
Au cours des 18 derniers mois, l’attention portée au trafic généré par les robots s’est déplacée de l’exploration et de l’indexation vers son impact sur les performances de base de votre serveur, votre facture d’hébergement et votre capacité à servir vos véritables clients.
Nous le savons car nous avons analysé plus de 10 milliards de requêtes sur l’infrastructure infogérée par Kinsta, et ce que nous avons découvert n’était pas une histoire d’attaque. C’était une histoire de ressources.
« Du point de vue de l’infrastructure, il n’existe pas de simple trafic de robots », explique Daniel Pataki, directeur technique chez Kinsta. « Chaque requête représente un travail réel. À grande échelle, un exploration inefficace cesse d’être un problème de trafic pour devenir un problème de ressources. »
Cet article explique pourquoi ce changement s’est produit, ce qu’il coûte réellement aux propriétaires de sites WordPress et en quoi le discours doit évoluer.
L’ancien modèle ne fonctionne plus
La gestion traditionnelle des robots reposait sur un principe simple : bloquer les mauvais et laisser passer les bons. Pendant des années, cela a suffi. Googlebot explorait vos pages, indexait votre contenu, puis passait à autre chose. Les robots malveillants tentaient de s’introduire sur votre page de connexion. Deux problèmes très différents, deux solutions très différentes.
Ce qu’aucun des deux modèles ne prenait en compte, c’est une troisième catégorie : le trafic automatisé qui n’est ni malveillant ni bloqué, mais qui cause des dommages mesurables aux performances de votre site à grande échelle.
Les robots d’exploration basés sur l’IA, conçus non seulement pour indexer des pages en vue des résultats de recherche, mais aussi pour ingérer du contenu destiné à l’entraînement des modèles, à la génération augmentée par la récupération et aux requêtes des utilisateurs en temps réel, opèrent à une échelle fondamentalement différente de tout ce qui existait auparavant. À lui seul, GPTBot a connu une croissance de 305 % entre mai 2024 et mai 2025. Début 2025, environ une visite web sur 200 était le fait d’un robot IA. À la fin de l’année, ce ratio était passé à une sur 31.
Fin 2025, les robots d’exploration IA représentaient 4,2 % de l’ensemble des requêtes HTML sur le réseau de Cloudflare, un chiffre qui a oscillé entre 2,4 % début avril et 6,4 % fin juin, soit près d’un triplement en l’espace d’un an.
Ces robots d’indexation sont persistants et fréquents, et ils ne se comportent pas comme les robots traditionnels des moteurs de recherche. Beaucoup génèrent d’importants volumes de requêtes vers des points de terminaison dynamiques non mis en cache, ce qui impose à votre serveur un « travail réel ».
Ce que signifie ce « travail réel » pour un site WordPress
C’est là que le problème d’infrastructure apparaît clairement, et c’est un aspect qui passe inaperçu dans la plupart des analyses du trafic des robots.
Lorsqu’un visiteur charge une page mise en cache sur un site WordPress, votre serveur n’a pratiquement rien à faire. Il renvoie un fichier HTML pré-généré, tout comme il le ferait pour une image ou un fichier CSS. Le serveur d’origine ne s’en rend pratiquement pas compte. C’est là tout l’intérêt de la mise en cache.
Mais une part importante des requêtes sur un véritable site WordPress, et en particulier sur les boutiques WooCommerce, ne peut pas être traitée à partir du cache. Ces requêtes comprennent :
- Les points de terminaison du panier et de la commande (
?add-to-cart=,/cart,/checkout) - Les pages de produits filtrées avec des réglages d’URL
- Les requêtes de recherche
- Les interactions basées sur AJAX (ajouts à la liste de souhaits, mises à jour de prix en temps réel, fenêtres contextuelles dynamiques)
- Les pages basées sur une session qui nécessitent que le serveur valide ou crée un contexte utilisateur
Lorsqu’un robot accède à ces points de terminaison, voici ce qui se passe réellement sur votre serveur :
- Un thread PHP est réservé. Chaque requête dynamique sur WordPress occupe un thread PHP pendant toute la durée du traitement, généralement entre 200 et 500 ms, voire plus si la page est complexe. Ce thread n’est pas disponible pour d’autres requêtes tant que la tâche n’est pas terminée. Votre plan d’hébergement dispose d’un nombre fixe de threads.
- Votre base de données exécute une requête. Les pages dynamiques interrogent votre base de données à chaque chargement. Dans le cadre d’un trafic humain normal, cela reste gérable. En cas de charge soutenue de robots accédant à des chemins non mis en cache, la base de données exécute des requêtes en permanence. Si les robots accèdent à des variantes d’URL uniques qui ne donnent lieu à aucun résultat en cache, chacune d’entre elles déclenche sa propre chaîne de requêtes.
- Une surcharge liée aux sessions est générée. Les pages de panier et de commande créent ou valident des sessions, même pour les robots qui ne génèrent jamais de conversion. Cela ajoute une surcharge de traitement à chacune de ces requêtes.
- Épuisement des threads PHP. Lorsque tous les threads PHP disponibles sont occupés, les visiteurs légitimes ne sont pas servis immédiatement ; leurs requêtes sont donc mises en file d’attente. Si la file d’attente se remplit, ils commencent à constater des chargements de pages lents, des processus de commande bloqués et des erreurs 504. Pour un véritable client essayant de finaliser un achat, votre site semble hors service.
