
Heb je ooit prijzen van meerdere sites tegelijk willen vergelijken? Of misschien automatisch een verzameling berichten uit je favoriete blog halen? Het is allemaal mogelijk met webscraping.
Webscraping is het proces waarbij content en gegevens van websites worden gehaald met behulp van software. De meeste prijsvergelijkingsdiensten gebruiken bijvoorbeeld webscrapers om prijsinformatie van verschillende online winkels te lezen. Een ander voorbeeld is Google, dat routinematig het web “af scrapet” of “crawlt” om websites te indexeren.
Natuurlijk zijn dit slechts twee van de vele use cases van webscraping. In dit artikel kijken we in meer details naar de wereld van webscrapers, leren we hoe ze werken, en zien we hoe sommige websites ze proberen te blokkeren. Lees verder voor meer informatie en begin met scrapen!
Wat is webscraping?
Webscraping is een verzameling praktijken die gebruikt worden om automatisch gegevens van het web te halen — of te “scrapen”.
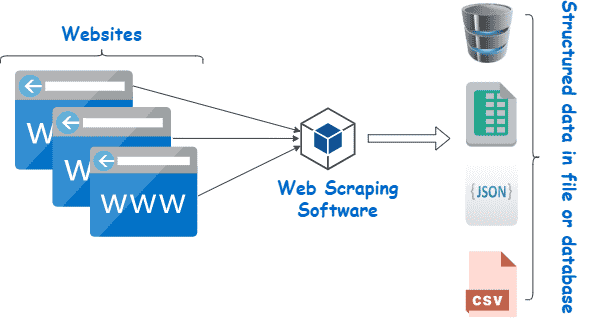
Andere termen voor webscraping zijn “contentscraping” of “datascraping.” Hoe het ook genoemd wordt, webscraping is een uiterst nuttige tool voor het verzamelen van online gegevens. Toepassingen van webscraping zijn marktonderzoek, prijsvergelijkingen, contentmonitoring en meer.
Maar wat “scrapet” webscraping precies — en hoe is het mogelijk? Is het wel legaal? Zou een website niet willen dat iemand zijn gegevens komt scrapen?
De antwoorden hangen af van verschillende factoren. Maar voordat we in methoden en use cases duiken, laten we eerst eens nader bekijken wat webscraping is en of het ethisch verantwoord is of niet.
Wat kunnen we “scrapen” van het web?
Het is mogelijk om allerlei soorten webgegevens te scrapen. Van zoekmachines en RSS feeds tot overheidsinformatie, de meeste websites maken hun gegevens openbaar beschikbaar voor scrapers, crawlers en andere vormen van geautomatiseerde gegevensverzameling.
Hier zijn enkele veel voorkomende voorbeelden.
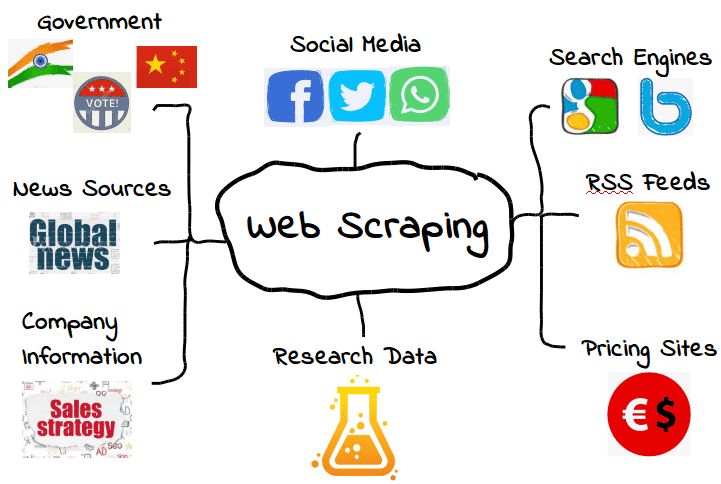
Dat betekent echter niet dat deze gegevens altijd beschikbaar zijn. Afhankelijk van de website moet je misschien een paar tools en trucs gebruiken om precies te krijgen wat je nodig hebt — er vanuit gaande dat de gegevens überhaupt toegankelijk zijn. Veel webscrapers kunnen bijvoorbeeld geen zinvolle gegevens uit visuele content halen.
