
Une augmentation du trafic devrait normalement être synonyme de succès, mais dans la pratique, ce n’est souvent pas le cas. De nombreux sites web enregistrent une hausse du nombre de visites, tandis que les conversions, l’engagement et le chiffre d’affaires stagnent, ce qui amène les équipes à se demander pourquoi cette « croissance » ne ressemble en rien à une véritable croissance.
L’une des raisons est que tout le trafic ne provient pas de personnes réelles. L’activité automatisée représente désormais une part importante du Web moderne. En effet, le rapport Imperva Bad Bot Report 2025 a révélé que les systèmes automatisés représentaient 51 % de l’ensemble du trafic Web en 2024, ce qui signifie que, pour la première fois en dix ans, les robots ont généré collectivement plus de requêtes que les visiteurs humains.
Lorsque le trafic automatisé se mêle aux rapports d’analyse, le simple nombre brut de visites ne constitue plus une mesure fiable de l’intérêt ou de la demande réels de l’audience.
Cet article explique comment faire la distinction entre les visiteurs authentiques d’un site, l’automatisation utile et l’activité nuisible des robots.
Qu’est-ce que le trafic de robots ?
Le trafic de robots désigne les requêtes effectuées par des logiciels automatisés plutôt que par un humain utilisant un navigateur. Ces programmes envoient des requêtes vers des pages web, des images, des scripts ou des API de la même manière que le ferait le navigateur d’un visiteur, mais cette activité se déroule sans interaction humaine directe.
D’un point de vue technique, le serveur perçoit souvent le même type de requête. La différence réside dans la manière dont la requête est générée et dans son comportement au fil du temps.
L’automatisation n’est ni inhabituelle ni intrinsèquement nuisible. Une grande partie d’Internet repose sur des systèmes automatisés qui explorent en permanence les sites web, vérifient leur disponibilité, valident leurs performances ou récupèrent des données pour des services légitimes. Les moteurs de recherche s’appuient sur des robots pour découvrir et indexer de nouveaux contenus, les outils de surveillance testent régulièrement la disponibilité, et diverses intégrations interrogent des API pour maintenir la synchronisation des applications.
Il est important de noter que le terme « robot » décrit la manière dont le trafic est généré, et non la raison de son existence. Certains systèmes automatisés favorisent la visibilité et la sécurité, tandis que d’autres tentent d’exploiter des vulnérabilités, de récupérer du contenu ou de surcharger l’infrastructure. Étant donné que les intentions varient considérablement, il est bien plus utile d’identifier et de classer les comportements des robots que de traiter l’ensemble du trafic automatisé comme une seule et même catégorie.
Les trois types de trafic qui affectent votre site
Le trafic web est souvent présenté comme une simple distinction entre « humain » et « robot », mais en réalité, la plupart des requêtes se répartissent en trois catégories pratiques : les visiteurs réels, les robots utiles et les robots nuisibles. Comprendre cette distinction facilite l’interprétation des analyses, la gestion des ressources et la mise en place des contrôles de sécurité appropriés sans perturber l’activité légitime.
Comme nous l’avons mentionné précédemment, le rapport Imperva Bad Bot a souligné que le trafic automatisé représentait plus de la moitié de toutes les requêtes web à l’échelle mondiale, une part importante étant classée soit comme automatisation bénéfique, soit comme activité malveillante de robots. Lorsque ces différentes sources sont combinées, le volume de trafic à lui seul ne fournit que peu d’informations sur la demande ou l’engagement réels des utilisateurs.
L’objectif n’est pas de bloquer tout ce qui semble automatisé, mais d’identifier quelles requêtes proviennent de personnes réelles, lesquelles soutiennent la fonctionnalité et la visibilité du site, et lesquelles créent un risque ou une charge inutile.
L’analyse des modèles de comportement, des caractéristiques des requêtes et des sources de trafic peut vous apporter la clarté nécessaire pour autoriser l’automatisation bénéfique, vous protéger contre les activités nuisibles et évaluer les performances à l’aide de données reflétant le comportement réel des utilisateurs.
