
Il peut être décourageant de constater que votre site web décline dans les classements de recherche. Lorsque vos pages ne sont plus explorées par Google, ces classements inférieurs peuvent contribuer à une diminution du nombre de visiteurs et de conversions.
L’erreur « Indexé, bien que bloqué par robots.txt » peut signifier un problème d’exploration de votre site par les moteurs de recherche. Lorsque cela se produit, Google a indexé une page qu’il ne peut pas explorer. Heureusement, vous pouvez modifier votre fichier robots.txt pour spécifier les pages qui doivent ou ne doivent pas être indexées.
Dans cet article, nous expliquerons l’erreur « Indexé, bien que bloqué par robots.txt » et comment tester votre site web pour ce problème. Ensuite, nous vous montrerons deux méthodes différentes pour la corriger. C’est parti !
Qu’est-ce que l’erreur « Indexé, bien que bloqué par robots.txt » ?
En tant que propriétaire de site web, la Google Search Console peut vous aider à analyser les performances de votre site dans de nombreux domaines essentiels. Cet outil peut surveiller la vitesse des pages, la sécurité et la « crawlabilité » ou l’exploraibilité afin que vous puissiez optimiser votre présence en ligne :
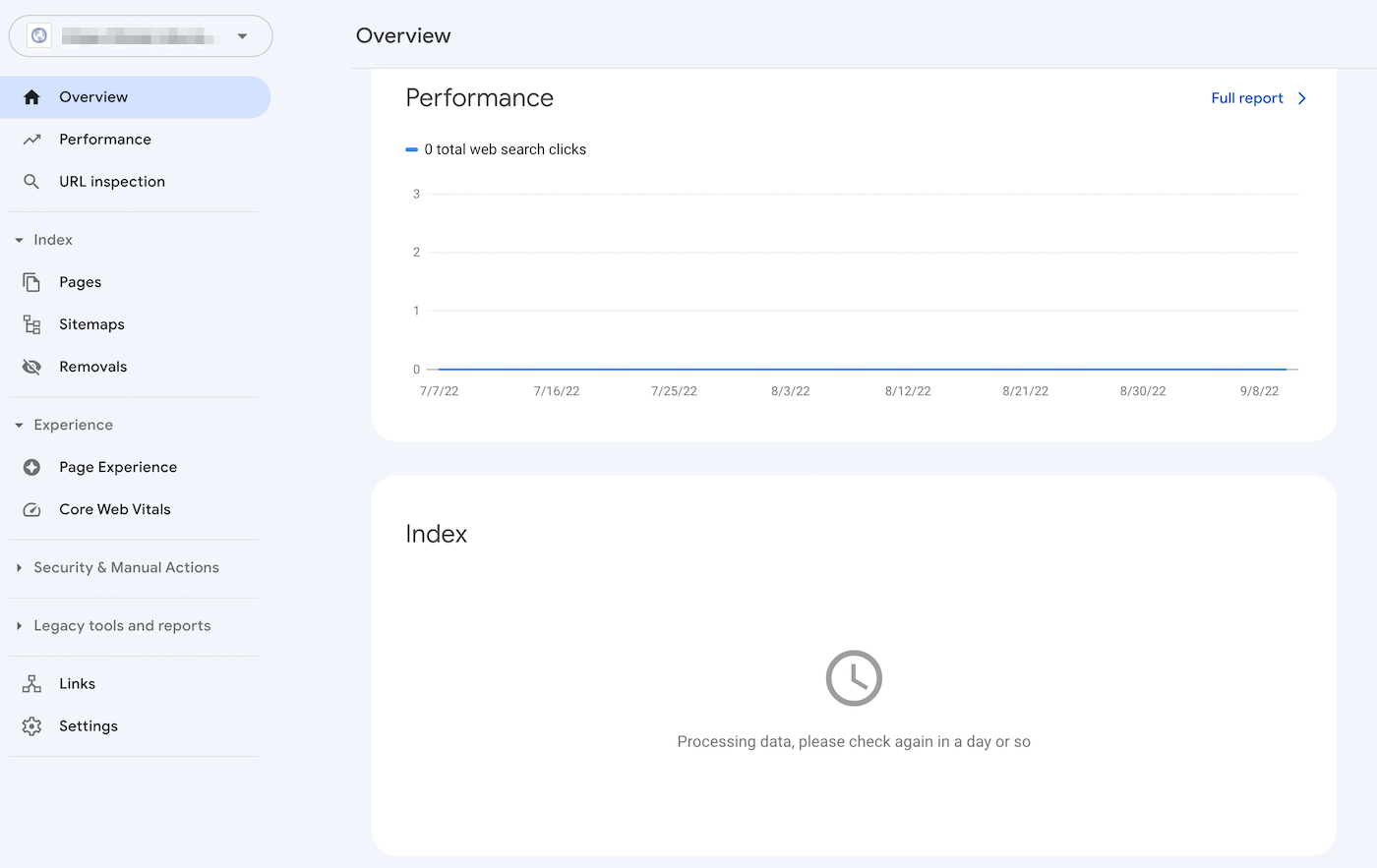
Par exemple, le rapport sur la couverture de l’index de Search Console peut vous aider à améliorer l’optimisation des moteurs de recherche (SEO) de votre site. Il analysera la manière dont Google indexe votre contenu en ligne, en renvoyant des informations sur les erreurs courantes, telles que l’avertissement « Indexé, bien que bloqué par robots.txt » :
Pour comprendre cette erreur, parlons d’abord du fichier robots.txt. Essentiellement, il informe les robots des moteurs de recherche des fichiers de votre site web qui doivent ou ne doivent pas être indexés. Avec un fichier robots.txt bien structuré, vous pouvez vous assurer que seules les pages web importantes sont explorées.
Si vous avez reçu un avertissement « Indexé, bien que bloqué par robots.txt », cela signifie que les robots de Google ont trouvé la page mais ont remarqué qu’elle était bloquée dans votre fichier robots.txt. Lorsque cela se produit, Google n’est pas sûr que vous souhaitiez que cette page soit indexée.
