
Vous avez déjà voulu comparer les prix de plusieurs sites en une seule fois ? Ou peut-être extraire automatiquement une collection d’articles de votre blog préféré? Tout est possible avec le web scraping.
Le web scraping désigne le processus d’extraction de contenu et de données de sites web à l’aide d’un logiciel. Par exemple, la plupart des services de comparaison de prix utilisent des extracteurs web pour lire les informations sur les prix de plusieurs boutiques en ligne. Un autre exemple est Google, qui extrait ou « crawle » régulièrement le web pour indexer les sites web.
Bien sûr, ce ne sont là que deux des nombreux cas d’utilisation du web scraping. Dans cet article, nous allons plonger dans le monde de l’extraction web, apprendre comment ils fonctionnent et voir comment certains sites web tentent de les bloquer. Lisez la suite pour en savoir plus et commencer à faire de l’extraction web !
Qu’est-ce que le Web Scraping ?
L’extraction web est un ensemble de pratiques utilisées pour extraire automatiquement – ou « scraper » – des données du web.
D’autres termes pour le web scraping incluent « content scraping » ou « data scraping » Quel que soit le nom qu’on lui donne, l’extraction web est un outil extrêmement utile pour la collecte de données en ligne. Les applications du web scraping comprennent les études de marché, les comparaisons de prix, la surveillance du contenu, et plus encore.
Mais qu’est-ce que le web scraping extrait exactement – et comment est-ce possible ? Est-il même légal ? Un site web ne voudrait-il pas que quelqu’un vienne extraire ses données ?
Les réponses dépendent de plusieurs facteurs. Mais avant de nous plonger dans les méthodes et les cas d’utilisation, examinons de plus près ce qu’est l’extraction web et si elle est éthique ou non.
Que peut-on extraire sur le web ?
Il est possible d’extraire toutes sortes de données du web. Qu’il s’agisse de moteurs de recherche, de flux RSS ou d’informations gouvernementales, la plupart des sites web mettent leurs données à la disposition des extracteurs, des crawlers et d’autres formes de collecte automatique de données.
Voici quelques exemples courants.
Toutefois, cela ne signifie pas que ces données sont toujours disponibles. Selon le site web, vous devrez peut-être employer quelques outils et astuces pour obtenir exactement ce dont vous avez besoin – en supposant que les données soient accessibles en premier lieu. Par exemple, de nombreux extracteurs de sites web ne peuvent pas extraire de données significatives d’un contenu visuel.
Dans les cas les plus simples, le web scraping peut se faire par le biais de l’API ou interface de programmation d’application d’un site web . Lorsqu’un site web met son API à disposition, les développeurs web peuvent l’utiliser pour extraire automatiquement des données et d’autres informations utiles dans un format pratique. C’est presque comme si l’hébergeur du site web vous fournissait votre propre « pipeline » vers ses données. Ça c’est de l’hospitalité !
Bien sûr, ce n’est pas toujours le cas – et de nombreux sites web que vous souhaitez scraper ne disposent pas d’une API que vous pouvez utiliser. De plus, même les sites web qui disposent d ‘une API ne vous fournissent pas toujours les données dans le bon format.
Par conséquent, l’extraction web n’est nécessaire que lorsque les données web que vous souhaitez ne sont pas disponibles sous la ou les formes dont vous avez besoin. Que cela signifie que les formats que vous souhaitez ne sont pas disponibles, ou que le site web ne fournit tout simplement pas l’ensemble des données, le web scraping permet d’obtenir ce que vous voulez.
Bien que ce soit formidable et tout, cela soulève également une question importante : Si certaines données web sont restreintes, est-il légal de les extraire ? Comme nous le verrons bientôt, il peut s’agir d’une zone grise.
Le web scraping est-il légal ?
Pour certaines personnes, l’idée de l’extraction web peut presque ressembler à du vol. Après tout, qui êtes-vous pour « prendre » les données de quelqu’un d’autre ?
Heureusement, il n’y a rien d’intrinsèquement illégal dans le web scraping. Lorsqu’un site web publie des données, celles-ci sont généralement à la disposition du public et, par conséquent, libres d’être extraites.