Véritables visiteurs : à quoi ressemble le trafic humain
Le trafic humain a tendance à suivre des schémas irréguliers et imprévisibles. Les visiteurs réels naviguent sur les sites de différentes manières. Ils cliquent sur différents chemins de navigation, s’attardent sur certaines pages, font défiler le contenu à des profondeurs variables et passent des durées inégales avant de passer à l’action suivante. Même lorsque plusieurs visiteurs proviennent d’une même campagne ou d’une même région, leur comportement suit rarement des séquences identiques.
Les sessions utilisateur authentiques comportent également des schémas d’interaction réalistes. Les actions telles que les recherches sur le site, les envois de formulaires, la lecture de médias, les connexions à un compte ou les activités de commerce électronique se produisent généralement selon une progression logique plutôt qu’à des intervalles parfaitement synchronisés ou répétés. Le délai entre les requêtes varie naturellement, reflétant la manière dont les gens lisent, réfléchissent et décident de la suite des évènements.
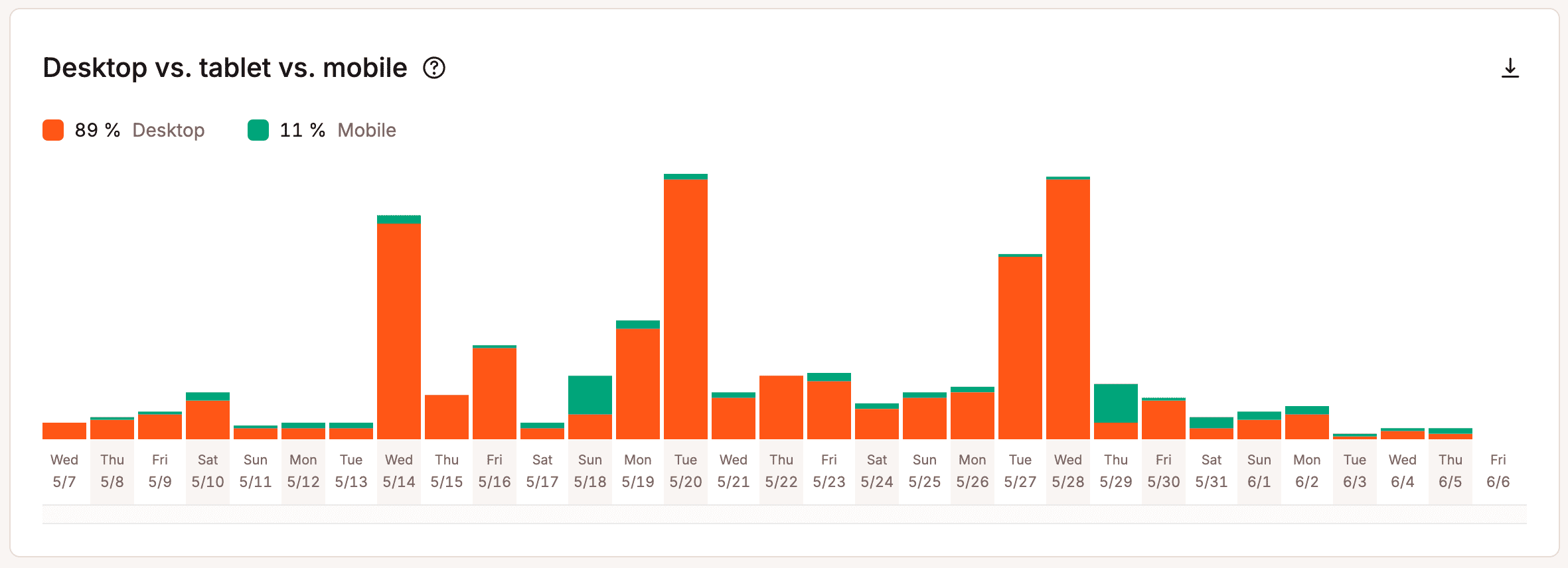
Avec MyKinsta, vous pouvez rapidement voir d’un seul coup d’œil quelles pages génèrent le plus de trafic :

La diversité des appareils est un autre indicateur fort du trafic humain. Les visiteurs réels accèdent à votre site en utilisant un large éventail de navigateurs, de systèmes d’exploitation, de vitesses de connexion et de tailles d’écran. Même un trafic géographique concentré présente des variations selon les appareils et les configurations, créant une répartition qui est rarement uniforme.