In de eenvoudigste gevallen kan webscraping gebeuren via de API of application programming interface van een website . Als een website zijn API beschikbaar stelt, kunnen webontwikkelaars die gebruiken om automatisch gegevens en andere nuttige informatie in een handig format te extraheren. Het is bijna alsof de webhost je voorziet van je eigen “pijplijn” naar hun gegevens. Over gastvrijheid gesproken!
Natuurlijk is dat niet altijd het geval — en veel websites die je wilt scrapen hebben geen API die je kunt gebruiken. Bovendien zullen zelfs websites die wel een API hebben je niet altijd gegevens in het juiste format leveren.
Daarom is webscraping alleen nodig als de webgegevens die je wilt hebben niet beschikbaar zijn in de vorm(en) die je nodig hebt. Of dat nu betekent dat de formats die je wilt niet beschikbaar zijn, of dat de website gewoon niet alle gegevens levert, met webscraping kun je krijgen wat je wilt.
Hoewel dat allemaal geweldig is, roept het ook een belangrijke vraag op: Als bepaalde webgegevens beperkt zijn, is het dan legaal om ze te scrapen? Zoals we straks zullen zien, kan het een beetje een grijs gebied zijn.
Is webscraping legaal?
Voor sommige mensen kan het idee van webscraping bijna aanvoelen als stelen. Immers, wie ben jij om zomaar andermans gegevens te “pakken”?
Gelukkig is er niets inherent illegaals aan webscraping. Als een website gegevens publiceert, zijn die meestal beschikbaar voor het publiek en dus vrij om te scrapen.
Omdat Amazon bijvoorbeeld productprijzen openbaar maakt, is het volkomen legaal om prijsgegevens te scrapen. Veel populaire shoppingapps en browserextensies gebruiken webscraping precies voor dit doel, zodat gebruikers weten dat ze de juiste prijs krijgen.
Maar niet alle webgegevens zijn gemaakt voor het publiek, wat betekent dat niet alle webgegevens legaal zijn om te scrapen. Als het gaat om persoonlijke gegevens en intellectueel eigendom, kan webscraping snel veranderen in kwaadaardig webscraping, met boetes als een DMCA takedown notice tot gevolg.
Wat is kwaadaardig webscraping?
Kwaardaardig webscraping is het scrapen van gegevens die de uitgever niet wilde delen of waarvoor hij geen toestemming had gegeven. Hoewel deze gegevens meestal persoonlijke gegevens of intellectueel eigendom zijn, kan kwaadwillig scrapen van toepassing zijn op alles wat niet bedoeld is voor het publiek.
Zoals je je kunt voorstellen heeft deze definitie een grijs gebied. Terwijl veel soorten persoonsgegevens worden beschermd door wetten als de General Data Protection Regulation (GDPR) en de California Consumer Privacy Act (CCPA), zijn andere dat niet. Maar dat betekent niet dat er geen situaties zijn waarin ze niet legaal te scrapen zijn.

Stel bijvoorbeeld dat een webhost “per ongeluk” zijn gebruikersinformatie openbaar maakt. Dat zou een complete lijst van namen, e-mails en andere informatie kunnen bevatten die technisch gezien openbaar is, maar misschien niet bedoeld om gedeeld te worden.
Hoewel het technisch ook legaal zou zijn om deze gegevens te scrapen, is het waarschijnlijk niet het beste idee. Het feit dat gegevens openbaar zijn, betekent niet noodzakelijkerwijs dat de webhost toestemming heeft gegeven om ze te scrapen, zelfs als het gebrek aan toezicht ze openbaar heeft gemaakt.