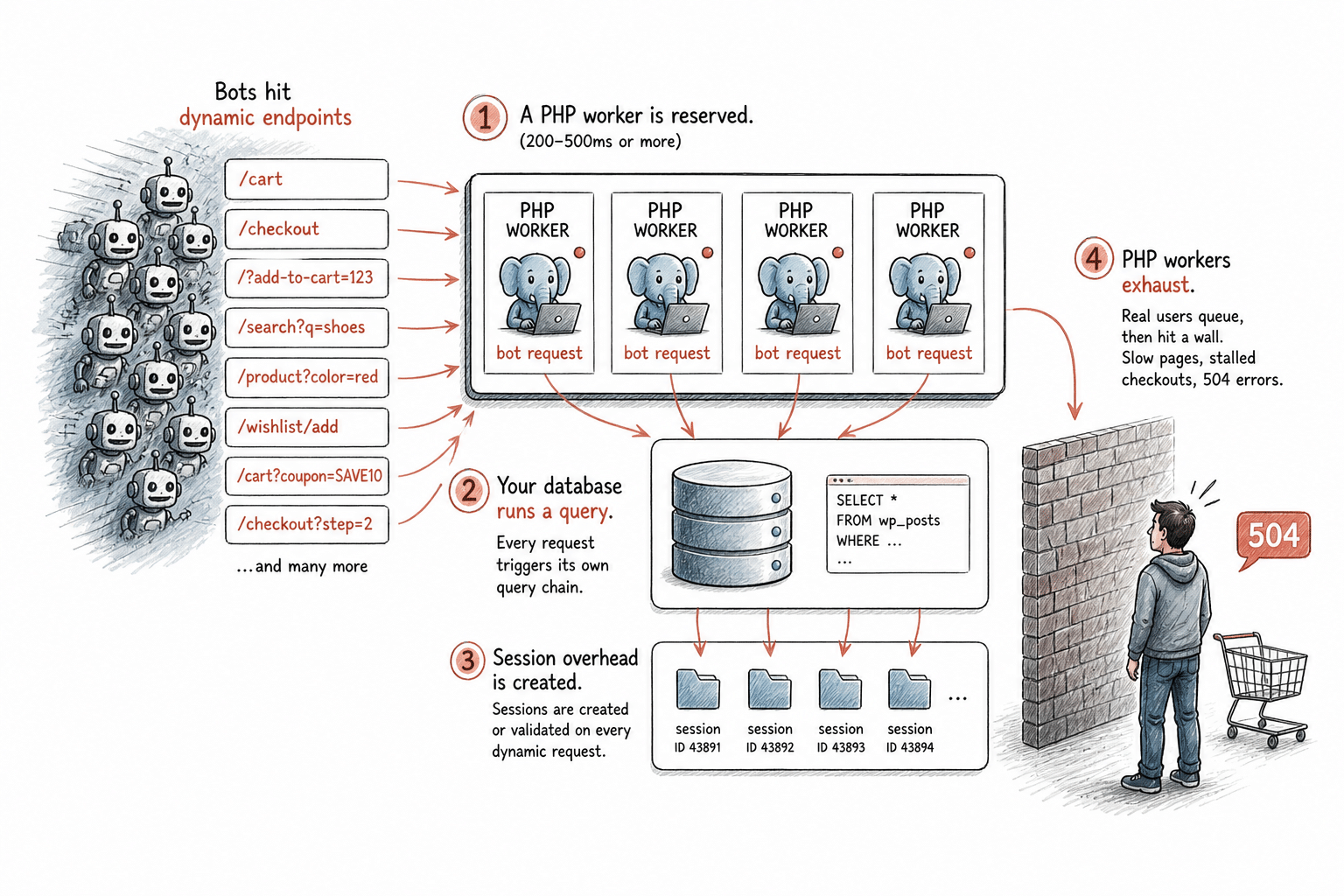
C’est le mécanisme par lequel le trafic généré par les robots devient un problème d’infrastructure. Ce n’est pas une hypothèse théorique. Il s’agit de la chaîne d’événements spécifique qui se produit lorsque des requêtes automatisées inondent les points de terminaison dynamiques d’un site WordPress en ligne.
Ce que révèlent réellement les données d’infrastructure de Kinsta
L’abstrait devient concret lorsque vous examinez les données réelles issues de l’infrastructure que nous gérons à grande échelle.
Une donnée que nous avons trouvée particulièrement frappante est qu’un seul robot (ClaudeBot) a généré 3,75 millions de requêtes « Ajouter au panier » en l’espace de 24 heures. Cela représente environ une requête toutes les 23 millisecondes (jour et nuit), chacune étant traitée par le serveur comme une nouvelle requête, car les points de terminaison du panier sont intrinsèquement dynamiques.