MyKinsta fournit également des informations sur l’utilisation des appareils :
Dans le même temps, l’identification du trafic humain n’est pas toujours simple. Les mesures de protection de la vie privée, les bloqueurs de publicités, les couches de mise en cache et les environnements réseau partagés peuvent masquer certains signaux ou faire apparaître différents utilisateurs comme similaires au niveau de l’infrastructure.
C’est pourquoi la classification du trafic fonctionne mieux lorsque plusieurs indicateurs, notamment les modèles de comportement, les caractéristiques de session, la diversité des appareils et les signaux d’interaction dont nous avons parlé, sont évalués conjointement plutôt que de se fier à un seul indicateur.
Les robots utiles : une automatisation au service de votre site
Tout le trafic automatisé ne doit pas nécessairement être bloqué. De nombreux robots jouent un rôle essentiel pour assurer la visibilité, la surveillance et le bon fonctionnement de votre site web.
Les robots d’indexation des moteurs de recherche
Il s’agit de l’un des exemples les plus importants. Ces robots interrogent systématiquement les pages afin de découvrir de nouveaux contenus, d’évaluer les modifications et de mettre à jour les index de recherche.
Leur comportement est généralement structuré et prévisible : ils suivent les liens de manière méthodique et respectent les directives d’exploration définies dans le fichier robots.txt. Empêcher ces robots d’accès d’accéder à votre site peut réduire votre visibilité dans les résultats de recherche et retarder l’apparition des nouvelles pages dans ces résultats.
Services de surveillance de la disponibilité et de test
D’autres automatisations légitimes se concentrent sur la surveillance et la santé opérationnelle. Les outils de surveillance de la disponibilité, les vérificateurs de performances et les services de tests synthétiques envoient des requêtes à intervalles réguliers pour confirmer la disponibilité, mesurer les temps de chargement et détecter les défaillances à un stade précoce.
Outils de référencement et de validation
De même, les outils de référencement, d’accessibilité et de validation analysent les pages afin d’identifier les problèmes techniques, les liens rompus ou les problèmes de conformité qui pourraient autrement passer inaperçus.
Les robots utiles signalent généralement clairement leur présence. Ils s’identifient souvent à l’aide de chaînes d’agent utilisateur cohérentes, opèrent dans des limites de requêtes définies et respectent les politiques d’exploration publiées.
Comme ces systèmes prennent en charge l’indexation, l’observabilité et les intégrations, leur blocage sans examen préalable peut interrompre les flux de travail de surveillance, réduire la visibilité ou perturber les services qui dépendent de requêtes automatisées planifiées.
Les robots nuisibles : un trafic source de risques ou de gaspillage
Les robots nuisibles sont des systèmes automatisés conçus pour exploiter des sites web, extraire des données à grande échelle ou consommer des ressources d’infrastructure sans apporter de valeur légitime. Contrairement aux automatisations utiles, ces robots tentent généralement de dissimuler leur identité, ignorent les règles d’exploration et génèrent des modèles de requêtes destinés à contourner les protections de base.
Les robots de « credential stuffing » et de force brute
Ils comptent parmi les menaces les plus courantes. Ces systèmes ciblent de manière répétée les points de connexion, testant en succession rapide de longues listes de noms d’utilisateur et de mots de passe volés afin d’obtenir un accès non autorisé. Même en cas d’échec, le volume de requêtes peut augmenter la charge du serveur et ralentir les temps de réponse pour les utilisateurs légitimes.
Scanners de vulnérabilités et scrapers
D’autres automatisations malveillantes se concentrent sur la découverte et l’exploitation. Les scanners de vulnérabilité sondent les répertoires connus, les fichiers de configuration et les points d’accès logiciels afin de rechercher des composants obsolètes ou des erreurs de configuration susceptibles d’être exploités. Des robots de scraping agressifs peuvent également demander de grands volumes de pages ou de fichiers multimédias afin de copier du contenu pour le republier ailleurs, consommant ainsi de la bande passante et de la capacité d’infrastructure.
