
Du öffnest dein Analyse-Dashboard und stellst fest, dass die Besucherzahlen gesunken sind, die Konversionsraten zurückgegangen sind oder die Ladezeiten der Website nun höher sind. Die Berichte zeigen deutlich, dass sich etwas verändert hat, aber sie erklären selten, warum.
Google Analytics zeigt vielleicht weniger Sitzungen an. Leistungstools können langsamere Ladezeiten anzeigen. Uptime-Monitoring kann bestätigen, dass die Website noch online ist. Jedes Tool zeigt einen Teil des Bildes, aber keines von ihnen erklärt, was die eigentliche Ursache der Veränderung ist.
Die meisten Analyseplattformen konzentrieren sich auf die Ergebnisse. Sie verfolgen oberflächliche Metriken wie Besucherzahlen, Engagement und Leistungskennzahlen. Diese Zahlen helfen dir, Trends zu erkennen, aber sie zeigen nicht, was innerhalb der WordPress-Anwendung oder der Serverumgebung, die die Website betreibt, passiert.
Mit anderen Worten: Sie beschreiben die Symptome, ohne die Ursache zu diagnostizieren. Um zu verstehen, warum Probleme auftreten, brauchst du Einblick in das System selbst. An dieser Stelle werden Betriebsdaten wichtig.
In diesem Artikel gehen wir der Frage nach, warum herkömmliche Analysetools oft nur oberflächliche Berichte liefern, welche Arten von Daten tatsächlich die Ursachen aufdecken und wie die Sichtbarkeit auf Hosting-Ebene das Management der Leistung und Zuverlässigkeit von WordPress verändern kann.
Der Unterschied zwischen Ergebnisanalyse und Betriebsanalyse
Die meisten Analysetools messen, was die Besucher an der Oberfläche erleben. Sie werden oft als Outcome Analytics bezeichnet.
Die Ergebnisanalyse verfolgt Kennzahlen wie Besucherzahlen, Engagement, Seitenladezeiten und Suchleistung. Plattformen wie Google Analytics und viele Tools für Leistungstests fallen in diese Kategorie. Sie helfen dir zu verstehen, wie Menschen mit deiner Website interagieren und ob diese Erfahrungen im Laufe der Zeit besser oder schlechter werden.
Diese Art von Daten ist nützlich, um Trends zu erkennen und die Marketingleistung zu bewerten. Was sie nicht verraten, ist, was innerhalb der WordPress-Anwendung oder der Serverumgebung passiert, die die Website betreibt.
Operative Analysen konzentrieren sich auf das System hinter der Website. Anstatt die Ergebnisse der Besucher zu messen, werden Signale wie Anfragemuster, Serverauslastung, Caching-Verhalten, Datenbankleistung und Anwendungsfehler verfolgt. Diese Metriken zeigen, wie sich die Website hinter den Kulissen verhält.
Wenn die Leistung nachlässt oder Zuverlässigkeitsprobleme auftreten, zeigt die Ergebnisanalyse das Ergebnis an. Operative Analysen helfen, die Ursache zu erklären. Eine effektive Fehlerbehebung bei WordPress erfordert in der Regel den Einblick in beide Ebenen.
Warum herkömmliche Monitoring-Tools oft nur an der Oberfläche kratzen
Die meisten Analyseplattformen sind darauf ausgelegt, Ergebnisse zu melden, anstatt Systeme zu diagnostizieren. Sie zeigen, was die Besucher/innen erlebten, wie die Websites funktionierten und ob die Uptime der Website. Diese Daten sind nützlich, um Trends zu verfolgen und die Leistung zu bewerten, aber sie erklären selten, was eine Veränderung verursacht hat.
Wenn die Leistung sinkt oder Fehler auftreten, zeigen diese Tools in der Regel eher das Symptom als das eigentliche Problem auf. Der Grund dafür wird klarer, wenn du dir die Art der Daten ansiehst, die sie sammeln.
Sie messen das Nutzerverhalten, nicht das Systemverhalten
Tools wie Google Analytics konzentrieren sich auf die Besucheraktivität. Sie erfassen Kennzahlen wie Seitenaufrufe, Sitzungsdauer, Absprungraten und Konversionspfade. Diese Berichte zeigen, wie sich die Besucher/innen durch deine Website bewegen, welche Seiten die Aufmerksamkeit auf sich ziehen und wo sie abspringen.
Diese Erkenntnisse sind wertvoll für Marketing- und Inhaltsentscheidungen. Allerdings verraten sie nur wenig darüber, wie WordPress oder der Server diese Anfragen verarbeitet haben.
Analysetools filtern auch viele bekannte Bots heraus, haben aber immer noch Schwierigkeiten, anspruchsvollen automatisierten Traffic zu identifizieren. Crawler, Scraper und andere Bots können immer noch als Sitzungen oder Seitenaufrufe erscheinen, was bedeutet, dass Aktivitätsspitzen nicht immer eine echte Nutzernachfrage darstellen.
Von außen betrachtet mag die Website geschäftig oder langsam erscheinen. Diese Kennzahlen zeigen jedoch selten, was der Server tatsächlich tut, um diese Anfragen zu bearbeiten.