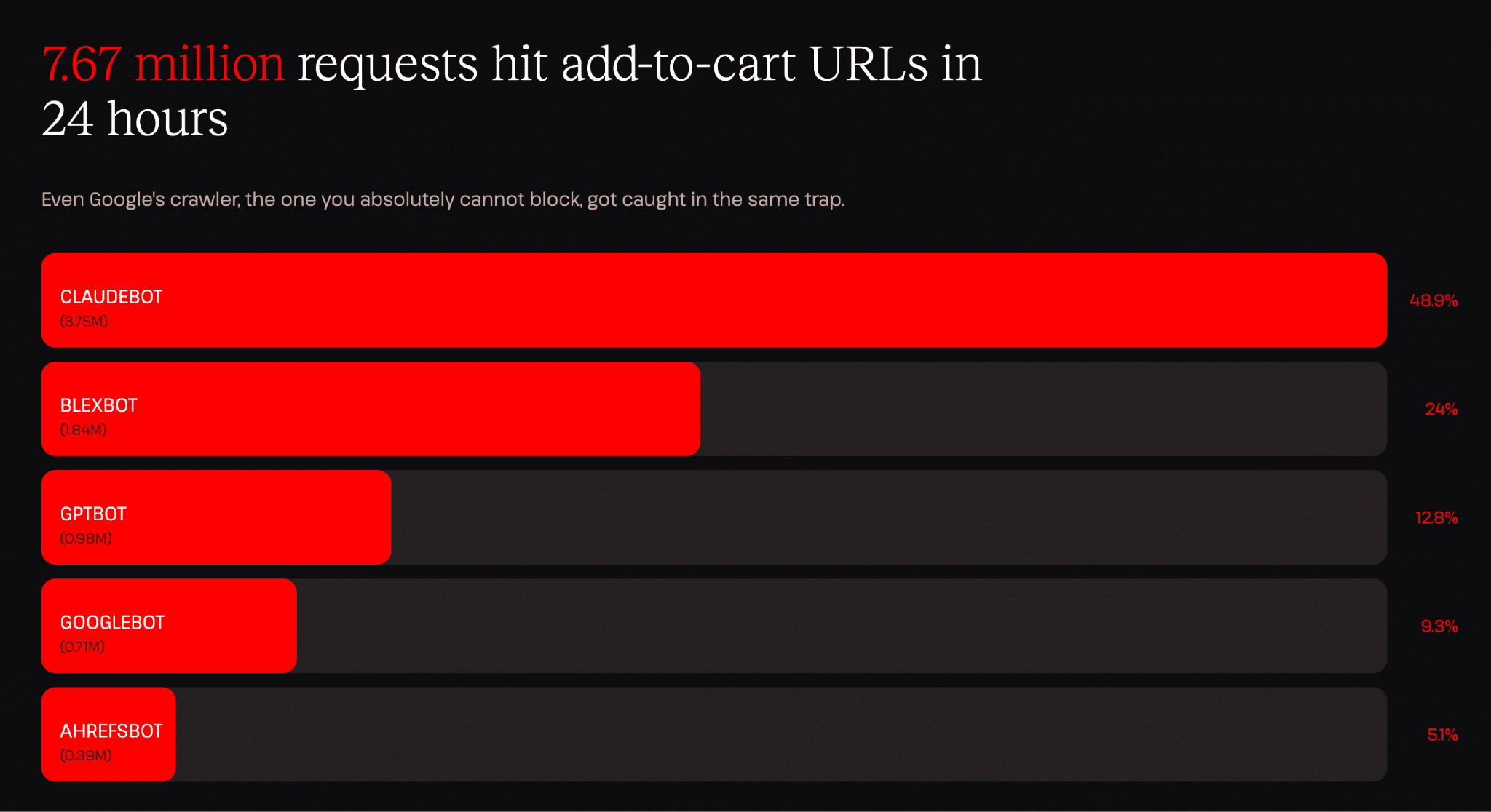
Pour replacer cela dans son contexte : les requêtes « Ajouter au panier » comptent parmi les points de terminaison les plus coûteux d’une boutique WooCommerce. Elles créent des sessions, exécutent des requêtes et mettent à jour l’état du panier. Chacune d’entre elles représente un véritable travail. Les 3,75 millions de requêtes que nous avons observées provenant d’une seule source en une journée constituent le type de trafic susceptible de mettre un site hors ligne.
Une deuxième donnée souligne à quel point ces schémas peuvent être persistants : une boucle défectueuse a généré 550 millions de requêtes en 30 jours, soit un trafic suffisant pour justifier la mise en place d’une règle de mitigation dédiée au sein de notre infrastructure. Il ne s’agit ni d’une attaque DDoS ni d’une campagne de logiciels malveillants, mais d’un robot bloqué dans une boucle d’exploration, qui interroge sans cesse des URL qu’il a déjà consultées.
Ce ne sont pas des cas isolés. Ce sont des schémas que nous observons sur l’ensemble de notre plateforme.
Le problème des boucles : les robots n’attaquent pas, ils sont bloqués
L’un des aspects les plus sous-estimés du problème actuel lié au trafic des robots est que la plupart des causes de dommages à l’infrastructure ne sont absolument pas malveillantes. Il s’agit d’une automatisation inefficace à grande échelle.
Les sites web modernes, en particulier les boutiques en ligne, génèrent des URL légèrement différentes pour une page qui est, en substance, la même :
- Un produit avec un filtre de couleur ajouté
- Une page de panier avec un jeton de session
- Une vue de catégorie avec un réglage de tri
Pour un humain, il s’agit dans tous les cas de « la même page ». Pour un robot qui suit les URL, chacune d’entre elles apparaît comme une toute nouvelle page à explorer.
