmente a los web scraping, que trataremos en la siguiente sección.
Noticias y Contenidos
No hay nada más valioso que mantenerse informado. Desde el control de la reputación hasta el seguimiento de las tendencias del sector, el web scraping es una valiosa herramienta para mantenerse informado.
Aunque algunos sitios web de noticias y blogs ya ofrecen canales RSS y otras interfaces sencillas, no siempre son la norma — ni son tan comunes como antes. En consecuencia, la agregación de las noticias y contenidos exactos que necesitas suele requerir alguna forma de web scraping.
Monitorización de la Marca
Mientras estás scrapeando las noticias, ¿por qué no controlar tu marca? En el caso de las marcas que reciben mucha cobertura informativa, el web scraping es una herramienta inestimable para estar al día sin tener que revisar innumerables artículos y sitios de noticias.
El web scraping también es útil para comprobar el precio mínimo disponible de un producto o servicio de una marca (MAP). Aunque esto es técnicamente una forma de scraping de precios, es una información clave que puede ayudar a las marcas a determinar si sus precios se ajustan a las expectativas de los clientes.
Inmobiliaria
Si alguna vez has buscado un apartamento o has comprado una casa, sabes lo mucho que hay que clasificar. Con miles de anuncios dispersos en múltiples sitios web inmobiliarios, puede ser difícil encontrar exactamente lo que buscas.
Muchos sitios web utilizan el «web scraping» para agregar listados inmobiliarios en una única base de datos para facilitar el proceso. Algunos ejemplos populares son Zillow y Trulia, aunque hay muchos otros que siguen un modelo similar.
Sin embargo, la agregación de listados no es el único uso del web scraping en el sector inmobiliario. Por ejemplo, los agentes inmobiliarios pueden utilizar las aplicaciones de scraping para estar al tanto de los precios medios de alquiler y venta, los tipos de propiedades que se venden y otras tendencias valiosas.
¿Cómo Funciona el Scraping Web?
El scraping web puede parecer complicado, pero en realidad es muy sencillo.
Aunque los métodos y las herramientas pueden variar, todo lo que tienes que hacer es encontrar una manera de (1) navegar automáticamente por tu(s) sitio(s) web de destino y (2) extraer los datos una vez que estés allí. Normalmente, estos pasos se realizan con scrapers y crawlers.
Scrapeadores y Crawlers
En principio, el web scraping funciona casi igual que el caballo y el arado.

A medida que el caballo guía el arado, éste gira y rompe la tierra, ayudando a abrir paso a nuevas semillas, a la vez que reincorpora al suelo las malas hierbas y los residuos de las cosechas no deseadas.
Aparte del caballo, el web scraping no es muy diferente. En este caso, el crawler desempeña el papel del caballo, guiando al scraper — efectivamente nuestro arado — a través de nuestros campos digitales.
Esto es lo que hacen ambos.
- Crawlers (a veces conocidos como arañas) son programas básicos que navegan por la web buscando e indexando contenidos. Aunque los crawlers(rastreadores) guían a los web scrapers, no se utilizan exclusivamente para este fin. Por ejemplo, los motores de búsqueda como Google utilizan rastreadores para actualizar los índices y las clasificaciones de los sitios web. Los rastreadores suelen estar disponibles como herramientas preconstruidas que permiten especificar un determinado sitio web o término de búsqueda.
- Los scrapers hacen el trabajo sucio de extraer rápidamente la información relevante de los sitios web. Dado que los sitios web están estructurados en HTML, los scrapers utilizan expresiones regulares (regex), XPath, selectores CSS y otros localizadores para encontrar y extraer rápidamente determinados contenidos. Por ejemplo, puedes dar a tu web scraper una expresión regular que especifique el nombre de una marca o una palabra clave.
Si esto suena un poco abrumador, no te preocupes. La mayoría de las herramientas de web scraping incluyen rastreadores y scrapers integrados, lo que facilita la realización de los trabajos más complicados.