Leistungskennzahlen zeigen Ergebnisse ohne Kontext
Leistungstests messen, wie schnell die Websites angezeigt werden und wie schnell die Besucher/innen reagieren. Metriken wie Largest Contentful Paint (LCP), Time to First Byte (TTFB) und Frameworks wie Core Web Vitals helfen dir dabei, zu überprüfen, wie schnell eine Website aus Sicht der Besucher/innen ist.
Wenn sich diese Zahlen verschlechtern, deutet das darauf hin, dass sich etwas geändert hat. Die Leistungskennzahlen geben jedoch nur selten Aufschluss über die Ursache. Ein höherer TTFB oder ein langsamerer LCP kann auf viele Ursachen zurückzuführen sein, z. B. auf umfangreiche Datenbankabfragen, ineffiziente Plugins, Spitzen im Datentraffic, umgangene Cache-Schichten oder begrenzte Serverressourcen.
Der Bericht zeigt die Verlangsamung an, aber er verrät normalerweise nicht, welche Komponente sie verursacht hat.
Monitoring-Tools konzentrieren sich nur auf die Betriebszeit
Viele Überwachungstools konzentrieren sich in erster Linie auf die Verfügbarkeit durch Uptime-Checks.
Die Uptime-Überwachung prüft, ob eine Website erreichbar ist und auf Anfragen antwortet. Dies hilft dabei, vollständige Ausfälle zu erkennen und festzustellen, ob der Dienst online ist.
Die Betriebszeit ist jedoch eine stumpfe Kennzahl. Eine Website kann technisch online bleiben, aber dennoch langsame Antworten, zeitweilige Fehler oder eine verminderte Leistung liefern. Diese Probleme treten oft lange vor einem kompletten Ausfall auf.
Da sich die Überwachung der Betriebszeit auf die Verfügbarkeit und nicht auf das Systemverhalten konzentriert, gibt sie nur einen begrenzten Einblick in die Bedingungen, die zu Verlangsamungen oder Ausfällen führen.
Warum die Fehlersuche bei der WordPress-Leistung oft zu einem Ratespiel wird
Wenn Analysetools nur Symptome aufzeigen, wird die Fehlersuche zu einem Ausschlussverfahren.
Du siehst zuerst die Auswirkungen: langsamere Websites, weniger Konversionen oder eine plötzliche Erhöhung der Server-Antwortzeiten. Aber weil die meisten Dashboards nicht zeigen, was die Infrastruktur tut, bleibt die wahre Ursache verborgen.
Website-Betreiber/innen springen oft zwischen verschiedenen Tools hin und her, um sich eine Theorie zusammenzureimen. Analyseplattformen zeigen Veränderungen im Datentraffic, Leistungstools weisen auf langsamere Ladezeiten hin und Betriebszeitüberwachungen bestätigen, dass die Website noch online ist. Jedes Tool zeigt einen kleinen Teil des Bildes, aber keines liefert die vollständige Erklärung.
In der Praxis lassen sich Leistungsprobleme bei WordPress oft auf eine Handvoll gängiger Szenarien zurückführen:
- Trafficspitzen, die die PHP-Threads überfordern: WordPress generiert Websites dynamisch. Wenn zu viele Anfragen auf einmal eintreffen, werden die verfügbaren PHP-Threads gesättigt, sodass sich die Anfragen in die Warteschlange einreihen und sich die Ladezeiten verlängern.
- Ineffiziente Datenbankabfragen durch ein Plugin-Update: Ein Plugin-Update oder eine neue Funktion kann schlecht optimierte Abfragen hinzufügen, die die Datenbanklast plötzlich erhöhen.
- Cache-Layer, die häufig angeforderte Seiten nicht mehr bedienen können: Wenn das Caching nicht mehr richtig funktioniert oder umgangen wird, muss der Server die Seiten immer wieder neu aufbauen, anstatt die gecachten Versionen zu bedienen.
- Bots erzeugen übermäßige Anfragen: Automatisierter Traffic von Crawlern, Scrapern oder bösartigen Bots kann große Mengen an Anfragen erzeugen, die die Serverressourcen belasten. Bei vielen Analyseplattformen wird dieser Traffic in den Dashboards als Besuche oder Sitzungen angezeigt, was dazu führen kann, dass Traffic-Spitzen legitim erscheinen, auch wenn sie nicht von echten Nutzern verursacht werden.
- Hintergrundaufgaben, die Serverressourcen verbrauchen: Geplante Aufgaben, Importe, Backups oder Indizierungsprozesse können im Hintergrund unbemerkt CPU und Speicher verbrauchen.
Ohne Einblick in das Serververhalten ist die Identifizierung der Ursache in der Regel mit Versuch und Irrtum verbunden. Teams deaktivieren Plugins, überprüfen Protokolle oder führen Leistungstests durch, um das Problem einzugrenzen. In vielen Fällen erfordert die Lösung des Problems eine Untersuchung durch die Entwickler, weil die verfügbaren Analysetools nicht zeigen, was das System tatsächlich tut (oder was ihm zugemutet wird).
