
Mehr Traffic sollte eigentlich mehr Erfolg bedeuten, aber in der Praxis ist das oft nicht der Fall. Viele Websites verzeichnen steigende Besucherzahlen, während Conversions, Interaktion und Umsatz stagnieren – und die Teams fragen sich, warum sich dieses „Wachstum“ überhaupt nicht auf den Umsatz übertragt.
Ein Grund dafür ist, dass nicht der gesamte Traffic von echten Menschen stammt. Automatisierte Aktivitäten machen mittlerweile einen großen Teil des modernen Webs aus. Tatsächlich ergab der „2025 Imperva Bad Bot Report“, dass automatisierte Systeme im Jahr 2024 51 % des gesamten Web-Traffics ausmachten – das bedeutet, dass Bots zum ersten Mal seit einem Jahrzehnt insgesamt mehr Anfragen generierten als menschliche Besucher.
Wenn sich automatisierter Traffic in die Analyseberichte mischt, werden reine Besucherzahlen allein zu einem unzuverlässigen Maßstab für das tatsächliche Interesse oder die Nachfrage der Zielgruppe.
Dieser Artikel erklärt, wie du zwischen echten Website-Besuchern, nützlicher Automatisierung und schädlicher Bot-Aktivität unterscheiden kannst.
Was Bot-Traffic eigentlich ist
Bot-Traffic bezieht sich auf Anfragen, die von automatisierter Software statt von einem Menschen über einen Browser gestellt werden. Diese Programme senden Anfragen an Webseiten, Bilder, Skripte oder APIs genauso wie der Browser eines Besuchers, aber die Aktivität findet ohne direkte menschliche Interaktion statt.
Aus technischer Sicht sieht der Server oft denselben Anfragetyp. Der Unterschied liegt darin, wie die Anfrage generiert wird und wie sie sich im Laufe der Zeit verhält.
Automatisierung ist weder ungewöhnlich noch von Natur aus schädlich. Ein Großteil des Internets hängt von automatisierten Systemen ab, die kontinuierlich Websites crawlen, die Verfügbarkeit prüfen, die Leistung validieren oder Daten für legitime Dienste abrufen. Suchmaschinen nutzen Bots, um neue Inhalte zu entdecken und zu indexieren, Monitoring-Tools testen regelmäßig die Verfügbarkeit, und verschiedene Integrationen fragen APIs ab, um Anwendungen synchron zu halten.
Wichtig ist, dass das Wort „Bot“ beschreibt, wie der Traffic generiert wird, nicht warum er existiert. Einige automatisierte Systeme unterstützen Transparenz und Sicherheit, während andere versuchen, Schwachstellen auszunutzen, Inhalte zu scrapen oder die Infrastruktur zu überlasten. Da die Absichten sehr unterschiedlich sind, ist es weitaus sinnvoller, das Verhalten von Bots zu identifizieren und zu klassifizieren, als den gesamten automatisierten Traffic als eine einzige Kategorie zu behandeln.
Die drei Arten von Traffic auf deiner Website
Website-Traffic wird oft als einfache Unterteilung in „menschlich“ und „Bot“ diskutiert, aber in Wirklichkeit lassen sich die meisten Anfragen in drei praktische Kategorien einteilen: echte Besucher, hilfreiche Bots und schädliche Bots. Wenn du diesen Unterschied verstehst, fällt es dir leichter, Analysen zu interpretieren, Ressourcen zu verwalten und die richtigen Sicherheitsmaßnahmen anzuwenden, ohne legitime Aktivitäten zu stören.
Wie bereits erwähnt, stellte der Imperva Bad Bot Report fest, dass automatisierter Traffic weltweit mehr als die Hälfte aller Webanfragen ausmachte, wobei ein erheblicher Teil entweder als nützliche Automatisierung oder als böswillige Bot-Aktivität eingestuft wurde. Wenn diese verschiedenen Quellen kombiniert werden, liefert das Traffic-Volumen allein kaum Aufschluss über die tatsächliche Nachfrage oder das Engagement der Nutzer.
