
Un aumento del traffico dovrebbe significare un maggiore successo, ma nella pratica spesso non è così. Molti siti web registrano un aumento delle visite, mentre le conversioni, il coinvolgimento e i ricavi rimangono invariati, lasciando i team a chiedersi perché questa “crescita” non sembri affatto tale.
Uno dei motivi è che non tutto il traffico rappresenta persone reali. L’attività automatizzata costituisce ormai una quota consistente del web moderno. Infatti, l’Imperva Bad Bot Report 2025 ha rilevato che i sistemi automatizzati rappresentavano il 51% di tutto il traffico web nel 2024, il che significa che i bot hanno generato complessivamente più richieste dei visitatori umani per la prima volta in un decennio.
Quando il traffico automatizzato si mescola ai report di analisi, il semplice conteggio delle visite diventa una misura inaffidabile dell’interesse o della domanda reale del pubblico.
Questo articolo spiega come distinguere tra visitatori reali del sito, automazione utile e attività dannosa dei bot.
Cos’è in realtà il traffico dei bot
Il traffico dei bot si riferisce alle richieste effettuate da software automatizzati anziché da un utente che utilizza un browser. Questi programmi inviano richieste a pagine web, immagini, script o API proprio come farebbe il browser di un visitatore, ma l’attività avviene senza un’interazione umana diretta.
Da un punto di vista tecnico, il server spesso vede lo stesso tipo di richiesta. La differenza sta nel modo in cui la richiesta viene generata e nel suo comportamento nel tempo.
L’automazione non è insolita né intrinsecamente dannosa. Gran parte di Internet dipende da sistemi automatizzati che scansionano continuamente i siti web, controllano l’uptime, verificano le prestazioni o recuperano dati per servizi legittimi. I motori di ricerca si affidano ai bot per scoprire e indicizzare nuovi contenuti, gli strumenti di monitoraggio testano regolarmente la disponibilità e varie integrazioni interrogano le API per mantenere le applicazioni sincronizzate.
È importante sottolineare che il termine “bot” descrive come viene generato il traffico, non perché esiste. Alcuni sistemi automatizzati supportano la visibilità e la sicurezza, mentre altri tentano di sfruttare le vulnerabilità, estrarre contenuti o sovraccaricare l’infrastruttura. Poiché le intenzioni variano notevolmente, identificare e classificare il comportamento dei bot è molto più utile che trattare tutto il traffico automatizzato come un’unica categoria.
I tre tipi di traffico che arrivano sul tuo sito
Il traffico web viene spesso discusso come una semplice divisione tra “umano” e “bot”, ma in realtà la maggior parte delle richieste rientra in tre categorie pratiche: visitatori reali, bot utili e bot dannosi. Comprendere questa distinzione rende più facile interpretare le analisi, gestire le risorse e applicare i giusti controlli di sicurezza senza interrompere l’attività legittima.
Come accennato in precedenza, l’Imperva Bad Bot Report ha rilevato che il traffico automatizzato rappresentava più della metà di tutte le richieste web a livello globale, con una parte consistente classificata come automazione benefica o attività bot dannosa. Quando queste diverse fonti vengono combinate, il volume di traffico da solo fornisce poche informazioni sulla domanda o sul coinvolgimento reale degli utenti.
L’obiettivo non è bloccare tutto ciò che sembra automatizzato, ma identificare quali richieste provengono da persone reali, quali supportano la funzionalità e la visibilità del sito e quali creano rischi o un carico inutile.
Analizzare i modelli di comportamento, le caratteristiche delle richieste e le fonti di traffico può darti la chiarezza necessaria per consentire l’automazione benefica, proteggerti dalle attività dannose e valutare le prestazioni utilizzando dati che riflettono il comportamento reale degli utenti.