Wie echte diagnostische Analysen beim WordPress-Hosting aussehen
Operative Analysen konzentrieren sich darauf, wie sich eine WordPress-Website hinter den Kulissen verhält. Anstatt nur zu berichten, was die Besucher erlebt haben, verfolgen sie, wie die Anwendung und die Infrastruktur in Echtzeit auf echten Traffic reagieren.
Diese Art von Transparenz macht die Analyse zu einem Werkzeug für die Fehlersuche. Wenn sich die Leistung ändert, können die Daten direkt auf die zugrundeliegende Ursache hinweisen, anstatt die Teams mit blinden Nachforschungen zu belasten.
Einige Arten von Metriken sind bei der Diagnose von WordPress-Leistungsproblemen besonders nützlich.
Anfragevolumen und Trafficmuster
Anfragedaten zeigen, wie viele Anfragen der Server verarbeitet und wann diese Anfragen auftreten. Der Datentraffic kommt selten in einem gleichmäßigen Fluss an. Spitzen bei Produkteinführungen, Marketingkampagnen oder Suchmaschinen-Crawls können die Belastung des Servers schnell erhöhen.
Anhand der Anfragemuster lässt sich leichter erkennen, ob eine Verlangsamung auf einen Anstieg des legitimen Datentraffics oder auf automatisierte Anfragen von Bots und Crawlern zurückzuführen ist.
Nutzung von PHP-Threads
WordPress nutzt PHP, um dynamische Seiten zu erstellen. Jede eingehende Anfrage benötigt einen PHP-Thread, um den Code zu verarbeiten und die Seite auszuliefern.
Wenn die Nachfrage die Anzahl der verfügbaren Threads übersteigt, stauen sich die Anfragen in der Warteschlange. Für die Besucher/innen kann es zu langsameren Ladezeiten kommen, obwohl die Website technisch gesehen online ist.
Analysen, die die PHP-Thread-Nutzung verfolgen, machen diese Engpässe sichtbar und zeigen, wann die Anwendung an ihre Verarbeitungsgrenzen stößt.
Cache-Effizienz
Caching spielt eine wichtige Rolle für die Leistung von WordPress. Wenn Seiten im Cache gespeichert werden, kann der Server sie sofort ausliefern, ohne WordPress zu starten oder die Datenbank abzufragen.
Betriebsanalysen, die die Cache-Hit- und -Miss-Quoten anzeigen, verraten, ob das Caching wie erwartet funktioniert. Ein plötzlicher Anstieg der Cache-Misses deutet oft darauf hin, dass unnötig dynamische Anfragen generiert werden, was die Serverlast erhöhen und die Auslieferung der Seiten verlangsamen kann.
Fehlerverfolgung und Antwortcodes
Server-Antwortcodes und Fehlerprotokolle liefern eine weitere wichtige Ebene von Diagnosedaten.
Durch die Überwachung von HTTP-Antworten wie 500-Fehlern sowie PHP-Warnungen oder Anwendungsfehlern können fehlerhafte Prozesse schnell aufgedeckt werden. In vielen Fällen weisen diese Signale direkt auf ein fehlerhaftes Plugin, einen Themenkonflikt oder ein Skript hin, das das Problem verursacht.
Warum Analysen auf Hosting-Ebene die Ursachen und nicht die Symptome aufdecken
Front-End-Analysetools zeigen, was Besucher nach dem Laden einer Website erleben. Hosting-Analysen zeigen, was innerhalb des Systems passiert, bevor die Ergebnisse in den Metriken für die Nutzer erscheinen.
Da sie die Infrastruktur selbst beobachten, können Analysen auf Hosting-Ebene Veränderungen in der Leistung der Website mit den Aktivitäten in Verbindung bringen, die sie verursacht haben.
Diese Transparenz macht es viel einfacher, verschiedene Dinge zu erkennen.
- Korrelation von Trafficspitzen mit der Nutzung von Serverressourcen: Wenn der Datentraffic plötzlich zunimmt, können Serverressourcen wie CPU, Speicher oder PHP-Threads überlastet sein. Mit Hosting-Analysen lässt sich feststellen, ob die steigende Nachfrage direkt mit einer Leistungsverlangsamung einhergeht.
- Erkennen, wann nicht zwischengespeicherte Anfragen die Verarbeitungslast erhöhen: Wenn zwischengespeicherte Seiten nicht mehr korrekt bedient werden, muss der Server jede Seite dynamisch generieren. Analysen, die das Cache-Verhalten verfolgen, können aufzeigen, wann nicht gecachte Anfragen mehr Rechenleistung verbrauchen.
- Langsame PHP-Ausführung oder Datenbankprobleme erkennen: Einige Leistungsprobleme sind auf ineffizienten Code oder Datenbankabfragen zurückzuführen. Metriken auf Infrastrukturebene helfen dabei, langsame Ausführungsmuster zu erkennen, die in Standard-Analyse-Dashboards nicht auftauchen würden.