Das Ziel ist nicht, alles zu blockieren, was automatisiert erscheint, sondern zu erkennen, welche Anfragen von echten Menschen stammen, welche die Funktionalität und Sichtbarkeit der Website unterstützen und welche Risiken oder unnötige Belastung verursachen.
Die Analyse von Verhaltensmustern, Anfrageeigenschaften und Traffic-Quellen kann dir die nötige Klarheit verschaffen, um nützliche Automatisierung zuzulassen, dich vor schädlichen Aktivitäten zu schützen und die Leistung anhand von Daten zu bewerten, die das echte Nutzerverhalten widerspiegeln.
Echte Besucher: So sieht menschlicher Traffic aus
Menschlicher Traffic folgt in der Regel unregelmäßigen, unvorhersehbaren Mustern. Echte Besucher bewegen sich auf unterschiedliche Weise durch Websites. Sie klicken auf verschiedene Navigationspfade, verweilen auf bestimmten Seiten, scrollen unterschiedlich tief und verbringen unterschiedlich lange Zeit auf einer Seite, bevor sie die nächste Aktion ausführen. Selbst wenn mehrere Besucher aus derselben Kampagne oder Region kommen, folgt ihr Verhalten selten identischen Abläufen.
Authentische Nutzersitzungen beinhalten auch realistische Interaktionsmuster. Aktionen wie Suchanfragen auf der Website, das Absenden von Formularen, die Wiedergabe von Medien, Kontoanmeldungen oder E-Commerce-Aktivitäten finden in der Regel in logischen Abläufen statt und nicht in perfekt getakteten oder sich wiederholenden Intervallen. Der zeitliche Abstand zwischen den Anfragen variiert auf natürliche Weise und spiegelt wider, wie Menschen lesen, denken und entscheiden, was sie als Nächstes tun.
Mit MyKinsta kannst du auf einen Blick schnell erkennen, welche Seiten den meisten Traffic erhalten:

Die Gerätevielfalt ist ein weiterer starker Indikator für echten Traffic. Echte Besucher nutzen eine breite Mischung aus Browsern, Betriebssystemen, Verbindungsgeschwindigkeiten und Bildschirmgrößen. Selbst bei geografisch konzentriertem Traffic gibt es Unterschiede zwischen den Geräten und Konfigurationen, was zu einer Verteilung führt, die selten einheitlich erscheint.
MyKinsta liefert auch Informationen zur Gerätenutzung:
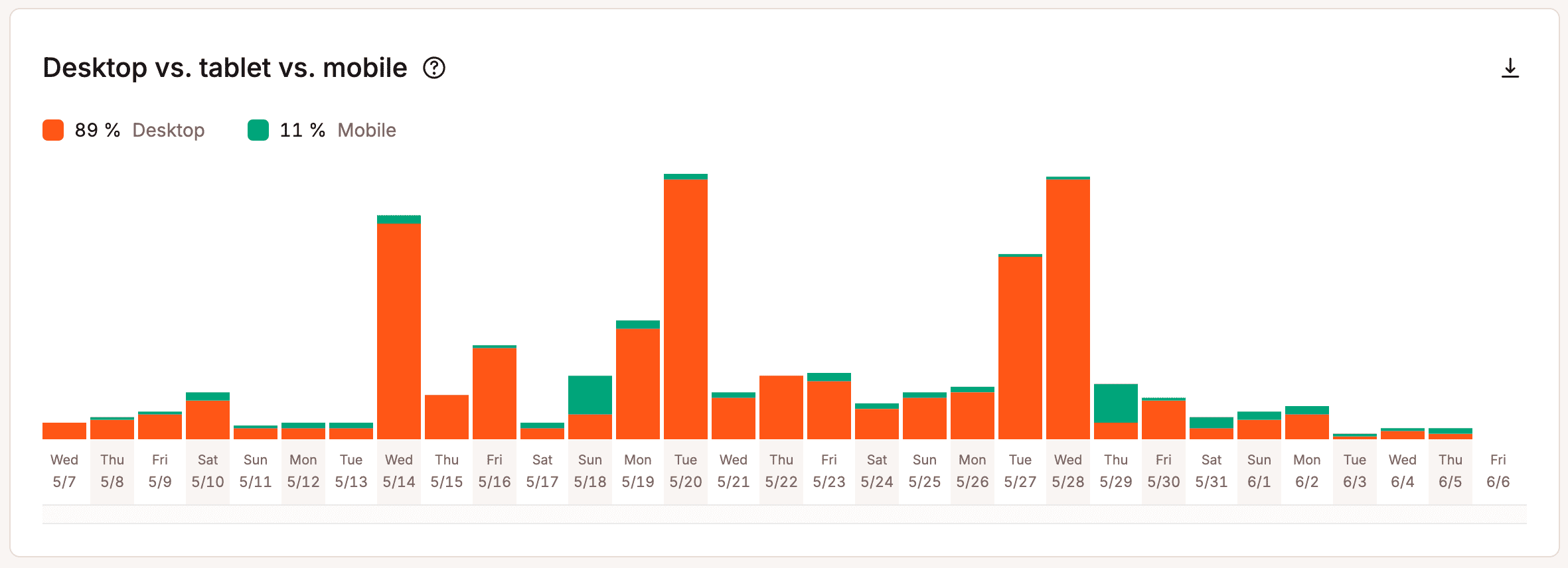