Par exemple, étant donné qu’Amazon met les prix des produits à la disposition du public, il est parfaitement légal de récupérer les données relatives aux prix. De nombreuses applications d’achat et extensions de navigateur populaires utilisent le web scraping dans ce but précis, afin que les utilisateurs sachent qu’ils obtiennent le bon prix.
Cependant, toutes les données web ne sont pas destinées au public, ce qui signifie que l’extraction de toutes les données web n’est pas légal. Lorsqu’il s’agit de données personnelles et de propriété intellectuelle, le web scraping peut rapidement se transformer en web scraping malveillant , entraînant des sanctions telles qu’un avis de retrait DMCA.
Qu’est-ce que le web scraping malveillant ?
Le web scraping malveillant est une extraction web de données que l’éditeur n’avait pas l’intention de partager ou n’a pas consenti à partager. Bien que ces données soient généralement des données personnelles ou de la propriété intellectuelle, le scraping malveillant peut s’appliquer à tout ce qui n’est pas destiné au public.
Comme vous pouvez l’imaginer, cette définition comporte une zone grise. Si de nombreux types de données personnelles sont protégés par des lois telles que le règlement général sur la protection des données (RGPD ) et la loi californienne sur la protection de la vie privée des consommateurs (CCPA), d’autres ne le sont pas. Mais cela ne signifie pas qu’il n’y a pas de situations où il n’est pas légal de les extraire.

Par exemple, disons qu’un hébergeur web met « accidentellement » à la disposition du public les informations concernant ses utilisateurs. Il peut s’agir d’une liste complète de noms, d’adresses e-mail et d’autres informations qui sont techniquement publiques mais qui ne sont peut-être pas destinées à être partagées.
Bien qu’il soit techniquement légal de récupérer ces données, ce n’est probablement pas la meilleure idée. Le fait que des données soient publiques ne signifie pas nécessairement que l’hébergeur a consenti à ce qu’elles soient extraites, même si son manque de surveillance les a rendues publiques.
Cette « zone grise » a donné au web scraping une réputation quelque peu mitigée. Bien que l’extraction web soit tout à fait légale, elle peut facilement être utilisée à des fins malveillantes ou non éthiques. Par conséquent, de nombreux hébergeurs n’apprécient pas que leurs données soient extraites, que ce soit légal ou non.
Un autre type de web scraping malveillant est le « over-scraping », où les extracteurs envoient trop de requêtes sur une période donnée. Un trop grand nombre de requêtes peut mettre à rude épreuve les hébergeurs, qui préfèrent dépenser les ressources de leurs serveurs pour des personnes réelles plutôt que pour des robots de scraping.
En règle générale, utilisez l’extraction web avec parcimonie et uniquement lorsque vous êtes totalement sûr que les données sont destinées à un usage public. N’oubliez pas que ce n’est pas parce que des données sont accessibles au public qu’il est légal ou éthique de les extraire.
À quoi sert le web scraping ?
Dans le meilleur des cas, le web scraping sert à de nombreuses fins utiles dans de nombreux secteurs. En 2021, près de la moitié de l’ensemble de l’extraction web est utilisé pour soutenir les stratégies de commerce électronique.
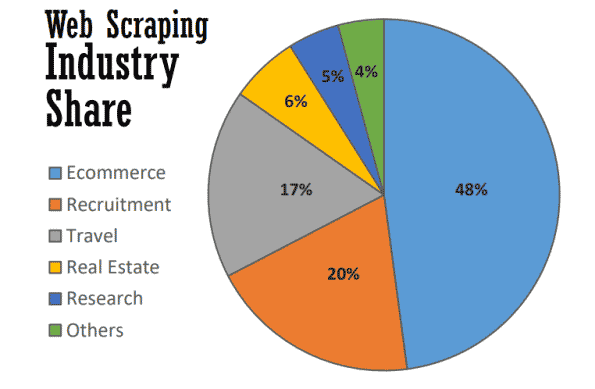
L’extraction web est devenue l’épine dorsale de nombreux processus axés sur les données, qu’il s’agisse de suivre les marques, de fournir des comparaisons de prix actualisées ou de réaliser de précieuses études de marché. Voici quelques-uns des procédés les plus courants.
