
De meeste bureaus denken niet veel na over Service Level Agreements (SLA’s) totdat er iets misgaat.
Wanneer een site van een klant uitvalt tijdens een lancering, de ondersteuning er langer over doet dan verwacht om te reageren, of de prestaties inzakken zonder duidelijke verklaring – dan wordt het verschil tussen een vage belofte en een gedocumenteerde garantie pijnlijk duidelijk.
Voor bureaus die jongleren met meerdere klantensites is betrouwbare hosting geen luxe: het is essentieel. Het beïnvloedt de timing van campagnes, de inkomsten uit e-commerce en het vertrouwen dat klanten in jouw aanbevelingen hebben. Als er hostingproblemen zijn, horen bureaus er vaak als eersten van, ongeacht waar de fout werkelijk ligt.
SLA’s zijn er om duidelijkheid te scheppen in die relatie. Ze geven aan wat een hostingprovider belooft te leveren, hoe prestaties en ondersteuning worden gemeten en wat er gebeurt als niet aan die normen wordt voldaan.
Dit artikel gaat dieper in op wat SLA’s en garanties écht betekenen, waar bureaus op moeten letten bij het beoordelen ervan en hoe de juiste overeenkomst kan helpen om zowel de relatie met de klant als de inkomsten van het bureau veilig te stellen.
Wat een SLA nou eigenlijk is (en wat het niet is)
Een SLA is een formeel document dat beschrijft wat een hostingprovider belooft te leveren en hoe die belofte wordt gemeten.
Het gaat meestal over prestatiebenchmarks, ondersteuningsverwachtingen, beschikbaarheidsdoelen en de vervolgstappen die beschikbaar zijn als die doelen niet worden gehaald. Praktisch gezien is het het verschil tussen een provider die zégt te streven naar betrouwbaarheid en een die cijfers, definities en verantwoording achter die claim zet.
Dat onderscheid is belangrijk omdat hostingmarketing vol staat met geruststellende taal. Je ziet zinnen als “hoge beschikbaarheid”, “razendsnelle prestaties” of “deskundige ondersteuning”, maar die beweringen op zichzelf wegen niet zo zwaar.
Een SLA definieert uptime in meetbare termen, schetst de reactietijden voor ondersteuning en legt uit wat er gebeurt als de leverancier zijn beloften niet nakomt. Ze helpen ook bij het standaardiseren van verwachtingen op belangrijke gebieden van hostingbetrouwbaarheid.
Tegelijkertijd is een SLA geen algemene belofte dat er nooit iets mis zal gaan. Het voorkomt downtime of prestatieproblemen niet helemaal. In plaats daarvan creëert het een gedeeld begrip van acceptabele drempels en een raamwerk voor het oplossen van problemen als die zich voordoen.
Waarom SLA’s belangrijker zijn voor bureaus dan voor individuele site-eigenaren
Hostingproblemen wegen zwaarder als je verantwoordelijk bent voor sites van klanten. Een korte storing of prestatiedip kan een campagne doen ontsporen, een lancering vertragen of een golf van klantberichten veroorzaken die je team in realtime moet afhandelen. Zelfs als de hostingprovider in gebreke blijft, zijn het meestal de bureaus die moeten uitleggen wat er is gebeurd en hoe het wordt opgelost.
Door deze realiteit zijn hostinggaranties nauw verbonden met de beloften die bureaus doen over uptime, snelheid en betrouwbaarheid. Als die verwachtingen deel uitmaken van je positionering of retainers, dan vertrouwen ze op de toezeggingen achter je infrastructuur. Duidelijke SLA’s versterken die verwachtingen en maken het makkelijker om met klanten te communiceren tijdens incidenten.
Er is ook een praktisch risico. Zwakke of vage garanties laten bureaus opdraaien voor de operationele en reputatie-impact van downtime, trage ondersteuning of onopgeloste prestatieproblemen. Goed gedefinieerde SLA’s helpen bij het stellen van grenzen, leggen verantwoording af en geven bureaus een referentiepunt als er iets mis gaat.