Gleichzeitig ist es nicht immer einfach, menschlichen Traffic zu identifizieren. Datenschutzmaßnahmen, Werbeblocker, Caching-Ebenen und gemeinsam genutzte Netzwerkumgebungen können bestimmte Signale verschleiern oder dazu führen, dass verschiedene Nutzer auf Infrastrukturebene ähnlich erscheinen.
Aus diesem Grund funktioniert die Traffic-Klassifizierung am besten, wenn mehrere Indikatoren – darunter die bereits erwähnten Verhaltensmuster, Sitzungsmerkmale, Gerätevielfalt und Interaktionssignale – gemeinsam ausgewertet werden, anstatt sich allein auf eine einzelne Metrik zu verlassen.
Nützliche Bots: Automatisierung, die deine Website unterstützt
Nicht jeder automatisierte Traffic ist etwas, das du unterbinden solltest. Viele Bots spielen eine wesentliche Rolle dabei, dass deine Website sichtbar bleibt, überwacht wird und korrekt funktioniert.
Suchmaschinen-Crawler
Dies ist eines der wichtigsten Beispiele. Diese Bots rufen systematisch Websites ab, um neue Inhalte zu entdecken, Änderungen zu bewerten und Suchindizes zu aktualisieren.
Ihr Verhalten ist in der Regel strukturiert und vorhersehbar: Sie folgen methodisch Links und halten sich an die in der robots.txt definierten Crawling-Richtlinien. Wenn du diesen Crawlern den Zugriff auf deine Website verweigerst, kann dies die Sichtbarkeit in Suchmaschinen verringern und verzögern, wie schnell neue Websites in den Ergebnissen erscheinen.
Verfügbarkeitsüberwachung und Testdienste
Andere legitime Automatisierungsmaßnahmen konzentrieren sich auf die Überwachung und den Betriebszustand. Tools zur Verfügbarkeitsüberwachung, Leistungsprüfungen und synthetische Testdienste senden in regelmäßigen Abständen Anfragen, um die Verfügbarkeit zu bestätigen, Ladezeiten zu messen und Fehler frühzeitig zu erkennen.
SEO- und Validierungstools
Ebenso scannen SEO-, Barrierefreiheits- und Validierungstools Websites, um technische Probleme, defekte Links oder Compliance-Bedenken zu identifizieren, die sonst unbemerkt bleiben könnten.
Nützliche Bots machen ihre Anwesenheit in der Regel deutlich. Sie identifizieren sich oft durch konsistente User-Agent-Strings, arbeiten innerhalb definierter Anforderungsgrenzen und halten sich an veröffentlichte Crawling-Richtlinien.