Étude de marché
Que font vos clients ? Qu’en est-il de vos prospects ? Comment les prix de vos concurrents sont-ils comparés aux vôtres ? Disposez-vous d’informations pour créer une campagne de marketing entrant ou de marketing de contenu réussie ?
Ce ne sont là que quelques-unes des questions qui constituent les pierres angulaires des études de marché – et celles-là mêmes auxquelles on peut répondre grâce au web scraping. Comme une grande partie de ces données sont disponibles publiquement, l’extraction web est devenue un outil précieux pour les équipes marketing qui cherchent à garder un œil sur leur marché sans avoir à effectuer des recherches manuelles fastidieuses.
Automatisation des activités
Bon nombre des avantages du web scraping pour les études de marché s’appliquent également à l’automatisation des activités.
Lorsque de nombreuses tâches d’automatisation de l’entreprise nécessitent la collecte et le traitement de grandes quantités de données, l’extraction web peut s’avérer inestimable – en particulier si cette opération serait autrement fastidieuse.
Par exemple, disons que vous devez recueillir des données à partir de dix sites web différents. Même si vous recueillez le même type de données sur chacun d’eux, chaque site web peut nécessiter une méthode d’extraction différente. Plutôt que de passer manuellement par différents processus internes sur chaque site web, vous pouvez utiliser un extracteur web pour le faire automatiquement.
Génération de prospects
Comme si les études de marché et l’automatisation des affaires ne suffisaient pas, le web scraping peut également générer de précieuses listes de prospects avec peu d’efforts.
Bien que vous deviez définir vos objectifs avec une certaine précision, vous pouvez utiliser l’extraction web pour générer suffisamment de données utilisateur pour créer des listes de prospects structurées. Les résultats peuvent varier, bien sûr, mais c’est plus pratique (et plus prometteur) que de créer des listes de prospects par vous-même.
Suivi des prix
L’extraction des prix – également connue sous le nom de « price scraping » – est l’une des applications les plus courantes du web scraping.
Voici un exemple tiré de l’application populaire de suivi des prix d’Amazon, Camelcamelcamel. L’application extrait régulièrement les prix des produits et les compare ensuite sur un graphique au fil du temps.
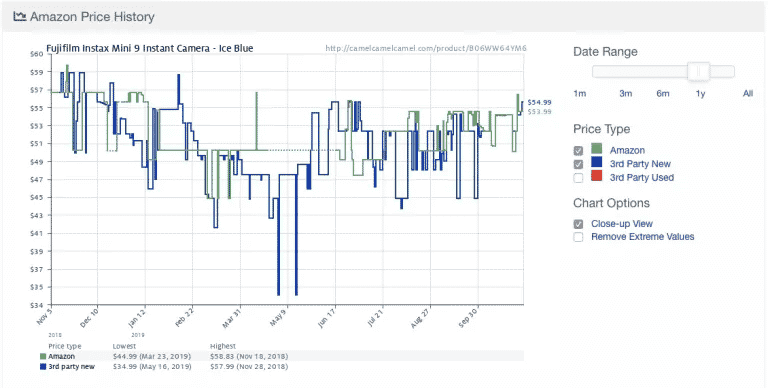
Les prix peuvent fluctuer énormément, même quotidiennement (regardez la chute soudaine des prix autour du 9 mai !). En ayant accès aux tendances historiques des prix, les utilisateurs peuvent vérifier si le prix qu’ils paient est idéal. Dans cet exemple, l’utilisateur pourrait choisir d’attendre une semaine environ dans l’espoir d’économiser 10 $.
Malgré son utilité, l’extraction des prix s’accompagne d’une certaine controverse. Étant donné que de nombreuses personnes veulent des mises à jour des prix en temps réel, certaines applications de suivi des prix deviennent rapidement malveillantes en surchargeant certains sites web de requêtes de serveur.
En conséquence, de nombreux sites eCommerce ont commencé à prendre des mesures supplémentaires pour bloquer complètement les extracteurs de prix, ce que nous allons aborder dans la section suivante.
Actualités et contenu
Il n’y a rien de plus précieux que de rester au courant. De la surveillance des réputations au suivi des tendances du secteur, le web scraping est un outil précieux pour rester informé.
