
Come vi dirà chiunque possieda un sito, la perdita di dati e i tempi di inattività, anche in dosi minime, possono essere catastrofici. Possono colpire gli impreparati in qualsiasi momento, riducendo la produttività, l’accessibilità e la fiducia nei prodotti.
Per proteggere l’integrità del vostro sito, è fondamentale predisporre delle misure di salvaguardia contro la possibilità di downtime o perdita di dati.
È qui che entra in gioco la replica dei dati.
La replica dei dati è un processo di backup automatico in cui i dati vengono ripetutamente copiati dal database principale a un’altra posizione remota per essere conservati. È una tecnologia fondamentale per qualsiasi sito o applicazione che usare un server di database. Potete anche sfruttare il database replicato per elaborare SQL di sola lettura, consentendo l’esecuzione di più processi all’interno del sistema.
L’impostazione della replica tra due database offre una tolleranza ai guasti contro gli imprevisti. È considerata la migliore strategia per ottenere un’alta disponibilità durante i disastri.
In questo articolo, approfondiremo le diverse strategie che possono essere implementate dagli sviluppatori di backend per una replica PostgreSQL senza soluzione di continuità.
Cos’È la Replica PostgreSQL?
La replica PostgreSQL è definita come il processo di copia dei dati da un server di database PostgreSQL a un altro server. Il server del database di origine è noto anche come server “primario”, mentre il server del database che riceve i dati copiati è noto come server “di replica”.
Il database PostgreSQL segue un modello di replica semplice, in cui tutte le scritture vengono inviate a un nodo primario. Il nodo primario può quindi applicare le modifiche e trasmetterle ai nodi secondari.
Cos’è il Failover Automatico?
Il failover è un metodo per recuperare i dati se il server primario cede per qualsiasi motivo. Se avete configurato PostreSQL per gestire la replica dello streaming fisico, voi e i vostri utenti sarete protetti dai tempi di inattività dovuti a un guasto del server primario.
Il processo di failover può richiedere un po’ di tempo per essere configurato e avviato. In PostgreSQL non esistono strumenti integrati per il monitoraggio e l’analisi dei guasti del server, quindi è necessario essere creativi.
Non dovete dipendere da PostgreSQL per il failover. Esistono strumenti dedicati che consentono il failover automatico e il passaggio automatico allo standby, riducendo i tempi di inattività del database.
Impostando la replica di failover, garantite l’alta disponibilità e vi assicurate che gli standby siano disponibili se il server primario dovesse crollare.
Vantaggi dell’Uso della Replica PostgreSQL
Ecco alcuni vantaggi chiave dell’utilizzo della replica di PostgreSQL:
- Migrazione dei dati: Potete sfruttare la replica di PostgreSQL per la migrazione dei dati, sia attraverso un cambio di hardware del server di database che attraverso l’implementazione del sistema.
- Tolleranza ai guasti: Se il server primario si guasta, il server standby può fungere da server perché i dati contenuti sia nel server primario che in quello standby sono gli stessi.
- Performance Online Transactional Processing (OLTP): Potete migliorare il tempo di elaborazione delle transazioni e il tempo di interrogazione di un sistema OLTP eliminando il carico delle query di reporting. Il tempo di elaborazione delle transazioni è la durata dell’esecuzione di una determinata query prima che una transazione sia terminata.
- Test del sistema in parallelo: Durante l’aggiornamento di un nuovo sistema, è necessario assicurarsi che il sistema funzioni bene con i dati esistenti; da qui la necessità di testare con una copia del database di produzione prima dell’implementazione.
Come Funziona la Replica PostgreSQL
In genere, si pensa che quando ci si diletta con un’architettura primaria e secondaria, ci sia un solo modo per impostare i backup e la replica. Le implementazioni di PostgreSQL, invece, possono seguire uno qualsiasi di questi tre metodi:
- Replica in streaming: Replica i dati dal nodo primario al secondario, quindi copia i dati su Amazon S3 o Azure Blob per l’archiviazione di backup.
- Replica a livello di volume per replicare a livello di storage dal nodo primario a quello secondario, seguita da un backup su storage blob/S3.
- Backup incrementali: Replica i dati dal nodo primario mentre costruisce un nuovo nodo secondario dallo storage di Amazon S3 o Azure Blob, consentendo lo streaming direttamente dal nodo primario.