Attaques DDoS
Certaines attaques visent purement à perturber le système plutôt qu’à y accéder. Les campagnes de saturation du trafic et de déni de service tentent de submerger les serveurs ou les couches applicatives par des pics de requêtes soutenus, dégradant ainsi les performances ou rendant les services temporairement indisponibles.
Au-delà de son impact immédiat sur les performances, le trafic de robots nuisibles peut fausser les analyses et dégrader l’expérience des visiteurs réels s’il n’est pas géré.
Comment distinguer les humains, les robots utiles et les robots nuisibles
La distinction entre les visiteurs réels, l’automatisation utile et les robots nuisibles repose moins sur un identifiant unique que sur la reconnaissance de schémas de comportement cohérents à travers plusieurs signaux.
Évalués conjointement, ces indicateurs permettent de déterminer plus facilement si le trafic reflète une activité humaine, une automatisation légitime ou des requêtes potentiellement abusives.
Fréquence et timing des requêtes
Les visiteurs humains génèrent des requêtes à des intervalles irréguliers lorsqu’ils lisent, font défiler et naviguent, tandis que les systèmes automatisés ont tendance à demander des pages à des vitesses très régulières ou par rafales rapides qu’il serait difficile pour une personne de reproduire. Des taux de requêtes extrêmement élevés provenant d’une seule source ou à des intervalles parfaitement synchronisés indiquent généralement une activité scriptée.
Chaînes d’agent utilisateur
Les robots légitimes s’identifient généralement de manière claire et cohérente, tandis que les robots malveillants changent fréquemment d’agent utilisateur ou usurpent leur identité afin de paraître humains. La comparaison des déclarations d’agent utilisateur avec le comportement observé permet de mettre en évidence des incohérences indiquant une automatisation.
Réputation IP et propriété du réseau
Le trafic provenant de réseaux d’hébergement cloud connus, de services proxy ou d’adresses précédemment signalées peut indiquer la présence de systèmes automatisés plutôt que de véritables personnes. Les bases de données de réputation et les outils de sécurité classent ces réseaux en fonction de leur activité passée et aident à identifier plus rapidement les sources suspectes.
Modèles de répartition géographique
Une augmentation soudaine du trafic provenant de régions inattendues, en particulier lorsqu’elle s’accompagne d’un comportement de requêtes identique, peut suggérer une activité coordonnée de bots plutôt qu’une véritable croissance de l’audience.
Respect du fichier robots.txt et des limites d’exploration
Si vous remarquez cela, c’est un indicateur fort d’automatisation légitime. Les robots utiles respectent généralement les politiques d’exploration publiées et opèrent dans des limites de requêtes raisonnables, tandis que les robots nuisibles ignorent généralement ces directives et continuent à demander des chemins ou des fichiers restreints.
Comme aucun de ces signaux ne fournit à lui seul une réponse complète, une classification efficace repose sur l’analyse conjointe de plusieurs indicateurs. Au fil du temps, ces modèles combinés permettent de déterminer de manière fiable si le trafic entrant provient d’utilisateurs réels, d’une automatisation bénéfique ou d’une activité nécessitant un filtrage ou une atténuation.
Où analyser le trafic des robots
Pour comprendre l’activité des robots, il faut disposer d’une visibilité sur plusieurs couches de votre infrastructure d’hébergement et de diffusion. Aucun outil ne donne à lui seul une vue d’ensemble complète, c’est pourquoi la combinaison d’outils d’analyse, de journaux et de tableaux de bord de sécurité permet d’obtenir des informations bien plus fiables. Examinons chacun d’entre eux :
Les plateformes d’analyse constituent un point de départ de haut niveau
Les pics de trafic sans engagement correspondant, les anomalies géographiques soudaines ou les répartitions inhabituelles des appareils signalent souvent une activité automatisée. Bien que les outils d’analyse ne classifient pas toujours les robots avec précision, ils aident à mettre en évidence des tendances qui indiquent la nécessité d’une enquête plus approfondie. Même des extensions simples comme Jetpack peuvent vous aider dans ce domaine.