Bien que certains sites web d’actualités et blogs fournissent déjà des flux RSS et d’autres interfaces faciles, ce n’est pas toujours la norme – et ce n’est pas non plus aussi courant qu’avant. Par conséquent, l’agrégation des nouvelles et du contenu exacts dont vous avez besoin nécessite souvent une certaine forme d’extraction web.
Surveillance de marque
Pendant que vous extrayez les nouvelles, pourquoi ne pas vérifier votre marque ? Pour les marques qui font l’objet d’une grande couverture médiatique, le web scraping est un outil inestimable pour rester à jour sans avoir à parcourir d’innombrables articles et sites d’information.
L’extraction web est également utile pour vérifier le prix minimum disponible (Minimum Available Price ou MVP) d’un produit ou d’un service d’une marque. Bien qu’il s’agisse techniquement d’une forme d’extraction de prix, il s’agit d’une information clé qui peut aider les marques à déterminer si leurs prix correspondent aux attentes des clients.
L’immobilier
Si vous avez déjà cherché un appartement ou acheté une maison, vous savez combien il y a de choses à trier. Avec des milliers d’annonces dispersées sur plusieurs sites web immobiliers, il peut être difficile de trouver exactement ce que vous cherchez.
De nombreux sites web utilisent le web scraping pour regrouper les annonces immobilières dans une seule base de données afin de faciliter le processus. Les exemples les plus populaires sont Zillow et Trulia, bien qu’il y en ait beaucoup d’autres qui suivent un modèle similaire.
Cependant, l’agrégation d’annonces n’est pas la seule utilisation de l’extraction web dans l’immobilier. Par exemple, les agents immobiliers peuvent utiliser des applications d’extraction pour rester au courant des prix moyens de location et de vente, des types de propriétés vendues et d’autres tendances précieuses.
Comment fonctionne le web scraping ?
L’extraction web peut sembler compliquée, mais c’est en fait très simple.
Bien que les méthodes et les outils puissent varier, tout ce que vous avez à faire est de trouver un moyen (1) de parcourir automatiquement le ou les sites web cibles et (2) d’extraire les données une fois sur place. Généralement, ces étapes sont réalisées à l’aide de scrapers et de crawlers.
Scrapeurs et crawlers
En principe, l’extraction web fonctionne presque de la même manière qu’un cheval et une charrue.

Tandis que le cheval guide la charrue, celle-ci tourne et brise la terre, aidant à faire place aux nouvelles graines tout en remettant dans le sol les mauvaises herbes et les résidus de culture indésirables.
Mis à part le cheval, le web scraping n’est pas très différent. Ici, un analyseur joue le rôle du cheval, guidant l’extracteur – en fait notre charrue – à travers nos champs numériques.
Voici ce qu’ils font tous les deux.
- Les crawlers (parfois appelés spiders) sont des programmes de base qui parcourent le web en recherchant et en indexant du contenu. Si les analyseurs guident les extracteurs de sites web, ils ne sont pas exclusivement utilisés à cette fin. Par exemple, les moteurs de recherche comme Google utilisent des analyseurs pour mettre à jour les index et les classements des sites web. Les analyseurs sont généralement disponibles sous forme d’outils pré-construits qui vous permettent de spécifier un site web ou un terme de recherche donné.
- Les scrapeurs font le sale boulot d’extraire rapidement les informations pertinentes des sites web. Comme les sites web sont structurés en HTML, les extracteurs utilisent des expressions régulières (regex), XPath, des sélecteurs CSS et d’autres localisateurs pour trouver et extraire rapidement certains contenus. Par exemple, vous pouvez donner à votre extracteur web une expression régulière spécifiant un nom de marque ou un mot-clé.
Si cela vous semble un peu trop compliqué, ne vous inquiétez pas. La plupart des outils d’extraction web comprennent des analyseurs et des extracteurs intégrés, ce qui permet d’effectuer facilement les tâches les plus compliquées.