Visitatori reali: come si presenta il traffico umano
Il traffico umano tende a seguire modelli irregolari e imprevedibili. I visitatori reali si muovono nei siti in modi diversi. Cliccano su percorsi di navigazione diversi, si fermano su determinate pagine, scorrono a diverse profondità e trascorrono periodi di tempo variabili prima di compiere l’azione successiva. Anche quando più visitatori provengono dalla stessa campagna o regione, il loro comportamento raramente segue sequenze identiche.
Le sessioni degli utenti autentici includono anche modelli di interazione realistici. Azioni come ricerche sul sito, invio di moduli, riproduzione di contenuti multimediali, accessi all’account o attività di e-commerce si verificano in genere in sequenze logiche piuttosto che a intervalli perfettamente sincronizzati o ripetuti. La tempistica tra le richieste varia naturalmente, riflettendo il modo in cui le persone leggono, pensano e decidono cosa fare dopo.
Con MyKinsta, puoi vedere rapidamente quali pagine stanno ricevendo più traffico, a colpo d’occhio:

La diversità dei dispositivi è un altro forte indicatore del traffico umano. I visitatori reali arrivano utilizzando un’ampia varietà di browser, sistemi operativi, velocità di connessione e dimensioni dello schermo. Anche il traffico geografico concentrato mostra variazioni tra dispositivi e configurazioni, creando una distribuzione che raramente appare uniforme.
MyKinsta fornisce anche informazioni sull’utilizzo dei dispositivi:
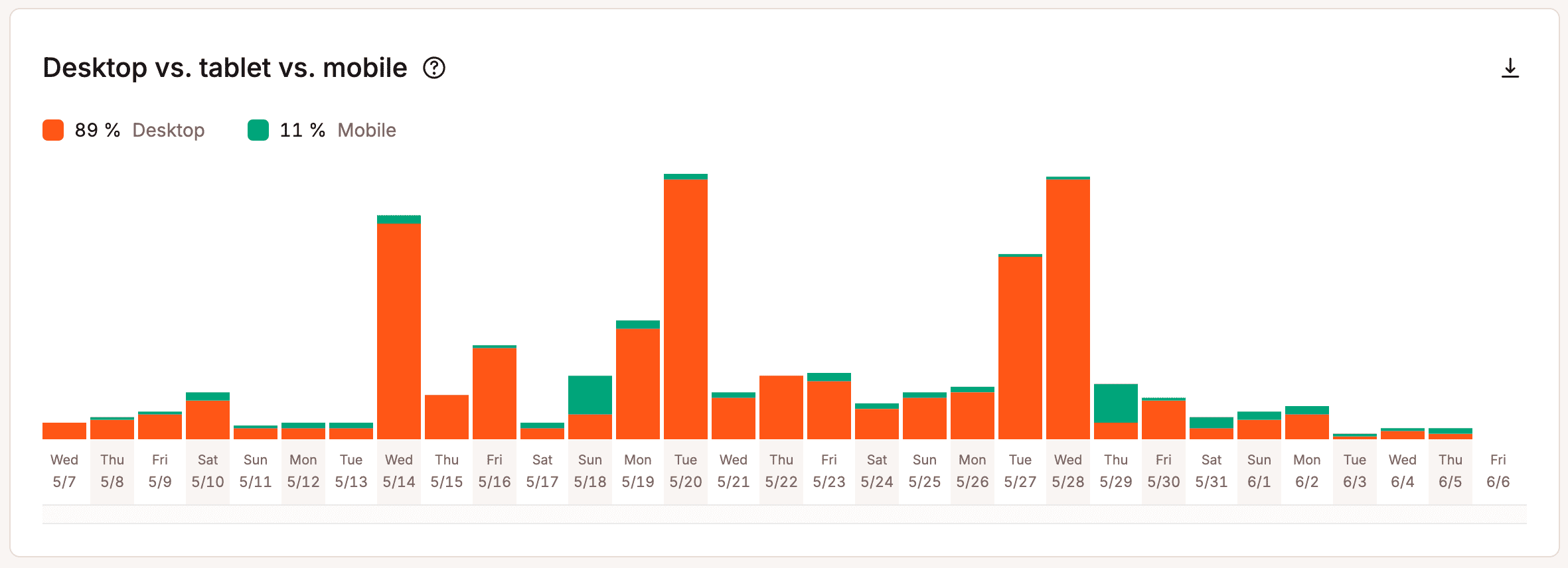
Allo stesso tempo, identificare il traffico umano non è sempre semplice. Le protezioni della privacy, gli ad blocker, i livelli di cache e gli ambienti di rete condivisi possono oscurare determinati segnali o far apparire utenti diversi simili a livello di infrastruttura.