Les journaux de serveur et d’accès offrent la vue la plus détaillée du comportement des requêtes
Les journaux révèlent la fréquence des requêtes, les codes de réponse, les chaînes d’agent utilisateur, les adresses IP et les chemins d’accès, ce qui vous permet d’identifier des schémas de balayage répétés, des tentatives d’attaques par connexion ou des comportements de scraping qui, autrement, resteraient cachés dans les données analytiques agrégées.
Les tableaux de bord CDN ajoutent un niveau supplémentaire de visibilité
Les tableaux de bord CDN affichent les modèles de trafic à la périphérie du réseau avant que les requêtes n’atteignent votre serveur d’origine. Ces tableaux de bord mettent souvent en évidence les pics de trafic, les anomalies régionales ou les requêtes automatisées répétées qui sont filtrées ou limitées en débit en amont. Cela vous aide à détecter les attaques bien plus tôt que vous ne le pourriez autrement.
Les pare-feu et les outils WAF fournissent des informations en temps réel
Les pare-feu vous permettent de connaître en temps réel les requêtes bloquées, contestées ou suspectes. L’examen des journaux de pare-feu peut révéler quelles sources de trafic déclenchent les règles de sécurité et si des ajustements sont nécessaires pour réduire les faux positifs ou renforcer les protections.
Les plateformes d’hébergement infogéré simplifient le processus en consolidant plusieurs de ces sources de données. Par exemple, les environnements qui intègrent des analyses au niveau du CDN, la surveillance des pare-feu et les journaux d’accès dans un tableau de bord unique facilitent la corrélation des comportements suspects entre les différentes couches.
Les fournisseurs d’hébergement tels que Kinsta mettent également en avant les analyses de trafic, la surveillance des performances et les données relatives aux événements de sécurité directement au sein de leur tableau de bord, MyKinsta. Cela signifie que vous et votre équipe pouvez analyser le comportement des robots sans avoir à recourir à de multiples outils externes.
Comment le trafic généré par les robots fausse les analyses et la prise de décision
Lorsque les requêtes automatisées se mêlent aux visites légitimes, les données analytiques commencent à refléter une activité qui ne correspond pas à l’intérêt réel de l’audience. Le nombre de pages vues et de sessions peut sembler augmenter régulièrement, même si l’engagement réel, les conversions ou les revenus restent inchangés. Sans distinguer le trafic automatisé des sessions humaines, vous risquez d’interpréter ces chiffres gonflés comme une croissance et de prendre des décisions stratégiques sur la base de signaux trompeurs.
Les indicateurs d’engagement deviennent particulièrement peu fiables. Les robots génèrent souvent des sessions d’une durée extrêmement courte, des sorties immédiates ou des requêtes de pages répétées, ce qui peut augmenter ou diminuer artificiellement le taux de rebond et le temps passé sur la page. Dans certains cas, les robots de scraping sollicitent de manière répétée des pages spécifiques, donnant l’impression que certains contenus obtiennent de bien meilleurs résultats qu’ils ne le font réellement auprès des utilisateurs réels.
Les données géographiques, relatives aux appareils et aux sources de trafic peuvent également être faussées. Le trafic automatisé provient souvent de centres de données, de réseaux de proxies ou de régions concentrées qui ne correspondent pas à la base de clients réelle du site. Lorsque ces sessions sont incluses dans les rapports, les équipes marketing peuvent investir dans les mauvaises régions, optimiser en fonction de tendances d’appareils erronées ou mal interpréter les performances des campagnes.
Au fil du temps, ces inexactitudes affectent les rapports, la planification des performances, les décisions relatives à l’évolutivité de l’infrastructure et les investissements marketing. Tous ces éléments s’appuient sur l’analyse du trafic pour prévoir la demande. Si une part importante de ce trafic est constituée de requêtes automatisées, les entreprises risquent de surestimer la croissance, d’allouer leurs ressources de manière inefficace ou de négliger le comportement réel des utilisateurs qui nécessite une attention particulière.