Uptime-garanties: Verder kijken dan het percentage
Uptimepercentages zien er op het eerste gezicht geruststellend uit, maar ze vertellen niet altijd het hele verhaal. Kleine verschillen in die cijfers kunnen zich vertalen in merkbare downtime in de loop van een jaar, vooral voor sites met veel verkeer of inkomsten.
Om gemeenschappelijke garanties in perspectief te plaatsen:
- 99.9% uptime: Ruwweg 8 uur en 45 minuten downtime per jaar
- 99.95% uptime: Ongeveer 4 uur en 20 minuten per jaar
- 99.99% uptime: Iets minder dan 53 minuten per jaar
- 99.999% uptime: Ongeveer 5 minuten per jaar
Die onderbrekingen zijn belangrijk. Voor bureaus die e-commercesites, ledenplatforms of landingspagina’s voor campagnes beheren, kunnen zelfs korte onderbrekingen conversies en het vertrouwen van klanten beïnvloeden.
Naast het percentage zelf, moeten bureaus ook letten op hoe uptime wordt gedefinieerd en gemeten. Sommige providers berekenen de beschikbaarheid op netwerkniveau, terwijl anderen de uptime op applicatieniveau meten, wat meestal meer betekenis heeft voor de werkelijke prestaties van een site. De rapportagefrequentie varieert ook. Betrouwbare hosts leveren meestal historische uptime-gegevens of dashboards, zodat je de prestaties kunt controleren in plaats van af te gaan op marketingclaims.
Transparantie tijdens incidenten is een andere belangrijke factor. Aanbieders met openbare statuspagina’s, duidelijke communicatie-updates en samenvattingen na een incident maken het makkelijker voor bureaus om klanten op de hoogte te houden.
Kinsta heeft ook een speciale statuspagina voor het melden van uptime en storingsincidenten:

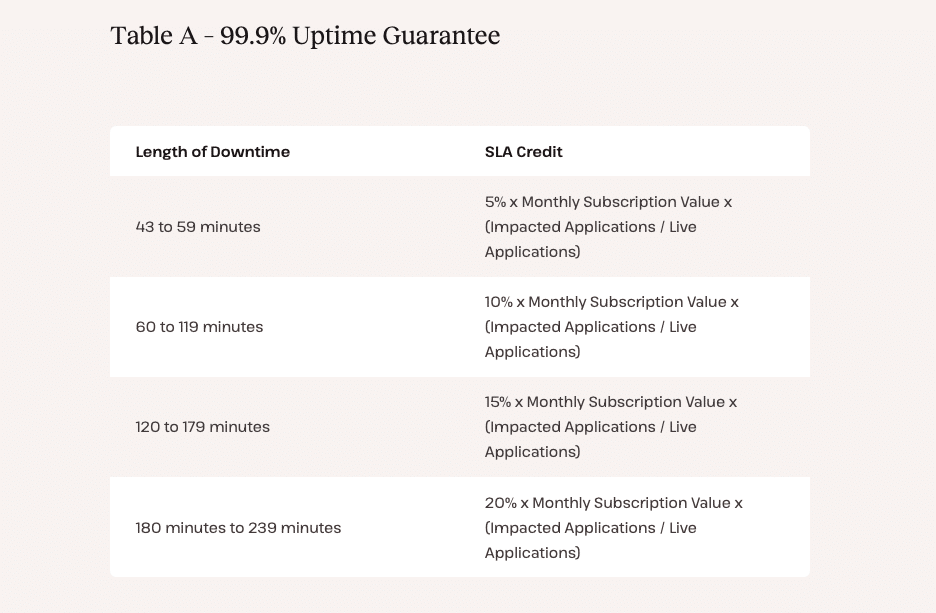
Tot slot is het de moeite waard om te kijken hoe compensatie werkt als uptime-doelstellingen niet worden gehaald. Veel SLA’s bieden credits gekoppeld aan downtimedrempels, maar de waarde en de criteria om hiervoor in aanmerking te komen kunnen sterk verschillen. Bureaus moeten bekijken hoe downtime wordt berekend, of claims automatisch of handmatig worden ingediend en of credits de operationele impact op een zinvolle manier compenseren.