Metodo 1: Streaming
La replica in streaming di PostgreSQL, nota anche come replica WAL, può essere impostata senza problemi dopo aver installato PostgreSQL su tutti i server. Questo approccio alla replica si basa sullo spostamento dei file WAL dal database primario a quello di destinazione.
Potete implementare la replica in streaming di PostgreSQL usando una configurazione primaria-secondaria. Il server primario è l’istanza principale che gestisce il database primario e tutte le sue operazioni. Il server secondario agisce come istanza supplementare ed esegue tutte le modifiche apportate al database primario su se stesso, generando una copia identica nel processo. Il server primario è un server di lettura/scrittura, mentre il server secondario è di sola lettura.
Per questo metodo, è necessario configurare sia il nodo primario che il nodo standby. Le sezioni seguenti illustrano i passaggi necessari per configurarli con facilità.
Configurazione del Nodo Primario
Potete configurare il nodo primario per la replica in streaming eseguendo i seguenti passaggi:
Passo 1: Inizializzare il Database
Per inizializzare il database, potete usare il comando initidb utility. Successivamente, potete creare un nuovo utente con privilegi di replica utilizzando il seguente comando:
CREATE USER 'example_username' REPLICATION LOGIN ENCRYPTED PASSWORD 'example_password';L’utente dovrà fornire una password e un nome utente per la query indicata. La parola chiave replica viene utilizzata per dare all’utente i privilegi richiesti. Un esempio di query potrebbe essere il seguente:
CREATE USER 'rep_username' REPLICATION LOGIN ENCRYPTED PASSWORD 'rep_password';Passo 2: Configurare le Proprietà di Streaming
Successivamente, potete configurare le proprietà dello streaming con il file di configurazione di PostgreSQL (postgresql.conf) che può essere modificato come segue:
wal_level = logical
wal_log_hints = on
max_wal_senders = 8
max_wal_size = 1GB
hot_standby = onEcco un po’ di informazioni sui parametri usati nel frammento precedente:
wal_log_hints: Questo parametro è necessario per la funzionalitàpg_rewindche si rivela utile quando il server standby non è sincronizzato con il server principale.wal_level: Potete usare questo parametro per abilitare la replica in streaming di PostgreSQL, con valori possibili comeminimal,replica, ological.max_wal_size: Questo parametro può essere usato per specificare la dimensione dei file WAL che possono essere conservati nei file di log.hot_standby: Potete sfruttare questo parametro per una connessione in lettura con il secondario quando è impostato su ON.max_wal_senders: Potete usaremax_wal_sendersper specificare il numero massimo di connessioni contemporanee che possono essere stabilite con i server standby.
Passo 3: Creare una Nuova Voce
Dopo aver modificato i parametri nel file postgresql.conf, una nuova voce di replica nel file pg_hba.conf può consentire ai server di stabilire una connessione reciproca per la replica.
Di solito questo file si trova nella directory dei dati di PostgreSQL. Per farlo, potete usare il seguente snippet di codice:
host replication rep_user IPaddress md5Una volta eseguito lo snippet di codice, il server primario permette a un utente chiamato rep_user di connettersi e di agire come server standby utilizzando l’IP specificato per la replica. Per esempio:
host replication rep_user 192.168.0.22/32 md5Configurazione del Nodo Standby
Per configurare il nodo standby per la replica in streaming, seguite i seguenti passaggi:
Passo 1: Backup del Nodo Primario
Per configurare il nodo standby, usate l’utility pg_basebackup per generare un backup del nodo primario. Questo servirà come punto di partenza per il nodo standby. Potete usare questa utility con la seguente sintassi:
pg_basebackp -D -h -X stream -c fast -U rep_user -WI parametri usati nella sintassi di cui sopra sono i seguenti:
-h: Potete usare questo parametro per menzionare l’host primario.-D: Questo parametro indica la directory su cui state lavorando.-C: Potete usare questo parametro per impostare i checkpoint.-X: Questo parametro può essere usato per includere i file di log transazionali necessari.-W: Potete usare questo parametro per richiedere all’utente una password prima di collegarsi al database.
Passo 2: Impostare il File di Configurazione della Replica
Successivamente, dovete verificare se il file di configurazione della replica esiste. Se non esiste, potete generare il file di configurazione della replica come recovery.conf.
Dovete creare questo file nella directory dei dati dell’installazione di PostgreSQL. Potte generarlo automaticamente usando l’opzione -R dell’utility pg_basebackup.