Dit “grijze gebied” heeft webscraping een enigszins gemengde reputatie gegeven. Hoewel webscraping zeker legaal is, kan het gemakkelijk gebruikt worden voor kwaadaardige of onethische doeleinden. Daarom stellen veel webhosts het niet op prijs dat hun gegevens worden gescrapet — ongeacht of het legaal is.
Een andere vorm van kwaadaardige webscraping is “over-scraping,” waarbij scrapers in een bepaalde periode te veel verzoeken sturen. Te veel verzoeken kunnen een enorme druk leggen op webhosts, die veel liever serverresources besteden aan echte mensen dan aan scrapingbots.
Als algemene regel geldt: gebruik webscraping spaarzaam en alleen als je helemaal zeker weet dat de gegevens bedoeld zijn voor openbaar gebruik. Vergeet niet dat het feit dat gegevens publiekelijk beschikbaar zijn niet betekent dat het legaal of ethisch is om ze te scrapen.
Waarvoor wordt webscraping gebruikt?
Op zijn best dient webscraping vele nuttige doelen in vele bedrijfstakken. Vanaf 2021 wordt bijna de helft van alle webscraping gebruikt om e-commerce strategieën te ondersteunen.
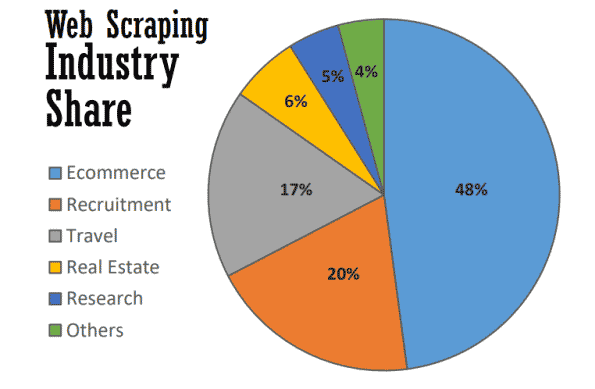
Webscraping is de ruggengraat geworden van veel datagedreven processen, van het volgen van merken en het bieden van actuele prijsvergelijkingen tot het uitvoeren van waardevol marktonderzoek. Hier zijn enkele van de meest voorkomende.
Marktonderzoek
Wat doen je klanten? Hoe zit het met je leads? Hoe zijn de prijzen van je concurrenten vergeleken met die van jou? Heb je genoeg informatie om een succesvolle inboundmarketing of contentmarketingcampagne op te zetten?
Dit zijn maar een paar van de vragen die de hoekstenen vormen van marktonderzoek — en precies dezelfde die beantwoord kunnen worden met webscraping. Omdat veel van deze gegevens openbaar beschikbaar zijn, is webscraping een tool van onschatbare waarde geworden voor marketingteams die hun markt in de gaten willen houden zonder tijdrovend handmatig onderzoek te hoeven doen.
Bedrijfsautomatisering
Veel van de voordelen van webscraping voor marktonderzoek gelden ook voor bedrijfsautomatisering.
Waar veel bedrijfsautomatiseringstaken het verzamelen en verwerken van grote hoeveelheden gegevens vereisen, kan webscraping van onschatbare waarde zijn — vooral als dit anders omslachtig zou zijn.
Stel bijvoorbeeld dat je gegevens moet verzamelen van tien verschillende websites. Zelfs als je van elke website hetzelfde type gegevens verzamelt, kan elke website een andere extractiemethode vereisen. In plaats van handmatig verschillende interne processen op elke website te doorlopen, kun je een webscraper gebruiken om dit automatisch te doen.
Leads genereren
Alsof marktonderzoek en bedrijfsautomatisering nog niet genoeg waren, kan webscraping ook met weinig moeite waardevolle lijsten met leads genereren.
Hoewel je je doelen met enige precisie moet stellen, kun je met webscraping voldoende gebruikersgegevens genereren om gestructureerde leadlijsten te maken. De resultaten kunnen natuurlijk variëren, maar het is handiger (en veelbelovender) dan zelf leadlijsten samenstellen.
Bijhouden van prijzen
Het extraheren van prijzen — ook wel pricescraping genoemd — is een van de meest voorkomende toepassingen voor webscraping.