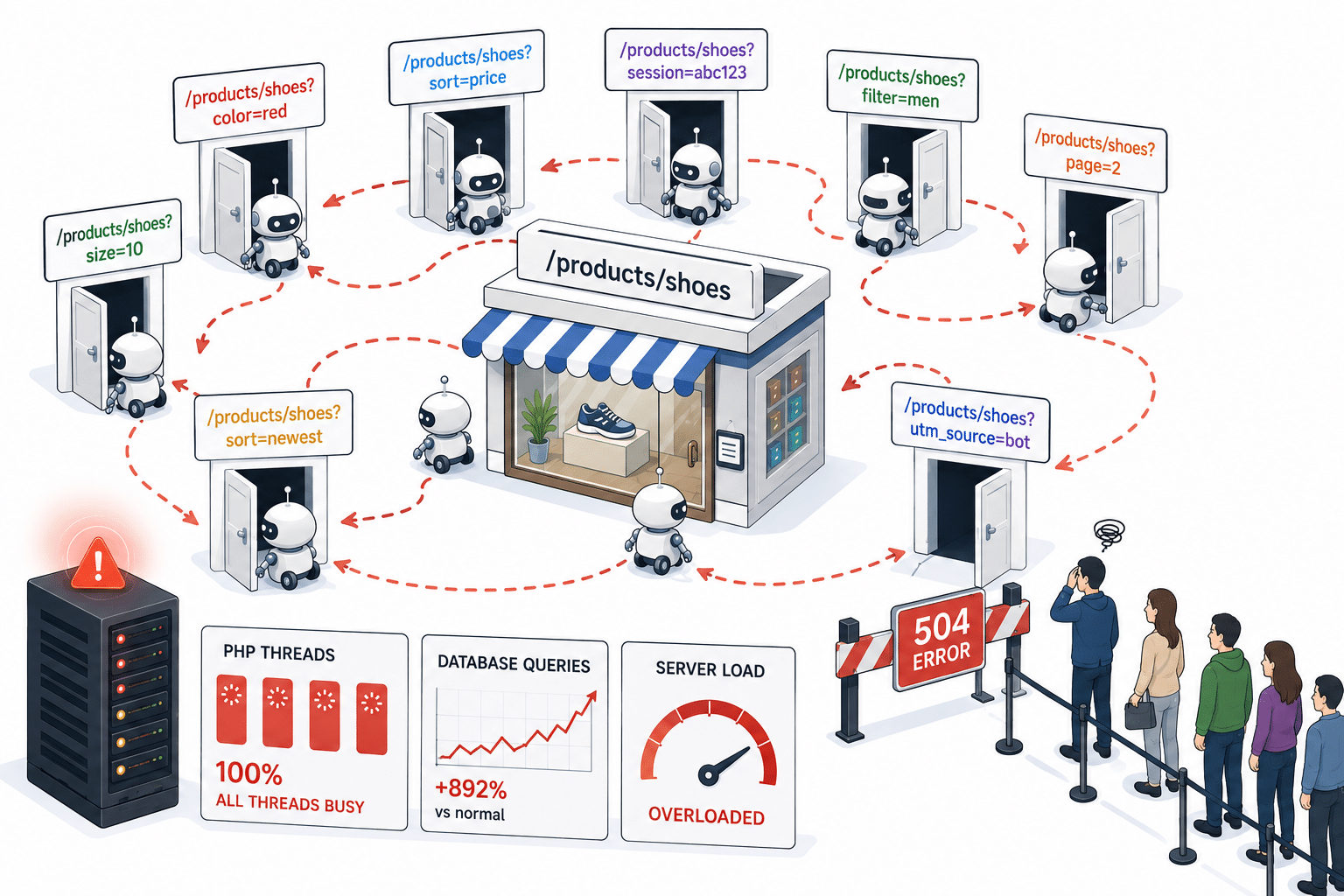
Le robot suit donc le premier lien. Cette page génère une autre variante d’URL, que le robot suit à son tour. Puis une autre. Et encore une autre. Il ne dispose d’aucun mécanisme lui permettant de reconnaître qu’il tourne en rond, et certaines de ces boucles ont pu se poursuivre sans être détectées sur l’infrastructure surveillée pendant plusieurs jours avant que les règles de mitigation ne les interceptent.
Dans le rapport sur le trafic lié à l’IA et aux robots que nous avons récemment publié, David Belson, ancien responsable de l’analyse des données chez Cloudflare, a déclaré : « Il y a cette personne qui ne savait absolument pas ce qu’elle faisait hier, mais qui a codé un robot à la va-vite aujourd’hui et l’a lâché dans la nature. Elle ne prend même pas la peine de vérifier robots.txt. »
Ce comportement ne provient pas toujours d’acteurs malveillants. Il provient de systèmes de robots d’exploration basés sur l’IA qui n’ont pas été conçus en tenant compte de la navigation à facettes, de la prolifération des réglages d’URL ou des URL générées par les sessions, qui sont des fonctionnalités standard des sites WordPress modernes.
Google lui-même identifie explicitement la navigation à facettes et les URL basées sur des réglages comme une source d’inefficacité d’exploration, soulignant que les robots peuvent explorer des variations quasi infinies d’une même page.
Votre facture de serveur est désormais un problème de gestion des robots
Jusqu’à récemment, de nombreuses formules d’hébergement étaient dimensionnées en fonction du nombre de visites, ce qui fonctionnait raisonnablement bien comme indicateur de l’utilisation réelle par des humains. On partait du principe que les visites correspondaient globalement au nombre de personnes interagissant avec votre site.
Cette hypothèse ne tient plus.
Le trafic automatisé a gonflé les chiffres de fréquentation d’une manière qui n’a pratiquement rien à voir avec l’activité commerciale réelle. Les requêtes des robots peuvent générer des chiffres de fréquentation sans entraîner d’engagement, de conversions ou de revenus correspondants. Les propriétaires de sites recevaient des avis de dépassement sur des formules basées sur la fréquentation, en raison d’une activité de robots qu’ils ne pouvaient pas contrôler et qu’ils n’avaient pas sollicitée.
Ce phénomène s’est révélé suffisamment évident en tant que tendance systémique pour que Kinsta lance des plans d’hébergement basées sur la bande passante, en réponse directe à une catégorie de sites dont les indicateurs de visites avaient commencé à s’écarter considérablement de leur consommation réelle de ressources. Si le nombre de visites d’un site augmentait mais que la bande passante ne suivait pas le rythme, cela indiquait presque toujours la présence de robots. Le passage à un modèle basé sur la bande passante a permis de dissocier efficacement la facturation d’un indicateur que lesro bots avaient appris à gonfler.
Le problème de facturation est mesurable et peut être résolu. Le problème le plus épineux est que la plupart des propriétaires de sites ne se rendent pas compte de ce qui se passe, car leurs tableaux de bord ne reflètent pas la situation dans son ensemble.
Ce que vos outils d’analyse vous révèlent (et ne vous révèlent pas)
L’une des conséquences d’un trafic de robots à cette échelle est que les outils d’analyse standard ne reflètent plus fidèlement les performances réelles de votre site.