Meilleures pratiques pour gérer les différents types de trafic
La gestion du trafic web moderne nécessite une approche équilibrée qui protège les performances du site sans interférer avec l’automatisation légitime ou les utilisateurs réels. Plutôt que de tenter de bloquer tout ce qui semble automatisé, l’objectif est d’appliquer des politiques qui correspondent au comportement et à l’intention de chaque type de trafic.
Donner la priorité à l’expérience utilisateur réelle
Optimisez les performances, la disponibilité et l’accessibilité afin que les visiteurs légitimes puissent accéder au contenu rapidement et de manière fiable, même lors des pics de trafic. Des temps de chargement rapides, une infrastructure stable et une mise en cache résiliente contribuent à garantir que les utilisateurs légitimes ne soient pas affectés lorsque le trafic automatisé augmente. Vous pouvez optimiser les performances directement au sein de Kinsta en utilisant l’API Kinsta avec Google PageSpeed Insights.
Autoriser et surveiller les automatisations utiles
Les robots d’indexation des moteurs de recherche, les outils de surveillance de la disponibilité et les outils de validation doivent être explicitement autorisés lorsque cela est approprié, afin que l’indexation, la surveillance et les intégrations continuent de fonctionner correctement. L’examen périodique du comportement d’exploration permet de s’assurer que les robots légitimes opèrent dans des limites raisonnables.
Appliquer des protections basées sur le comportement au trafic nuisible
Les limites de débit, les défis de sécurité et les règles de blocage ciblées fonctionnent mieux lorsqu’ils sont déclenchés par des modèles de requêtes suspects plutôt que par des hypothèses statiques concernant les plages d’adresses IP ou les agents utilisateurs. Les contrôles comportementaux réduisent le risque de bloquer des services légitimes tout en continuant à atténuer les activités abusives.
Réviser et ajuster régulièrement les politiques
Les modèles de trafic évoluent à mesure que les sites se développent, que des campagnes sont lancées et que de nouveaux systèmes automatisés interagissent avec le contenu. Des revues périodiques des règles de pare-feu, des limites de débit et des alertes de surveillance permettent de s’assurer que les protections correspondent à votre comportement de trafic actuel, plutôt que de s’appuyer sur des hypothèses obsolètes.
Utiliser les informations sur la source du trafic pour prendre de meilleures décisions
Le volume de trafic à lui seul donne rarement une image complète des performances d’un site web. Lorsque les visites humaines, l’automatisation utile et l’activité nuisible des robots sont séparées, les données analytiques deviennent bien plus significatives et exploitables.
Une segmentation claire du trafic permet aux équipes de mesurer la croissance réelle de l’audience, de comprendre les véritables modèles d’engagement et d’évaluer les performances marketing sans que le bruit généré par l’automatisation ne fausse les résultats.
Une classification plus précise du trafic améliore également les décisions opérationnelles. La planification des performances, la mise à l’échelle de l’infrastructure et les stratégies de sécurité s’alignent plus facilement sur la demande réelle lorsque les requêtes automatisées sont mesurées et gérées de manière indépendante.
Si votre environnement d’hébergement actuel offre une visibilité limitée sur les sources de trafic, il peut être intéressant d’évaluer des plateformes proposant des informations plus approfondies sur le trafic et des outils intégrés de gestion des robots. Les environnements infogérés tels que Kinsta fournissent des analyses intégrées, des protections par pare-feu et des informations sur le trafic au niveau de la périphérie qui aident à distinguer les utilisateurs réels de l’activité automatisée.
Les nouveaux plans d’hébergement basés sur la bande passante de Kinsta offrent également davantage de flexibilité en adaptant plus étroitement les ressources d’hébergement à la consommation réelle de trafic. Si vous avez des questions, vous pouvez contacter notre équipe de support à tout moment.

Joel est un développeur d'interfaces publiques qui travaille chez Kinsta en tant que rédacteur technique. Il est un enseignant passionné par l'open source et a écrit plus de 200 articles techniques, principalement autour de JavaScript et de ses frameworks.

