
複数のサイトの価格を一度に比較したり、いつもチェックするブログですべての記事を一括取得したりできれば…と思った経験はありませんか?これはどちらもウェブスクレイピングで実現可能です。
ウェブスクレイピングとは、ソフトウェアを使用してサイトからコンテンツやデータを抽出する技術です。わかりやすい例として、価格比較サイトは、この技術を用いて複数のオンラインストアから価格情報を読み取っています。また、Googleはウェブサイトのインデックス作成のため、日常的にウェブスクレイピング(クロールと呼ばれる)を行っています。
他にも使用例はさまざま。そこで今回は、その仕組みからウェブスクレイピングツールからサイトを保護する方法まで、ウェブスクレイピングについて知っておきたい情報を一挙ご紹介します。
ウェブスクレイピングとは
ウェブスクレイピングは、ウェブからデータを自動的に抽出する技術です(語源である「scrape」は「かき集める」という意味)。
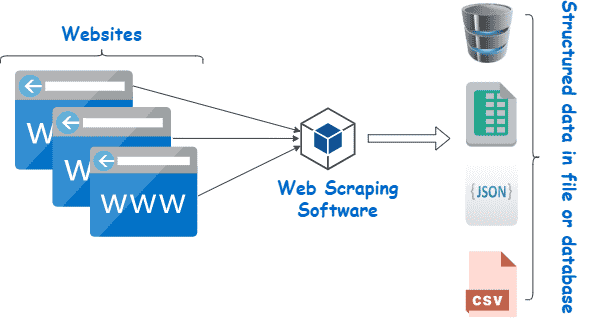
ウェブスクレイピングは、コンテンツスクレイピングやデータスクレイピングなどとも呼ばれ、オンラインデータ収集に非常に便利なツールです。市場調査、価格比較、コンテンツモニタリングなどの用途があります。
とはいえ、データを「スクレイピングする」(かき集める)と聞くと、その合法性が気になる方もいるでしょう。また、サイト運営者の立場では、勝手に誰かにサイトのコンテンツを抽出されることを想像すると不安になります。
ウェブスクレイピングの方法と用途をご紹介する前に、まずはウェブスクレイピングとは何かを押さえておきましょう。
スクレイピング可能なデータ
ウェブスクレイピングは、あらゆるデータに使用できます。検索エンジンやRSSフィードから政府の情報に至るまで、ほとんどのサイトはスクレイパーやクローラー、その他の自動データ収集プログラムに対して、データを一般公開しています。
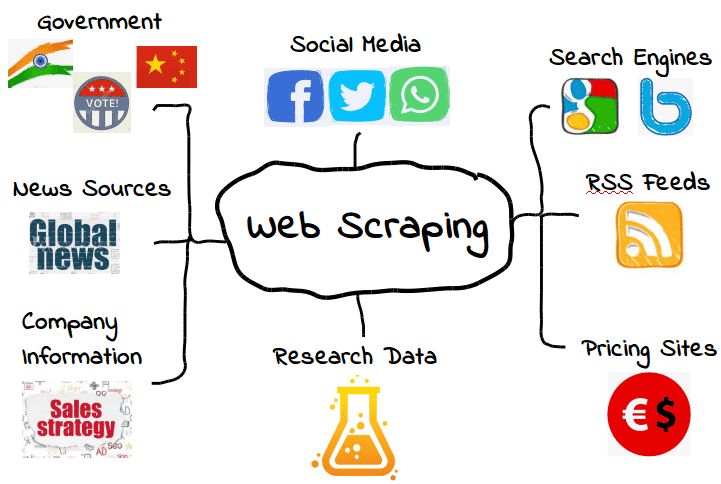
しかし、これらのデータをいつでも自由に取得できるというわけではありません。サイトによっては、取得したいデータを手にするためにツールやトリックが必要になります。例えば、多くのウェブスクレイピングツールは、ビジュアルコンテンツから意味を持つデータを抽出することができません。
例えば、API(アプリケーションプログラミングインターフェース)を通じてデータを取得することができます。サイトがAPIを公開している場合は、さまざまなデータを都合の良い形式で自動的に抽出可能で、これはウェブサーバーが「パイプライン」を提供することで実現します。
もちろん、APIを公開していないサイトも数多くあり、APIを持っているサイトであっても、常に正しい形式でデータを提供してくれるとは限りません。