Da diese Systeme die Indizierung, Beobachtbarkeit und Integrationen unterstützen, kann ihre Blockierung ohne Überprüfung Überwachungsabläufe unterbrechen, die Auffindbarkeit verringern oder Dienste beeinträchtigen, die auf geplante automatisierte Anfragen angewiesen sind.
Schädliche Bots: Traffic, der Risiken oder Verschwendung verursacht
Schädliche Bots sind automatisierte Systeme, die darauf ausgelegt sind, Websites auszunutzen, Daten in großem Umfang zu extrahieren oder Infrastrukturressourcen zu verbrauchen, ohne einen legitimen Nutzen zu bieten. Im Gegensatz zu hilfreicher Automatisierung versuchen diese Bots in der Regel, ihre Identität zu verschleiern, Crawling-Regeln zu ignorieren und Anfragemuster zu generieren, die darauf abzielen, grundlegende Schutzmaßnahmen zu umgehen.
Credential-Stuffing- und Brute-Force-Bots
Diese gehören zu den häufigsten Bedrohungen. Diese Systeme greifen wiederholt auf Login-Endpunkte zu und testen in schneller Folge große Listen gestohlener Benutzernamen und Passwörter, um sich unbefugten Zugriff zu verschaffen. Selbst wenn sie keinen Erfolg haben, kann das Volumen der Anfragen die Serverlast erhöhen und die Antwortzeiten für legitime Nutzer verlangsamen.
Schwachstellenscanner und Scraper
Andere bösartige Automatisierungen konzentrieren sich auf das Aufspüren und Ausnutzen von Schwachstellen. Schwachstellenscanner durchsuchen bekannte Verzeichnisse, Konfigurationsdateien und Software-Endpunkte nach veralteten Komponenten oder Fehlkonfigurationen, die ausgenutzt werden könnten. Aggressive Scraping-Bots können zudem große Mengen an Seiten oder Mediendateien anfordern, um Inhalte zu kopieren und an anderer Stelle erneut zu veröffentlichen, wobei sie Bandbreite und Infrastrukturkapazität beanspruchen.
DDoS-Angriffe
Manche Angriffe zielen rein auf Störung ab, statt auf Zugriff. Traffic-Flooding- und Denial-of-Service-Kampagnen versuchen, Server oder Anwendungsschichten mit anhaltenden Anfragespitzen zu überlasten, wodurch die Leistung beeinträchtigt wird oder Dienste vorübergehend nicht verfügbar sind.
Über die unmittelbaren Auswirkungen auf die Leistung hinaus kann schädlicher Bot-Traffic Analysen verfälschen und das Erlebnis für echte Besucher beeinträchtigen, wenn er nicht kontrolliert wird.
Wie man Menschen, hilfreiche Bots und schädliche Bots voneinander unterscheidet
Die Unterscheidung zwischen echten Besuchern, hilfreicher Automatisierung und schädlichen Bots hängt weniger von einem einzelnen Identikator ab, sondern vielmehr davon, konsistente Verhaltensmuster über mehrere Signale hinweg zu erkennen.
Wenn diese Indikatoren gemeinsam ausgewertet werden, lässt sich leichter feststellen, ob der Traffic menschliche Aktivitäten, legitime Automatisierung oder potenziell missbräuchliche Anfragen widerspiegelt.
Anfragehäufigkeit und -zeitpunkt
Menschliche Besucher generieren Anfragen in unregelmäßigen Abständen, während sie lesen, scrollen und navigieren, während automatisierte Systeme dazu neigen, Seiten mit sehr gleichmäßiger Geschwindigkeit oder in schnellen Bursts anzufordern, die für einen Menschen schwer nachzuahmen wären. Extrem hohe Anfrageraten von einer einzigen Quelle oder perfekt getimte Intervalle deuten in der Regel auf skriptgesteuerte Aktivitäten hin.