Si le nombre de visites augmente mais que le chiffre d’affaires, le temps passé sur la page et le taux de rebond n’évoluent pas proportionnellement, les robots sont probablement en cause. Si votre serveur présente une dégradation des performances qui ne correspond pas aux pics de trafic que vous attendriez suite à une activité de contenu ou de marketing, il convient d’examiner de plus près le trafic de robots vers des points de terminaison non mis en cache.
Kinsta filtre automatiquement les agents utilisateurs de robots connus des analyses et des calculs d’utilisation des plans. Cependant, un trafic automatisé ressemblant fortement au comportement humain peut tout de même apparaître dans vos indicateurs.
Les schémas à surveiller :
- Des requêtes répétées vers les mêmes types d’URL, en particulier les chemins comportant de nombreux réglages ou basés sur des sessions
- Des pics de trafic à des moments qui ne correspondent à aucune activité de publication, promotionnelle ou saisonnière
- Une dégradation des performances du serveur (TTFB plus élevé, erreurs d’épuisement des threads PHP) pendant les périodes de trafic élevé qui ne correspondent pas à des événements réels
- Une croissance du nombre de visites plus rapide que celle de la bande passante, des conversions ou des indicateurs d’engagement
Aucun de ces éléments n’est déterminant en soi, mais toute combinaison de ceux-ci justifie une enquête avant d’attribuer ces chiffres à la croissance de l’activité.
Pourquoi ce problème est-il plus complexe qu’il n’y paraît ?
La réaction instinctive la plus courante face aux données de trafic générées par des robots est de tout bloquer. D’autres pourraient tout autoriser, car « l’IA est l’avenir ».
Aucune de ces deux approches ne fonctionne !
Bloquer sans discernement revient à bloquer des robots d’indexation vérifiés, notamment Googlebot, dont la couverture d’indexation détermine si votre contenu apparaît ou non dans les résultats de recherche. Cela revient à bloquer les robots de découverte basés sur l’IA qui pourraient mettre en avant votre contenu dans les résultats de recherche conversationnelle, les recommandations alimentées par l’IA ou les moteurs de réponses. Pour une boutique WooCommerce ou un éditeur de contenu, cela représente un coût de distribution non négligeable.
Tout laisser passer revient à accepter des coûts d’infrastructure qui ne génèrent aucun retour sur investissement. Et pour les points de terminaison dynamiques que les robots ont tendance à solliciter le plus, ces coûts ne sont pas négligeables. Ils s’accumulent et s’aggravent, en particulier en cas de charge automatisée soutenue.
La véritable réponse se situe quelque part entre ces deux extrêmes, et elle nécessite de comprendre les différences entre les catégories de trafic plutôt que de traiter tous les robots comme une seule et même catégorie.
Comme l’a expliqué Cristian Lopez, rédacteur en chef chez HostingAdvice, dans ce rapport : « L’idée fausse consiste à penser que le trafic des robots est un simple problème de bloquer ou autoriser. En réalité, il s’agit de politique, de visibilité et de contrôle économique. »