Il file recovery.conf deve contenere i seguenti comandi:
standby_mode = 'on'
primary_conninfo = 'host=<master_host> port=<postgres_port> user=<replication_user> password=<password> application_name="host_name"'
recovery_target_timeline = 'latest'
I parametri utilizzati nei suddetti comandi sono i seguenti:
primary_conninfo: Potete usare questo parametro per creare una connessione tra il server primario e quello secondario sfruttando una stringa di connessione.standby_mode: Questo parametro può far sì che il server primario parta come standby quando viene acceso.recovery_target_timeline: Potete usare questo parametro per impostare il tempo di ripristino.
Per impostare una connessione, dovete fornire il nome utente, l’indirizzo IP e la password come valori del parametro primary_conninfo. Per esempio:
primary_conninfo = 'host=192.168.0.26 port=5432 user=rep_user password=rep_pass'Passo 3: Riavviare il Server Secondario
Infine, potete riavviare il server secondario per completare il processo di configurazione.
Tuttavia, la replica in streaming comporta diverse sfide, come per esempio:
- Diversi client PostgreSQL (scritti in diversi linguaggi di programmazione) dialogano con un unico endpoint. Quando il nodo primario si guasta, questi client continuano a riprovare lo stesso nome DNS o IP. In questo modo il failover è visibile all’applicazione.
- La replica di PostgreSQL non è dotata di failover e monitoraggio integrati. Quando il nodo primario si guasta, dovete promuovere un secondario come nuovo primario. Questa promozione deve essere eseguita in modo che i client scrivano su un solo nodo primario e non osservino incongruenze nei dati.
- PostgreSQL replica l’intero stato. Quando è necessario sviluppare un nuovo nodo secondario, quest’ultimo deve recuperare l’intera cronologia dei cambiamenti di stato dal nodo primario, il che richiede un notevole dispendio di risorse e rende costosa l’eliminazione dei nodi della testa e la creazione di nuovi nodi.
Metodo 2: Dispositivo a Blocchi Replicato
L’metodo del dispositivo a blocchi replicato dipende dal mirroring del disco (noto anche come replica del volume). In questo approccio, le modifiche vengono scritte su un volume persistente che viene sincronizzato con un altro volume.
Il vantaggio di questo metodo è la compatibilità e la durata dei dati in ambienti cloud con tutti i database relazionali, tra cui PostgreSQL, MySQL e SQL Server, per citarne alcuni.
Tuttavia, l’metodo alla replica di PostgreSQL basato sul mirroring del disco richiede la replica sia dei log WAL che dei dati delle tabelle. Dal momento che ogni scrittura sul database deve passare attraverso la rete in modo sincrono, non potete permettervi di perdere nemmeno un byte, perché questo potrebbe lasciare il vostro database in uno stato corrotto.
Questo approccio viene normalmente utilizzato con Azure PostgreSQL e Amazon RDS.
Metodo 3: WAL
Il WAL consiste in file di segmenti (16 MB per impostazione predefinita). Ogni segmento contiene uno o più record. Un record di sequenza di log (LSN) è un puntatore a un record nel WAL, che consente di conoscere la posizione/località in cui il record è stato salvato nel file di log.
Un server standby sfrutta i segmenti WAL – noti anche come XLOGS nella terminologia di PostgreSQL – per replicare continuamente le modifiche dal server primario. Potete usare il write-ahead logging per garantire la durabilità e l’atomicità di un DBMS serializzando pezzi di dati byte-array (ognuno con un LSN univoco) in uno storage stabile prima che vengano applicati al database.
L’applicazione di una mutazione a un database può portare a diverse operazioni sul file system. Una domanda pertinente che sorge spontanea è come un database possa garantire l’atomicità in caso di guasto del server dovuto a un’interruzione di corrente mentre è nel bel mezzo di un aggiornamento del file system. Quando un database si avvia, inizia un processo di avvio o replay che può leggere i segmenti WAL disponibili e confrontarli con l’LSN memorizzato su ogni pagina di dati (ogni pagina di dati è contrassegnata con l’LSN dell’ultimo record WAL che riguarda la pagina).
Replica Basata sul Log Shipping (Livello di Blocco)
La replica in streaming perfeziona il processo di spedizione dei log. Invece di aspettare il passaggio al WAL, i record vengono inviati man mano che vengono creati, riducendo così il ritardo della replica.