Per questo motivo, la classificazione del traffico funziona meglio quando più indicatori, inclusi quei modelli di comportamento, le caratteristiche delle sessioni, la diversità dei dispositivi e i segnali di interazione di cui abbiamo parlato, vengono valutati insieme piuttosto che affidarsi a una singola metrica.
Bot utili: automazione a supporto del sito
Non tutto il traffico automatizzato è qualcosa che vuoi bloccare. Molti bot svolgono un ruolo essenziale nel mantenere un sito web visibile, monitorato e funzionante correttamente.
Crawler dei motori di ricerca
Questo è uno degli esempi più importanti. Questi bot richiedono sistematicamente le pagine per scoprire nuovi contenuti, valutare le modifiche e aggiornare gli indici di ricerca.
Il loro comportamento è in genere strutturato e prevedibile: seguono i link in modo metodico e rispettano le direttive di scansione definite nel file robots.txt. Impedire a questi crawler di accedere al sito può ridurre la visibilità nei motori di ricerca e ritardare la velocità con cui le nuove pagine compaiono nei risultati.
Monitoraggio dell’uptime e servizi di test
Altre forme legittime di automazione si concentrano sul monitoraggio e sullo stato operativo. Gli strumenti di monitoraggio dell’uptime, i controlli delle prestazioni e i servizi di test sintetici inviano richieste a intervalli regolari per confermare la disponibilità, misurare i tempi di caricamento e rilevare tempestivamente eventuali malfunzionamenti.
Strumenti SEO e di validazione
Allo stesso modo, gli strumenti SEO, di accessibilità e di validazione scansionano le pagine per identificare problemi tecnici, link non funzionanti o questioni di conformità che altrimenti potrebbero passare inosservate.
I bot utili generalmente rendono chiara la loro presenza. Spesso si identificano tramite stringhe user agent coerenti, operano entro limiti di richiesta definiti e seguono le politiche di scansione pubblicate.
Poiché questi sistemi supportano l’indicizzazione, l’osservabilità e le integrazioni, bloccarli senza prima esaminarli può interrompere i flussi di lavoro di monitoraggio, ridurre la reperibilità o compromettere i servizi che dipendono da richieste automatizzate programmate.
Bot dannosi: traffico che crea rischi o sprechi
I bot dannosi sono sistemi automatizzati progettati per sfruttare i siti web, estrarre dati su larga scala o consumare risorse infrastrutturali senza fornire alcun valore legittimo. A differenza dell’automazione utile, questi bot in genere tentano di nascondere la propria identità, ignorano le regole di scansione e generano modelli di richiesta volti ad aggirare le protezioni di base.
Bot di credential stuffing e brute force
Queste sono tra le minacce più comuni. Questi sistemi prendono ripetutamente di mira gli endpoint di accesso, testando in rapida successione lunghi elenchi di nomi utente e password rubati nel tentativo di ottenere un accesso non autorizzato. Anche quando non hanno successo, il volume delle richieste può aumentare il carico del server e rallentare i tempi di risposta per gli utenti legittimi.