Processus de base du web scraping
À son niveau le plus basique, l’extraction web se résume à quelques étapes simples :
- Spécifiez les URL des sites web et des pages que vous souhaitez extraire
- Faites une requête HTML vers les URL (c’est-à-dire, « visitez » les pages)
- Utilisez des localisateurs tels que les expressions régulières pour extraire les informations souhaitées du HTML
- Enregistrez les données dans un format structuré (tel que CSV ou JSON)
Comme nous le verrons dans la section suivante, un large éventail d’outils d’extraction web peut être utilisé pour effectuer ces étapes automatiquement.
Cependant, ce n’est pas toujours aussi simple, surtout lorsqu’il s’agit d’effectuer du web scraping à grande échelle. L’un des plus grands défis de l’extraction est de maintenir votre extracteur à jour au fur et à mesure que les sites web changent de présentation ou adoptent des mesures anti-scraping (tout ne peut pas être éternel). Bien que cela ne soit pas trop difficile si vous n’extrayez que quelques sites web à la fois, en extraire davantage peut rapidement devenir une source de tracas.
Pour minimiser le travail supplémentaire, il est important de comprendre comment les sites web tentent de bloquer les extracteurs – ce que nous allons apprendre dans la section suivante.
Outils de scraping web
De nombreuses fonctions d’extraction web sont facilement disponibles sous la forme d’outils de scraping web. Bien que de nombreux outils soient disponibles, ils varient considérablement en termes de qualité, de prix et (malheureusement) d’éthique.
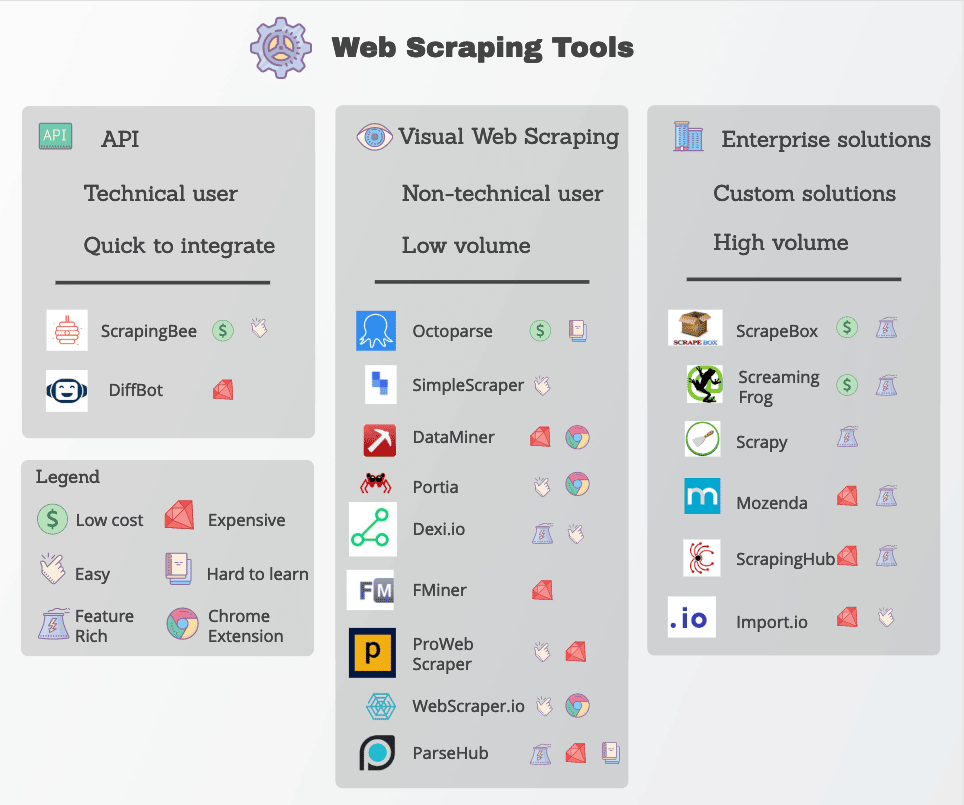
Dans tous les cas, un bon extracteur web sera capable d’extraire de manière fiable les données dont vous avez besoin sans se heurter à trop de mesures anti-scraping. Voici quelques caractéristiques clés à rechercher.