La replica in streaming supera anche il log shipping perché il server standby si collega al server primario attraverso la rete sfruttando un protocollo di replica. Il server primario può quindi inviare i record WAL direttamente attraverso questa connessione senza dover dipendere dagli script forniti dall’utente finale.
Replica Basata sul Log Shipping (Livello File)
Il log shipping è definito come la copia dei file di log su un altro server PostgreSQL per generare un altro server di standby riproducendo i file WAL. Questo server è configurato per funzionare in modalità di recupero e il suo unico scopo è quello di applicare i nuovi file WAL non appena si presentano.
Questo server secondario diventa quindi un backup a caldo del server PostgreSQL primario. Può anche essere configurato per essere una replica di lettura, dove può offrire query di sola lettura, anche detta hot standby.
Archiviazione WAL Continua
La duplicazione dei file WAL man mano che vengono creati in una posizione diversa dalla sottodirectory pg_wal per archiviarli è nota come archiviazione WAL. PostgreSQL richiama uno script fornito dall’utente per l’archiviazione, ogni volta che viene creato un file WAL.
Lo script può sfruttare il comando scp per duplicare il file in una o più posizioni, come per esempio un mount NFS. Una volta archiviati, i file WAL possono essere utilizzati per recuperare il database in qualsiasi momento.
Altre configurazioni basate sui log includono:
- Replica sincrona: Prima che ogni transazione di replica sincrona venga impegnata, il server primario attende che gli standby confermino di aver ricevuto i dati. Il vantaggio di questa configurazione è che non ci saranno conflitti dovuti a processi di scrittura paralleli.
- Replica sincrona multi-master: In questo caso, ogni server può accettare richieste di scrittura e i dati modificati vengono trasmessi dal server originale a tutti gli altri server prima che ogni transazione venga impegnata. Sfrutta il protocollo 2PC e rispetta la regola “tutto o niente”.
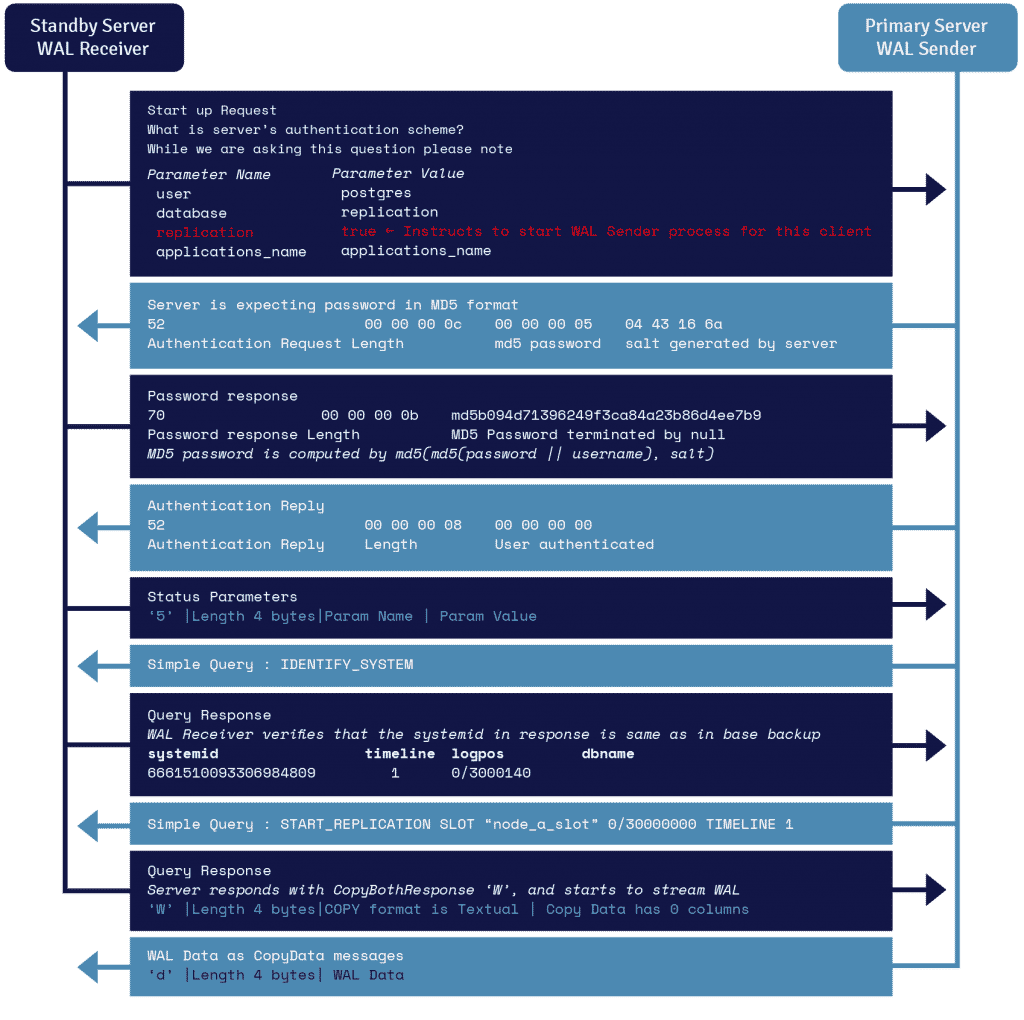
Dettagli del Protocollo di Streaming WAL
Un processo noto come ricevitore WAL, in esecuzione sul server standby, sfrutta i dettagli della connessione forniti nel parametro primary_conninfo di recovery.conf e si connette al server primario sfruttando una connessione TCP/IP.
