
Les problèmes de mise à l’échelle apparaissent rarement de nulle part. Ils s’accumulent généralement en silence jusqu’à ce qu’une campagne de lancement, un pic de trafic, une période de pointe saisonnière ou une expérience de paiement lente obligent tout le monde à y prêter attention.
Certaines équipes optimisent très tôt sur la base d’hypothèses. D’autres attendent que des ralentissements, des plaintes ou une augmentation des coûts rendent l’action inévitable. Les deux approches comportent des risques. L’une peut gaspiller votre budget. L’autre peut faire en sorte que votre site ne soit pas suffisamment préparé lorsque la croissance arrive.
L’analyse offre aux équipes un meilleur moyen de décider quand agir. Dans cet article, nous expliquons comment l’analyse peut être utilisée comme outil de planification pour révéler les seuils, les contraintes et les modèles d’utilisation avant qu’ils ne deviennent des problèmes plus importants.
Pourquoi les décisions de mise à l’échelle sont souvent prises trop tard
Les décisions de mise à l’échelle interviennent souvent au pire moment, après que quelque chose a déjà commencé à se briser.
Un site ralentit pendant une campagne. Le flux de paiement commence à s’essouffler en cas de pic de trafic. Les équipes internes commencent à signaler des problèmes qu’elles ne parviennent pas à expliquer. Ce qui aurait pu être un ajustement planifié se transforme en une réparation urgente du jour au lendemain.
Ce schéma réactif est courant car de nombreuses équipes n’ont pas une vision claire du moment où leur infrastructure approche de ses limites. Elles peuvent voir le trafic augmenter, mais ne pas comprendre comment cette croissance affecte les ressources du serveur, les performances du cache, la bande passante ou l’activité de la base de données. Elles attendent donc que les signes deviennent impossibles à ignorer.
L’inverse se produit également. Certaines équipes procèdent à des mises à niveau précoces par crainte d’une croissance future, même si les données n’indiquent pas une pression constante. Cela entraine des dépenses inutiles, en particulier lorsque le véritable problème aurait pu être résolu par une meilleure mise en cache, un nettoyage du code ou des modifications du flux de travail.
La mise à l’échelle réactive crée plusieurs problèmes qui rendent la croissance plus difficile à gérer :
Les décisions sont prises sous pression
Lorsque la mise à l’échelle est déclenchée par un ralentissement, une panne ou un pic de trafic, les équipes sont obligées de diagnostiquer les problèmes alors que l’entreprise en ressent déjà l’impact. Cette pression conduit à des choix précipités et à des solutions temporaires qui ne s’attaquent pas à la cause réelle.
La planification se transforme en conjecture
Au lieu d’utiliser les tendances pour guider les budgets et les calendriers, les équipes lient les décisions d’infrastructure aux situations d’urgence. Il est alors plus difficile de prévoir quand la capacité sera nécessaire ou d’en justifier le cout.
La confiance s’érode avec le temps
Lorsque chaque décision de mise à l’échelle semble urgente, les équipes commencent à remettre en question leur jugement. Elles ne savent pas si elles ont agi trop tard, trop tôt ou pour la mauvaise raison. Au fil du temps, l’infrastructure commence à être perçue comme un risque récurrent plutôt que comme quelque chose que l’on peut contrôler.
Les rapports vous disent ce qui s’est passé, mais les analyses opérationnelles vous disent ce qu’il faut faire ensuite
La plupart des équipes ont déjà accès à des rapports. Elles peuvent voir les tendances du trafic, les pages vues, les conversions et les sources de référence. Ces informations sont utiles, mais elles ne racontent qu’une partie de l’histoire.
Les rapports de surface indiquent les résultats. Ils vous indiquent combien de personnes ont visité votre site, ce qu’elles ont fait et si elles se sont converties. Ce qu’il ne montre pas, c’est la manière dont votre infrastructure a géré cette activité en coulisses. Cette lacune prend de plus en plus d’importance à mesure que vous vous développez.