Proceso Básico del Web Scraping
En su nivel más básico, el web scraping se reduce a unos simples pasos:
- Especifica las URLs de los sitios web y las páginas que quieres scrapear
- Haz una petición HTML a las URL (es decir, «visita» las páginas)
- Utiliza localizadores como expresiones regulares para extraer la información deseada del HTML
- Guarda los datos en un formato estructurado (como CSV o JSON)
Como veremos en la siguiente sección, se puede utilizar una amplia gama de herramientas de web scraping para realizar estos pasos automáticamente.
Sin embargo, no siempre es tan sencillo — especialmente cuando se realiza el web scraping a gran escala. Uno de los mayores retos del web scraping es mantener tu scraper actualizado a medida que los sitios web cambian de diseño o adoptan medidas anti-scraping (no todo puede ser perenne). Aunque esto no es demasiado difícil si sólo scrapeas unos pocos sitios web a la vez, scrapear más puede convertirse rápidamente en una complicación.
Para minimizar el trabajo extra, es importante entender cómo los sitios web intentan bloquear a los scrapers — algo que aprenderemos en la siguiente sección.
Herramientas de Web Scraping
Muchas funciones de web scraping están disponibles en forma de herramientas de web scraping. Aunque hay muchas herramientas disponibles, varían mucho en cuanto a calidad, precio y (por desgracia) ética.
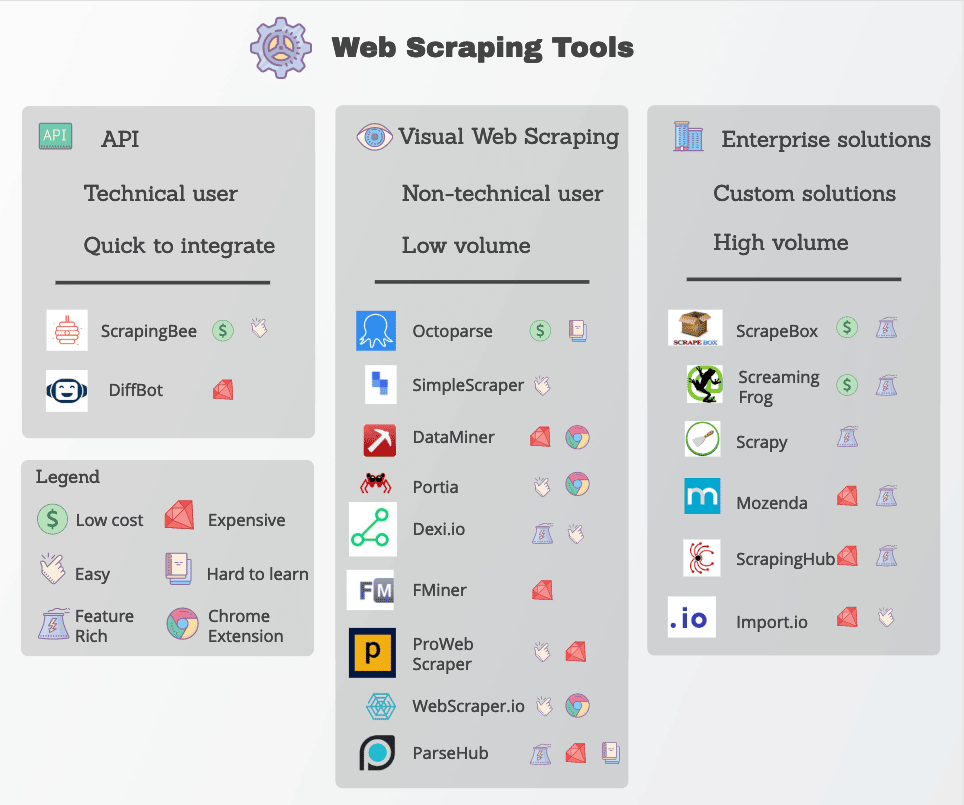
En cualquier caso, un buen web scraping será capaz de extraer de forma fiable los datos que necesitas sin toparse con demasiadas medidas anti-scraping. Aquí tienes algunas características clave que debes buscar.