Per avviare la replica in streaming, il frontend può inviare il parametro di replica nel messaggio di avvio. Un valore booleano di true, yes, 1 o ON fa capire al backend che deve passare alla modalità walsender di replica fisica.
Il WAL sender è un altro processo che viene eseguito sul server primario e ha il compito di inviare i record WAL al server standby quando vengono generati. Il ricevitore WAL salva i record WAL nel WAL come se fossero stati creati dall’attività dei client connessi localmente.
Una volta che i record WAL raggiungono i file di segmento WAL, il server standby continua a riprodurre costantemente il WAL in modo che il server primario e quello standby siano aggiornati.
Elementi di Replica PostgreSQL
In questa sezione, potete approfondire la conoscenza dei modelli comunemente utilizzati (replica single-master e multi-master), dei tipi (replica fisica e logica) e delle modalità (sincrona e asincrona) della replica PostgreSQL.
Modelli di Replica dei Database PostgreSQL
Scalabilità significa aggiungere altre risorse/ hardware ai nodi esistenti per migliorare la capacità del database di memorizzare ed elaborare più dati, il che può essere ottenuto in modo orizzontale e verticale. La replica di PostgreSQL è un esempio di scalabilità orizzontale che è molto più difficile da implementare rispetto alla scalabilità verticale. La scalabilità orizzontale può essere ottenuta principalmente tramite la replica single-master (SMR) e la replica multi-master (MMR).
La replica single-master consente di modificare i dati solo su un singolo nodo e di replicare le modifiche su uno o più nodi. Le tabelle replicate nel database di replica non possono accettare alcuna modifica, tranne quelle provenienti dal server primario. Anche se lo fanno, le modifiche non vengono replicate al server primario.
Nella maggior parte dei casi, la SMR è sufficiente per l’applicazione perché è meno complicata da configurare e gestire, oltre a non avere possibilità di conflitti. La replica single-master è anche unidirezionale, in quanto i dati di replica fluiscono principalmente in una direzione, dal database primario a quello di replica.
In alcuni casi, la sola SMR potrebbe non essere sufficiente e potrebbe essere necessario implementare la MMR. L’MMR permette a più di un nodo di agire come nodo primario. Le modifiche alle righe delle tabelle in più di un database primario designato vengono replicate alle tabelle corrispondenti in ogni altro database primario. In questo modello, spesso si usano schemi di risoluzione dei conflitti per evitare problemi come la duplicazione delle chiavi primarie.
L’utilizzo dell’MMR presenta alcuni vantaggi, tra cui:
- In caso di guasto dell’host, gli altri host possono comunque fornire servizi di aggiornamento e inserimento.
- I nodi primari sono distribuiti in diverse località, quindi la possibilità che tutti i nodi primari si guastino è molto bassa.
- Possibilità di usare una rete WAN (Wide Area Network) di database primari che possono essere geograficamente vicini a gruppi di clienti, pur mantenendo la coerenza dei dati in tutta la rete.
Tuttavia, l’aspetto negativo dell’implementazione dell’MMR è la complessità e la difficoltà di risolvere i conflitti.