Par conséquent, cette page peut apparaître dans les résultats de recherche, mais elle n’affichera pas de description. Il exclura également les images, les vidéos, les PDF et les fichiers non-HTML. Par conséquent, vous devrez mettre à jour votre fichier robots.txt si vous souhaitez afficher ces informations.
Problèmes potentiels d’indexation des pages
Vous pouvez ajouter intentionnellement des directives à votre fichier robots.txt qui bloquent les pages aux robots d’exploration. Cependant, ces directives peuvent ne pas supprimer complètement les pages de Google. Si un site web externe établit un lien vers la page, cela peut provoquer une erreur « Indexé, bien que bloqué par robots.txt ».
Google (et les autres moteurs de recherche) doivent indexer vos pages avant de pouvoir les classer correctement. Pour garantir que seul le contenu pertinent apparaît dans les résultats de recherche, il est crucial de comprendre le fonctionnement de ce processus.
Bien que certaines pages devraient être indexées, elles peuvent ne pas l’être. Cela peut être dû à plusieurs raisons différentes :
- Une directive dans le fichier robots.txt qui empêche l’indexation
- Des liens brisés ou des chaînes de redirection
- Des balises canoniques dans l’en-tête HTML
D’autre part, certaines pages web ne devraient pas être indexées. Elles peuvent finir par être indexées accidentellement en raison de ces facteurs :
- Directives noindex incorrectes
- Liens externes provenant d’autres sites
- Anciennes URL dans l’index Google
- Pas de fichier robots.txt
Si un trop grand nombre de vos pages sont indexées, votre serveur peut être submergé par le robot d’exploration de Google. De plus, Google pourrait perdre du temps à indexer des pages non pertinentes de votre site web. Par conséquent, vous devrez créer et modifier correctement votre fichier robots.txt.
Trouver la source de l’erreur « Indexé, bien que bloqué par robots.txt »
Un moyen efficace d’identifier les problèmes d’indexation des pages est de se connecter à Google Search Console. Après avoir vérifié la propriété du site, vous pourrez accéder à des rapports sur les performances de votre site web.
Dans la section Index, cliquez sur l’onglet Valide avec avertissements. Vous obtiendrez une liste de vos erreurs d’indexation, y compris les avertissements « Indexé, bien que bloqué par robots.txt ». Si vous n’en voyez pas, votre site web n’est probablement pas concerné par ce problème.