- Localizadores precisos: Los web scrapers utilizan localizadores como expresiones regulares y selectores CSS para extraer datos específicos. La herramienta que elijas debe permitirte varias opciones para especificar lo que buscas.
- Calidad de los datos: La mayoría de los datos de la web no están estructurados, aunque se presenten claramente al ojo humano. Trabajar con datos no estructurados no sólo es desordenado, sino que rara vez ofrece buenos resultados. Asegúrate de buscar herramientas de scraping que limpien y clasifiquen los datos en bruto antes de su entrega.
- Entrega de datos: Dependiendo de tus herramientas o flujos de trabajo existentes, probablemente necesitarás los datos scrapeados en un formato específico, como JSON, XML o CSV. En lugar de convertir los datos en bruto tú mismo, busca herramientas con opciones de entrega de datos en los formatos que necesitas.
- Manejo del anti-scraping: El web scraping es tan eficaz como su capacidad para evitar los bloqueos. Aunque es posible que tengas que emplear herramientas adicionales, como proxies y VPN, para desbloquear sitios web, muchas herramientas de web scraping lo consiguen haciendo pequeñas modificaciones en sus rastreadores.
- Precios transparentes: Aunque algunas herramientas de web scraping son de uso gratuito, las opciones más robustas tienen un precio. Presta mucha atención al esquema de precios, especialmente si pretendes escalar y scrapear muchos sitios.
- Asistencia al cliente: Aunque utilizar una herramienta preconstruida es muy cómodo, no siempre podrás solucionar los problemas tú mismo. Por ello, asegúrate de que tu proveedor también ofrece un servicio de atención al cliente fiable y recursos para la resolución de problemas.
Entre las herramientas de web scraping más populares están Octoparse, Import.io y Parsehub.
Protección Contra el Scraping Web
Cambiemos un poco las tornas: Supongamos que eres un administrador web pero no quieres que otras personas utilicen todos estos métodos inteligentes para scrapear tus datos. ¿Qué puedes hacer para protegerte?
Más allá de los plugins de seguridad básicos, hay algunos métodos eficaces para bloquear los scrapers y rastreadores web.
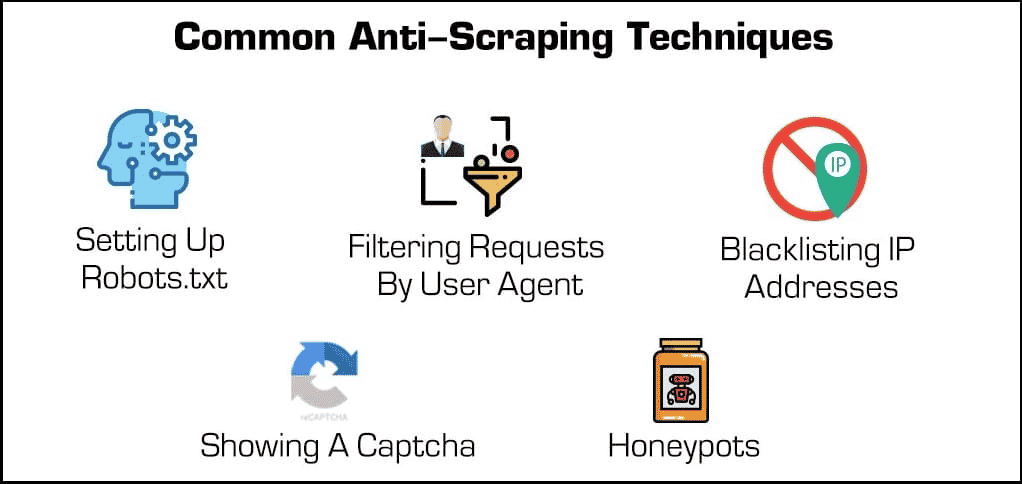
- Bloqueo de direcciones IP: Muchos proveedores de alojamiento web hacen un seguimiento de las direcciones IP de sus visitantes. Si un host observa que un visitante concreto está generando muchas peticiones al servidor (como en el caso de algunos scrapers o bots), puede bloquear la IP por completo. Sin embargo, los scrapers pueden superar estos bloqueos cambiando su dirección IP a través de un proxy o una VPN.