必要なウェブデータが必要な形式で入手できない場合は、ウェブスクレイピングの出番です。必要な形式でデータが取得できなくても、サイトがすべてのデータを提供していなくても、ウェブスクレイピングによって実現可能です。
一見すると万能ですが、その一方で、制限されているウェブデータをスクレイピングしてもいいのか、という疑問も生じます。これについては、グレーゾーンになる可能性があります。
ウェブスクレイピングは合法なのか
ウェブスクレイピングという行為に、盗用のようなマイナスのイメージを抱く方は少なくないでしょう。「他の人のデータを自分の都合で取得する」というのは聞こえが良いわけではありません。
ウェブスクレイピングは、本質的に違法ではありません。サイトがデータを公開している以上、それは通常一般公開されているため、自由に抽出することができます。
例えば、Amazonは商品価格を公開しており、この価格データをスクレイピングすることには全く問題ありません。人気のショッピングアプリやブラウザの拡張機能の多くは、まさにこの目的でウェブスクレイピングを行っており、これによって訪問者は正しい価格を確認することができます。
しかし、すべてのウェブデータが公開されているわけでなく、すべてのデータのスクレイピングが合法というわけではありません。個人情報や知的財産のスクレイピングはすぐに悪質な行為としてみなされ、DMCAテイクダウン通知などの罰則を科せられます。
悪質なウェブスクレイピング
悪質なウェブスクレイピングは、パブリッシャーが意図していない、または共有することに同意していないデータを抽出することです。このデータは通常、個人情報か知的財産のいずれかになりますが、基本的には一般公開を意図していないデータすべてが対象になる可能性があります。
この定義にはグレーゾーンがあります。多くの個人情報は、EU一般データ保護規則(GDPR)やカリフォルニア州消費者プライバシー法(CCPA)などで保護されていますが、そうでないものも。もちろん、保護されていないからといってスクレイピングしていいとは限りません。

例えば、あるウェブホストが誤って名前やメールアドレスのようなユーザー情報を公開してしまったとします。
このようなデータをスクレイピングすることは技術的には合法ですが、避けるのが最善です。たとえウェブホストの監督不行き届きでデータが公開されていたとしても、このウェブホストがスクレイピングに同意しているとは限りません。
この「グレーゾーン」によって、ウェブスクレイピングには賛否両論があります。ウェブスクレイピングは決して違法ではありませんが、悪意や非倫理的な目的に使用されることもあるため、多くのサーバー会社は、合法かどうかに関わらず、スクレイピングされることを好意的には見ていません。
一定の期間に大量のリクエストを送信する過剰なスクレイピングもまた、悪質な行為です。リクエストが多すぎるとウェブホストに多大な負荷がかかり、サーバーリソースを無駄に消費することになります。