Vous pouvez également utiliser le testeur robots.txt de Google. Avec cet outil, vous pouvez analyser votre fichier robots.txt pour rechercher les avertissements de syntaxe et autres erreurs :
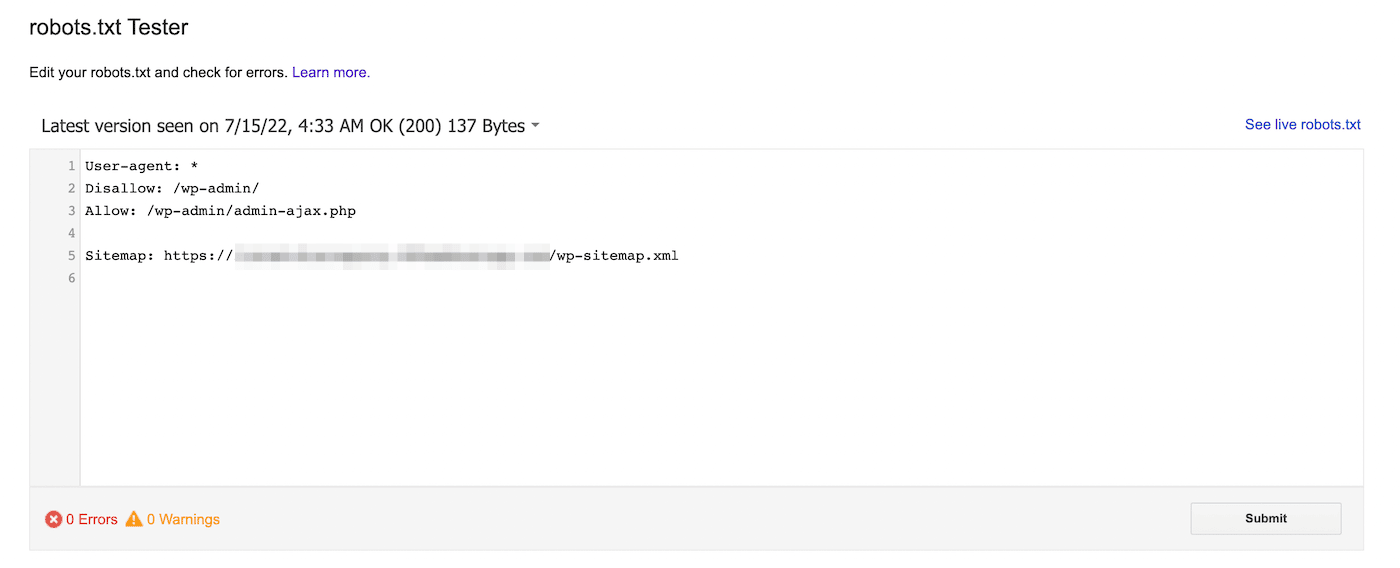
Au bas de la page, saisissez une URL spécifique pour voir si elle est bloquée. Vous devrez choisir un agent utilisateur dans le menu déroulant et sélectionner Test :

Vous pouvez également naviguer vers domain.com/robots.txt. Si vous avez déjà un fichier robots.txt, cela vous permettra de le visualiser :
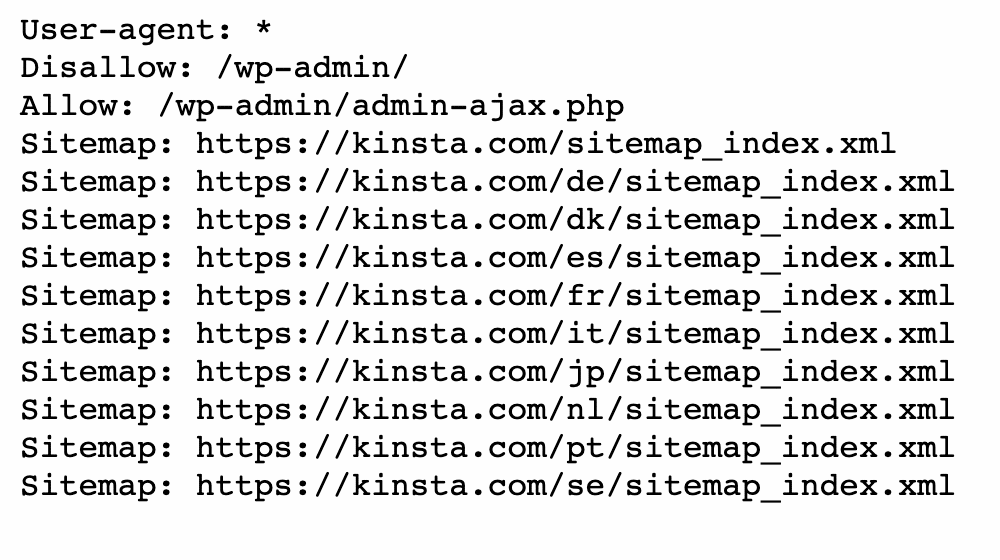
Ensuite, recherchez les déclarations disallow. Les administrateurs du site peuvent ajouter ces déclarations pour indiquer aux robots de recherche comment accéder à des fichiers ou des pages spécifiques.