Zelfs als de compensatie bescheiden is, geeft de aanwezigheid van duidelijke oplossingen aan dat er verantwoording moet worden afgelegd. Kinsta biedt bijvoorbeeld SLA-credits op basis van de lengte van de downtime, mocht die zich voordoen:
Prestatiegaranties en betrouwbaarheid van de infrastructuur
Sommige hosting SLA’s gaan een stap verder dan uptime door in te gaan op prestatieverwachtingen. In plaats van zich alleen te richten op beschikbaarheid, kunnen ze verwijzen naar responstijden, toewijzing van resources of consistentie onder belasting.
Voor bureaus die marketingcampagnes of e-commercesites beheren, is dat onderscheid belangrijk. Een site kan technisch online zijn maar toch traag genoeg om de gebruikerservaring en resultaten te beïnvloeden.
Bij het evalueren van prestatiegerelateerde garanties helpt het om naar de achterliggende infrastructuur te kijken. Belangrijke factoren die betrouwbare prestaties ondersteunen zijn vaak
- Geïsoleerde omgevingen: Voorkomen dat “noisy neighbors” gedeelde resources gebruiken en de snelheid of stabiliteit beïnvloeden.
- Schaalbaarheid: Resources in staat stellen om pieken in het verkeer op te vangen zonder downtime.
- Wereldwijde datacenterdekking: Verminder vertraging door bezoekers dichter bij hun geografische locatie de site te leveren.
- Ingebouwde caching en CDN-integratie: Verbeter de afleversnelheid en verminder de serverbelasting tijdens perioden met veel vraag.
- Moderne hardware en netwerkredundantie: Ondersteun consistente responstijden en verminder problemen.
Deze elementen bepalen hoe goed een site presteert onder echte omstandigheden, vooral als het verkeer onvoorspelbaar of campagne-gedreven is.
Voor bureaus is de betrouwbaarheid van de prestaties direct gekoppeld aan meetbare resultaten. Trage responstijden kunnen de zichtbaarheid bij zoekopdrachten beïnvloeden, bouncepercentages verhogen en het conversiepotentieel beperken. Tijdens betaalde campagnes of productlanceringen kunnen inconsistente prestaties ook het rendement op advertentie-uitgaven verminderen en vermijdbare zorgen bij klanten veroorzaken.
Prestatiegaranties elimineren variabiliteit niet helemaal, maar ze geven wel aan dat een hostingprovider bereid is om bepaalde verwachtingen te definiëren en erachter te staan. In combinatie met een sterke infrastructuur helpen deze toezeggingen bureaus om consistentere ervaringen te leveren en verrassingen tijdens belangrijke momenten te beperken.
SLA’s voor ondersteuning: Responstijd vs oplostijd
Supportgaranties zien er op papier vaak eenvoudig uit, maar de details erachter maken een groot verschil voor bureaus. De meeste SLA’s splitsen supportverplichtingen op in een paar belangrijke metrics, die elk een andere fase van de supportervaring beschrijven.
Veel voorkomende termen zijn onder andere:
- Eerste reactietijd: Hoe snel een provider een ticket of live chatverzoek beantwoordt
- Oplostijd: De gemiddelde of streeftermijn voor het volledig oplossen van het probleem
- Escalatiepaden: Gedefinieerde processen voor het routeren van complexe of urgente problemen naar senior engineers
- Beschikbaarheidstijden: Of ondersteuning beperkt is tot kantooruren of 24 uur per dag wordt aangeboden
Inzicht in dit onderscheid helpt instanties om realistische verwachtingen te stellen in tijdgevoelige situaties. Een snelle eerste reactie is geruststellend, maar betekent niet noodzakelijkerwijs dat het probleem snel wordt opgelost. Tijdlijnen voor oplossingen en escalatieprocessen wegen vaak zwaarder.