Diversi rami e applicazioni forniscono soluzioni MMR, dato che PostgreSQL non lo supporta in modo nativo. Queste soluzioni possono essere open-source, gratuite o a pagamento. Una di queste è la replica bidirezionale (BDR) che è asincrona e si basa sulla funzione di decodifica logica di PostgreSQL.
Poiché l’applicazione BDR riproduce le transazioni su altri nodi, l’operazione di replay può fallire se c’è un conflitto tra la transazione applicata e quella impegnata sul nodo ricevente.
Tipi di Replica PostgreSQL
Esistono due tipi di replica PostgreSQL: la replica logica e quella fisica.
Una semplice operazione logica initdb esegue l’operazione fisica di creazione di una directory di base per un cluster. Allo stesso modo, una semplice operazione logica CREATE DATABASE eseguirà l’operazione fisica di creazione di una sottodirectory nella directory di base.
La replica fisica di solito si occupa di file e directory. Non sa cosa rappresentino questi file e directory. Questi metodi sono utilizzati per mantenere una copia completa di tutti i dati di un singolo cluster, in genere su un’altra macchina, e vengono eseguiti a livello di file system o di disco e usano indirizzi di blocco esatti.
La replica logica è un modo per riprodurre le entità di dati e le loro modifiche, basandosi sulla loro identità di replica (di solito una chiave primaria). A differenza della replica fisica, si occupa di database, tabelle e operazioni DML e avviene a livello di cluster di database. Usa un modello publish e subscribe in cui uno o più sottoscrittori sono abbonati a una o più pubblicazioni su un nodo editore.
Il processo di replica inizia con l’acquisizione di un’istantanea dei dati sul database dell’editore e la successiva copia sul sottoscrittore. Gli abbonati estraggono i dati dalle pubblicazioni a cui si abbonano e possono ripubblicare i dati in un secondo momento per consentire la replica a cascata o configurazioni più complesse. L’abbonato applica i dati nello stesso ordine dell’editore in modo da garantire la coerenza transazionale delle pubblicazioni all’interno di un singolo abbonamento, nota anche come replica transazionale.
I casi d’uso tipici della replica logica sono:
- Invio di modifiche incrementali in un singolo database (o in un sottoinsieme di un database) agli abbonati man mano che si verificano.
- Condividere un sottoinsieme del database tra più database.
- Attivare l’avvio delle singole modifiche quando arrivano all’abbonato.
- Consolidamento di più database in uno solo.
- Fornire l’accesso ai dati replicati a diversi gruppi di utenti.
Il database sottoscrittore si comporta come qualsiasi altra istanza di PostgreSQL e può essere utilizzato come editore per altri database definendo le sue pubblicazioni.
Se il subscriber è trattato come di sola lettura dall’applicazione, non ci saranno conflitti da una singola sottoscrizione. D’altra parte, se ci sono altre scritture effettuate da un’applicazione o da altri sottoscrittori sullo stesso insieme di tabelle, possono sorgere dei conflitti.
PostgreSQL supporta entrambi i meccanismi contemporaneamente. La replica logica consente un controllo a grana fine sia sulla replica dei dati che sulla sicurezza.
Modalità di Replica
Le modalità di replica di PostgreSQL sono principalmente due: sincrona e asincrona. La replica sincrona permette di scrivere i dati contemporaneamente sul server primario e su quello secondario, mentre la replica asincrona garantisce che i dati vengano prima scritti sull’host e poi copiati sul server secondario.
Nella replica in modalità sincrona, le transazioni sul database primario sono considerate complete solo quando le modifiche sono state replicate a tutte le repliche. I server di replica devono essere tutti sempre disponibili affinché le transazioni sul primario siano completate. La modalità di replica sincrona viene utilizzata in ambienti transazionali di alto livello con requisiti di failover immediato.
In modalità asincrona, le transazioni sul server primario possono essere dichiarate completate quando le modifiche sono state effettuate solo sul server primario. Queste modifiche vengono poi replicate nelle repliche in un secondo momento. I server di replica possono rimanere non sincronizzati per un certo periodo di tempo, chiamato ritardo di replica. In caso di crash, si può verificare una perdita di dati, ma l’overhead fornito dalla replica asincrona è ridotto, quindi è accettabile nella maggior parte dei casi (non sovraccarica l’host). Il failover dal database primario a quello secondario richiede più tempo rispetto alla replica sincrona.