User-Agent-Strings
Legitime Bots identifizieren sich in der Regel klar und konsistent, während schädliche Bots häufig ihre User-Agents wechseln oder vortäuschen, um menschlich zu wirken. Der Vergleich von User-Agent-Angaben mit dem beobachteten Verhalten hilft dabei, Unstimmigkeiten aufzudecken, die auf Automatisierung hindeuten.
IP-Reputation und Netzwerkzugehörigkeit
Traffic, der von bekannten Cloud-Hosting-Netzwerken, Proxy-Diensten oder zuvor markierten Adressen stammt, kann auf automatisierte Systeme statt auf echte Menschen hindeuten. Reputationsdatenbanken und Sicherheitstools klassifizieren diese Netzwerke anhand vergangener Aktivitäten und helfen dabei, verdächtige Quellen schneller zu identifizieren.
Geografische Verteilungsmuster
Ein plötzlicher Anstieg des Datenverkehrs aus unerwarteten Regionen, insbesondere in Verbindung mit identischem Anfrageverhalten, kann auf koordinierte Bot-Aktivitäten hindeuten und nicht auf echtes Nutzerwachstum.
Einhaltung von robots.txt und Crawling-Limits
Wenn dir das auffällt, ist das ein starker Hinweis auf legitime Automatisierung. Nützliche Bots halten sich in der Regel an veröffentlichte Crawling-Richtlinien und bewegen sich innerhalb angemessener Anfragegrenzen, während schädliche Bots diese Vorgaben meist ignorieren und weiterhin auf gesperrte Pfade oder Dateien zugreifen.
Da keines dieser Signale für sich allein eine vollständige Antwort liefert, ergibt sich eine effektive Klassifizierung aus der gemeinsamen Analyse mehrerer Indikatoren. Im Laufe der Zeit ergeben diese kombinierten Muster ein zuverlässiges Bild davon, ob der eingehende Traffic echte Nutzer, nützliche Automatisierung oder Aktivitäten darstellt, die gefiltert oder gemindert werden müssen.
Wo lässt sich Bot-Traffic analysieren?
Um Bot-Aktivitäten zu verstehen, ist Transparenz über mehrere Ebenen deines Hosting- und Bereitstellungs-Stacks hinweg erforderlich. Kein einzelnes Tool liefert das vollständige Bild, weshalb die Kombination von Analysen, Protokollen und Sicherheits-Dashboards weitaus zuverlässigere Erkenntnisse liefert. Schauen wir uns die einzelnen Punkte an:
Analysetools bieten einen guten Ausgangspunkt
Traffic-Spitzen ohne entsprechendes Engagement, plötzliche geografische Anomalien oder ungewöhnliche Geräteverteilungen deuten oft auf automatisierte Aktivitäten hin. Auch wenn Analysetools Bots nicht immer präzise klassifizieren, helfen sie dabei, Muster aufzuzeigen, die auf die Notwendigkeit einer eingehenderen Untersuchung hindeuten. Selbst einfache Plugins wie Jetpack können dabei helfen.
Server- und Zugriffsprotokolle bieten den detailliertesten Einblick in das Anfrageverhalten
Protokolle zeigen die Häufigkeit von Anfragen, Antwortcodes, User-Agent-Strings, IP-Adressen und aufgerufene Pfade an. So kannst du wiederholte Scan-Muster, Anmeldeversuche oder Scraping-Verhalten erkennen, die in den zusammengefassten Analysedaten sonst verborgen blieben.
CDN-Dashboards bieten eine weitere Ebene der Transparenz
CDN-Dashboards zeigen Traffic-Muster am Netzwerkrand an, bevor Anfragen deinen Ursprungsserver erreichen. Diese Dashboards heben oft Traffic-Spitzen, regionale Anomalien oder wiederholte automatisierte Anfragen hervor, die stromaufwärts gefiltert oder in ihrer Rate begrenzt werden. So kannst du Angriffe viel früher erkennen, als es sonst der Fall wäre.
Firewalls und WAF-Tools bieten Echtzeit-Einblicke
Mit Firewalls erfährst du in Echtzeit von blockierten, angefochtenen oder verdächtigen Anfragen. Die Überprüfung von Firewall-Protokollen kann aufzeigen, welche Traffic-Quellen Sicherheitsregeln auslösen und ob Anpassungen erforderlich sind, um Fehlalarme zu reduzieren oder den Schutz zu verstärken.