Veel bureaus hechten waarde aan sterke SLA’s voor ondersteuning tijdens lanceringen, migraties en onverwachte incidenten. Toegang tot deskundige ondersteuning op elk uur kan de cycli voor probleemoplossing verkorten en voorkomen dat kleine problemen uitgroeien tot verstoringen voor de klant.
Sommige hosts combineren support SLA’s ook met proactieve monitoring en interventie. Als providers problemen vroegtijdig detecteren of oplossen voordat een ticket wordt ingediend, besteden bureaus minder tijd aan het oplossen van problemen en meer tijd aan het werk voor de klant.
Beveiligingsgaranties en incident response verplichtingen
Beveiligingsverantwoordelijkheden zijn een ander gebied waar SLA’s de broodnodige duidelijkheid kunnen verschaffen. Hoewel elke hostingprovider het over beveiliging heeft, geven gedocumenteerde garanties aan wat actief wordt beheerd, wat wordt gemonitord en hoe incidenten worden afgehandeld als ze zich voordoen.
Beveiligingsgerelateerde verplichtingen in hosting SLA’s bevatten vaak:
- Malwaredetectie en -verwijdering: Duidelijke processen voor het identificeren van infecties en het herstellen van aangetaste omgevingen.
- DDoS-bescherming: Beveiligingen op netwerkniveau die zijn ontworpen om op verkeer gebaseerde aanvallen te beperken voordat ze de beschikbaarheid van de site beïnvloeden.
- Patch- en infrastructuurupdates: Gedefinieerde verantwoordelijkheden voor het onderhoud van serversoftware, besturingssystemen en platformcomponenten.
- Dekking van firewall en monitoring: Voortdurende verkeersinspectie en detectie van bedreigingen op infrastructuurniveau.
Naast preventieve maatregelen spelen ook de verwachtingen met betrekking tot de reactie op incidenten een grote rol in de manier waarop instanties beveiligingsincidenten ervaren. Sterke SLA’s hebben meestal betrekking op detectietijdlijnen, communicatiepraktijken en de mate van ondersteuning bij herstel. Bureaus hebben er baat bij om te weten hoe snel verdachte activiteiten worden onderzocht, hoe updates worden gedeeld tijdens een incident en of er hands-on assistentie wordt geboden in het herstelproces.
Deze garanties wegen extra zwaar voor bureaus die werken met gereguleerde sectoren of zakelijke klanten. Compliance-eisen, verwachtingen op het gebied van gegevensbescherming en reputatierisico’s verhogen de inzet bij beveiligingsincidenten. Het hebben van gedocumenteerde verantwoordelijkheden en reactieprocessen maakt het makkelijker om due diligence aan te tonen en het vertrouwen van de klant te behouden.
Garanties voor backup, herstel en noodherstel
Backups worden vaak genoemd in hostingpakketten, maar SLA’s helpen verduidelijken hoe betrouwbaar die beveiligingen echt zijn. Details zoals backupfrequentie, retentievensters en herstelprocessen bepalen hoe snel instanties kunnen herstellen van gegevensverlies, sitefouten of beveiligingsincidenten.
Bij het beoordelen van backupgerelateerde garanties moeten bureaus letten op een paar kernelementen:
- Backupfrequentie: Of snapshots dagelijks, elk uur of in realtime worden uitgevoerd.
- Retentiebeleid: Hoe lang backups worden bewaard en hoeveel herstelpunten er beschikbaar zijn.
- Terugzetgaranties: Verwachte tijdsbestekken voor het voltooien van een restore en of ondersteuning is inbegrepen.
- Off-site opslag of geografische redundantie: Extra bescherming tegen lokale storingen in de infrastructuur.
Naast de backups zelf, verwijzen veel SLA’s naar hersteltijddoelstellingen (RTO) en herstelpuntdoelstellingen (RPO). RTO geeft aan hoe snel een site kan worden hersteld na een incident, terwijl RPO aangeeft hoeveel gegevensverlies acceptabel is op basis van de meest recente backup. Samen helpen deze benchmarks instanties om de hostingwaarborgen af te stemmen op de verwachtingen van de klant en de tolerantie voor verstoringen.