- Früheres Erkennen von Bot-Traffic oder bösartigen Anfragen: Automatisierter Datentraffic kann große Mengen an Anfragen generieren, lange bevor dies in Besucherberichten ersichtlich wird. Hosting-Analysen machen es einfacher, ungewöhnliche Traffic-Muster zu erkennen und zu reagieren, bevor die Leistung nachlässt.
Mit diesem Maß an Transparenz ist die Analyse nicht mehr nur ein Berichtswerkzeug, sondern zeigt dir aktiv an, welche Komponente des Systems sich verändert hat, sodass du die Ursache direkt untersuchen kannst.
Neuausrichtung der Analytik als operatives Werkzeug
Viele Unternehmen betrachten Analysen in erster Linie als Marketing-Tool. Teams nutzen Dashboards, um Kampagnen zu verfolgen, die SEO-Leistung zu überwachen und zu analysieren, wie Besucher mit der Website interagieren.
Diese Einblicke sind wertvoll, aber die Analyse kann eine viel umfassendere Rolle spielen.
Wenn die Analysen auch die Systemebene einbeziehen, werden sie zu einem Teil des operativen Instrumentariums, mit dem der Zustand und die Leistung einer WordPress-Website gesteuert werden. Anstatt nur die Ergebnisse zu messen, helfen die Daten den Teams zu verstehen, wie sich die Anwendung und die Infrastruktur unter realen Bedingungen verhalten.
Diese Art von Einblick in den Betrieb hilft den Teams:
- Leistungsprobleme schnell zu erkennen
- Die Grenzen der Infrastruktur zu verstehen
- Probleme zu erkennen, bevor sie zu Ausfällen führen
- Fundierte Entscheidungen zur Skalierung zu treffen
Wenn Analysen diesen Grad an Systemtransparenz bieten, werden sie Teil des täglichen Managements einer WordPress-Umgebung und sind nicht nur eine weitere Reihe von Berichts-Dashboards, die man sich regelmäßig ansieht.
Wie Managed Hosting-Analysen für mehr Transparenz sorgen
Moderne Managed-Hosting-Plattformen bieten zunehmend Analysen, die über grundlegende Berichte zur Betriebszeit und zum Traffic hinausgehen. Statt nur oberflächliche Metriken anzuzeigen, zeigen sie, wie sich die Infrastruktur, die eine WordPress-Website unterstützt, unter realen Trafficbedingungen verhält.
Diese Art von Transparenz hilft den Teams, die Probleme auf der Benutzerseite mit den Vorgängen im System in Verbindung zu bringen.
Nützliche Analysen auf Hosting-Ebene umfassen oft Daten wie:
- Trends beiAnfragen und Bandbreiten: Sie zeigen, wie sich das Trafficaufkommen im Laufe der Zeit verändert und wie viele Anfragen der Server in Spitzenzeiten verarbeitet.
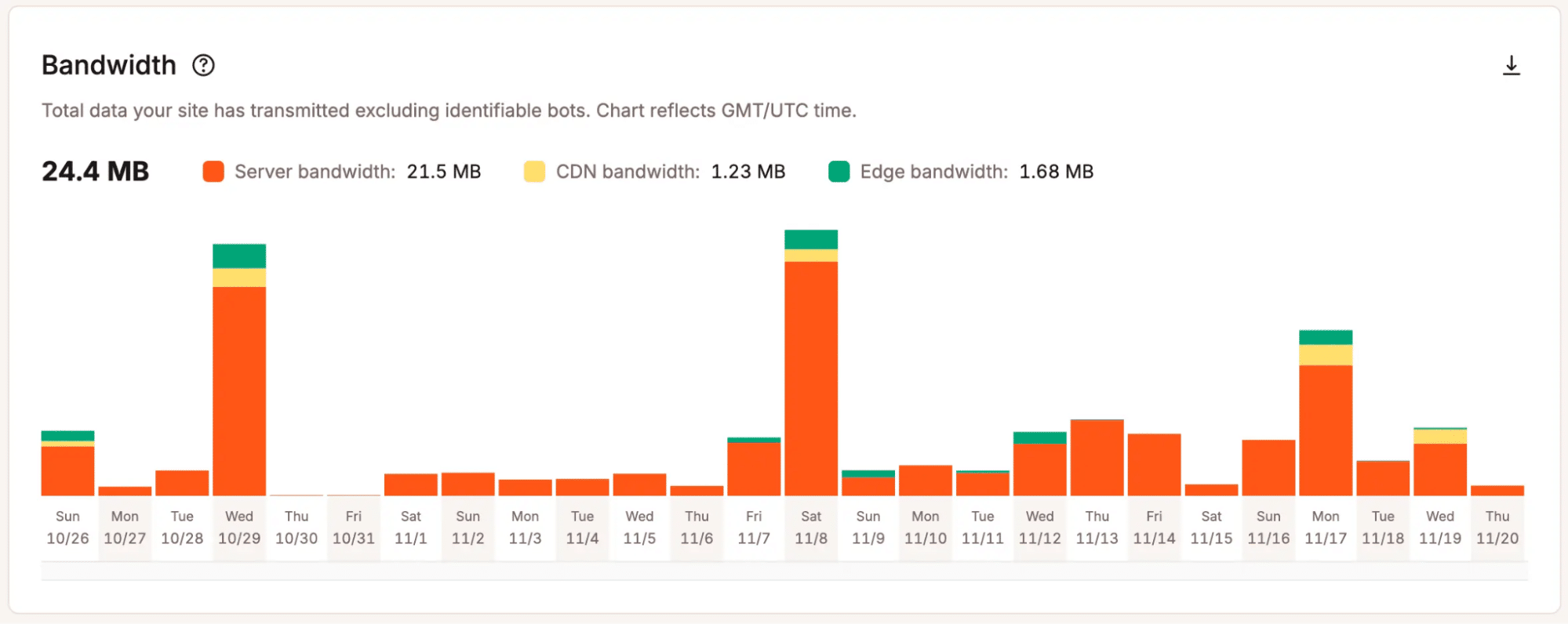
Bandbreitennutzung in MyKinsta anzeigen - Cache-Leistungsdaten: Zeigt an, ob die Seiten effizient aus dem Cache ausgeliefert werden oder ob dynamische Anfragen die Verarbeitungslast erhöhen.