Un pic de trafic peut ressembler à une victoire dans un tableau de bord de reporting, mais il n’explique pas si votre serveur était sous pression, si les threads PHP étaient au maximum, ou si la mise en cache a permis de faire fonctionner les choses en douceur. Deux sites peuvent connaitre la même augmentation du nombre de visites et avoir des résultats totalement différents en termes de performances, en fonction de la manière dont leurs ressources sont utilisées.
L’analyse opérationnelle permet d’aller plus loin. Au lieu de se concentrer uniquement sur les résultats, elles montrent ce qui se passe sous la surface. Les équipes peuvent voir comment les demandes sont traitées, comment les ressources sont utilisées et où la pression commence à monter. Des mesures telles que l’utilisation de la bande passante, l’efficacité du cache, l’activité des threads PHP et le comportement des réponses donnent aux équipes une image plus claire de la manière dont leur infrastructure gère la demande réelle.
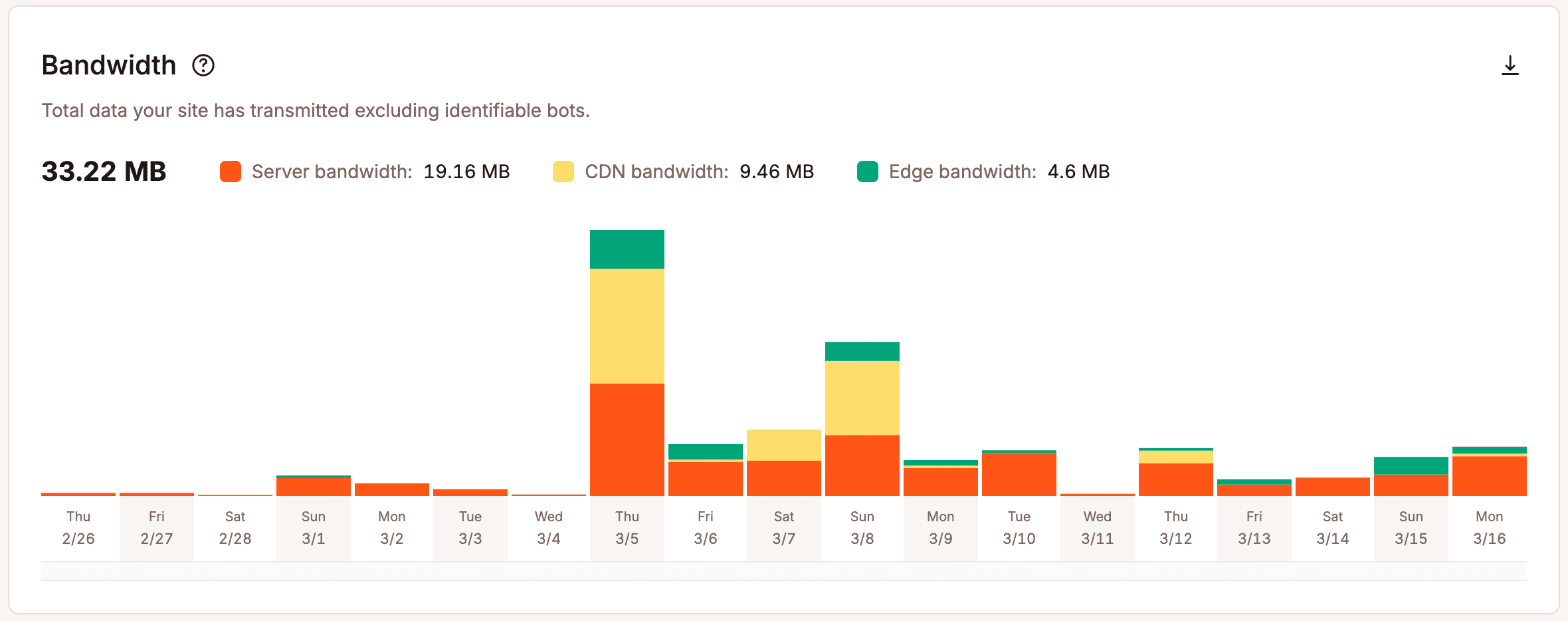
Sans cette visibilité, les décisions de mise à l’échelle deviennent subjectives. Les équipes réagissent à des incidents isolés, se fient à leur instinct ou planifient les pires scénarios sans en connaitre la probabilité.