Scanner di vulnerabilità e scraper
Altre forme di automazione dannosa si concentrano sull’individuazione e lo sfruttamento delle vulnerabilità. Gli scanner di vulnerabilità analizzano directory note, file di configurazione ed endpoint software alla ricerca di componenti obsoleti o configurazioni errate che potrebbero essere sfruttate. I bot di scraping aggressivi possono anche richiedere grandi volumi di pagine o file multimediali per copiare contenuti da ripubblicare altrove, consumando così larghezza di banda e capacità dell’infrastruttura.
Attacchi DDoS
Alcuni attacchi mirano esclusivamente a causare interruzioni piuttosto che all’accesso. Le campagne di flooding del traffico e denial-of-service tentano di sovraccaricare i server o i livelli applicativi con picchi di richieste prolungati, compromettendo le prestazioni o rendendo i servizi temporaneamente non disponibili.
Oltre al suo impatto immediato sulle prestazioni, il traffico dannoso dei bot può distorcere le analisi e peggiorare l’esperienza dei visitatori reali se non viene gestito.
Come distinguere gli esseri umani, i bot utili e i bot dannosi
Distinguere tra visitatori reali, automazione utile e bot dannosi dipende meno da un singolo identificatore e più dal riconoscimento di modelli di comportamento coerenti attraverso più segnali.
Se valutati insieme, questi indicatori rendono più facile determinare se il traffico riflette attività umana, automazione legittima o richieste potenzialmente abusive.
Frequenza e tempistica delle richieste
I visitatori umani generano richieste a intervalli irregolari mentre leggono, scorrono e navigano, mentre i sistemi automatizzati tendono a richiedere pagine a velocità molto costanti o in rapidi picchi che sarebbero difficili da replicare per una persona. Tassi di richiesta estremamente elevati da una singola fonte o intervalli perfettamente sincronizzati di solito indicano un’attività scriptata.
Stringhe dell’user agent
I bot legittimi in genere si identificano in modo chiaro e coerente, mentre i bot dannosi cambiano spesso o falsificano gli user agent nel tentativo di sembrare umani. Confrontare le dichiarazioni degli user agent con il comportamento osservato aiuta a rivelare incongruenze che indicano la presenza di automazione.
Reputazione IP e proprietà della rete
Il traffico proveniente da reti di cloud hosting note, servizi proxy o indirizzi segnalati in precedenza può indicare sistemi automatizzati piuttosto che persone reali. I database di reputazione e gli strumenti di sicurezza classificano queste reti in base all’attività passata e aiutano a identificare più rapidamente le fonti sospette.
Modelli di distribuzione geografica
Aumenti improvvisi di traffico da regioni inaspettate, specialmente se combinati con un comportamento identico nelle richieste, possono suggerire un’attività coordinata dei bot piuttosto che una crescita reale del pubblico.
Rispetto del file robots.txt e dei limiti di scansione
Se noti questo, è un forte indicatore di automazione legittima. I bot utili generalmente seguono le politiche di scansione pubblicate e operano entro limiti di richiesta ragionevoli, mentre i bot dannosi in genere ignorano queste direttive e continuano a richiedere percorsi o file soggetti a restrizioni.
Poiché nessuno di questi segnali da solo fornisce una risposta completa, una classificazione efficace deriva dall’analisi combinata di diversi indicatori. Nel tempo, questi modelli combinati creano un quadro affidabile per capire se il traffico in entrata rappresenta utenti reali, automazione benefica o attività che richiede filtraggio o mitigazione.
Dove analizzare il traffico dei bot
Comprendere l’attività dei bot richiede visibilità su diversi livelli del tuo stack di hosting e distribuzione. Nessuno strumento da solo mostra il quadro completo, ed è per questo che combinare analisi, log e dashboard di sicurezza produce informazioni molto più affidabili. Diamo un’occhiata a ciascuno di essi:
Le piattaforme di analisi forniscono un punto di partenza di alto livello
Picchi di traffico senza un corrispondente coinvolgimento, improvvise anomalie geografiche o distribuzioni insolite dei dispositivi spesso segnalano attività automatizzata. Anche se gli strumenti di analisi non sempre classificano i bot con precisione, aiutano a illustrare modelli che segnalano la necessità di un’indagine più approfondita. Anche semplici plugin come Jetpack possono essere d’aiuto in questo senso.