Hier is een voorbeeld van de populaire Amazon price-trackingapp Camelcamelcamel. De app scrapet regelmatig productprijzen en vergelijkt ze dan op een grafiek in de tijd.
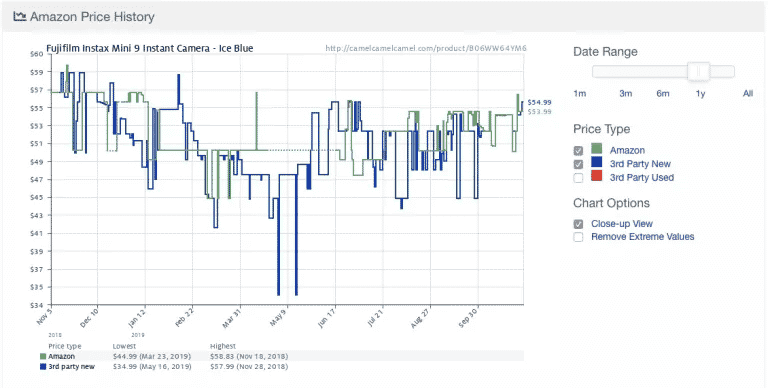
Prijzen kunnen enorm fluctueren, zelfs dagelijks (kijk naar de plotselinge prijsdaling rond 9 mei!). Met toegang tot historische prijstrends kunnen gebruikers nagaan of de prijs die ze betalen ideaal is. In dit voorbeeld zou de gebruiker ervoor kunnen kiezen een week of zo te wachten in de hoop $10 te besparen.
Ondanks het nut komt pricescraping met enige controverse. Omdat veel mensen real-time prijsupdates willen, worden sommige prijstrackingapps al snel kwaadaardig door bepaalde websites te overbelasten met serververzoeken.
Als gevolg daarvan zijn veel e-commercewebsites extra maatregelen gaan nemen om webscrapers helemaal te blokkeren, wat we in de volgende paragraaf zullen behandelen.
Nieuws en content
Niets is waardevoller dan op de hoogte blijven. Van het monitoren van reputaties tot het volgen van trends in de sector, webscraping is een waardevolle tool om op de hoogte te blijven.
Hoewel sommige nieuwswebsites en blogs al RSS feeds en andere gemakkelijke interfaces bieden, zijn ze niet altijd de norm — en ook niet zo gebruikelijk als vroeger. Om precies het nieuws en de content te verzamelen die je nodig hebt, is vaak een vorm van webscraping nodig.
Merkmonitoring
Als je dan toch het nieuws scrapet, waarom check je dan niet meteen je merk? Voor merken die veel in het nieuws komen is webscraping een tool van onschatbare waarde om op de hoogte te blijven zonder talloze artikelen en nieuwssites te hoeven doorspitten.
Webscraping is ook nuttig om de minimum available price (MAP) van een product of dienst van een merk te checken. Hoewel dit technisch gezien een vorm van pricescraping is, is het een belangrijk inzicht dat merken kan helpen bepalen of hun prijsstelling in overeenstemming is met de verwachtingen van de klant.
Vastgoed
Als je ooit naar een appartement hebt gezocht of een huis hebt gekocht, weet je hoeveel er te regelen valt. Met duizenden aanbiedingen verspreid over meerdere vastgoedwebsites kan het moeilijk zijn om precies te vinden wat je zoekt.
Veel websites gebruiken webscraping om vastgoedadvertenties samen te voegen in een enkele database om het proces gemakkelijker te maken. Populaire voorbeelden zijn Zillow en Trulia, hoewel er vele andere zijn die een soortgelijk model volgen.
Het samenvoegen van lijsten is echter niet het enige gebruik van webscraping in de vastgoedsector. Makelaars kunnen bijvoorbeeld scrapingapplicaties gebruiken om op de hoogte te blijven van gemiddelde huur- en verkoopprijzen, soorten woningen die worden verkocht en andere waardevolle trends.
Hoe werkt webscraping?