Si la déclaration disallow bloque tous les moteurs de recherche, elle pourrait ressembler à ceci :
Disallow: /Elle peut également bloquer un agent utilisateur spécifique :
User-agent: *
Disallow: /Avec l’un de ces outils, vous serez en mesure d’identifier les problèmes d’indexation de votre page. Ensuite, vous devrez prendre des mesures pour mettre à jour votre fichier robots.txt.
Comment corriger l’erreur « Indexé, bien que bloqué par robots.txt » ?
Maintenant que vous en savez plus sur le fichier robots.txt et sur la manière dont il peut empêcher l’indexation des pages, il est temps de corriger l’erreur « Indexé, bien que bloqué par robots.txt ». Toutefois, veillez à évaluer d’abord si la page bloquée doit être indexée avant d’utiliser ces solutions.
Méthode 1 : Modifier directement le fichier robots.txt
Si vous avez un site web WordPress, vous aurez probablement un fichier robots.txt virtuel. Vous pouvez le consulter en recherchant domain.com/robots.txt dans un navigateur web (en remplaçant domain.com par votre nom de domaine). Toutefois, ce fichier virtuel ne vous permettra pas d’effectuer des modifications.
Pour commencer à modifier le fichier robots.txt, vous devez créer un fichier sur votre serveur. Tout d’abord, choisissez un éditeur de texte et créez un nouveau fichier. Veillez à le nommer « robots.txt » :
Ensuite, vous devrez vous connecter à un client SFTP. Si vous utilisez un compte d’hébergement Kinsta, connectez-vous à MyKinsta et allez dans Sites > Info:

Vous trouverez ici votre nom d’utilisateur, votre mot de passe, votre hôte et votre numéro de port. Vous pouvez ensuite télécharger un client SFTP tel que FileZilla. Saisissez vos identifiants de connexion SFTP et cliquez sur Connexion rapide :

Enfin, téléversez le fichier robots.txt dans votre répertoire racine (pour les sites WordPress, il devrait s’appeler public_html). Ensuite, vous pouvez ouvrir le fichier et apporter les modifications nécessaires.
Vous pouvez utiliser les déclarations allow et disallow pour personnaliser l’indexation de votre site WordPress. Par exemple, vous pouvez souhaiter qu’un certain fichier soit explorer sans indexer le dossier entier. Dans ce cas, vous pouvez ajouter ce code :
User-agent: *
Disallow: /wp-admin/
Allow: /wp-admin/admin-ajax.phpN’oubliez pas de cibler la page qui provoque l’erreur « Indexé, bien que bloqué par robots.txt » pendant ce processus. En fonction de votre objectif, vous pouvez préciser si Google doit ou non explorer la page.
Lorsque vous avez terminé, enregistrez vos modifications. Ensuite, retournez dans la Google Search Console pour voir si cette méthode a permis de résoudre l’erreur.
Méthode 2 : Utiliser un plugin de SEO
Si vous avez activé une extension de référencement, vous n’aurez pas à créer un fichier robots.txt entièrement nouveau. Dans de nombreux cas, l’outil de référencement en construira un pour vous. De plus, il peut également fournir des moyens de modifier le fichier sans quitter le tableau de bord de WordPress.