Les signaux qui montrent qu’il est temps d’optimiser ou de faire évoluer le système
La vraie question n’est pas : « Pouvons-nous rendre le site plus rapide ? » La plupart des équipes peuvent toujours trouver quelque chose à régler, à nettoyer ou à améliorer.
La meilleure question est : « Qu’est-ce que les données nous indiquent de faire ensuite ? »
L’analyse aide les équipes à faire la distinction entre une anomalie temporaire et un véritable problème de capacité. Au lieu d’agir sur la base de vagues préoccupations, elles peuvent examiner des signaux mesurables qui indiquent quand l’optimisation ou la mise à l’échelle doit être prise en compte.
Tendances du trafic qui ne cessent d’augmenter
Un pic de trafic unique ne signifie pas toujours qu’un site a besoin de plus de ressources. Il peut résulter d’une campagne d’e-mailing ponctuelle, d’une mention sociale, d’une opération de relations publiques ou d’un évènement saisonnier. Ces moments méritent d’être examinés, mais ils n’indiquent pas toujours un besoin d’expansion à long terme.
Une croissance soutenue est une autre histoire. Si les visites, les requêtes ou les activités de connexion continuent d’augmenter au fil du temps, il se peut que votre configuration actuelle doive être examinée de plus près. Des augmentations répétées peuvent progressivement accroitre la pression sur les ressources du serveur, l’activité de la base de données, les couches de mise en cache et la bande passante.
Les données sur les tendances aident les équipes à planifier à l’avance. Lorsqu’elles constatent que le trafic augmente mois après mois, elles peuvent tester les performances, identifier les points faibles et apporter des améliorations avant que la croissance ne ralentisse.
Modèles d’utilisation des ressources indiquant une tension
Le trafic seul n’indique pas à quel point votre site travaille dur. Même un nombre modeste de visiteurs peut mettre le site à rude épreuve lorsque des pages dynamiques, des requêtes de base de données lourdes, une faible mise en cache ou des processus d’arrière-plan consomment des ressources excessives.