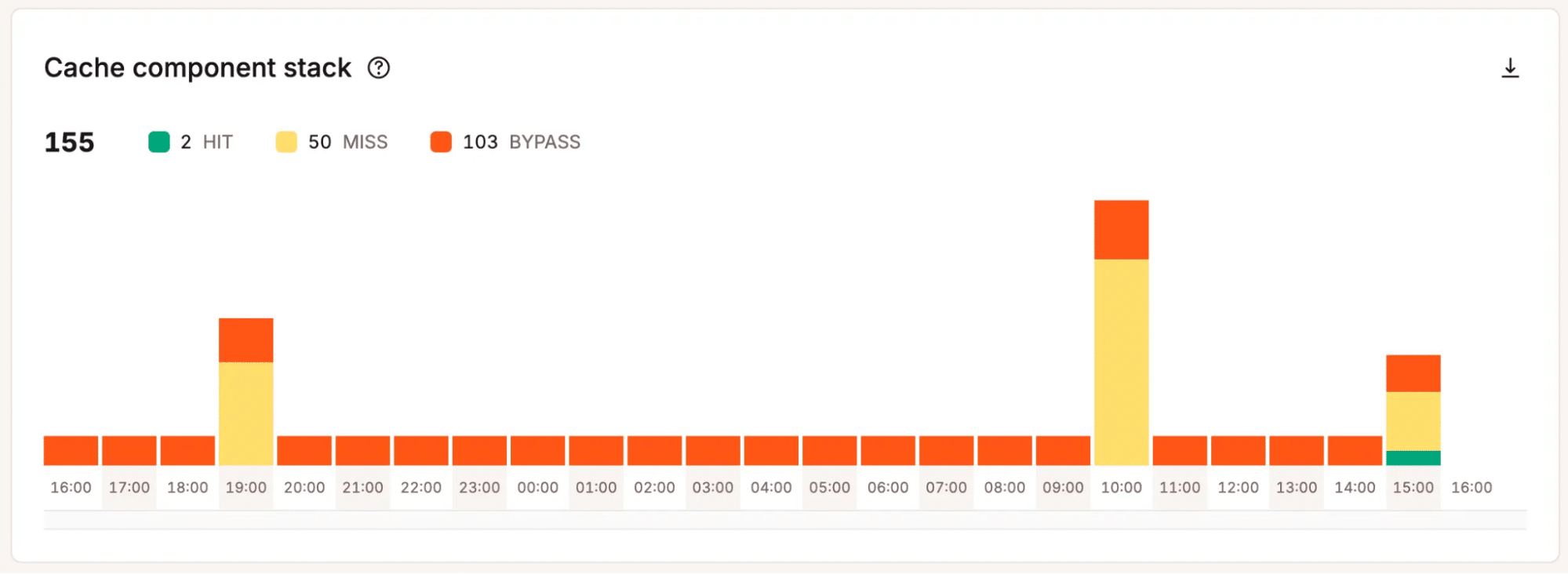
Erhalte Einblicke in die Cache-Leistung in MyKinsta - PHP-Thread-Aktivität: Zeigt an, wie stark WordPress die verfügbaren PHP-Threads nutzt und ob sich die Anfragen in der Warteschlange stauen.
