
Avec sa part de marché croissante, WordPress a été – et continue d’être – le CMS le plus populaire pour créer, gérer et développer des sites web.
Pourtant, WordPress ne représente qu’une fraction du développement effectué sur le web. Qu’en est-il de tous les développeurs qui n’utilisent pas WordPress ? Ils créent, exécutent et gèrent également des applications web pour leur entreprise, leurs clients, les consommateurs ou eux-mêmes.
Chez Kinsta, nous avons travaillé avec des milliers de développeurs et des centaines d’agences dont les clients ont des projets construits sur WordPress. Beaucoup ont également des projets qui ne sont pas propulsés par le célèbre CMS.
Jusqu’à aujourd’hui, Kinsta se concentrait sur la création de solutions d’hébergement WordPress infogérées – ce qui signifie que les clients (et leurs clients) n’étaient pas en mesure de tirer parti des avantages de notre plateforme pour les projets non-WordPress et d’héberger tous les projets « sous un même toit ». Cela rendait leur travail plus difficile et moins efficace.
Nous avons donc commencé à chercher des moyens de leur faciliter la vie.
Plus nous recevions de commentaires et plus nous parlions de leurs projets avec nos clients et nos bêta-testeurs, plus nous nous rendions compte que nos clients étaient aux prises avec un problème sous-jacent.
Mais il y a un rebondissement : ce n’était pas seulement nos clients.
Nous avons réalisé que ce point douloureux est ressenti par presque tous les développeurs, équipes DevOps et agences qui gèrent des projets web. Tout le monde y est confronté et est désireux de trouver une meilleure solution.
Les développeurs ne devraient pas perdre de temps à s’inquiéter de l’hébergement ; ils devraient se concentrer sur le développement
Quel est le problème ?
Le manque de simplicité d’une plateforme d’hébergement cloud.
Les développeurs veulent livrer leurs applications rapidement. Les développeurs ont besoin d’une plateforme qui leur permette de tout avoir en un seul endroit, sous un même toit.
Une plateforme simple, claire et facile à utiliser, qui ne confine pas le travail de développement à une seule technologie, un seul framework ou une seule bibliothèque.
Une plateforme facile à apprendre et à utiliser dès le premier jour, sans avoir besoin de cours spéciaux ou de certifications spécifiques à la plateforme.
Une plateforme dotée d’un modèle de tarification simple et transparent. (Avez-vous déjà essayé de comprendre la tarification d’AWS ? Un vrai défi !)
Nous savions que l’architecture conteneurisée de Kinsta nous permettrait de répondre à ces besoins et de fournir la plateforme et les outils permettant aux développeurs de faire leur meilleur travail.
En plus de cela, nous savions que nous avions :
- Plus de 8 ans d’expérience dans le secteur de l’hébergement
- Un support inégalé
- Des développeurs et des équipes d’ingénieurs talentueux qui sont capables de résoudre n’importe quel problème technique
- Des équipes DevOps qui n’ont pas leur pareil lorsqu’il s’agit d’orchestrer, de gérer et de mettre à l’échelle notre plateforme d’hébergement
C’est pourquoi nous avons construit nos nouvelles solutions d’hébergement améliorées sur la même plateforme qui rend nos services WordPress si puissants. Maintenant, après plus d’un an de travail acharné impliquant plus de 320 membre de l’équipe Kinsta, plus de 750 bêta-testeurs et d’innombrables itérations, nous l’avons mis à la disposition du public.
Présentation des solutions d’hébergement d’applications et d’hébergement de bases de données
La vision de Kinsta est de changer le statu quo. Nous y parvenons grâce à notre engagement ferme à offrir la meilleure expérience aux développeurs:
Nous évoluons constamment pour offrir des outils et des services de pointe au développeur moderne. Nous nous engageons à offrir la meilleure expérience aux développeurs et aux entreprises, en construisant pour la performance et la facilité d’utilisation.
En ajoutant de nouveaux services à notre offre, les développeurs et les équipes DevOps de toutes formes et tailles ont désormais le choix entre une pléthore de solutions d’hébergement pour leurs applications, bases de données, services et sites WordPress, avec plus de flexibilité que jamais.