一般的なルールとして、ウェブスクレイピングは控えめに、そしてそのデータが確実に一般利用を目的としている場合にのみ使用します。データが公開されているからといって、スクレイピングが合法的、倫理的であるとは限らないことは念頭においてください。
ウェブスクレイピングの用途
ウェブスクレイピングには、さまざまな業界で多くの用途があります。2021年では、ウェブスクレイピングのほぼ半分がEC戦略の強化に利用されています。
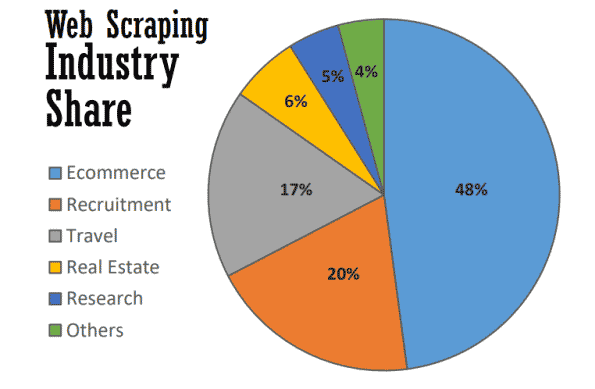
ブランドの追跡や最新の価格比較、市場調査の実施まで、多くのデータ駆動型プロセスで重要な役割を担うウェブスクレイピングです。以下、特に一般的な用途をご紹介します。
市場調査
まずは、顧客の行動や、見込み顧客の監視、競合他社の価格設定の調査など、インバウンドマーケティングやコンテンツマーケティングを成功させるための情報の取得があります。
これらはほんの一例ですが、市場調査の基礎となるあらゆる情報をウェブスクレイピングで抽出することができます。また、このようなデータの多くは一般公開されているため、調査に長時間かけることなく市場を監視したいマーケティング担当者にとっては欠かせません。
タスクの自動化
市場調査に役立つ特徴は、タスクの自動化にも当てはまります。
大量のデータを収集して計算が必要になる自動化タスクには、ウェブスクレイピングはうってつけの技術です。
例えば、10のウェブサイトからデータを収集する必要がある場合、それぞれから同じ種類のデータを収集するのにサイトごとに異なる抽出方法が必要になる場合は手間がかかります。ウェブスクレイピングを利用して自動化するのが賢明かもしれません。
リードジェネレーション
市場調査やタスクの自動化にとどまらず、わずかな労力で見込み顧客のリストを生成することもできてしまいます。
ターゲットをある程度正確に設定する必要はありますが、ウェブスクレイピングを使用して、構造的に見込み顧客のリストを作成するのに十分なユーザー情報を取得可能です。結果は異なるかもしれませんが、手作業でリストを作成するよりもはるかに効率的です。
価格トラッキング
価格の抽出(価格スクレイピングとしても知られる)は、一般的なウェブスクレイピングの用途のひとつです。
以下は、人気のAmazon価格追跡アプリCamelcamelcamelの例です。定期的に商品価格を抽出し、経時的にグラフで比較することができます。
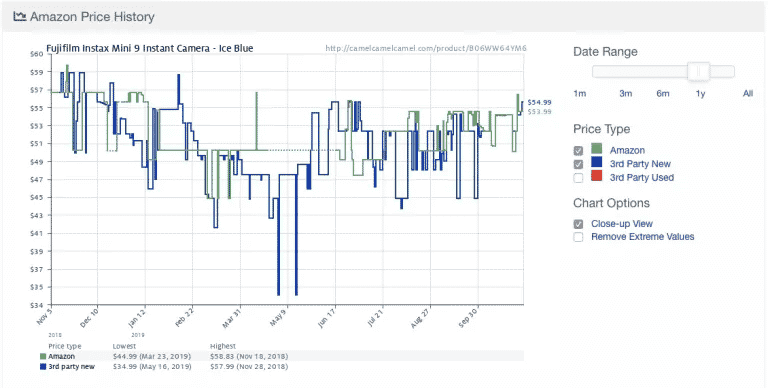
価格は日毎に大きく変動することも(グラフ中央の5月9日頃には突然の値下がりが生じているのがわかる)あります。過去の価格推移を確認することで、ユーザーは購入しようとしている商品の価格が適正であるかどうかをチェックすることができます。上の例で言えば、10ドルお得に買い物できることを期待して購入を先延ばしにすることができます。