Breder bekeken: backups en disaster recovery zijn essentieel voor je noodplan. Bureaus die kritieke sites beheren, moeten erop kunnen vertrouwen dat storingen in de infrastructuur, beveiligingsincidenten of onbedoelde wijzigingen niet leiden tot langdurige onderbrekingen.
SLA-transparantie en -rapportage: Wat bureaus mogen verwachten
Duidelijke rapportage is wat SLA-beloften verandert in iets wat instanties daadwerkelijk kunnen verifiëren. Toegang tot realtime monitoringdashboards, openbare statuspagina’s en historische uptimegegevens geeft teams inzicht in hoe een hostingomgeving dagelijks presteert, niet alleen wanneer zich een incident voordoet.
Die transparantie maakt communicatie met klanten veel gemakkelijker. Wanneer er prestatiedips of uitval zijn, kunnen bureaus verwijzen naar updates van providers, accurate tijdlijnen delen en speculaties vermijden. Het helpt ook om hostingaanbevelingen kracht bij te zetten, omdat gedocumenteerde prestatiegegevens een concrete basis bieden om uit te leggen waarom voor een bepaald platform is gekozen.
Rapportagemogelijkheden kunnen ook interne beoordelingen en compliancebehoeften ondersteunen. Historische logboeken, samenvattingen van incidenten en prestatiecijfers maken het eenvoudiger om trends te evalueren, audits voor te bereiden en analyses uit te voeren na een incident. Na verloop van tijd helpt die zichtbaarheid instanties om hun infrastructuurbeslissingen te verfijnen en met meer vertrouwen te reageren op verstoringen.
Verborgen beperkingen en uitsluitingen waar instanties op moeten letten
SLA-garanties zien er op het eerste gezicht vaak sterk uit, maar de kleine lettertjes kunnen beperkingen introduceren die van invloed zijn op hoe die afspraken in de praktijk worden toegepast. Geplande onderhoudsvensters zijn een veelvoorkomend voorbeeld. Aanbieders kunnen geplande updates uitsluiten van uptime-berekeningen, wat redelijk is, maar de timing en frequentie van die vensters kunnen nog steeds van invloed zijn op de klantervaring.
Andere uitsluitingen kunnen integraties van externe partijen, custom configuraties of problemen als gevolg van wijzigingen op applicatieniveau zijn. Als een vertraging of uitval het gevolg is van een plugin-conflict, een externe service of een verkeerde configuratie, beschouwt de leverancier dit mogelijk niet als een schending van de SLA. Dat onderscheid kan ervoor zorgen dat bureaus in grijze gebieden moeten navigeren tijdens probleemoplossing of gesprekken met klanten.
Definities zijn ook belangrijk. Sommige SLA’s beschrijven downtime eng en richten zich op volledige onbeschikbaarheid van de service, terwijl gedeeltelijke prestatievermindering of regionale verstoringen worden uitgesloten. In die gevallen kan een site traag of met tussenpozen bereikbaar zijn zonder technisch de uptimegarantie te schenden.
Vanwege deze nuances is het de moeite waard om de SLA-taal zorgvuldig door te nemen en vragen te stellen voordat je een verplichting aangaat. Door te verduidelijken hoe downtime wordt gemeten, welke scenario’s worden uitgesloten en hoe wordt omgegaan met randgevallen, kunnen instanties verrassingen voorkomen en ervoor zorgen dat de overeenkomst overeenkomt met de verwachtingen in de praktijk.
Vragen die bureaus moeten stellen bij het evalueren van hostingpartners
SLA-documentatie kan dik zijn, dus met een aantal praktische vragen is het makkelijker om hiaten te ontdekken en providers op gelijke voet te vergelijken. Deze gesprekken helpen ook om duidelijk te maken hoe garanties zich vertalen in de dagelijkse praktijk in plaats van theoretisch te blijven.