Plus précisément, Kinsta offre maintenant :
- Hébergement WordPress infogéré
- Hébergement d’applications – Nouveau !
- Hébergement de bases de données – Nouveau !
Examinons de plus près chacun d’entre eux.
Hébergement WordPress infogéré (en bref)
Grâce à Google Cloud Platform et à son réseau Premium Tier, nous avons créé un service d’hébergement WordPress infogéré qui fournit à plus de 25.000 entreprises et 100.000 sites web tout ce dont ils ont besoin pour fonctionner et se développer.
Grâce à l’utilisation de processeurs haut de gamme et à la disponibilité mondiale des VM C2 optimisées pour le calcul de Google, à 29 centres de données disponibles et au CDN ultra-rapide de Kinsta avec 300 PoP pour servir du contenu statique et dynamique à un public réparti dans le monde entier, les clients qui migrent de n’importe quel hébergeur vers Kinsta constatent une accélération moyenne de 20 % des temps de chargement presque instantanément.

Mais les avantages ne s’arrêtent pas là.
Grâce aux sauvegardes automatiques, à MyKinsta (notre tableau de bord personnalisé et facile à utiliser pour la gestion des sites), à l’outil intégré de surveillance des applications et au pare-feu de niveau entreprise et à la protection DDoS alimentée par Cloudflare, notre solution d’hébergement WordPress info aide les gestionnaires et les développeurs de sites à dormir sur leurs deux oreilles en sachant que leurs sites sont en sécurité.
Ils savent également que Kinsta leur fait économiser des heures de travail chaque mois. Moins de temps passé à effectuer des tâches répétitives mais essentielles signifie moins de frais généraux et moins de coûts de maintenance pour votre entreprise.
Votre entreprise fonctionne sur WordPress ? Vous êtes un développeur WordPress à la recherche d’un hébergeur avec des outils qui peuvent vous aider à rationaliser votre travail ? Découvrez nos solutions d’hébergement WordPress infogéré.
Hébergement d’applications (en bref)
Le développement web vit un moment intéressant qui montre à quel point ce monde est aujourd’hui articulé, nuancé et complexe. Notre nouvelle solution d’hébergement d’applications simplifie le travail des développeurs web modernes.
Nous le simplifions en vous libérant de la mise en place de conteneurs, de la gestion des serveurs, des soucis liés au système d’exploitation, de la gestion des sauvegardes, de l’installation de certificats SSL et de l’ajout de domaines personnalisés – tout ce qui pourrait vous empêcher de vous concentrer exclusivement sur le développement.
Nous avons construit une plateforme de développement conçue pour vous aider à livrer vos applications aux utilisateurs le plus rapidement possible.
L’hébergement d’applications de Kinsta est ce que le marché appelle habituellement une plateforme en tant que service (Platform as a Service ou Paas), avec des outils qui rendent le déploiement de vos applications rapide et facile à partir de services d’hébergement de code comme GitHub et la capacité de les faire fonctionner sans problème dans un environnement optimisé qui est construit pour évoluer.
Comment déployer une application sur Kinsta
Nos ingénieurs et chefs de produit se sont concentrés sur l’élaboration d’un processus simplifié pour vos déploiements. Le processus ne nécessite que 3 étapes :
- Connectez-vous à votre compte GitHub et choisissez un dépôt
- Déployez votre application automatiquement (à chaque commit) ou manuellement
- Construisez, mettez à l’échelle et exécutez vos processus séparément
C’est aussi simple que cela !
Vous n’avez pas à vous soucier de la configuration des images de conteneurs car nous détectons et déployons automatiquement les applications construites dans cette liste croissante de langages ou de frameworks :
- Node.js
- PHP
- Django
- Rails
- Java
- Scala
- Go
(Note : Nous établissons une liste de dépôts de base « Hello World » que vous pouvez forker et déployer sur Kinsta pour faire un essai du service.)
Si vous préférez avoir plus de contrôle avec une image Docker personnalisée, vous pouvez utiliser votre propre Dockerfile dans le dépôt. Cela vous permettra d’utiliser presque n’importe quel langage/framework et ne vous limitera pas à ceux supportés par nos Buildpacks actuels.