- Localisateurs précis : Les extracteurs web utilisent des localisateurs tels que des expressions régulières et des sélecteurs CSS pour extraire des données spécifiques. L’outil que vous choisissez doit vous offrir plusieurs options pour spécifier ce que vous recherchez.
- Qualité des données : La plupart des données web sont non structurées, même si elles sont présentées clairement à l’œil humain. Travailler avec des données non structurées est non seulement désordonné, mais cela donne rarement de bons résultats. Veillez à rechercher des outils d’extraction qui nettoient et trient les données brutes avant de les livrer.
- Livraison des données : En fonction de vos outils ou flux de travail existants, vous aurez probablement besoin des données extraites dans un format spécifique tel que JSON, XML ou CSV. Au lieu de convertir les données brutes vous-même, recherchez des outils offrant des options de livraison des données dans les formats dont vous avez besoin.
- Manipulation anti-scraping : Le scraping web n’est aussi efficace que sa capacité à contourner les blocages. Bien que vous puissiez avoir besoin d’utiliser des outils supplémentaires tels que des proxies et des VPN pour débloquer des sites web, de nombreux outils d’extraction web y parviennent en apportant de petites modifications à leurs analyseurs.
- Prix transparents : Bien que certains outils de web scraping soient gratuits, les options plus robustes ont un prix. Portez une attention particulière au système de tarification, surtout si vous avez l’intention de passer à l’échelle et d’extraire de nombreux sites.
- Assistance clientèle : Bien que l’utilisation d’un outil pré-établi soit extrêmement pratique, vous ne serez pas toujours en mesure de résoudre les problèmes vous-même. Par conséquent, assurez-vous que votre fournisseur offre également un support client et des ressources de dépannage fiables.
Les outils d’extraction web les plus populaires sont Octoparse, Import.io et Parsehub.
Protection contre le web scraping
Inversons un peu les rôles : Supposons que vous êtes un hébergeur web mais que vous ne voulez pas que d’autres personnes utilisent toutes ces méthodes astucieuses pour extraire vos données. Que pouvez-vous faire pour vous protéger ?
Au-delà des extensions de sécurité de base, il existe quelques méthodes efficaces pour bloquer les extracteurs et les analyseurs.
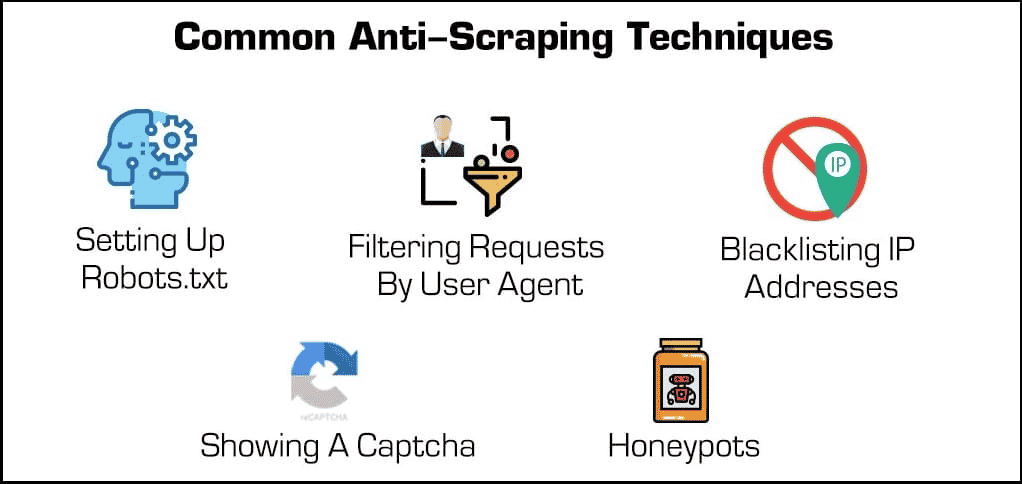
- Blocage des adresses IP : De nombreux hébergeurs wôeb gardent la trace des adresses IP de leurs visiteurs. Si un hébergeur remarque qu’un visiteur particulier génère de nombreuses requêtes de serveur (comme dans le cas de certains extracteurs de sites web ou robots), il peut alors bloquer entièrement l’IP. Cependant, les extracteurs peuvent contourner ces blocages en changeant leur adresse IP via un proxy ou un VPN.