Bij het beoordelen van de SLA van een hostingpartner kunnen bureaus vragen stellen:
- Hoe wordt uptime gemeten en gerapporteerd? Verduidelijk of de beschikbaarheid wordt bijgehouden op infrastructuur-, netwerk- of applicatieniveau en of historische gegevens toegankelijk zijn.
- Wat gebeurt er als ondersteuningsverzoeken geëscaleerd moeten worden? Begrijp reactietijdlijnen, escalatiepaden en of er senior engineers beschikbaar zijn tijdens complexe incidenten.
- Welke beveiligingsverantwoordelijkheden worden gedekt door de leverancier? Controleer de dekking rond monitoring, patching, incident response en hands-on ondersteuning bij herstel.
- Hoe vaak worden backups gemaakt en hoe snel kunnen restores worden uitgevoerd? Controleer of het backupbeleid overeenkomt met de verwachtingen van de klant met betrekking tot tolerantie voor gegevensverlies en hersteltijdlijnen.
- Welke compensatie is van toepassing als SLA-doelstellingen niet worden gehaald? Controleer hoe servicecredits worden berekend, of claims automatisch worden ingediend en of oplossingen in verhouding staan tot de impact.
- Welke scenario’s zijn uitgesloten van garanties? Identificeer beperkingen die samenhangen met onderhoudsvensters, services van derden of configuratiegerelateerde problemen.
Het stellen van deze vragen maakt het ook makkelijker om hostinggaranties te vergelijken met je eigen bureauverplichtingen. Als je retainers een snelle respons, hoge uptime of proactieve monitoring beloven, moet je hosting SLA die verwachtingen versterken in plaats van gaten te creëren die je later moet beheren.
Hoe managed hosting de betrouwbaarheid van SLA’s versterkt
SLA-verplichtingen wegen zwaarder als ze worden ondersteund door proactieve activiteiten. Managed hostingproviders investeren meestal in voortdurende monitoring, optimalisatie op platformniveau en gespecialiseerde supportteams die problemen kunnen detecteren en aanpakken voordat ze escaleren. Dat overzicht verkleint de kans op uitval, instabiele prestaties en gaten in de beveiliging.
Voor instanties betekent dit minder reactieve taken en voorspelbaarder sitebeheer. Als de hostingpartner zorgt voor het onderhoud van de infrastructuur, het patchen van de beveiliging, het afstemmen van de prestaties en het monitoren, kunnen teams zich meer richten op de klantstrategie en de levering in plaats van op het oplossen van problemen op serverniveau.
Aanbieders zoals Kinsta illustreren dit verband door gedocumenteerde garanties te koppelen aan managed omgevingen, prestatiegerichte architectuur en ervaren ondersteuningsteams. Door die afstemming kunnen instanties met meer vertrouwen vertrouwen vertrouwen op SLA-toezeggingen.
Zie SLA’s als een partnerschapsovereenkomst met je bureau
SLA’s helpen definiëren hoe verantwoording en communicatie werken tussen bureaus en hun hostingproviders. Duidelijke garanties zorgen voor transparantie over de verwachtingen op het gebied van prestaties, ondersteuning en herstel, waardoor het gemakkelijker wordt om incidenten op te lossen zonder onzekerheid of met de vinger te wijzen.
Voor bureaus ondersteunt die duidelijkheid meer dan alleen de technische kant van de zaak. Het versterkt het vertrouwen van klanten, versterkt servicebeloften en vermindert risico’s naarmate je portfolio groeit. Door SLA’s zorgvuldig te controleren en ervoor te zorgen dat ze overeenkomen met je beloften, zorg je ervoor dat je hosting de ervaring ondersteunt die je klanten willen hebben.
Als je partners evalueert met deze prioriteiten in gedachten, bieden beheerde platforms zoals Kinsta gedocumenteerde garanties die worden ondersteund door proactieve infrastructuur en deskundige ondersteuning. Praat gerust met sales als je hier meer over wilt weten.