Come Impostare la Replica di PostgreSQL
In questa sezione vi mostreremo come impostare il processo di replica di PostgreSQL su un sistema operativo Linux. In questo caso, utilizzeremo Ubuntu 18.04 LTS e PostgreSQL 10.
Entriamo nel vivo dell’argomento!
Installazione
Iniziiamo installando PostgreSQL su Linux con i seguenti passaggi:
- Per prima cosa, dovete importare la chiave di firma di PostgreSQL digitando il seguente comando nel terminale:
wget -q https://www.postgresql.org/media/keys/ACCC4CF8.asc -O- | sudo apt-key add - - Poi, aggiungete il repository PostgreSQL digitando il seguente comando nel terminale:
echo "deb http://apt.postgresql.org/pub/repos/apt/ bionic-pgdg main" | sudo tee /etc/apt/sources.list.d/postgresql.list - Aggiornate l’indice del repository digitando il seguente comando nel terminale:
sudo apt-get update - Installate il pacchetto PostgreSQL usando il comando apt:
sudo apt-get install -y postgresql-10 - Infine, impostate la password per l’utente PostgreSQL con il seguente comando:
sudo passwd postgres
L’installazione di PostgreSQL è obbligatoria sia per il server primario che per quello secondario prima di avviare il processo di replica di PostgreSQL.
Una volta configurato PostgreSQL per entrambi i server, potete passare alla configurazione della replica del server primario e di quello secondario.
Impostazione della Replica nel Server Primario
Eseguite questi passaggi dopo aver installato PostgreSQL su entrambi i server primario e secondario.
- Per prima cosa, accedete al database PostgreSQL con il seguente comando:
su - postgres - Create un utente di replica con il seguente comando:
psql -c "CREATEUSER replication REPLICATION LOGIN CONNECTION LIMIT 1 ENCRYPTED PASSWORD'YOUR_PASSWORD';" - Modificate il file pg_hba.cnf con qualsiasi applicazione nano in Ubuntu e aggiungete la seguente configurazione:
nano /etc/postgresql/10/main/pg_hba.confPer configurare il file, usate il seguente comando:
host replication replication MasterIP/24 md5 - Aprite e modificate postgresql.conf e inserite la seguente configurazione nel server primario:
nano /etc/postgresql/10/main/postgresql.confUsate le seguenti impostazioni di configurazione:
listen_addresses = 'localhost,MasterIP'wal_level = replicawal_keep_segments = 64max_wal_senders = 10 - Infine, riavviate PostgreSQL nel server principale:
systemctl restart postgresqlA questo punto avete completato l’installazione sul server primario.
Impostazione della Replica nel Server Secondario
Seguite questi passaggi per impostare la replica nel server secondario:
- Accedete a PostgreSQL RDMS con il comando seguente:
su - postgres - Arrestate il servizio PostgreSQL così potete lavorare su di esso con il comando seguente:
systemctl stop postgresql - Modificate il file pg_hba.conf con questo comando e aggiungete la seguente configurazione:
// "Edit" command nano /etc/postgresql/10/main/pg_hba.conf // "Configuration" command host replication replication MasterIP/24 md5 - Aprite e modificate postgresql.conf nel server secondario e inserite la seguente configurazione o togliete il commento se è commentata:
nano /etc/postgresql/10/main/postgresql.conf listen_addresses = 'localhost,SecondaryIP' wal_keep_segments = 64 wal_level = replica hot_standby = on max_wal_senders = 10SecondaryIPè l’indirizzo del server secondario - Accedete alla directory dei dati PostgreSQL nel server secondario e rimuovete tutto:
cd /var/lib/postgresql/10/main rm -rfv * - Copiate i file della directory dei dati del server primario PostgreSQL nella directory dei dati del server secondario PostgreSQL e scrivete questo comando nel server secondario:
pg_basebackup -h MasterIP -D /var/lib/postgresql/11/main/ -P -U replication --wal-method=fetch - Inserite la password del server primario PostgreSQL e premete invio. Successivamente, aggiungete il seguente comando per la configurazione di recupero:
// "Edit" Command nano /var/lib/postgresql/10/main/recovery.conf // Configuration standby_mode = 'on' primary_conninfo = 'host=MasterIP port=5432 user=replication password=YOUR_PASSWORD' trigger_file = '/tmp/MasterNow'Qui,
YOUR_PASSWORDè la password dell’utente di replica nel server primario creato da PostgreSQL - Una volta impostata la password, dovrete riavviare il database PostgreSQL secondario poiché è stato interrotto:
systemctl start postgresqlVerifica della Configurazione
Ora che abbiamo eseguito i passaggi, testiamo il processo di replica e osserviamo il database del server secondario. A tal fine, creiamo una tabella nel server primario e osserviamo se la stessa si riflette sul server secondario.