Webscraping klinkt misschien ingewikkeld, maar het is eigenlijk heel eenvoudig.
Hoewel de methoden en tools kunnen variëren, hoef je alleen maar een manier te vinden om (1) automatisch door je doelwebsite(s) te browsen en (2) de gegevens eruit te halen als je er eenmaal bent. Meestal worden deze stappen uitgevoerd met scrapers en crawlers.
Scrapers en crawlers
In principe werkt webscraping bijna hetzelfde als paard en ploeg.

Terwijl het paard de ploeg leidt, woelt en breekt de ploeg de aarde en helpt zo plaats te maken voor nieuw zaad, terwijl ongewenst onkruid en gewasresten weer in de grond worden gewerkt.
Afgezien van het paard is het scrapen van het web niet veel anders. Hier speelt een crawler de rol van het paard en leidt de scraper — in feite onze ploeg — door onze digitale velden.
Dit is wat beiden doen.
- Crawlers (soms ook wel spiders genoemd) zijn basisprogramma’s die het web afspeuren en content zoeken en indexeren. Hoewel crawlers webscrapers begeleiden, worden ze niet uitsluitend voor dit doel gebruikt. Zoekmachines als Google gebruiken bijvoorbeeld crawlers om de indexen en ranglijsten van websites bij te werken. Crawlers zijn meestal beschikbaar als vooraf gebouwde tools waarmee je een bepaalde website of zoekterm kunt specificeren.
- Scrapers doen het vuile werk om snel relevante informatie van websites te halen. Omdat websites gestructureerd zijn in HTML, gebruiken scrapers regular expressions (regex), XPath, CSS selectors en andere locators om snel bepaalde content te vinden en te extraheren. Je kunt je webscraper bijvoorbeeld een regular expression geven die een merknaam of trefwoord specificeert.
Als je nu geen idee hebt waar we het over hebben, maak je dan geen zorgen. De meeste webscrapingtools bevatten ingebouwde crawlers en scrapers, waardoor je zelfs de meest ingewikkelde klussen gemakkelijk kunt uitvoeren.
Basisprocedure voor webscraping
Op het meest basale niveau komt webscraping neer op een paar eenvoudige stappen:
- Specificeer URL’s van websites en pagina’s die je wilt scrapen
- Doe een HTML verzoek naar de URL’s (d.w.z. “bezoek” de pagina’s)
- Gebruik locators zoals regular expressions om de gewenste informatie uit de HTML te halen
- Sla de gegevens op in een gestructureerd format (zoals CSV of JSON)
Zoals we in de volgende paragraaf zullen zien, kan een groot aantal webscrapingtools gebruikt worden om deze stappen automatisch uit te voeren.
Het is echter niet altijd zo eenvoudig — vooral als je webscraping op grotere schaal uitvoert. Een van de grootste uitdagingen van webscraping is het bijhouden van je scraper als websites van layout veranderen of anti-scrapingmaatregelen nemen (niet alles kan evergreen zijn). Hoewel dat niet al te moeilijk is als je maar een paar websites tegelijk scrapet, kan het scrapen van meer websites al snel een gedoe worden.
Om het extra werk tot een minimum te beperken, is het belangrijk te begrijpen hoe websites scrapers proberen te blokkeren — iets wat we in de volgende paragraaf zullen leren.
Tools voor webscraping
Veel functies voor webscraping zijn beschikbaar in de vorm van webscrapingtools. Hoewel er veel tools beschikbaar zijn, variëren ze sterk in kwaliteit, prijs en (helaas) ethiek.
In elk geval zal een goede webscraper in staat zijn om betrouwbaar de gegevens te extraheren die je nodig hebt, zonder tegen al te veel anti-scrapingmaatregelen aan te lopen. Hier zijn enkele belangrijke features waar je op moet letten.
- Precieze locators: Webscrapers gebruiken locators zoals regular expressions en CSS selectors om specifieke gegevens te extraheren. De tool die je kiest moet je verschillende opties geven om aan te geven wat je zoekt.