I log del server e di accesso offrono la visione più dettagliata del comportamento delle richieste
I log rivelano la frequenza delle richieste, i codici di risposta, le stringhe degli user agent, gli indirizzi IP e i percorsi di accesso, consentendoti di identificare modelli di scansione ripetuti, tentativi di attacco di login o comportamenti di scraping che altrimenti rimarrebbero nascosti nei dati analitici aggregati.
Le dashboard CDN aggiungono un ulteriore livello di visibilità
Le dashboard CDN mostrano i modelli di traffico ai margini della rete prima che le richieste raggiungano il tuo server di origine. Queste dashboard spesso evidenziano picchi di traffico, anomalie regionali o richieste automatizzate ripetute che vengono filtrate o limitate a monte. Questo ti aiuta a rilevare gli attacchi molto prima di quanto faresti altrimenti.
I firewall e gli strumenti WAF forniscono informazioni in tempo reale
I firewall permettono di conoscere in tempo reale le richieste bloccate, contestate o sospette. Esaminare i log del firewall può rivelare quali fonti di traffico stanno attivando le regole di sicurezza e se sono necessari aggiustamenti per ridurre i falsi positivi o rafforzare le protezioni.
Le piattaforme di hosting gestito semplificano il processo consolidando molte di queste fonti di dati. Ad esempio, gli ambienti che integrano analisi a livello di CDN, monitoraggio dei firewall e log di accesso in un’unica dashboard rendono più facile correlare i comportamenti sospetti tra i vari livelli.
I provider di hosting come Kinsta mettono in evidenza anche le analisi del traffico, il monitoraggio delle prestazioni e i dati sugli eventi di sicurezza direttamente all’interno della loro dashboard, come MyKinsta. Questo significa che tu e il tuo team potete analizzare il comportamento dei bot senza dover ricorrere a più strumenti esterni.
Come il traffico dei bot distorce le analisi e il processo decisionale
Quando le richieste automatizzate si mescolano alle visite legittime, i dati analitici iniziano a riflettere un’attività che non rappresenta il reale interesse del pubblico. Le visualizzazioni di pagina e il numero di sessioni possono sembrare in costante aumento anche se il coinvolgimento effettivo, le conversioni o le entrate rimangono invariati. Senza separare il traffico automatizzato dalle sessioni umane, potresti interpretare i numeri gonfiati del traffico come una crescita e prendere decisioni strategiche basate su segnali fuorvianti.
Le metriche di coinvolgimento diventano particolarmente inaffidabili. I bot generano spesso sessioni di durata estremamente breve, uscite immediate o richieste ripetute di pagine, il che può aumentare o diminuire artificialmente la frequenza di rimbalzo e il tempo trascorso sulla pagina. In alcuni casi, i bot di scraping richiedono ripetutamente pagine specifiche, creando l’impressione che determinati contenuti abbiano un rendimento molto migliore di quanto non abbiano in realtà tra gli utenti reali.
Anche i dati geografici, relativi ai dispositivi e ai referral possono risultare distorti. Il traffico automatizzato proviene spesso da data center, reti proxy o regioni concentrate che non corrispondono all’effettiva base clienti del sito. Quando queste sessioni vengono incluse nei report, i team di marketing potrebbero investire nelle regioni sbagliate, ottimizzare in base a tendenze errate sui dispositivi o interpretare in modo errato le prestazioni delle campagne.
Nel tempo, queste imprecisioni influenzano la reportistica, la pianificazione delle prestazioni, le decisioni relative al ridimensionamento dell’infrastruttura e gli investimenti di marketing. Tutti questi aspetti si basano sull’analisi del traffico per prevedere la domanda. Se una parte significativa di quel traffico è costituita da richieste automatizzate, le aziende rischiano di sovrastimare la crescita, allocare le risorse in modo inefficiente o trascurare comportamenti reali degli utenti che richiedono attenzione.