Yoast SEO
L’une des extensions de SEO les plus populaires est Yoast SEO. Elle peut fournir une analyse détaillée du référencement sur page, ainsi que des outils supplémentaires pour personnaliser votre indexation dans les moteurs de recherche.
Pour commencer à modifier votre fichier robots.txt, allez dans Yoast SEO > Outils dans votre tableau de bord WordPress. Dans la liste des outils intégrés, sélectionnez l’éditeur de fichiers:

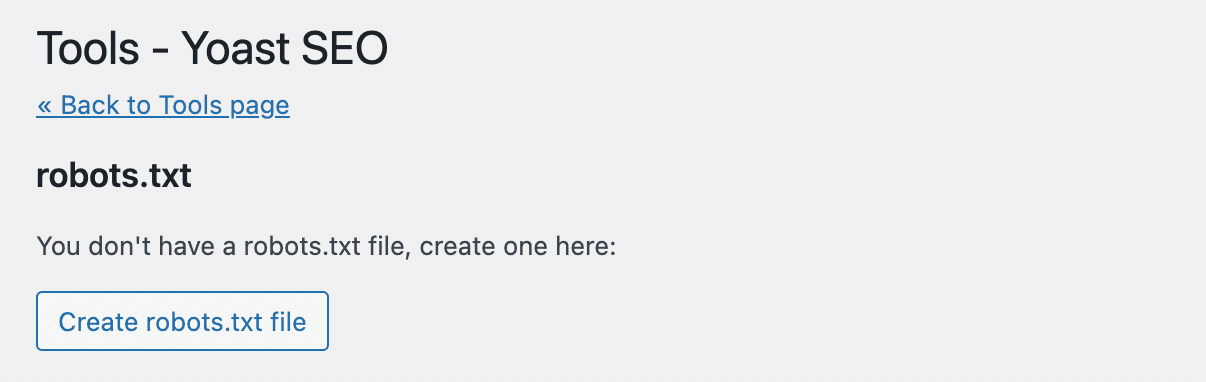
Yoast SEO ne créera pas automatiquement un fichier robots.txt. Si vous n’en avez pas déjà un, cliquez sur Créer un fichier robots.txt :
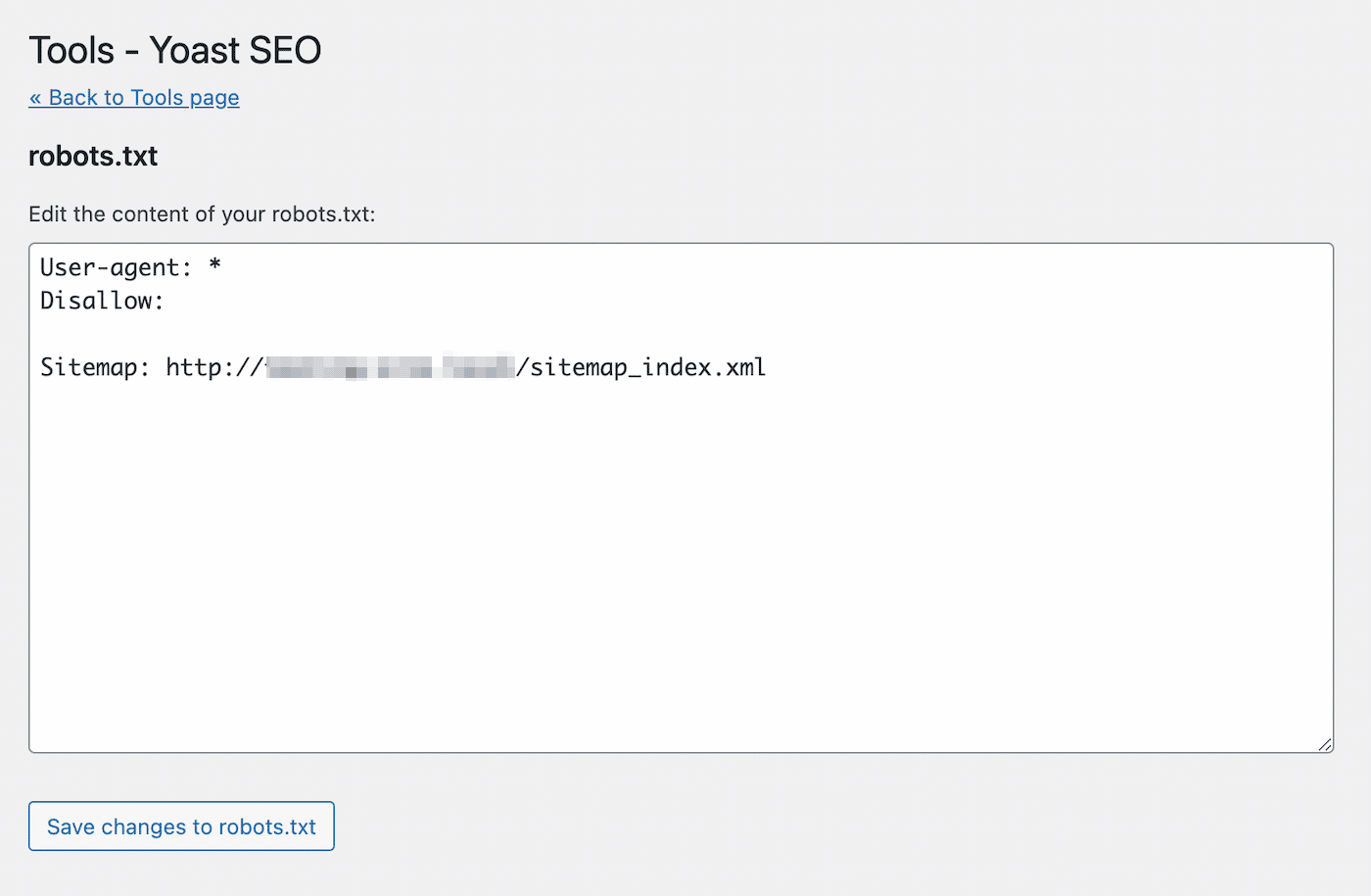
Cela ouvrira un éditeur de texte avec le contenu de votre nouveau fichier robots.txt. Comme pour la première méthode, vous pouvez ajouter des déclarations allow aux pages que vous souhaitez voir indexées. Alternativement, utilisez des déclarations disallow pour les URL pour éviter l’indexation :
Après avoir effectué vos modifications, enregistrez le fichier. Yoast SEO vous alertera lorsque vous aurez mis à jour le fichier robots.txt.
Rank Math
Rank Math est une autre extension freemium qui inclut un éditeur de robots.txt. Après avoir activé l’outil sur votre site WordPress, allez dans Rank Math > Réglages généraux > Modifier robots.txt:
Dans l’éditeur de code, vous verrez quelques règles par défaut, dont votre plan de site. Pour mettre à jour ses réglages, vous pouvez coller ou supprimer du code si nécessaire.
Pendant ce processus d’édition, il y a quelques règles que vous devez suivre :
- Utilisez un ou plusieurs groupes, chaque groupe contenant plusieurs règles.
- Commencez chaque groupe par un agent utilisateur et poursuivez avec des répertoires ou des fichiers spécifiques.
- Partez du principe que toute page web permet l’indexation, à moins qu’elle ne comporte une règle disallow.
Gardez à l’esprit que cette méthode n’est possible que si vous n’avez pas déjà un fichier robots.txt dans votre répertoire racine. Si c’est le cas, vous devrez modifier le fichier robots.txt directement à l’aide d’un client SFTP. Sinon, vous pouvez supprimer ce fichier pré-existant et utiliser l’éditeur Rank Math à la place.