- Kwaliteit van de gegevens: De meeste webgegevens zijn ongestructureerd – zelfs als ze voor het menselijk oog duidelijk worden gepresenteerd. Werken met ongestructureerde gegevens is niet alleen rommelig, maar levert ook zelden goede resultaten op. Zorg ervoor dat je zoekt naar scrapingtools die ruwe gegevens opschonen en sorteren voordat ze worden aangeleverd.
- Levering van gegevens: Afhankelijk van je bestaande tools of workflows heb je waarschijnlijk gescrapete gegevens nodig in een specifiek format zoals JSON, XML of CSV. In plaats van de ruwe gegevens zelf te converteren, zoek je naar tools met opties voor het aanleveren van gegevens in de formats die je nodig hebt.
- Anti-scrapingbehandeling: Webscraping is slechts zo effectief als het vermogen om blokkades te omzeilen. Hoewel je misschien extra tools zoals proxies en VPN’s moet gebruiken om websites te deblokkeren, doen veel webscrapingtools dit door kleine aanpassingen aan hun crawlers.
- Transparante prijzen: Hoewel sommige webscrapingtools gratis te gebruiken zijn, hebben robuustere opties een prijs. Let goed op de prijzen, vooral als je van plan bent op te schalen en veel sites te scrapen.
- Klantenondersteuning: Hoewel het gebruik van een kant-en-klare tool uiterst handig is, zul je niet altijd in staat zijn om zelf problemen op te lossen. Zorg er daarom voor dat je provider ook betrouwbare klantenondersteuning en troubleshootingresources biedt.
Populaire webscrapingtools zijn Octoparse, Import.io, en Parsehub.
Bescherming tegen webscraping
Laten we de rollen een beetje omdraaien: Stel dat jij een webhost bent, maar niet wilt dat andere mensen al deze slimme methoden gebruiken om je gegevens te scrapen. Wat kun je doen om jezelf te beschermen?
Naast eenvoudige beveiligingsplugins zijn er een paar effectieve methoden om webscrapers en crawlers te blokkeren.
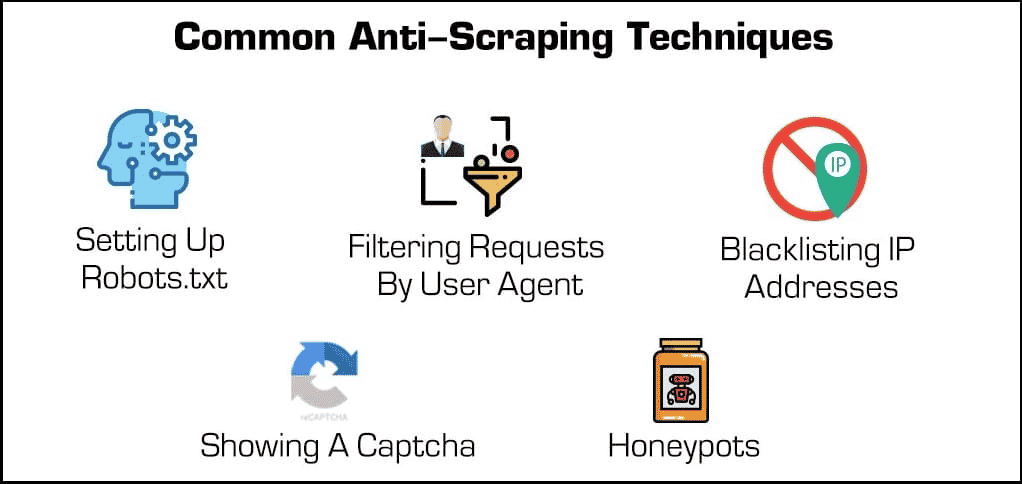
- Blokkeren van IP-adressen: Veel webhosts houden de IP-adressen van hun bezoekers bij. Als een host merkt dat een bepaalde bezoeker veel serververzoeken genereert (zoals in het geval van sommige webscrapers of bots), dan kan hij het IP adres volledig blokkeren. Scrapers kunnen deze blokkades echter omzeilen door hun IP adres te veranderen via een proxy of VPN.