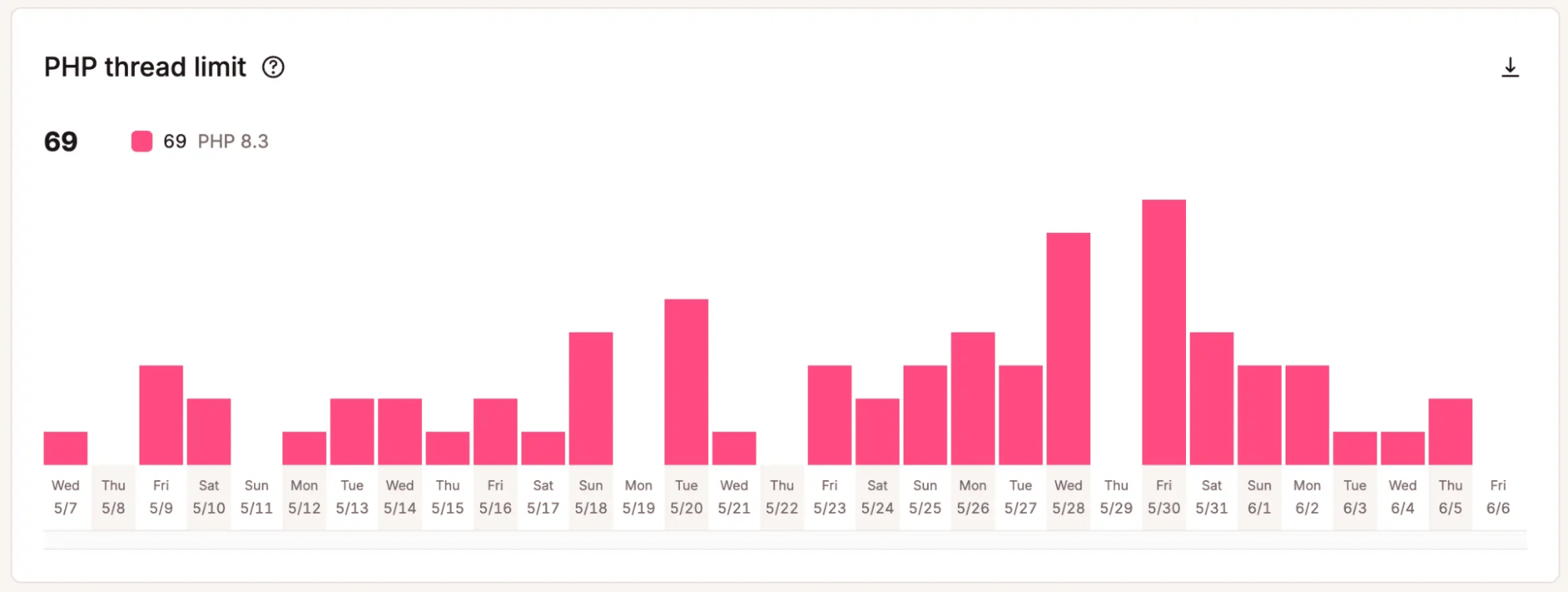
Erhalte einen Einblick in die PHP-Thread-Aktivität in MyKinsta - Datenbank-Nutzungsmuster: Zeigt die Abfrageaktivität und die Datenbankauslastung an, wodurch ineffizienter Code oder das Verhalten von Plugins aufgedeckt werden kann.
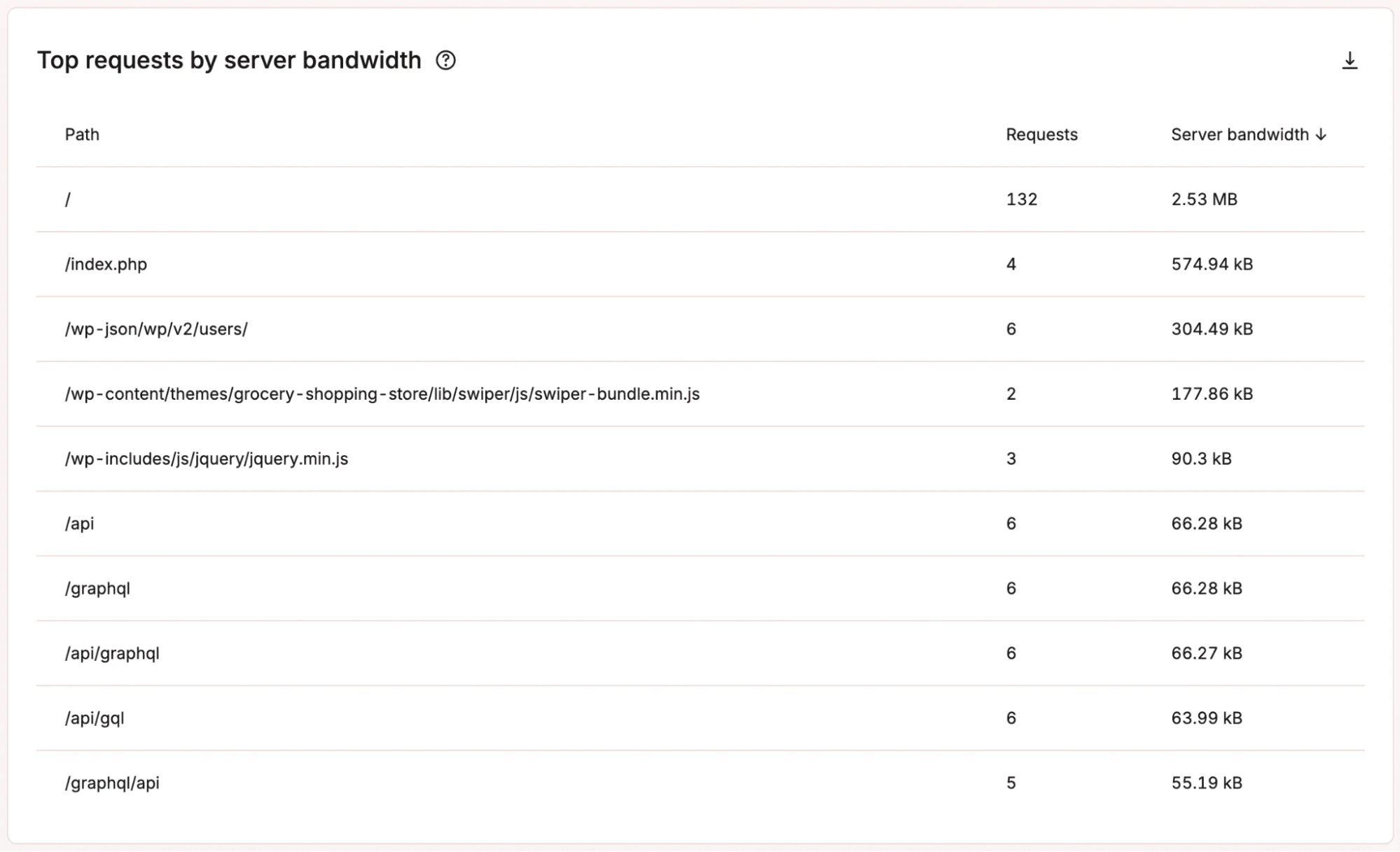
Die Top-Anfragen nach Serverbandbreite in MyKinsta anzeigen - Antwortcode-Überwachung: Verfolgt die