Managed-Hosting-Plattformen vereinfachen den Prozess, indem sie mehrere dieser Datenquellen zusammenführen. Beispielsweise erleichtern Umgebungen, die Analysen auf CDN-Ebene, Firewall-Überwachung und Zugriffsprotokolle in einem einzigen Dashboard integrieren, die Korrelation verdächtigen Verhaltens über verschiedene Ebenen hinweg.
Hosting-Anbieter wie Kinsta stellen außerdem Daten zu Traffic-Analysen, Leistungsüberwachung und Sicherheitsereignissen direkt in ihrem Dashboard, MyKinsta, bereit. Das bedeutet, dass du und dein Team das Verhalten von Bots analysieren könnt, ohne auf mehrere externe Tools angewiesen zu sein.
Wie Bot-Traffic Analysen und Entscheidungsfindung verzerrt
Wenn sich automatisierte Anfragen mit legitimen Besuchen vermischen, spiegeln die Analysedaten Aktivitäten wider, die nicht das tatsächliche Interesse der Besucher widerspiegeln. Seitenaufrufe und Sitzungszahlen scheinen stetig zu steigen, obwohl das tatsächliche Engagement, die Conversions oder der Umsatz unverändert bleiben. Ohne den automatisierten Traffic von menschlichen Sitzungen zu trennen, könntest du überhöhte Traffic-Zahlen als Wachstum interpretieren und strategische Entscheidungen auf der Grundlage irreführender Signale treffen.
Engagement-Kennzahlen werden besonders unzuverlässig. Bots generieren oft Sitzungen mit extrem kurzer Dauer, sofortigen Abgängen oder wiederholten Seitenanfragen, was die Absprungrate und die Verweildauer auf der Seite künstlich erhöhen oder verringern kann. In manchen Fällen fordern Scraping-Bots bestimmte Seiten wiederholt an, wodurch der Eindruck entsteht, dass bestimmte Inhalte bei echten Nutzern weitaus besser abschneiden, als dies tatsächlich der Fall ist.
Auch Daten zu Standort, Geräten und Verweisen können verzerrt werden. Automatisierter Traffic stammt häufig aus Rechenzentren, Proxy-Netzwerken oder konzentrierten Regionen, die nicht der tatsächlichen Kundenbasis der Website entsprechen. Wenn diese Sitzungen in Berichte einfließen, investieren Marketingteams möglicherweise in die falschen Regionen, optimieren für falsche Gerätetrends oder interpretieren die Kampagnenleistung falsch.
Mit der Zeit wirken sich diese Ungenauigkeiten auf die Berichterstattung, die Leistungsplanung, Entscheidungen zur Skalierung der Infrastruktur und Marketinginvestitionen aus. All diese Faktoren stützen sich auf Traffic-Analysen, um die Nachfrage vorherzusagen. Wenn ein erheblicher Teil dieses Traffics aus automatisierten Anfragen besteht, laufen Unternehmen Gefahr, das Wachstum zu überschätzen, Ressourcen ineffizient zuzuweisen oder das tatsächliche Nutzerverhalten zu übersehen, das Aufmerksamkeit erfordert.
Bewährte Methoden für den Umgang mit verschiedenen Traffic-Arten
Das Management modernen Web-Traffics erfordert einen ausgewogenen Ansatz, der die Website-Performance schützt, ohne legitime Automatisierung oder echte Nutzer zu beeinträchtigen. Anstatt zu versuchen, alles zu blockieren, was automatisiert erscheint, besteht das Ziel darin, Richtlinien anzuwenden, die dem Verhalten und der Absicht der jeweiligen Traffic-Art entsprechen.