Les analyses au niveau de l’hébergement montrent où la pression s’accumule. Les équipes peuvent examiner l’utilisation des threads PHP, la consommation de la bande passante, les taux de réussite et d’échec du cache, l’activité de la base de données, les codes de réponse et le volume des requêtes.
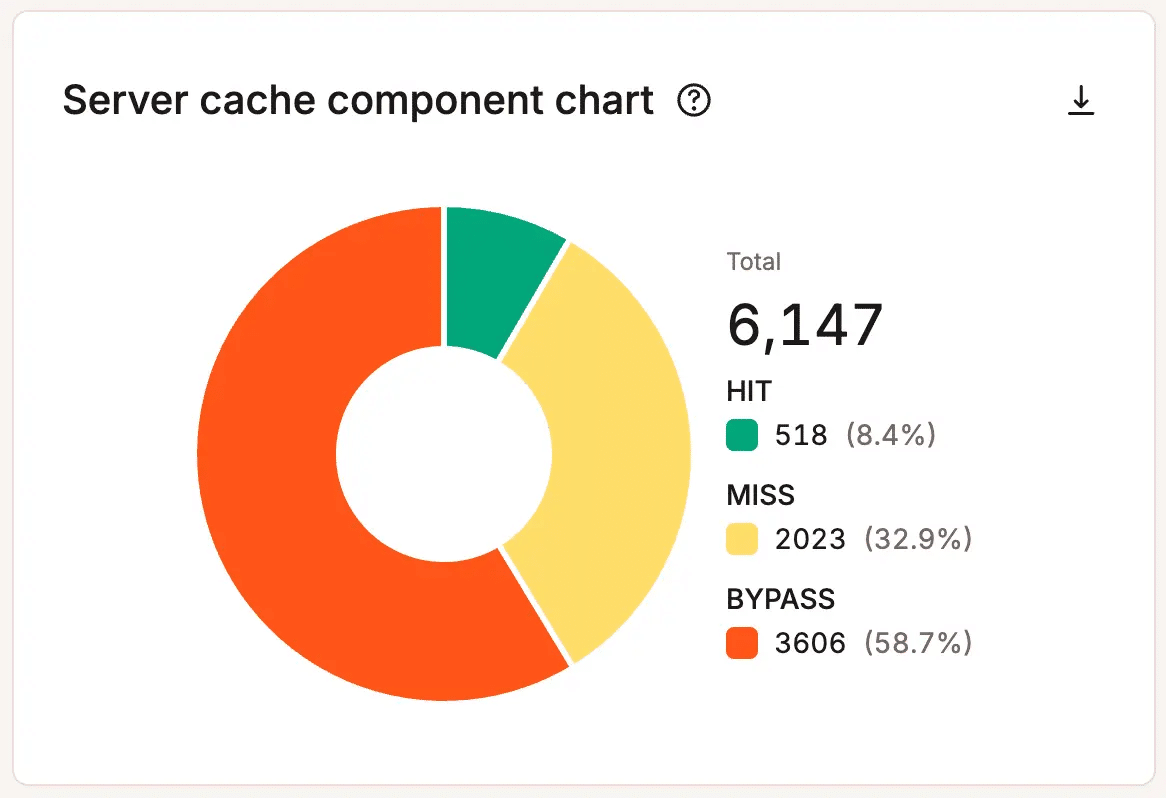
Recherchez des schémas, et non des pics ponctuels. Une brève augmentation du nombre de threads PHP pendant une heure d’affluence peut ne pas avoir d’importance. En revanche, des pics répétés, des demandes croissantes de bande passante ou des performances de cache toujours faibles peuvent indiquer que votre site a besoin d’être optimisé, de revoir son flux de travail ou d’augmenter sa capacité.
Problèmes de performance apparaissant dans des conditions spécifiques
Certains problèmes de performances n’apparaissent que lorsque votre site est sous pression. Un site peut être rapide en temps normal, puis ralentir lors du lancement d’un produit, d’une collecte de fonds, d’une période d’inscription, d’une promotion du Black Friday ou d’une campagne de contenu importante.
Ces moments révèlent souvent les véritables limites de votre configuration actuelle.
L’analyse aide les équipes à déterminer si le problème est temporaire, récurrent ou susceptible de s’aggraver. Si les performances ne baissent que lors de rares pics de trafic, l’équipe devra peut-être améliorer la préparation de la campagne. Si les ralentissements se produisent à chaque fois que la demande augmente, le site a probablement besoin d’une optimisation plus poussée ou d’une configuration d’hébergement plus évolutive.
Erreurs et anomalies qui deviennent des signes d’alerte précoce
Les erreurs, les requêtes qui échouent et les activités inhabituelles peuvent alerter les équipes avant que les visiteurs n’en ressentent pleinement l’impact.