この利便性にもかかわらず、価格スクレイピングには賛否両論があります。というのも、多くのユーザーがリアルタイムでの価格確認を求めていることから、特定のサイトにサーバーリクエストで過負荷をかけて情報をスクレイピングする、悪質な価格追跡アプリも存在します。
これを受け、ウェブスクレイピングを完全にブロックする高度な対策を講じるECサイトが増えています。
ニュースとコンテンツ
最新情報を随時取得できることには、もちろんメリットがあります。ドメインの信頼性を確認したり、業界のトレンドを追跡したりするのにもウェブスクレイピングが便利です。
ニュースサイトやブログの中には、RSSフィードのようなインターフェースを提供しているものもありますが、すべてのサイトに該当するわけではありません。そのため、必要なニュースやコンテンツを確実に収集する際に必要になることがよくあります。
ブランド力の確認
ニュースをスクレイピングしている間に、自社の(または特定の)ブランド力や評判を確認することもできます。多数のニュースに取り上げられている場合、無数の記事やニュースサイトにわざわざ目を通すことなく、最新情報を取得することができます。
また、製品やサービスの最低広告価格(MAP)をチェックするのにも役立ちます。厳密には価格スクレイピングの一種になりますが、ブランドの価格設定が顧客の期待に合致しているかどうかを判断するのに役立つ重要なインサイトになります。
不動産
アパートを探したり、家を購入したりする際には、通常数ある物件に目を通して選別しなければなりません。何千もの物件が複数の不動産サイトに掲載されているため、理想の物件を確実に見つけるのには時間がかかります。
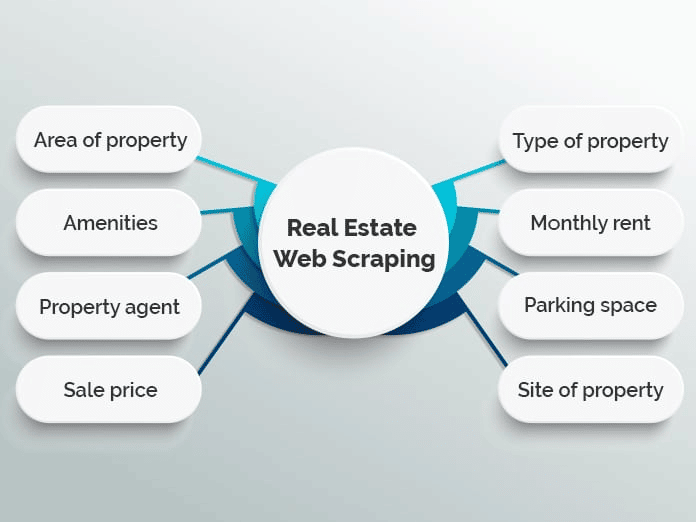
多くのサイトでは、単一のデータベースに不動産物件を集約し、このプロセスを簡素化するためにウェブスクレイピングを活用しています。米国の有名不動産サイトであるZillowやTruliaなど、このモデルを採用している企業は少なくありません。
不動産におけるウェブスクレイピングの用途はこれだけでなく、多くの不動産業者はスクレイピングアプリを使用して、平均家賃や販売価格、販売されている物件の種類などの貴重なトレンドを常に把握しています。
ウェブスクレイピングの仕組み
ウェブスクレイピングは一見複雑な技術かもしれませんが、実は非常にシンプルです。
方法やツールはさまざまですが、基本的には 1. ターゲットとなるサイトを自動的に閲覧し、2. データを抽出する方法を見つけるだけ。このステップは、スクレイパーとクローラーが実行してくれます。
スクレイパーとクローラー
わかりやすいよう、ウェブスクレイピングを馬と耕うん機に例えてみます。

馬が耕うん機を引くと、耕うん機が回転して土を砕いて柔らかく耕し、種を蒔く土壌を整えながら、不要な雑草や作物の残渣を再び土に戻します。
ウェブスクレイピングもこの仕組みに似ており、クローラーが馬、スクレイパーが耕うん機になります。