Procediamo.
- Poiché stiamo creando la tabella nel server primario, dovrete effettuare il login al server primario:
su - postgres psql - Ora creiamo una semplice tabella denominata “testtable” e inseriamo i dati nella tabella eseguendo le seguenti query PostgreSQL nel terminale:
CREATE TABLE testtable (websites varchar(100)); INSERT INTO testtable VALUES ('section.com'); INSERT INTO testtable VALUES ('google.com'); INSERT INTO testtable VALUES ('github.com'); - Osservate il database PostgreSQL del server secondario accedendo al server secondario:
su - postgres psql - Ora verifichiamo se la tabella ‘testtable’ esiste e possiamo restituire i dati eseguendo le seguenti query PostgreSQL nel terminale. Questo comando mostra essenzialmente l’intera tabella.
select * from testtable;
Questo è l’output della tabella di prova:
| websites |
-------------------
| section.com |
| google.com |
| github.com |
--------------------Dovreste poter osservare gli stessi dati del server primario.
Se vedete quanto sopra, allora avete portato a termine con successo il processo di replica!
Quali Sono i Passaggi del Failover Manuale di PostgreSQL?
Esaminiamo i passaggi per un failover manuale di PostgreSQL:
- Crash del server principale.
- Promuovere il server standby eseguendo il seguente comando sul server standby:
./pg_ctl promote -D ../sb_data/ server promoting - Connesssione al server standby promosso e inserimento di una riga:
-bash-4.2$ ./edb-psql -p 5432 edb Password: psql.bin (10.7) Type "help" for help. edb=# insert into abc values(4,'Four');
Se l’inserimento funziona correttamente, allora lo standby, che in precedenza era un server di sola lettura, è stato promosso a nuovo server primario.
Come Automatizzare il Failover in PostgreSQL
Impostare il failover automatico è facile.
Avrete bisogno del gestore di failover EDB PostgreSQL (EFM). Dopo aver scaricato e installato EFM su ogni nodo primario e standby, potete creare un cluster EFM, che consiste in un nodo primario, uno o più nodi standby e un nodo Witness opzionale che conferma le asserzioni in caso di guasto.
EFM monitora continuamente la salute del sistema e invia avvisi via email in base agli eventi del sistema. Quando si verifica un guasto, passa automaticamente allo standby più aggiornato e riconfigura tutti gli altri server standby per riconoscere il nuovo nodo primario.
Riconfigura anche i bilanciatori di carico (come pgPool) e impedisce che si verifichi lo “split-brain” (quando due nodi pensano di essere primari).
Riepilogo
A causa dell’elevata quantità di dati, la scalabilità e la sicurezza sono diventati due dei criteri più importanti nella gestione dei database, soprattutto in un ambiente di transazioni. Sebbene sia possibile migliorare la scalabilità in senso verticale aggiungendo più risorse/hardware ai nodi esistenti, ciò non è sempre possibile, spesso a causa dei costi o dei limiti dell’aggiunta di nuovo hardware.
Per questo motivo è necessaria una scalabilità orizzontale, che significa aggiungere altri nodi ai nodi di rete esistenti piuttosto che migliorare le funzionalità dei nodi esistenti. È qui che entra in gioco la replica di PostgreSQL.
In questo articolo abbiamo parlato dei tipi di repliche PostgreSQL, dei vantaggi, delle modalità di replica, dell’installazione e del failover PostgreSQL tra SMR e MMR. Ora vogliamo sentiamo il vostro parere.
Quale dei due sistemi usate di solito? Quale caratteristica del database è più importante per voi e perché? Ci piacerebbe sapere cosa ne pensate! Ditecelo nella sezione commenti qui sotto.

Salman Ravoof é uno sviluppatore web autodidatta, uno scrittore, un creatore e un grande ammiratore del Free and Open Source Software (FOSS). Oltre alla tecnologia, è appassionato di scienza, filosofia, fotografia, arte, gatti e cibo. Per saperne di più su di lui, visitate il suo sito web o contattate Salman su X.