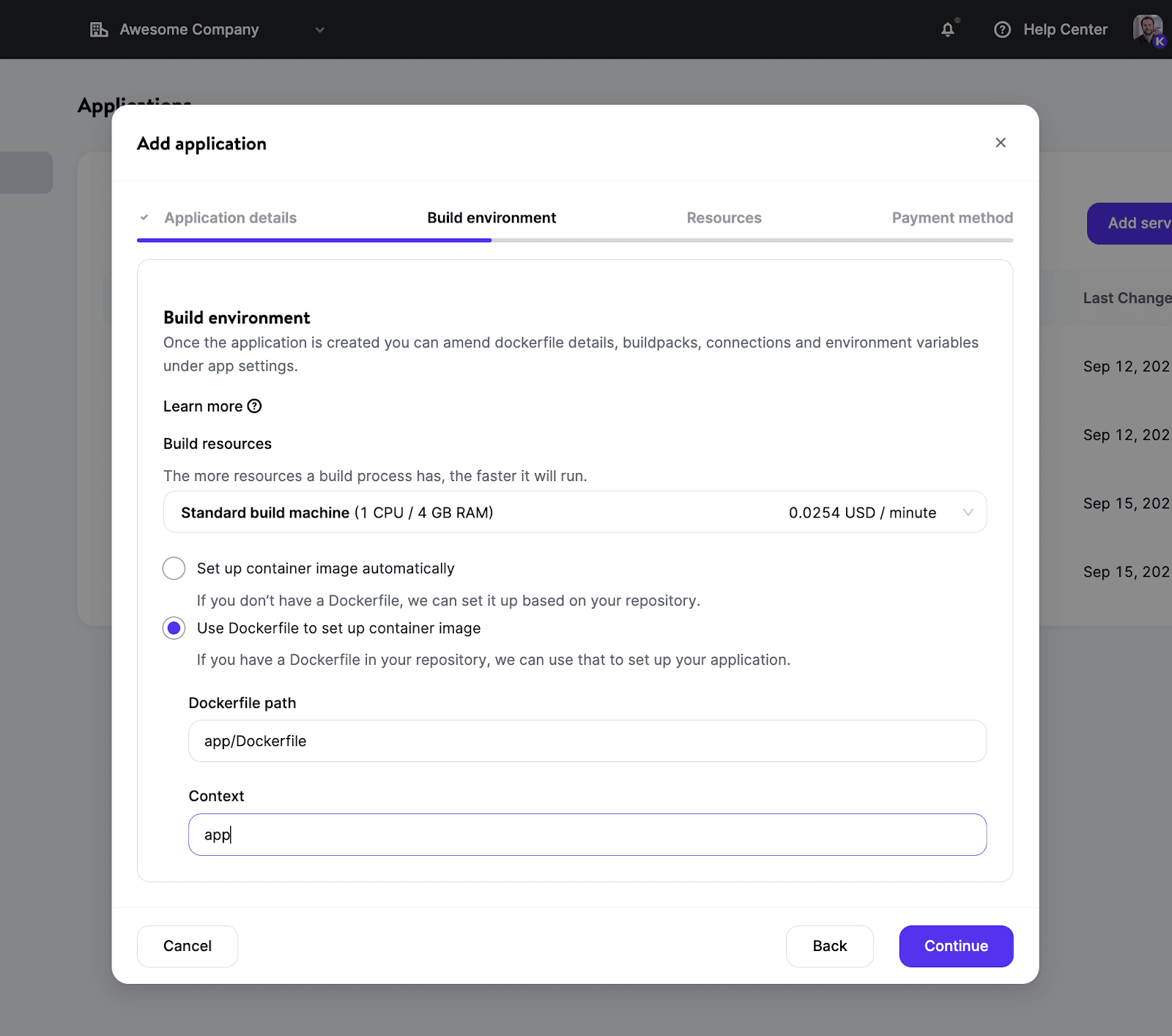
Une fois votre environnement de construction mis en place, vous aurez de nombreuses options pour choisir la taille des ressources (grâce aux différents types de pods) qui correspond à vos besoins et définir le nombre d’instances pour une meilleure évolutivité.