具体的には、それぞれ以下のような役割を持っています。
- クローラー (スパイダーとも):コンテンツを検索してインデックスを作成しながら、ウェブをブラウズする基本的なプログラム。スクレイパーを誘導する役割を持つが、それだけでなく、たとえばGoogleのような検索エンジンは、サイトのインデックスと検索順位を更新するためにクローラーを使用している。通常はツールとして提供されており、特定のサイトや検索語を指定できる。
- スクレイパー:サイトから関連情報を素早く抽出する。サイトはHTMLで構造化されているため、正規表現(regex)、XPath、CSSセレクタなどを使用して、特定のコンテンツを速やかに見つけて取得。ブランド名やキーワードを指定する正規表現を与えることができる。
ほとんどのウェブスクレイピングツールには、クローラーやスクレイパーが組み込まれており、操作は比較的簡単です。
基本的なウェブスクレイピングの流れ
ウェブスクレイピングは、簡単には以下のようなステップに集約されます。
- データを抽出したいサイトやページのURLを指定
- URLに対してHTMLリクエストを行う(つまりそのページにアクセスする)
- 正規表現などのロケータを使用して、HTMLから必要な情報を抽出
- CSVやJSONなどの形式で構造化データを保存
次のセクションで掘り下げますが、ウェブスクレイピングツールを使用すれば、上記のステップを自動化することができます。
ただし、すべての用途で自動化が可能であるとは限らず、特に大規模なウェブスクレイピングでは難しい場合があります。ウェブスクレイピングの最大の課題として、サイトがレイアウトを変更したり、スクレイピング防止策を講じたりするたびに、スクレイパーを更新し続けなければなりません(すべてのコンテンツがエバーグリーンであるとは限らない)。一度にいくつかのサイトをスクレイピングするだけであれば比較的シンプルですが、それ以上となるとすぐに複雑化します。
余計な手間を最小限に抑えるためには、サイトがどのようにスクレイパーをブロックしているかを理解することが重要です。
ウェブスクレイピングツール
多くのウェブスクレイピング機能は、ツールとして簡単に利用できます。多数の選択肢が存在しますが、品質、価格、そして倫理的な面で幅があります。
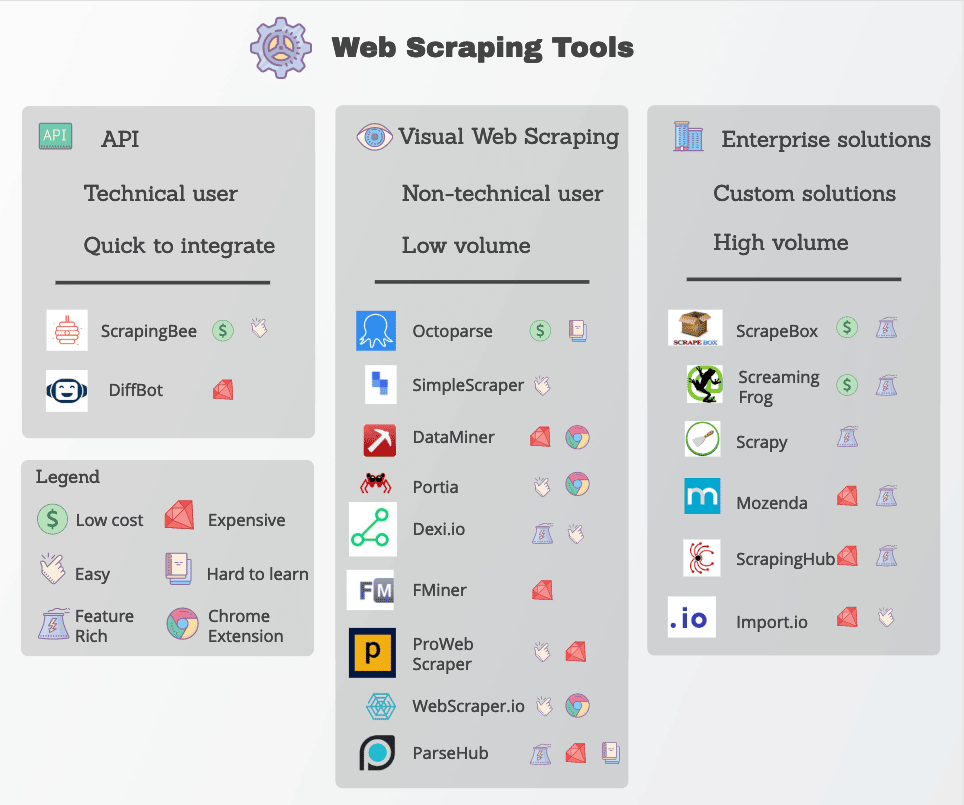
いずれにしても、優れたウェブスクレイピングツールを利用すれば、スクレイピング対策にあまり手を煩わせることなく、必要なデータを確実に抽出することができます。優れた選択肢の条件として、以下のような機能が挙げられます。
- 正確なロケータ:ウェブスクレイピングツールは、正規表現やCSSセレクタなどのロケータを使用して特定どのデータを抽出するため、必要なデータを複数のオプションで正確に指定できるものが好ましい。