HTTP-Statuscodes, um Fehler oder fehlgeschlagene Prozesse aufzudecken, bevor sie sich zu größeren Problemen auswachsen.
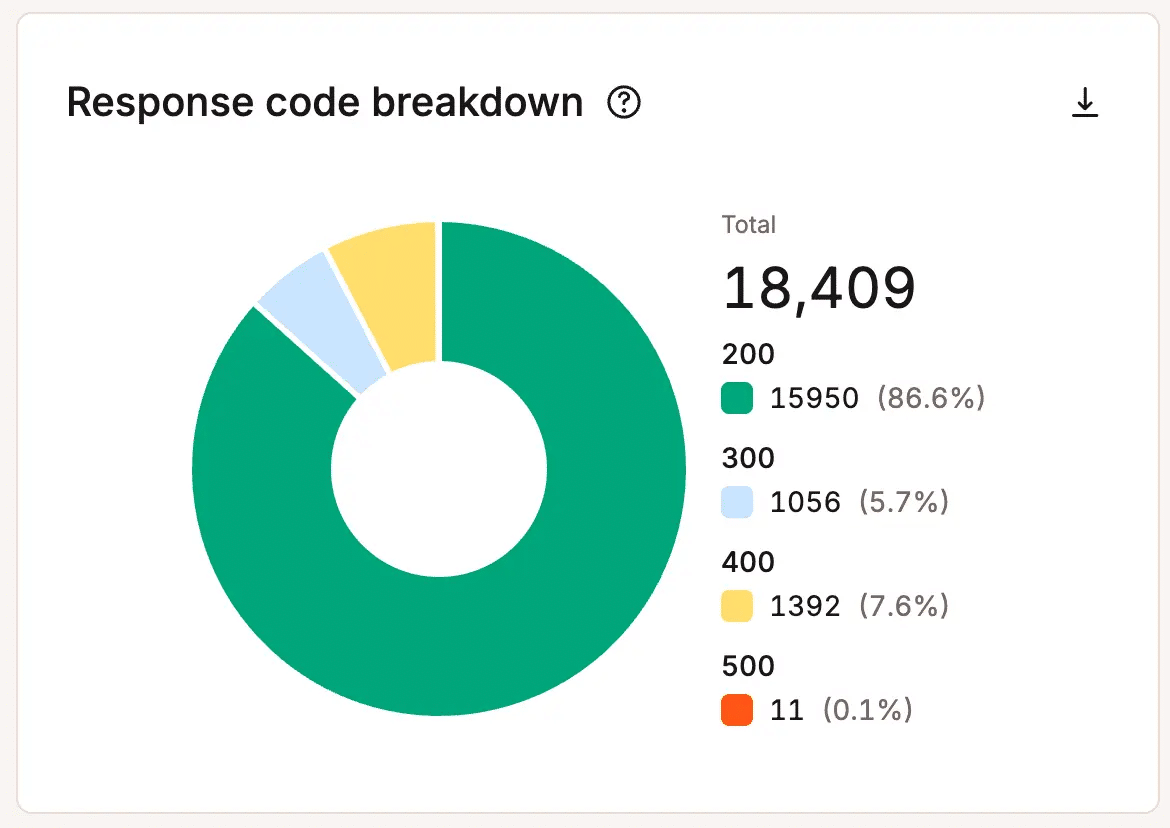
Verfolge HTTP-Statuscodes, um Fehler zu erkennen, bevor sie größere Probleme verursachen - Geografische Verteilung des Datentraffics: So kannst du feststellen, woher die Anfragen kommen und ob ungewöhnliche Trafficmuster die Leistung beeinträchtigen.