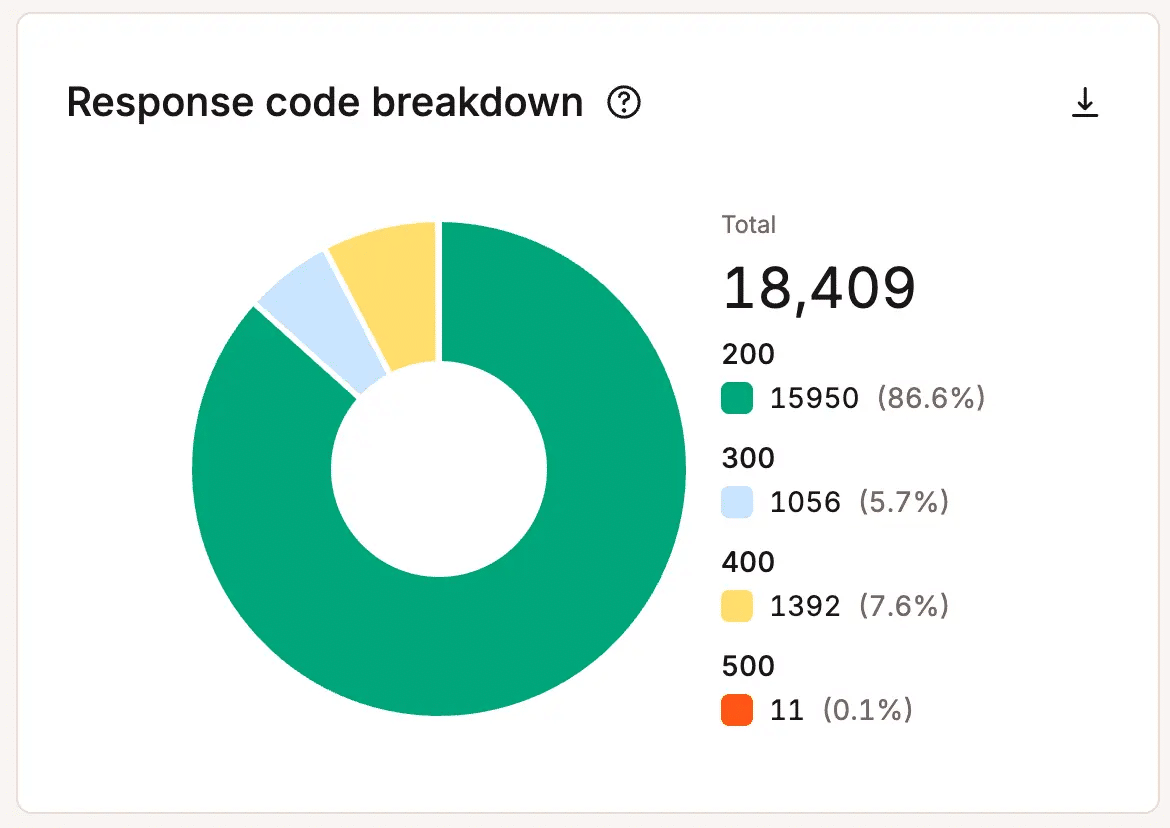
L’augmentation des taux d’erreur peut indiquer une surcharge de l’infrastructure, des problèmes d’application, des goulets d’étranglement au niveau des ressources ou des processus défaillants. Des schémas de trafic inhabituels peuvent révéler la présence de robots, de requêtes abusives ou d’une demande inattendue qui utilise les ressources sans créer de valeur commerciale.
Ces signaux donnent aux équipes la possibilité d’agir rapidement. Lorsqu’elles voient les erreurs et les anomalies dans leur contexte, elles peuvent en rechercher la cause, réduire les contraintes inutiles et protéger l’expérience client avant que les petits signes d’alerte ne se transforment en problèmes visibles.
Comment l’analyse permet de prendre des décisions plus intelligentes en matière de dimensionnement
L‘analyse aide les équipes à passer de l’idée que « quelque chose ne va pas » à « voici ce que les données montrent » Ce changement rend les décisions d’expansion plus pratiques, moins réactives et plus faciles à défendre.
Elle aide également les équipes à choisir la bonne étape suivante. Tous les ralentissements ou pics ne nécessitent pas un plan d’hébergement plus important. Parfois, l’optimisation est plus judicieuse. Dans d’autres cas, les données révèlent un problème de flux de travail, un processus gourmand en ressources ou un changement d’infrastructure plus important.
Savoir s’il faut optimiser avant de mettre à niveau
L’augmentation de la capacité n’est pas toujours la meilleure solution. Si les analyses révèlent une mauvaise efficacité du cache, des requêtes inhabituellement lourdes, un code inefficace ou des tâches d’arrière-plan gourmandes en ressources, l’équipe peut améliorer les performances avant de changer de plan.
Il peut s’agir d’affiner les règles de mise en cache, de nettoyer les extensions ou le code personnalisé, de revoir les requêtes de base de données ou d’ajuster les processus qui créent une charge évitable. Dans ces cas, l’analyse permet aux équipes d’éviter de payer pour plus de capacité lorsqu’une meilleure efficacité résout le problème.