- データの質:ウェブデータのほとんどは構造化されておらず、扱うのが面倒なだけでなく、良い結果をもたらしてくれることもほぼない。配信前に生データをクレンジングし、整理してくれるツールが好ましい。
- データ配信:採用するツールやワークフローによっては、JSON、XML、CSVなどの特定の形式でデータがほしいことも。生データを自分で変換する手間を省くため、必要な形式のデータ配信機能を持つツールを選ぶこと。
- スクレイピング対策:ウェブスクレイピングには、ブロックを迂回する能力が必須。サイトのブロックを解除するには、プロキシやVPNなどのツールが別途必要になる可能性はあるが、優れたツールであれば、通常クローラーにちょっとした変更を加えるだけでOK。
- 透明な価格設定:無料で使用できるものもあるが、堅牢な機能を利用するには投資が必要になる。特に規模を広げて多くのサイトをスクレイピングする予定の場合、価格設定を念入りに確認すること。
- カスタマーサポート:ツールで作業を自動化しても、時には問題に直面することも。これを考慮し、ツールの提供元が優れたサポートやトラブルシューティングリソースを提供しているかどうかを確認すること。
人気のウェブスクレイピングツールには、Octoparse、Import.io、Parsehubなどがあります。
ウェブスクレイピングからサイトを保護する
ここで視点を変えてみます。逆にウェブスクレイピングからサイトを保護したい場合には、どのような対策があるかを見ていきましょう。
基本的なセキュリティプラグイン以外にも、ウェブスクレイピングツールやクローラーをブロックする効果的な方法がいくつかあります。
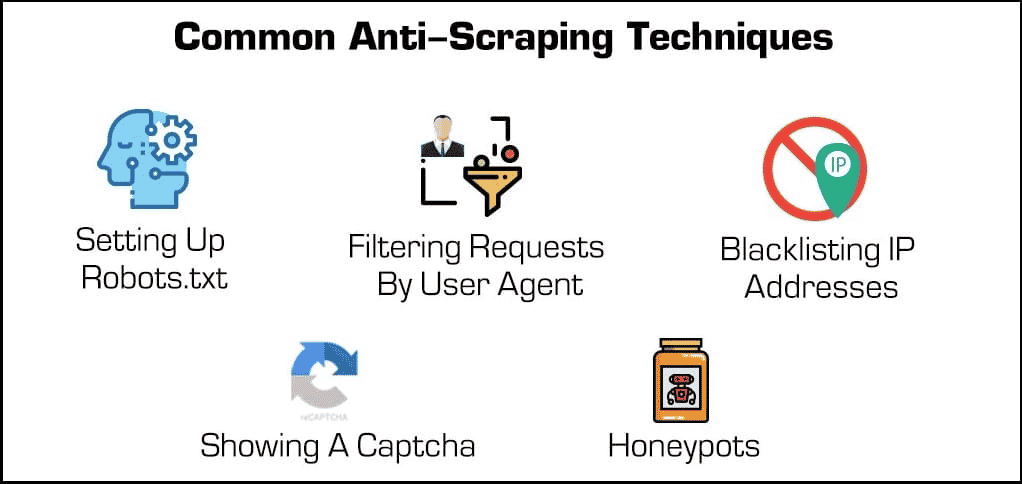
- IPアドレスのブロック:多くのウェブサーバーは、訪問者のIPアドレスを追跡しており、ある特定の訪問者が大量のサーバーリクエストを生成していることを検出すると(ウェブスクレイピングツールやボットなど)、IPが完全にブロックすることがある。しかし、ウェブスクレイピングツールは、プロキシやVPNを通じてIPアドレスを変更することで、この対策を突破できてしまう。
- robots.txtの設定:robots.txtファイルを使って、ウェブスクレイピングツール、クローラーなどのアクセスを許可しない設定を加えることができる。例えば、robots.txtファイルで検索エンジンにインデックスされないように指定しているサイトもあります。多くの検索エンジンはこのファイルを尊重しますが、悪意のあるウェブスクレイピングツールには無視されてしまう。
- リクエストのフィルタリング:サイトに訪問する際には、ウェブサーバーにHTMLページを「リクエスト」している。これらのリクエストは通常ウェブサーバーで確認することができ、IPアドレスやブラウザなどのユーザーエージェントなど、特定の識別要素をチェックできる。IPアドレスのブロックについては先に触れた通り、ユーザーエージェントによってフィルタリングすることも可能。