Les robots vérifiés, notamment Googlebot, Bing et les outils de surveillance légitimes, doivent généralement être autorisés, avec d’éventuelles restrictions d’accès aux points de terminaison qui ne présentent aucun intérêt pour l’exploration (votre page de commande ne contribue en rien à votre référencement). Les robots non vérifiés, dépourvus d’informations d’identification ou d’objectif précis, justifient une surveillance plus étroite. Les robots d’entraînement à l’IA qui génèrent des volumes élevés de requêtes vers des points de terminaison dynamiques constituent une catégorie spécifique pouvant justifier un blocage ou une limitation de débit, en fonction du type de votre site et de vos priorités.
Dans notre rapport sur l’IA et le trafic des robots, nous avons élaboré un cadre décisionnel interactif qui présente l’approche adaptée à différents types de sites. L’exemple ci-dessous présente la configuration recommandée pour une boutique WooCommerce axée sur les performances et la stabilité du site :
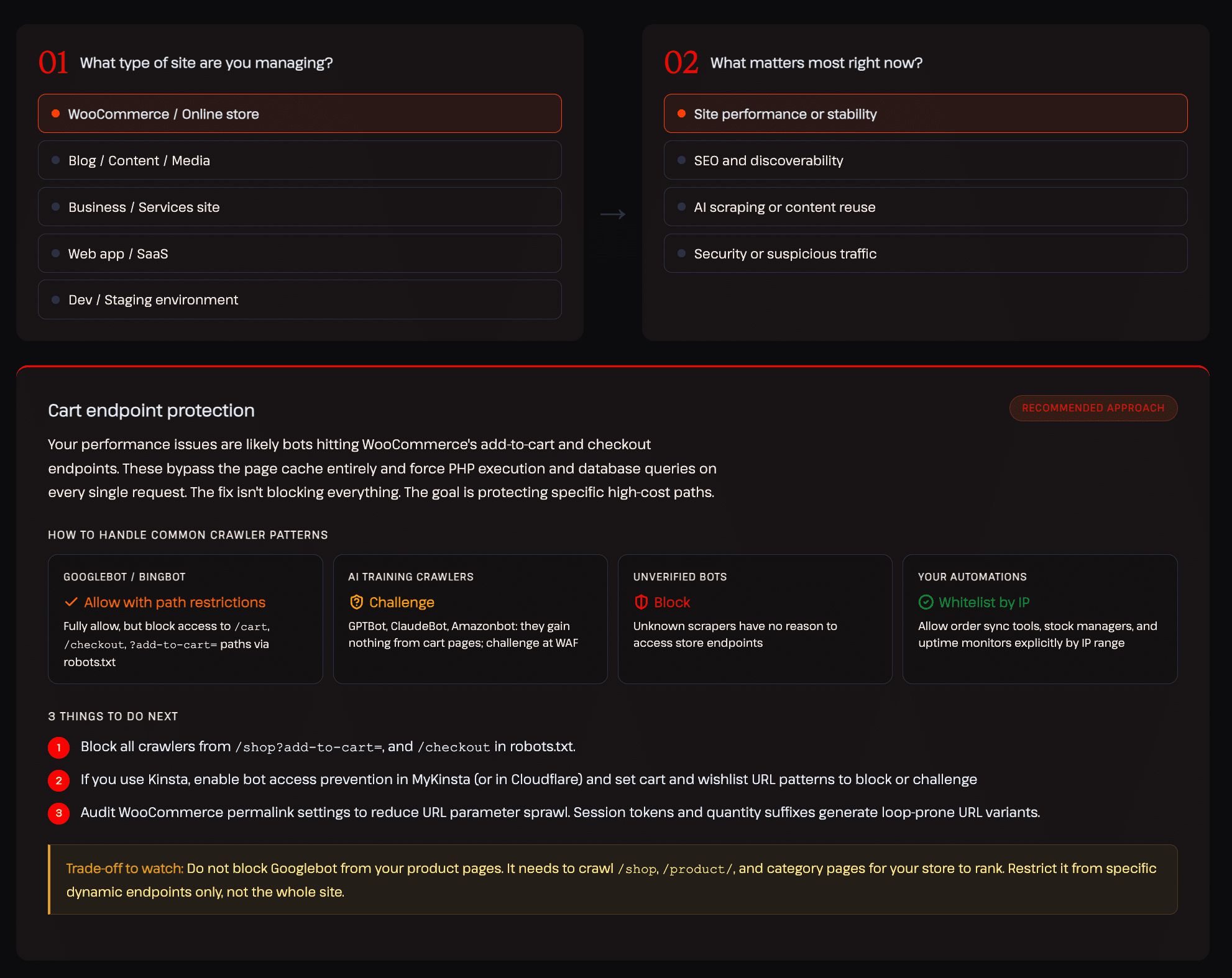
Ce type de contrôle nuancé et tenant compte des différentes catégories est précisément ce que la plupart des outils existants ne vous offrent pas.
L’approche de Kinsta en matière de protection contre les robots
Ce que nous avons mis au point avec la protection anti-robots de Kinsta a été spécialement conçu pour répondre aux défis d’infrastructure décrits ci-dessus.
Le système classe le trafic en catégories telles que les robots vérifiés, les visiteurs probablement humains, les visiteurs probablement des robots, le trafic automatisé et le trafic malveillant, et vous permet de définir des niveaux de protection adaptés aux besoins réels de votre site.

Ces niveaux ne sont pas binaires. L’option « Bloquer les automatisations » cible le trafic automatisé confirmé tout en laissant les robots vérifiés intacts. L’option « Défier les robots » ajoute une étape de vérification pour les automatisations non vérifiées sans perturber les visiteurs légitimes. L’option « Défier tout le monde est disponible en cas de pics de trafic importants, mais comporte les inconvénients auxquels vous pouvez vous attendre.
Il est essentiel de noter que cet outil s’appuie sur le système de notation des robots de niveau entreprise de Cloudflare, un système de classification en temps réel basé sur l’apprentissage automatique qui attribue à chaque visiteur un score compris entre 1 et 99 en fonction de signaux comportementaux, et non pas uniquement des chaînes d’agent utilisateur. Cela est important car la correspondance des user-agents seule s’avère de plus en plus inefficace, puisque 12,9 % des robots IA ignorent désormais les directives « robots.txt », contre 3,3 % il y a seulement un trimestre. La classification comportementale détecte ce que les règles basées sur les user-agents ne parviennent pas à repérer.
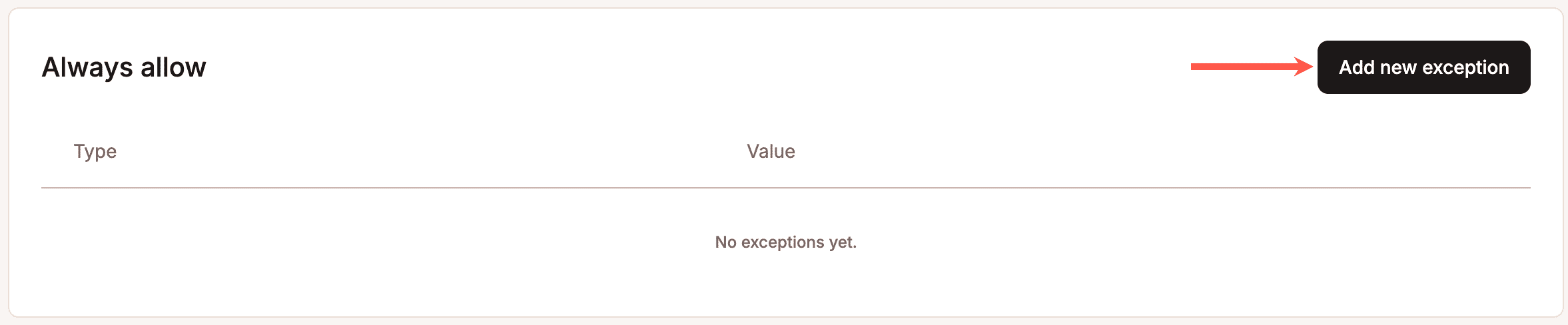
Il existe également un système d’exceptions « Toujours autoriser » destiné aux intégrations de confiance, aux services de surveillance et aux automatisations critiques pour l’activité qui ne doivent pas être bloquées par les règles de protection, car le blocage excessif représente lui aussi un coût réel, en particulier pour les boutiques WooCommerce qui dépendent de la synchronisation automatisée des commandes, des intégrations de passerelles de paiement ou des outils de surveillance de la disponibilité.