- Configuration de robots.txt : Un fichier robots.txt permet à un hébergeur web d’indiquer aux extracteurs, aux analyseurs et aux autres robots ce à quoi ils peuvent ou non accéder. Par exemple, certains sites web utilisent un fichier robots.txt pour rester privés en indiquant aux moteurs de recherche de ne pas les indexer. Si la plupart des moteurs de recherche respectent ces fichiers, ce n’est pas le cas de nombreuses formes malveillantes d’extracteurs web.
- Filtrage des requêtes : Lorsqu’une personne visite un site web, elle « demande » une page HTML au serveur web. Ces requêtes sont souvent visibles pour les hébergeurs web, qui peuvent voir certains facteurs d’identification tels que les adresses IP et les agents utilisateurs comme les navigateurs web. Nous avons déjà abordé le blocage des IP, mais les hébergeurs web peuvent également filtrer par agent utilisateur.
Par exemple, si un hébergeur web remarque de nombreuses requêtes provenant du même utilisateur qui utilise une version obsolète de Mozilla Firefox, il peut simplement bloquer cette version et, ce faisant, bloquer le robot. Ces capacités de blocage sont disponibles dans la plupart des plans d’hébergement infogéré.
- Afficher un Captcha : Avez-vous déjà dû saisir une étrange chaîne de texte ou cliquer sur au moins six voiliers avant d’accéder à une page ? Alors vous avez rencontré un Captcha. Bien qu’ils soient simples, ils sont incroyablement efficaces pour filtrer les extracteurs web et autres robots.
- Honeypots : Un honeypot ou pot de miel est un type de piège utilisé pour attirer et identifier les visiteurs indésirables. Dans le cas des extracteurs web, un hébergeur web peut inclure des liens invisibles sur sa page web. Les utilisateurs humains ne s’en apercevront pas, mais les robots les visiteront automatiquement en les faisant défiler, ce qui permettra aux hébergeurs web de collecter (et de bloquer) leurs adresses IP ou leurs agents utilisateurs.
Maintenant, inversons les rôles. Que peut faire un extracteur pour surmonter ces protections ?
Si certaines mesures anti-scraping sont difficiles à contourner, il existe quelques méthodes qui ont tendance à fonctionner souvent. Elles consistent à modifier d’une manière ou d’une autre les caractéristiques d’identification de votre extracteur.
- Utilisez un proxy ou un VPN : Étant donné que de nombreux hébergeurs web bloquent les extracteurs web en fonction de leur adresse IP, il est souvent nécessaire d’utiliser une variété d’adresses IP pour garantir l’accès. Les proxies et les réseaux privés virtuels (Virtual Private Network ou VPN) sont idéaux pour cette tâche, bien qu’ils présentent quelques différences essentielles.
- Visitez régulièrement vos cibles : La plupart des extracteurs de sites web vous indiqueront quand ils ont été bloqués. Par conséquent, il est important de vérifier régulièrement l’endroit d’où vous faites de l’extraction pour voir si vous avez été bloqué ou si le formatage du site web a changé. Notez que l’un de ces cas est pratiquement garanti à un moment ou à un autre.
Bien sûr, aucune de ces mesures n’est nécessaire si vous utilisez le web scraping de manière responsable. Si vous décidez de mettre en œuvre l’extraction web, n’oubliez pas de le faire avec parcimonie et de respecter vos hébergeurs web !
Résumé
Si le web scraping est un outil puissant, il constitue également une menace puissante pour de nombreux hébergeurs web. Quel que soit le côté du serveur où vous vous trouvez, tout le monde a intérêt à s’assurer que l’extraction web est utilisée de manière responsable et, bien sûr, pour de bon.
Si vous êtes un hébergeur web qui cherche à contrôler les extracteurs web, ne cherchez pas plus loin que les plans d’hébergement WordPress infogéré de Kinsta. Vous pouvez limiter les robots et sauvegarder des données et des ressources précieuses grâce aux nombreux outils de contrôle d’accès disponibles.
Pour plus d’informations, planifiez une démonstration gratuite ou contactez un expert en hébergement web de Kinsta dès aujourd’hui.