- Configurar el archivo robots.txt: Un archivo robots.txt permite a un anfitrión web indicar a los scrapers, crawlers y otros bots a qué pueden y no pueden acceder. Por ejemplo, algunos sitios web utilizan un archivo robots.txt para mantenerse privados, indicando a los motores de búsqueda que no los indexen. Aunque la mayoría de los motores de búsqueda respetan estos archivos, muchas formas maliciosas de web scraping no lo hacen.
- Filtrado de solicitudes: Cada vez que alguien visita un sitio web, está «solicitando» una página HTML al servidor web. Estas peticiones suelen ser visibles para los servidores web, que pueden ver ciertos factores de identificación, como las direcciones IP y user agents, como los navegadores web. Aunque ya hemos hablado del bloqueo de IPs, los servidores web también pueden filtrar por agente de usuario.
Por ejemplo, si un proveedor de alojamiento web observa que hay muchas solicitudes del mismo usuario que ejecuta una versión de Mozilla Firefox muy anticuada, podría simplemente bloquear esa versión y, al hacerlo, bloquear el bot. Estas capacidades de bloqueo están disponibles en la mayoría de los planes de alojamiento gestionado.
- Mostrar un Captcha: ¿Alguna vez has tenido que escribir una extraña cadena de texto o hacer clic en al menos seis veleros antes de acceder a una página? Entonces te has encontrado con un «Captcha» o completely automated public Turing test for telling computers and humans apart. Aunque sean simples, son increíblemente eficaces para filtrar a los scrapers de la web y otros bots.
- Los «honeypots»: Un «honeypot» es un tipo de trampa utilizada para atraer e identificar a los visitantes no deseados. En el caso de los web scraping, un administrador web puede incluir enlaces invisibles en su página web. Aunque los usuarios humanos no se darán cuenta, los bots los visitarán automáticamente al desplazarse, lo que permitirá a los admiinistradores web recopilar (y bloquear) sus direcciones IP o agentes de usuario.
Ahora volvamos a darle la vuelta a la tortilla. ¿Qué puede hacer un scraper para superar estas protecciones?
Aunque algunas medidas anti-scraping son difíciles de eludir, hay un par de métodos que suelen funcionar con frecuencia. Estos implican cambiar de alguna manera las características de identificación de tu scraper.
- Utiliza un proxy o una VPN: Dado que muchos alojamientos web bloquean a los web scraping en función de su dirección IP, a menudo es necesario utilizar varias direcciones IP para garantizar el acceso. Los proxies y las redes privadas virtuales (VPN) son ideales para esta tarea, aunque tienen algunas diferencias clave.
- Visita regularmente tus objetivos: La mayoría (si es que hay alguno) de los scrapers web te dirán cuando han sido bloqueados. Por lo tanto, es importante que compruebes regularmente desde dónde estás haciendo el scrapeo para ver si te han bloqueado o si el formato del sitio web ha cambiado. Ten en cuenta que una de estas cosas está prácticamente garantizada en algún momento.
Por supuesto, ninguna de estas medidas es necesaria si utilizas el web scraping de forma responsable. Si decides llevar a cabo el web scraping, ¡recuerda scrapea con moderación y respetar a tus anfitriones web!
Resumen
Aunque el web scraping es una herramienta poderosa, también supone una poderosa amenaza para muchos servidores web. Independientemente del lado del servidor en el que te encuentres, todo el mundo tiene interés en asegurarse de que el web scraping se utiliza de forma responsable y, por supuesto, para el bien.
Si eres un proveedor de alojamiento web que quiere controlar a los web scraping, no busques más que los planes de alojamiento gestionado de Kinsta. Puedes limitar los bots y salvaguardar datos y recursos valiosos con muchas herramientas de control de acceso disponibles.
Para obtener más información, programa una demo gratuita o ponte en contacto con un experto en alojamiento web de Kinsta hoy mismo.