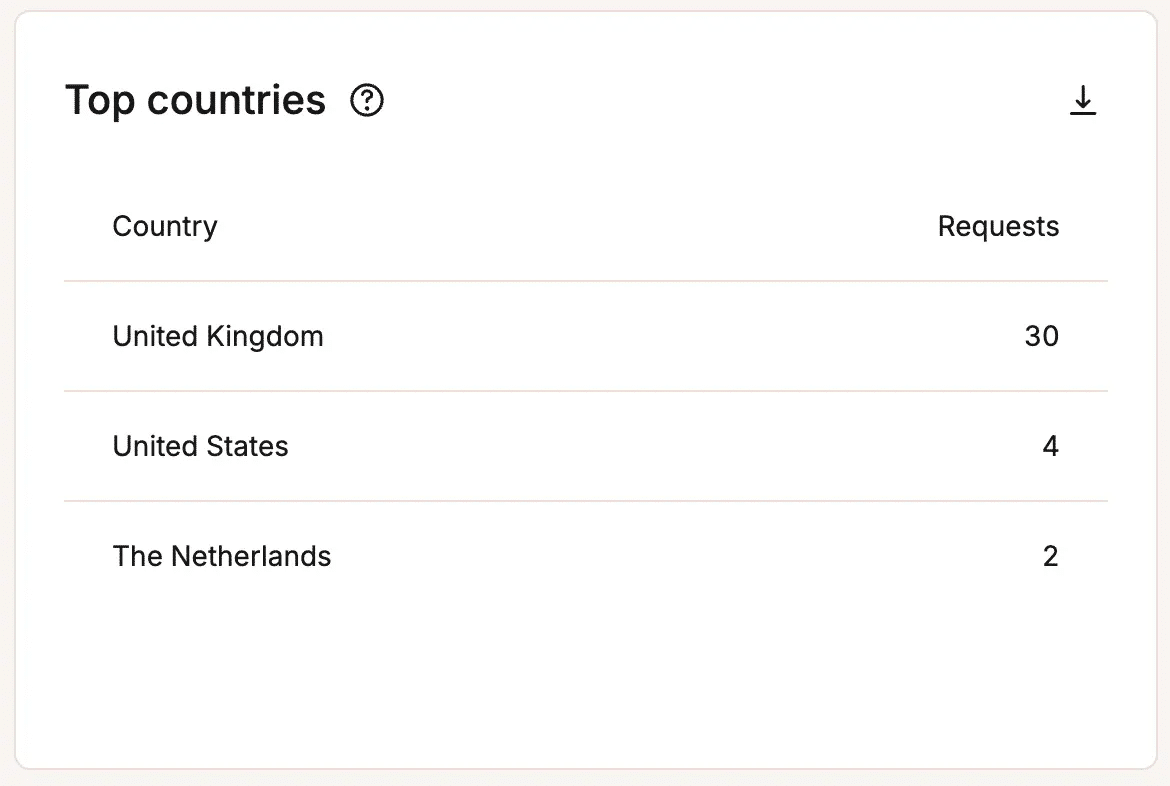
Identifiziere die geografische Verteilung des Datentraffics in MyKinsta
Das MyKinsta-Dashboard ist auf diese Art von Transparenz auf Infrastrukturebene ausgelegt. Anstatt das Hosting als Blackbox zu betrachten, zeigt es Betriebskennzahlen an, die Aufschluss darüber geben, wie eine WordPress-Website mit der zugrunde liegenden Plattform interagiert.
Mehr zu diesen Analysen findest du in unserer Dokumentation. Website-Betreiber und Entwicklungsteams können über die oberflächliche Berichterstattung hinausgehen und Leistungsänderungen direkt in der Hosting-Umgebung diagnostizieren.
Reines Wissen reicht nicht aus – entscheidend ist dasWarum
Die meisten Analysetools sind hervorragend darin, Ergebnisse anzuzeigen. Aber wenn Leistungseinbrüche oder Zuverlässigkeitsprobleme auftreten, erzählen diese Berichte nur einen Teil der Geschichte.
Plattformen wie Kinsta machen diese Art von Einblick leichter zugänglich. Die im MyKinsta-Dashboard verfügbaren Analysen zeigen, wie sich eine WordPress-Website auf der Infrastrukturebene verhält, und geben Entwicklern, Agenturen und Website-Betreibern einen besseren Einblick in die Leistung und Zuverlässigkeit.
Wenn du Analysen möchtest, die nicht nur erklären, was passiert ist, sondern auch warum, solltest du dir die Managed WordPress Hosting-Pakete von Kinsta genauer ansehen. Es gab nie einen besseren Zeitpunkt als jetzt, um die Kontrolle über den Betrieb deiner Website zu übernehmen.

Joel ist Frontend-Entwickler und arbeitet bei Kinsta als Technical Editor. Er ist ein leidenschaftlicher Lehrer mit einer Vorliebe für Open Source und hat über 200 technische Artikel geschrieben, die sich hauptsächlich um JavaScript und seine Frameworks drehen.