- Robots.txt instellen: Met een robots.txt bestand kan een webhost scrapers, crawlers en andere bots vertellen waar ze wel en niet bij kunnen. Sommige websites gebruiken bijvoorbeeld een robots.txt bestand om privé te blijven door zoekmachines te vertellen dat ze ze niet mogen indexeren. Hoewel de meeste zoekmachines deze bestanden respecteren, doen veel kwaadaardige vormen van webscrapers dat niet.
- Verzoeken filteren: Wanneer iemand een website bezoekt, “vraagt” hij een HTML pagina aan de webserver. Deze verzoeken zijn vaak zichtbaar voor webhosts, die bepaalde identificatiefactoren zoals IP-adressen en user agents zoals webbrowsers kunnen zien. Hoewel we het blokkeren van IP’s al hebben behandeld, kunnen webhosts ook filteren op user agent.
Als een webhost bijvoorbeeld merkt dat dezelfde gebruiker veel aanvragen doet met een verouderde versie van Mozilla Firefox, dan kan hij die versie blokkeren en daarmee de bot blokkeren. Deze blokkeringsmogelijkheden zijn beschikbaar in de meeste managed hostingabonnementen.
- Het tonen van een Captcha: Heb je ooit een vreemde reeks tekst moeten typen of op minstens zes zeilboten moeten klikken voordat je toegang kreeg tot een pagina? Dan ben je een “Captcha” of completely automated public Turing test for telling computers and humans apart. Hoewel ze misschien eenvoudig zijn, zijn ze ongelooflijk effectief in het uitfilteren van webscrapers en andere bots.
- Honeypots: Een “honeypot” is een soort val die gebruikt wordt om ongewenste bezoekers aan te trekken en te identificeren. In het geval van webscrapers kan een webhost onzichtbare links op zijn webpagina zetten. Hoewel menselijke gebruikers dit niet opmerken, zullen bots deze automatisch bezoeken als ze doorlopen, waardoor webhosts hun IP-adressen of user agents kunnen verzamelen (en blokkeren).