Pour un examen approfondi de toutes les fonctionnalités, assurez-vous de lire notre documentation sur l’hébergement d’applications.
Des analyses puissantes pour surveiller vos applications
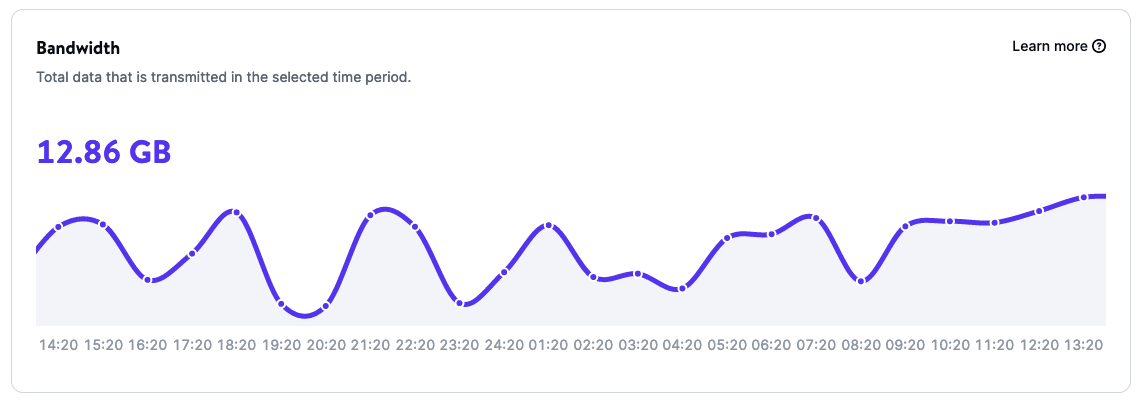
Grâce aux pages d’analyse pour vos applications, vous pouvez obtenir des rapports sur l’utilisation des applications qui incluent :
- La bande passante
- Le temps de construction
- Le temps d’exécution
- L’utilisation du CPU
- L’utilisation de la mémoire
Qu’en est-il de la tarification ?
L’hébergement d’applications offre des options basées sur les ressources, ce qui signifie que vous serez facturé exclusivement pour votre utilisation et rien de plus. Et les premiers 20 $ sont à notre charge, tant pour les nouveaux clients que pour les clients existants.
Découvrez l’hébergement d’applications chez Kinsta et déployez votre première application dans l’un de nos 24 centres de données.
Hébergement de bases de données (en bref)
Les bases de données sont un élément clé de nombreux projets web. Bien qu’il existe des applications qui n’en ont pas besoin, la grande majorité nécessite une base de données.
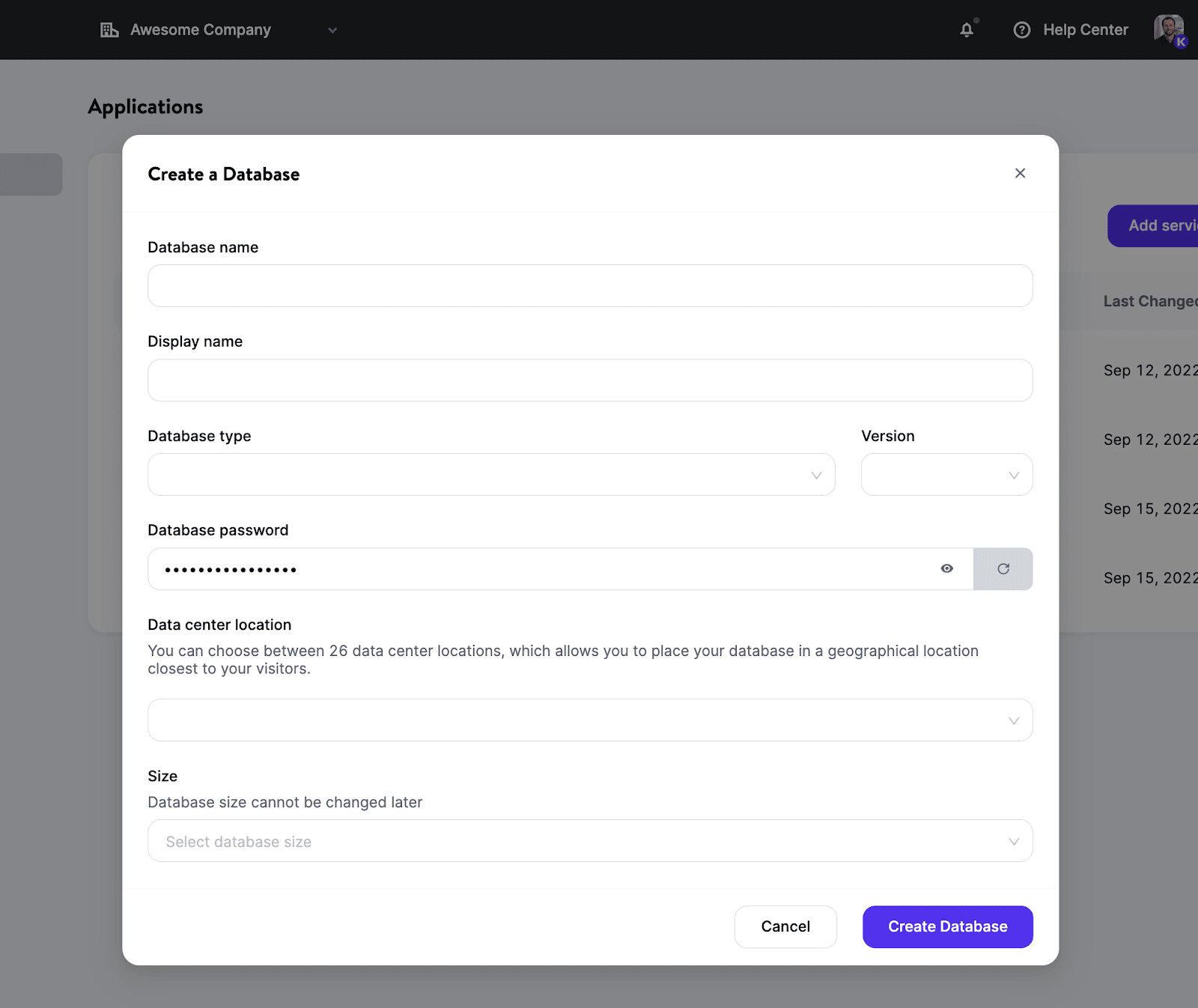
Grâce à la solution d’hébergement de base de données de Kinsta, vous pouvez configurer une base de données en quelques clics, et vous pouvez vous connecter à votre base de données avec une application hébergée par Kinsta ou un service externe.