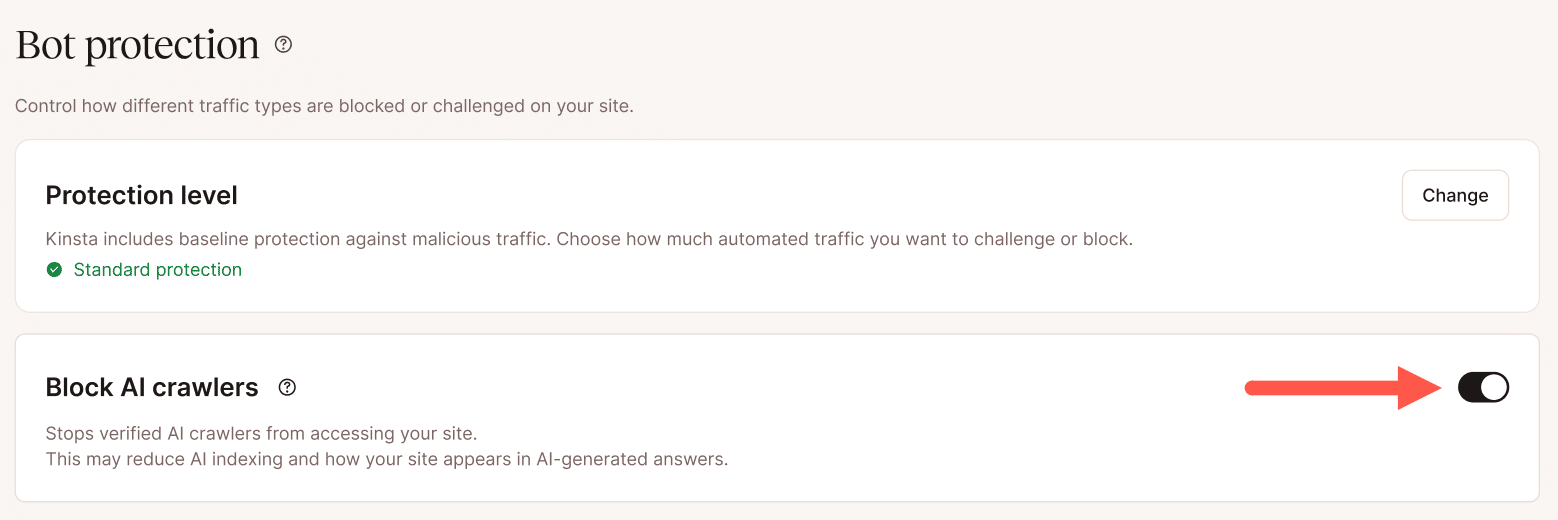
Le bouton de blocage des robots d’IA cible spécifiquement les robots d’entraînement de l’IA sans affecter les robots des moteurs de recherche tels que Googlebot ou Bingbot. Pour les sites ayant identifié l’activité des robots d’IA comme un facteur de performance, il s’agit d’une mesure d’atténuation en une seule étape qui ne nécessite pas la configuration de règles individuelles.
Savoir que cet outil existe est une chose. Savoir quand et comment l’utiliser en est une autre.
Que faire si le trafic de robots est votre problème
Si vous constatez les schémas décrits ci-dessus, voici un point de départ pratique, classé par ordre d’impact :
Tout d’abord : vérifiez la source. Utilisez le graphique de répartition des requêtes dans la vue « Protection contre les robots » de MyKinsta pour comprendre comment le trafic vers votre site est classé.
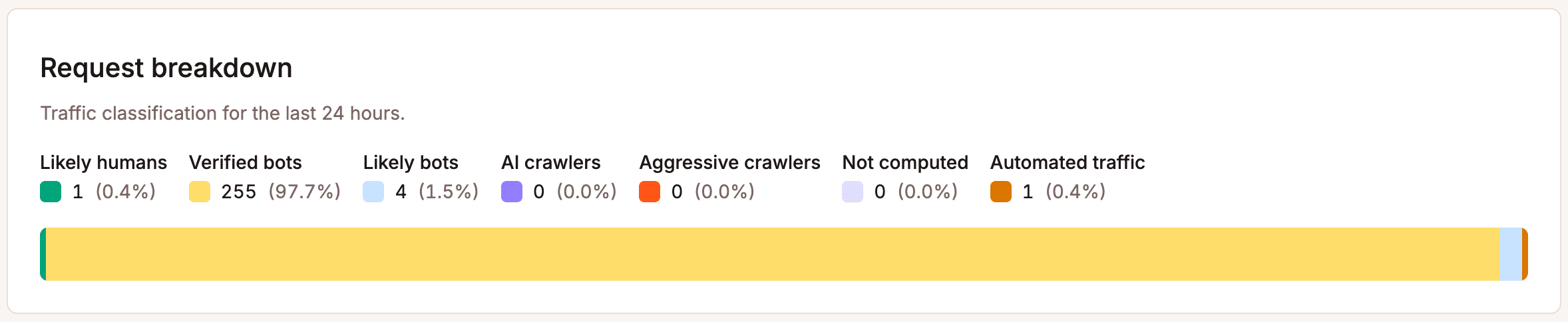
Si une part importante du trafic est automatisée ou non vérifiée, c’est le signe qu’il faut agir. Ne négligez pas cette étape, car apporter des modifications à la protection sans savoir contre quoi vous vous protégez conduit à des erreurs de configuration.