Savoir quand une mise à niveau est justifiée
À un moment donné, l’optimisation peut ne pas suffire. Si les données révèlent une pression constante sur les ressources, des ralentissements récurrents lors d’une croissance normale, des besoins croissants en bande passante ou des plafonds d’utilisation clairs, l’équipe peut plus facilement justifier une mise à niveau.
Par exemple, le graphique ci-dessous montre que ce site a atteint le nombre maximum de threads PHP alloués, 69, 69 fois en moins de 30 jours.
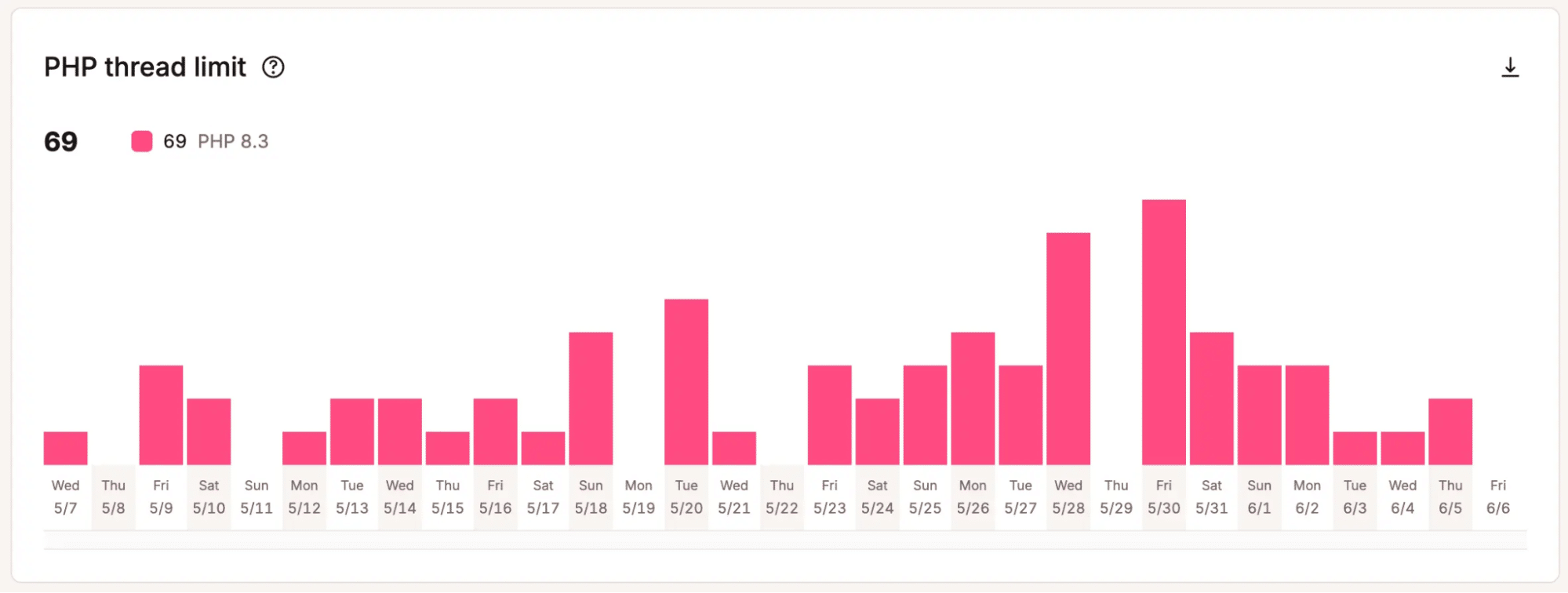
C’est important lorsque les équipes doivent décider si l’augmentation de la capacité vaut le cout. Au lieu de se fier à une intuition, elles peuvent s’appuyer sur des modèles qui montrent que la configuration actuelle atteint ses limites.
Savoir expliquer la décision en interne
Les décisions de mise à l’échelle restent rarement l’apanage de l’équipe technique. La direction, les finances, le marketing et les opérations veulent tous comprendre pourquoi le changement est important et pourquoi maintenant.