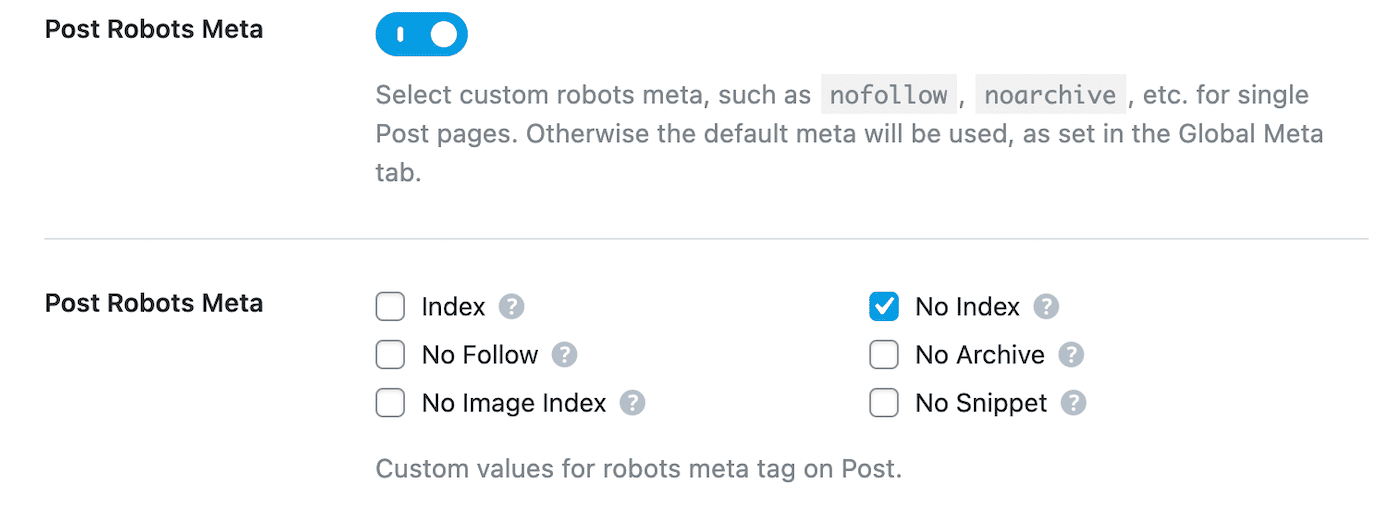
Une fois que vous avez interdit une page dans le fichier robots.txt, vous devez également ajouter une directive noindex. Cela permettra de garder la page privée des recherches Google. Pour cela, rendez-vous dans Rank Math > Titres & méta > Articles :
Faites défiler jusqu’à Méta robots articles activez-le. Ensuite, sélectionnez Pas d’index :
Enfin, enregistrez vos modifications. Dans Google Search Console, trouvez l’avertissement « Indexé, mais bloqué par robots.txt » et cliquez sur Valider la correction. Cela permettra à Google de recrawler les URLs données et de résoudre l’erreur.
Squirrly SEO
En utilisant l’extension Squirrly SEO, vous pouvez de la même manière modifier le fichier robots.txt. Pour commencer, cliquez sur Squirrly SEO > Configuration SEO. Cela ouvrira les réglages Tweaks et Sitemap :
Sur le côté gauche, sélectionnez l’onglet Fichier Robots. Vous verrez alors un éditeur de fichier robots.txt qui ressemble à celui des autres extensions de SEO :
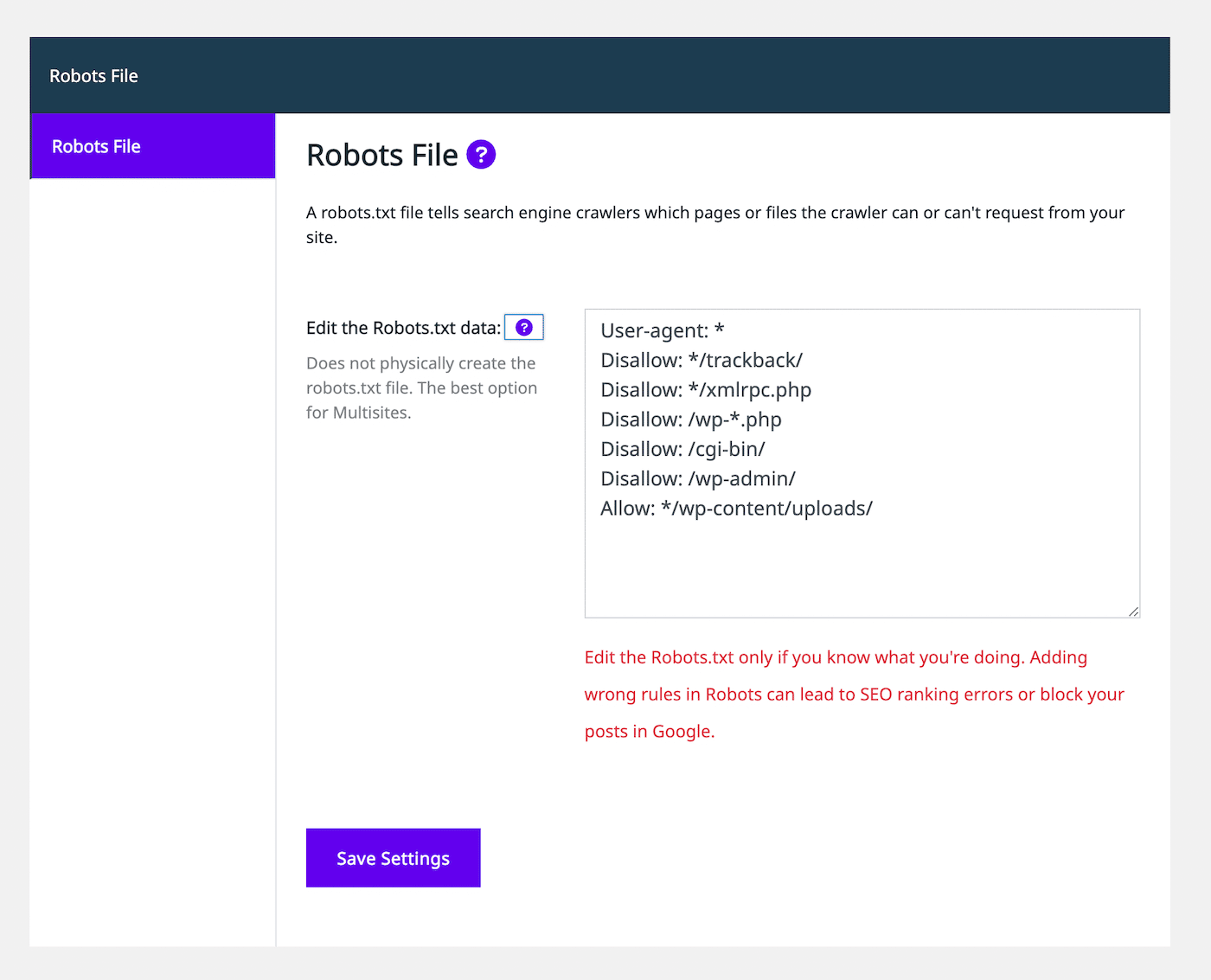
En utilisant l’éditeur de texte, vous pouvez ajouter des déclarations d’autorisation ou d’interdiction pour personnaliser le fichier robots.txt. Continuez à ajouter autant de règles que vous le souhaitez. Lorsque vous êtes satisfait de l’apparence de ce fichier, sélectionnez Enregistrer les réglages.