Nous prenons actuellement en charge différents types de bases de données, pour lesquels vous pouvez sélectionner la version qui correspond le mieux aux besoins de votre projet. Plus précisément, vous pouvez héberger :
- MySQL
- MariaDB
- Redis
- PostgreSQL
Et nous travaillons à en ajouter d’autres dans un futur proche !
Comment déployer une base de données chez Kinsta
Vous pouvez configurer une nouvelle base de données et la rendre disponible en quelques minutes. Vous n’aurez pas à gérer des serveurs, à manipuler des clusters et des conteneurs, ou à vous soucier d’autres tâches dont le DevOps est habituellement responsable.
Voici le processus :
- Sélectionnez le type de base de données et la version que vous préférez.
- Choisissez un emplacement de déploiement parmi les 24 emplacements de centre de données actuellement disponibles.
- Configurez les ressources pour votre base de données.
Voilà : Vous disposez maintenant d’une base de données conteneurisée fraîchement créée (sans ressources partagées !) pour vos projets.
Si vous créez une connexion interne entre votre application et votre base de données, elles vivront toutes deux dans le même cluster et communiqueront via une connexion sécurisée, ce qui offre de meilleures performances que les connexions externes.
De plus, vous ne serez pas facturé pour le trafic interne, car les requêtes restent dans le même réseau !
Pour plus d’informations, n’hésitez pas à lire notre documentation sur l’hébergement de bases de données.