L’analyse permet aux équipes d’élaborer un argumentaire clair. Au lieu de s’appuyer sur des opinions, elles peuvent s’appuyer sur des données réelles et relier les dépenses d’infrastructure à la fiabilité des sites, à la préparation des campagnes, à l’expérience des clients et à la protection des revenus. Cela permet de passer d’une préférence technique à un risque mesurable, à un calendrier et à un impact attendu.
Pourquoi l’hébergement réactif rend la mise à l’échelle plus difficile
L’hébergement réactif rend la croissance plus difficile à gérer car les équipes ne voient pas les limites avant d’en ressentir l’impact.
De nombreux environnements d’hébergement ne donnent aux équipes qu’une vision limitée des seuils de capacité réels. Les équipes peuvent connaitre les limites de leur plan, mais elles ne peuvent pas toujours voir à quel point le site est proche de la tension ou quelles parties de la pile créent le plus de pression.
Cela crée un schéma frustrant. Le site ralentit, une campagne n’est pas performante ou des tickets de support commencent à arriver. L’équipe enquête alors, contacte l’hébergeur et envisage une mise à niveau alors que le problème a déjà affecté l’entreprise.
Ce modèle ajoute de l’incertitude. Il rend l’infrastructure plus difficile à prévoir, à justifier et à croire. Pour les équipes en pleine croissance, ce manque de clarté fait de la mise à l’échelle une réaction au lieu d’une partie planifiée de la croissance.
Comment Kinsta aide les équipes à évoluer avec plus de confiance
Kinsta donne aux équipes une vision plus claire de la façon dont leurs sites WordPress fonctionnent sous une demande réelle. Avec les analyses MyKinsta, les équipes peuvent suivre les modèles de trafic, l’utilisation des ressources, les signaux de performance et les points de pression émergents sans traiter l’hébergement comme une boite noire.
Cette visibilité rend la mise à l’échelle moins réactive. Les équipes repèrent les tendances plus tôt, planifient la croissance avec plus de confiance et prennent des décisions d’infrastructure basées sur des données réelles.
Des analyses qui révèlent les contraintes réelles
Kinsta aide les équipes à voir où les limites commencent à émerger. L’analyse MyKinsta montre des signaux tels que les tendances du trafic, l’utilisation de la bande passante, la performance du cache, les codes de réponse et l’activité des ressources, donnant aux équipes une vue plus pratique de la façon dont leur site gère la demande.