En outre, vous pouvez ajouter des règles noindex à certains types de publication. Pour cela, il vous suffit de désactiver le réglage Laisser Google l’indexer dans l’onglet Automatisation. Par défaut, SEO Squirrly laisse ce réglage activé.
Résumé
En règle générale, Google trouve vos pages web et les indexe dans ses résultats de recherche. Toutefois, un fichier robots.txt mal configuré peut semer la confusion dans l’esprit des moteurs de recherche quant à la nécessité d’ignorer cette page lors de l’exploration. Dans ce cas, vous devrez clarifier les instructions d’exploration pour continuer à optimiser le référencement de votre site web.
Vous pouvez modifier le fichier robots.txt directement avec un client SFTP tel que FileZilla. Sinon, de nombreuses extensions SEO, dont Yoast, Rank Math et Squirrly SEO, incluent des éditeurs de robots.txt dans leurs interfaces. En utilisant l’un de ces outils, vous serez en mesure d’ajouter des déclarations d’autorisation et d’exclusion pour aider les moteurs de recherche à indexer correctement votre contenu.
Pour aider votre site web à se hisser au sommet des résultats de recherche, nous vous recommandons de choisir un hébergeur web optimisé pour le SEO. Chez Kinsta, nos plans d’hébergement WordPress infogérés comprennent des outils SEO tels que la surveillance du temps de fonctionnement, les certificats SSL et la gestion des redirections. Consultez nos plans dès aujourd’hui !

Rédacteur en chef chez Kinsta et consultant en marketing de contenu pour les développeurs de plugins WordPress. Connectez-vous avec Matteo sur Twitter.