例えば、同じユーザーから古いバージョンのMozilla Firefoxを使ったリクエストが多いことを検出すると、そのバージョンをブロックすることで、ボットをブロックすることができます。このような対策は、ほとんどのマネージドサーバープランで提供されています。
- Captchaの表示:ページにアクセスする際、歪んだ文字列を入力したり、複数の画像から該当するものを選択したりした経験は、おそらく多くの人があるはず。これは、Captcha(Completely Automated Public Turing test to tell Computers and Humans Apart)と呼ばれ、ウェブスクレイピングツールやボットをフィルタリングするのに非常に効果がある。
- ハニーポット:悪意のあるユーザーをおびき寄せて、特定するための罠の一種。ウェブスクレイピングの場合、ウェブページに目に見えないリンクを忍ばせるのが一般的。ユーザーは気がつくことはなくても、ボットはスクロールしながら自動的にリンクを訪れるため、ウェブホストがそのIPアドレスやユーザーエージェントを収集(およびブロック)することができる。
では、ウェブスクレイピングツールはこれらの対策にどのように対処しているのでしょうか。
いくつかの対策は迂回が難しい一方で、効果的な対処方法もいくつかあります。例えば、スクレイパーの識別機能を何らかの方法で変更すること。
- プロキシまたはVPNを使用する─多くのウェブホストがIPアドレスに基づいてウェブスクレイピングツールをブロックしているため、多くの場合、これを突破するためにさまざまなIPアドレスを使用する必要がある。これには、プロキシや仮想プライベートネットワーク(VPN)が有用(プロキシとVPNの違いはこちら)。
- 定期的にターゲットを訪問する─ほとんどのウェブスクレイピングツールは、ブロックされたことを通知してくれないため、定期的にウェブスクレイピングを行うサイトやページを訪れ、ブロックされていないか、またはサイトの形式が変更されていないかを確認することが重要です(いずれ少なくともどちらかがほぼ確実に起こる)。
もちろん、責任を持ってウェブスクレイピングを行うのであれば、このような対策はどれも不要です。ウェブスクレイピングを行う際には、スクレイピング先のサイトを尊重し、ルールやマナーを守ることをお忘れなく。
まとめ
ウェブスクレイピングは強力な技術ですが、それと同時にサイト運営者にとっては脅威にもなり得ます。両方の立場を考慮し、ウェブスクレイピングはルールを守り、良い目的で利用することが大切です。
効果的にウェブスクレイピングからサイトを保護するなら、KinstaのマネージドWordPress専用ホスティングをお試しください。ボットを制限し、貴重なデータとリソースを保護するツールが多数揃っています。
見本紹介セッションをご予約いただくか、営業担当までお気軽にお問い合わせください。