Deuxièmement : adaptez le niveau de protection au type de site. Une boutique WooCommerce n’a pas les mêmes priorités qu’un site de publication de contenu, qui a lui-même des priorités différentes de celles d’un environnement de préproduction. Bloquer le trafic automatisé et mettre à l’épreuve les robots potentiels est judicieux pour une boutique dotée de points de terminaison dynamiques. Un site de contenu pourrait privilégier l’autorisation des robots de découverte IA tout en bloquant les robots d’indexation destinés à l’entraînement de l’IA. Un environnement de préproduction doit quant à lui être entièrement verrouillé, quoi qu’il arrive.
Troisièmement : protégez en priorité les chemins d’accès les plus coûteux. Avant d’appliquer des règles de protection générales, vérifiez si vos points de terminaison les plus coûteux, tels que le panier, la page de commande et les gestionnaires AJAX, sont accessibles à des robots d’indexation qui n’ont aucune raison de s’y trouver. Bloquer les agents utilisateurs de robots connus provenant de /cart et ?add-to-cart= via robots.txt constitue un point de départ ; c’est l’application de cette mesure au niveau du WAF (et non pas seulement sa signalisation) qui permet réellement d’empêcher la charge.
Quatrièmement : surveillez, puis ajustez. Les schémas de trafic des robots évoluent plus rapidement que ne le pensent la plupart des propriétaires de sites. La part de trafic de GPTBot a triplé en l’espace d’une seule année. Définir des règles de protection une seule fois puis les ignorer ne constitue pas une stratégie. Le graphique des résultats de la protection contre les robots dans MyKinsta suit ce qui est bloqué, contesté et autorisé au fil du temps.
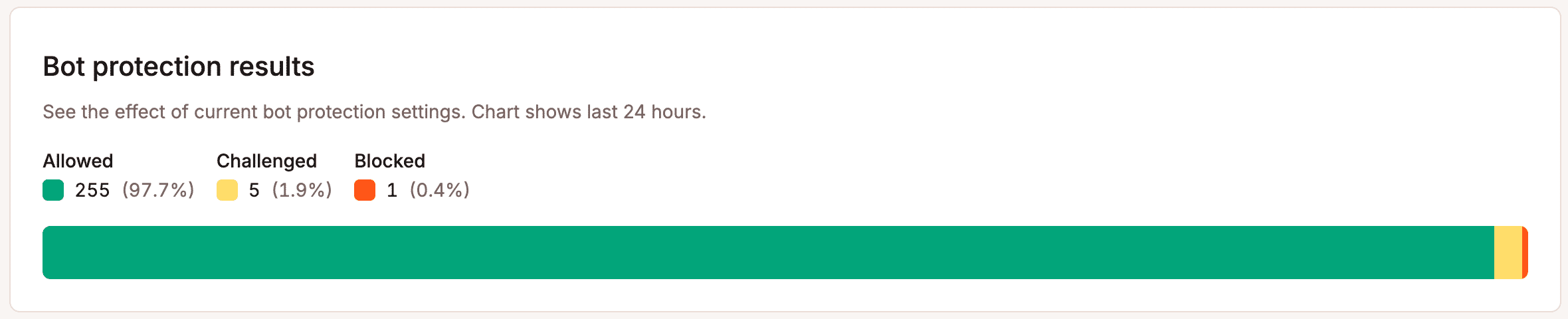
Ces données doivent vous aider à ajuster vos réglages.
Si les robots génèrent des dépassements du nombre de visites dans le cadre d’un plan basé sur le nombre de visites, il peut également être utile d’examiner en parallèle les plans d’hébergement Kinsta basés sur la bande passante. Passer à un plan basé sur la bande passante ne résout pas le problème sous-jacent lié aux robots, mais cela permet de mieux refléter le coût réel de l’infrastructure lié à la composition de votre trafic, qui est souvent nettement inférieur à ce que suggère le nombre de visites.
Vue d’ensemble : ce problème va s’aggraver
Le trafic provenant d’agents automatisés apparaît déjà dans les journaux d’infrastructure. Google a annoncé la mise en place d’un agent utilisateur dédié pour les interactions de ses agents IA avec les sites. Il s’agit de systèmes automatisés qui cliquent sur des liens, remplissent des formulaires et effectuent des requêtes qui ressemblent de plus en plus au comportement d’une session humaine.
Les indicateurs qui permettent actuellement de classer les robots, tels que les chaînes d’agent utilisateur, la fréquence des requêtes et l’évaluation comportementale, deviennent plus difficiles à appliquer avec précision à mesure que la frontière entre interaction automatisée et interaction humaine continue de s’estomper.
La plupart des propriétaires de sites ne peuvent pas suivre cette évolution par eux-mêmes. Le comportement des robots évolue plus rapidement que ne peuvent s’adapter les règles définies manuellement. Ce qui fonctionnait il y a trois mois peut déjà s’avérer insuffisant. Et le coût d’une erreur – en termes de ressources serveur, de dépassements de facturation ou de clients réels confrontés à des erreurs 504 lors de la commande – est bien réel et immédiat.
C’est là qu’intervient une infrastructure qui gère cela à votre place. La plateforme de Kinsta bloque 15 à 20 % du trafic malveillant avant même qu’il n’atteigne votre site, repose sur le réseau d’entreprise de Cloudflare et vous offre des contrôles de protection contre les robots qui s’adaptent au comportement réel de votre site. À mesure que le trafic de robots continue d’évoluer, la différence entre une plateforme d’hébergement qui traite ce problème comme un enjeu d’infrastructure et une autre qui le considère comme un détail deviendra de plus en plus difficile à ignorer.
Les sites qui gèrent le mieux cette situation ne seront pas ceux qui bloquent le plus de trafic. Ce seront ceux qui s’appuient sur une infrastructure conçue pour gérer au mieux les robots.

Joel est un développeur d'interfaces publiques qui travaille chez Kinsta en tant que rédacteur technique. Il est un enseignant passionné par l'open source et a écrit plus de 200 articles techniques, principalement autour de JavaScript et de ses frameworks.