Laten we nu de rollen weer omdraaien. Wat kan een scraper doen om deze beveiligingen te omzeilen?
Hoewel sommige anti-scrapingmaatregelen moeilijk te omzeilen zijn, zijn er een paar methoden die vaak werken. Deze houden in dat je de identificatiefeatures van je scraper op de een of andere manier verandert.
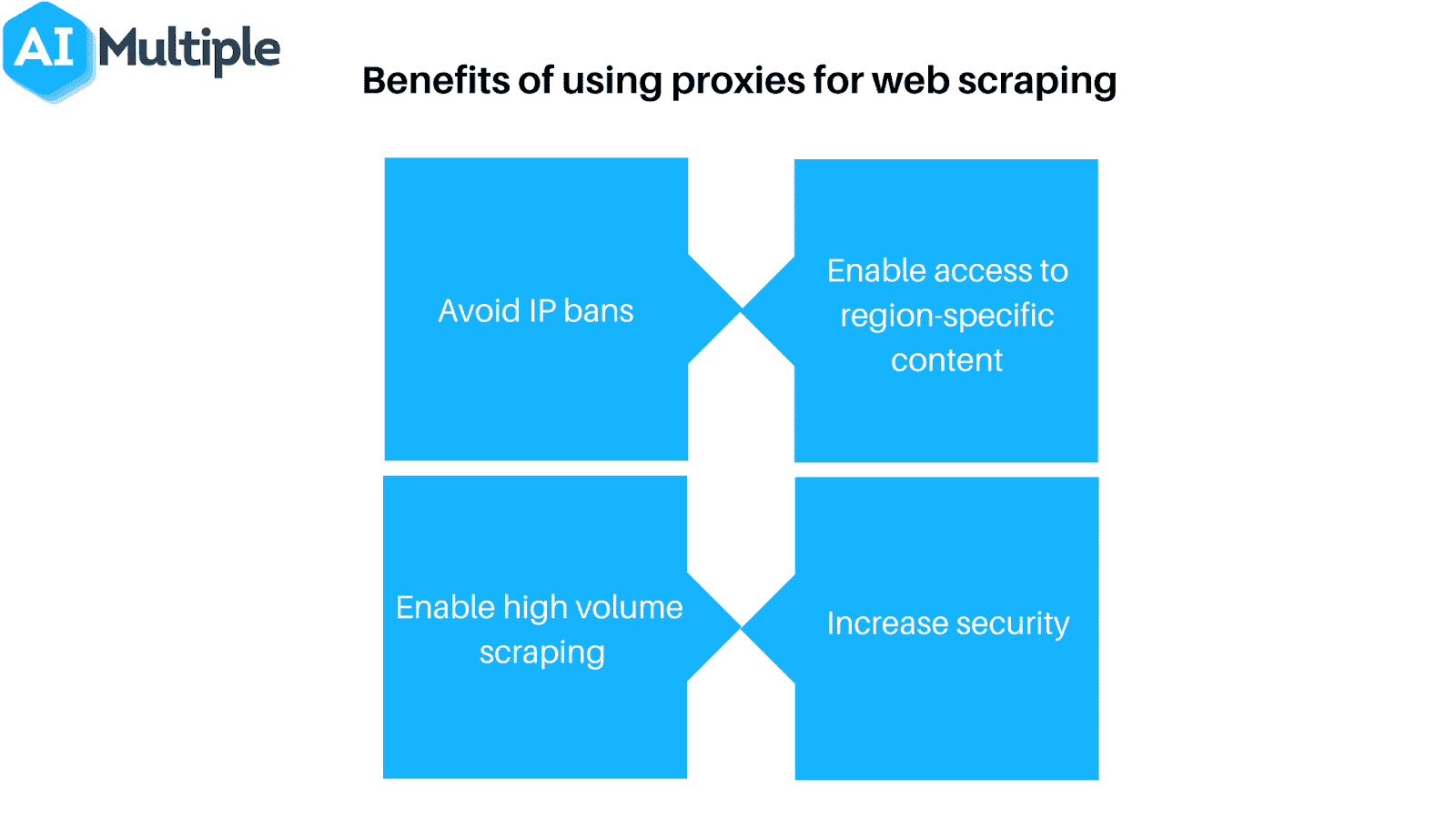
- Gebruik een proxy of VPN: Omdat veel webhosts webscrapers blokkeren op basis van hun IP adres, is het vaak nodig om verschillende IP adressen te gebruiken om toegang te garanderen. Proxy’s en Virtual Private Networks (VPN’s) zijn ideaal voor deze taak, hoewel ze een paar belangrijke verschillen hebben.
- Bezoek je doelgebieden regelmatig: De meeste (eventuele) webscrapers zullen je vertellen wanneer ze geblokkeerd zijn. Daarom is het belangrijk om regelmatig te controleren waar je vandaan schraapt om te zien of je geblokkeerd bent of dat de opmaak van de website veranderd is. Weet dat het vrijwel zeker is dat je op den duur tegen een ervan aanloopt.
Natuurlijk is geen van deze maatregelen nodig als je webscraping verantwoord gebruikt. Als je besluit om webscraping toe te passen, vergeet dan niet spaarzaam te scrapen en respecteer je webhosts!
Samenvatting
Hoewel webscraping een krachtige tool is, vormt het ook een flinke bedreiging voor veel webhosts. Aan welke kant van de server je ook staat, iedereen heeft er belang bij ervoor te zorgen dat webscraping verantwoord wordt gebruikt en natuurlijk voor het goede doel.
Als je als webhost op zoek bent naar controle over webscrapers, kijk dan niet verder dan Kinsta’s plannen voor managed WordPress hosting. Je kunt bots beperken en waardevolle gegevens en resources beschermen met de vele beschikbare tools voor toegangscontrole.
Plan voor meer informatie een gratis demo in of neem vandaag nog contact op met een webhostingexpert van Kinsta.