Des analyses puissantes pour surveiller votre base de données
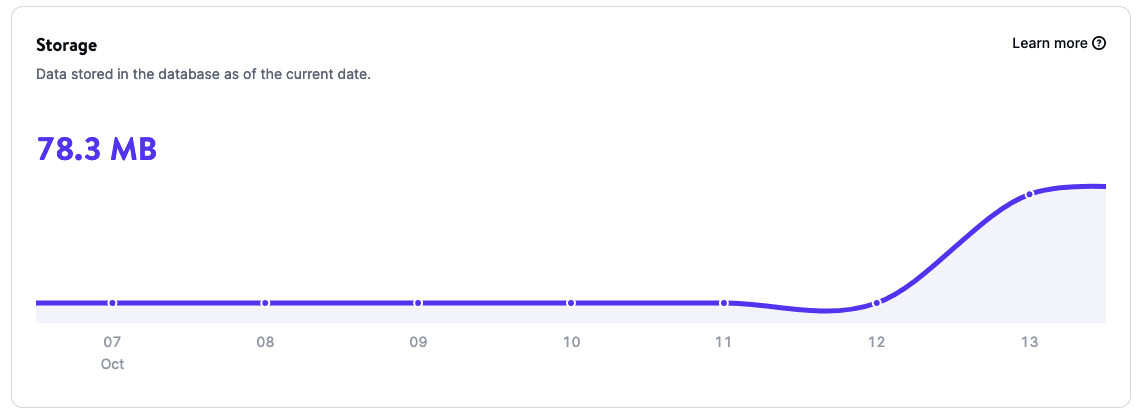
Grâce à l’analyse de base de données, vous pouvez obtenir des informations sur les données d’utilisation de votre base de données, notamment :
- Le stockage
- Le temps d’exécution
- L’utilisation du CPU
- L’utilisation de la mémoire
Qu’en est-il de la tarification ?
Comme pour l’hébergement d’applications, l’hébergement de bases de données offre un système de facturation à l’utilisation qui vous facture en fonction de la taille et de la durée d’exécution de votre base de données.
Apprenez-en plus sur l’hébergement de bases de données chez Kinsta et déployez votre première base de données dans l’un de nos 24 centres de données. N’oubliez pas : vous bénéficiez de 20 $ de réduction sur votre premier mois.
Quelle est la suite ?
Ce n’est que le tout début de la nouvelle ère de Kinsta. Nos équipes de développement et d’ingénierie travaillent d’arrache-pied sur de nouvelles fonctionnalités, corrigent les bogues et itèrent en écoutant attentivement les commentaires que vous avez partagés.
Parmi les nouvelles solutions sur lesquelles nous travaillons, citons l’hébergement de sites statiques, l’apprentissage automatique, les applications dansle cloud et le Function-as-a-Service à la périphérie – pour ne citer que quelques-unes des choses passionnantes sur notre feuille de route. En plus de cela, nous continuerons à nous concentrer sur l’amélioration de nos solutions WordPress gérées et à les perfectionner avec la sortie de fonctionnalités, telles que le cache edge, qui réduit le temps nécessaire pour servir le HTML WordPress en cache de plus de 50 % en moyenne !
C’est le moment idéal pour travailler en tant que développeur, et nous ne pourrions pas être plus excités par ce qui nous attend ici chez Kinsta !
Résumé
En élargissant les solutions d’hébergement de Kinsta, nous enrichissons la façon dont nous soutenons les entreprises et les développeurs, quelle que soit la technologie avec laquelle ils travaillent. Comme l’a résumé le président du conseil d’administration de Kinsta :
Nous construisons une plateforme où les développeurs peuvent trouver tout ce dont ils ont besoin pour utiliser un service web avec facilité, afin qu’ils puissent se concentrer sur la création et le partage de leur meilleur travail avec le monde.
Pour célébrer ce nouveau chapitre de l’histoire de Kinsta, tout le monde – nouveaux et anciens clients – peut essayer notre hébergement d’applications et notre hébergement de bases de données avec 20 $ de réduction sur votre premier mois.
Bienvenue dans le nouveau Kinsta – la plateforme construite pour les développeurs modernes pour transformer les idées en applications vivantes et évolutives comme vous l’avez toujours imaginé.
Simple, rapide, avec tout en un seul endroit.
Merci à tous nos formidables clients de nous faire confiance et de nous soutenir dans cette aventure !