Priorisiere das echte Nutzererlebnis
Optimiere Leistung, Verfügbarkeit und Barrierefreiheit, damit legitime Besucher auch bei Traffic-Spitzen schnell und zuverlässig auf Inhalte zugreifen können. Schnelle Ladezeiten, eine stabile Infrastruktur und ein robustes Caching tragen dazu bei, dass legitime Nutzer nicht beeinträchtigt werden, wenn der automatisierte Traffic zunimmt. Du kannst die Leistung direkt in Kinsta optimieren, indem du die Kinsta-API mit Google PageSpeed Insights nutzt.
Hilfreiche Automatisierung zulassen und überwachen
Suchmaschinen-Crawler, Verfügbarkeitsmonitore und Validierungstools sollten, wo angemessen, ausdrücklich zugelassen werden, damit Indizierung, Überwachung und Integrationen weiterhin korrekt funktionieren. Eine regelmäßige Überprüfung des Crawling-Verhaltens hilft dabei, sicherzustellen, dass legitime Bots innerhalb angemessener Grenzen operieren.
Wende verhaltensbasierte Schutzmaßnahmen gegen schädlichen Traffic an
Ratenbegrenzungen, Sicherheitsabfragen und gezielte Blockierungsregeln funktionieren am besten, wenn sie durch verdächtige Anfragemuster ausgelöst werden, anstatt auf statischen Annahmen über IP-Bereiche oder User-Agents zu beruhen. Verhaltenskontrollen verringern die Wahrscheinlichkeit, legitime Dienste zu blockieren, während missbräuchliche Aktivitäten dennoch eingedämmt werden.
Überprüfe und passe Richtlinien regelmäßig an
Traffic-Muster ändern sich, wenn Websites wachsen, Kampagnen starten und neue automatisierte Systeme mit Inhalten interagieren. Regelmäßige Überprüfungen von Firewall-Regeln, Ratenbegrenzungen und Überwachungswarnungen helfen sicherzustellen, dass die Schutzmaßnahmen deinem aktuellen Traffic-Verhalten entsprechen, anstatt sich auf veraltete Annahmen zu stützen.
Nutze Informationen zur Traffic-Quelle, um bessere Entscheidungen zu treffen
Das Traffic-Volumen allein sagt selten alles darüber aus, wie eine Website performt. Wenn menschliche Besuche, nützliche Automatisierung und schädliche Bot-Aktivitäten voneinander getrennt werden, werden Analysedaten weitaus aussagekräftiger und umsetzbarer.
Eine saubere Traffic-Segmentierung ermöglicht es Teams, echtes Zielgruppenwachstum zu messen, reale Interaktionsmuster zu verstehen und die Marketing-Performance zu bewerten, ohne dass automatisierte Störsignale die Ergebnisse verfälschen.
Eine genauere Traffic-Klassifizierung verbessert zudem operative Entscheidungen. Leistungsplanung, Skalierung der Infrastruktur und Sicherheitsstrategien lassen sich leichter an den tatsächlichen Bedarf anpassen, wenn automatisierte Anfragen unabhängig gemessen und verwaltet werden.
Wenn deine aktuelle Hosting-Umgebung nur begrenzte Einblicke in Traffic-Quellen bietet, lohnt es sich vielleicht, Plattformen zu prüfen, die tiefere Traffic-Einblicke und integrierte Bot-Management-Tools bieten. Managed-Umgebungen wie Kinsta bieten integrierte Analysen, Firewall-Schutz und Traffic-Einblicke auf Edge-Ebene, die dabei helfen, echte Nutzer von automatisierten Aktivitäten zu unterscheiden.
Die neueren bandbreitenbasierten Hosting-Pakete von Kinsta bieten zudem mehr Flexibilität, da sie die Hosting-Ressourcen enger an den tatsächlichen Datenverkehrskonsum anpassen. Wenn du Fragen hast, kannst du dich jederzeit an unser Support-Team wenden.

Joel ist Frontend-Entwickler und arbeitet bei Kinsta als Technical Editor. Er ist ein leidenschaftlicher Lehrer mit einer Vorliebe für Open Source und hat über 200 technische Artikel geschrieben, die sich hauptsächlich um JavaScript und seine Frameworks drehen.