Best practice per la gestione dei diversi tipi di traffico
La gestione del traffico web moderno richiede un approccio equilibrato che protegga le prestazioni del sito senza interferire con l’automazione legittima o con gli utenti reali. Piuttosto che cercare di bloccare tutto ciò che sembra automatizzato, l’obiettivo è applicare politiche che corrispondano al comportamento e all’intento di ciascun tipo di traffico.
Dai priorità all’esperienza degli utenti reali
Ottimizza le prestazioni, la disponibilità e l’accessibilità in modo che i visitatori legittimi possano accedere ai contenuti in modo rapido e affidabile, anche durante i picchi di traffico. Tempi di caricamento rapidi, un’infrastruttura stabile e una cache resiliente aiutano a garantire che gli utenti legittimi non siano influenzati dall’aumento del traffico automatizzato. Puoi ottimizzare le prestazioni direttamente all’interno di Kinsta utilizzando l’API di Kinsta con Google PageSpeed Insights.
Consenti e monitora l’automazione utile
I crawler dei motori di ricerca, i monitor di uptime e gli strumenti di convalida dovrebbero essere esplicitamente consentiti, ove appropriato, in modo che l’indicizzazione, il monitoraggio e le integrazioni continuino a funzionare correttamente. Esaminare periodicamente il comportamento di crawling aiuta a confermare che i bot legittimi operino entro limiti ragionevoli.
Applica protezioni basate sul comportamento al traffico dannoso
I limiti di velocità, le verifiche di sicurezza e le regole di blocco mirate funzionano meglio quando vengono attivate da modelli di richiesta sospetti piuttosto che da ipotesi statiche su intervalli IP o user agent. I controlli comportamentali riducono la probabilità di bloccare servizi legittimi, mitigando al contempo le attività abusive.
Rivedi e modifica regolarmente le policy
I modelli di traffico cambiano man mano che i siti crescono, vengono lanciate campagne e nuovi sistemi automatizzati interagiscono con i contenuti. Le revisioni periodiche delle regole del firewall, dei limiti di velocità e degli avvisi di monitoraggio aiutano a garantire che le protezioni corrispondano al tuo attuale comportamento di traffico, invece di basarsi su ipotesi obsolete.
Usa le informazioni sulla fonte del traffico per prendere decisioni migliori
Il volume di traffico da solo raramente racconta tutta la storia delle prestazioni di un sito web. Quando le visite umane, l’automazione utile e l’attività dannosa dei bot vengono separate, i dati analitici diventano molto più significativi e utilizzabili.
Una segmentazione pulita del traffico permette ai team di misurare la crescita reale del pubblico, comprendere i modelli di coinvolgimento effettivi e valutare le prestazioni di marketing senza che il rumore automatizzato distorca i risultati.
Una classificazione del traffico più accurata migliora anche le decisioni operative. La pianificazione delle prestazioni, il ridimensionamento dell’infrastruttura e le strategie di sicurezza diventano più facili da allineare alla domanda reale quando le richieste automatizzate vengono misurate e gestite in modo indipendente.
Se il tuo attuale ambiente di hosting offre una visibilità limitata sulle fonti di traffico, potrebbe valere la pena valutare piattaforme che offrono informazioni più approfondite sul traffico e strumenti integrati di gestione dei bot. Gli ambienti gestiti come Kinsta forniscono analisi integrate, protezioni firewall e approfondimenti sul traffico a livello di edge che aiutano a distinguere gli utenti reali dall’attività automatizzata.
I nuovi piani di hosting basati sulla larghezza di banda di Kinsta aggiungono inoltre flessibilità, abbinando più da vicino le risorse di hosting al consumo effettivo di traffico. Se hai domande, puoi rivolgerti al nostro team di supporto in qualsiasi momento.