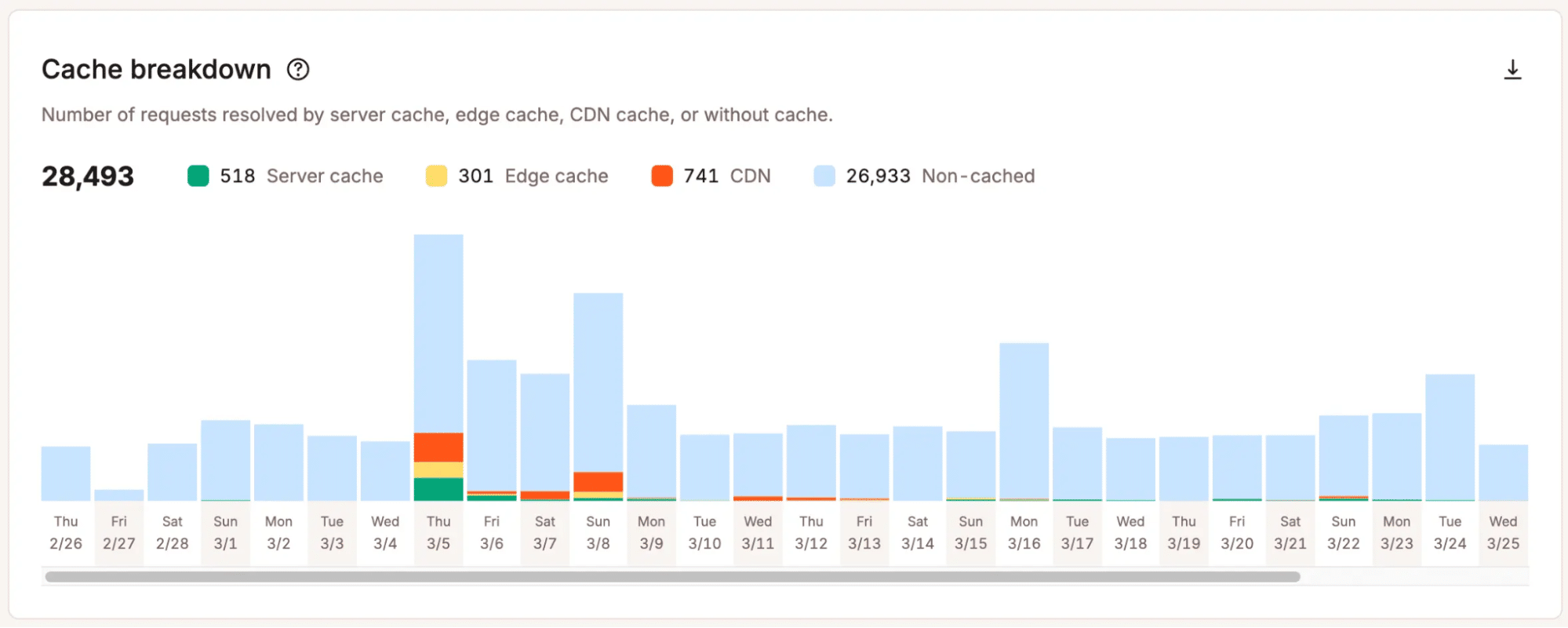
Cette clarté est importante, car les décisions de mise à l’échelle ne doivent pas dépendre d’hypothèses vagues. Lorsque les équipes voient où la pression augmente, elles peuvent décider d’optimiser, d’ajuster leur plan ou de procéder à un examen technique plus approfondi.
Une plateforme conçue pour des décisions éclairées
La croissance s’accompagne souvent de questions budgétaires, de planification de lancement et de pression pour justifier de nouvelles dépenses. Kinsta soutient ces conversations avec des données plus claires sur l’utilisation et la performance du site.
La planification de l’infrastructure est ainsi plus facile à expliquer. Au lieu de demander plus de capacité parce que le site « semble lent », les équipes peuvent relier la décision à des tendances mesurables, à des tensions récurrentes ou à des besoins de croissance spécifiques.
La prévisibilité, un avantage pour la croissance
La montée en charge est moins stressante lorsque les équipes voient ce qui change avant que cela ne devienne urgent. Avec une meilleure visibilité sur les modèles d’utilisation et les signaux de performance, les équipes peuvent se préparer aux campagnes, à la demande saisonnière et à la croissance à long terme avec plus de confiance.
Cette prévisibilité donne aux équipes une plateforme d’hébergement qu’elles peuvent comprendre, planifier et à laquelle elles peuvent faire confiance au fur et à mesure que la croissance se poursuit.
Ne traitez plus l’analyse comme un complément de rapport
L’analyse fonctionne mieux lorsqu’elle façonne la façon dont vous planifiez, et pas seulement la façon dont vous examinez les performances après coup.
Lorsque vous pouvez observer les tendances, les modes d’utilisation et les premiers signes de tension, vous pouvez mieux planifier vos décisions et les justifier plus clairement. Vous n’avez pas à deviner quand agir ou réagir sous la pression. Vous pouvez faire des choix éclairés en vous basant sur ce que fait réellement votre site.
La croissance est ainsi plus prévisible et beaucoup moins stressante.
Explorez MyKinsta pour mieux comprendre vos modèles d’utilisation, vos signaux de performance et vos besoins d’évolution avant qu’ils ne deviennent urgents.

Joel est un développeur d'interfaces publiques qui travaille chez Kinsta en tant que rédacteur technique. Il est un enseignant passionné par l'open source et a écrit plus de 200 articles techniques, principalement autour de JavaScript et de ses frameworks.

