
Avete mai voluto confrontare i prezzi di più siti in una volta sola? O magari estrarre automaticamente una raccolta di post dal vostro blog preferito? Tutto questo è possibile con il web scraping.
Il web scraping si riferisce al processo di estrazione di contenuti e dati da siti web tramite software. Per esempio, la maggior parte dei servizi di comparazione dei prezzi usa i web scraper per leggere le informazioni sui prezzi di diversi negozi online. Un altro esempio è Google, che effettua abitualmente lo scraping o il “crawling” del web per indicizzare i siti web.
Naturalmente, questi sono solo due dei tanti casi di utilizzo del web scraping. In questo articolo ci addentreremo nel mondo dei web scraper, scopriremo come funzionano e come alcuni siti web cercano di bloccarli. Continuate a leggere per saperne di più e iniziare a fare scraping!
Cos’È il Web Scraping?
Il web scraping è un insieme di pratiche utilizzate per estrarre automaticamente – “scrape” in inglese significa raschiare, grattare via – dati dal web.
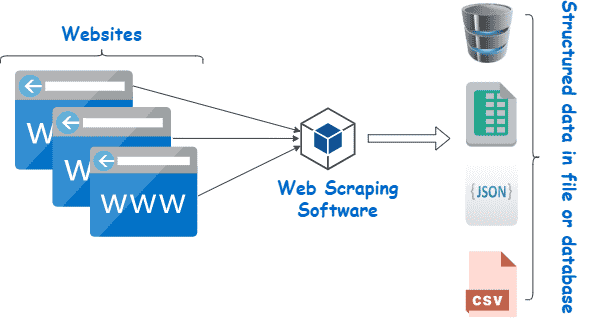
Altri termini per definire il web scraping sono “content scraping” o “data scraping”. Indipendentemente dal nome, il web scraping è uno strumento estremamente utile per la raccolta di dati online. Le applicazioni del web scraping includono ricerche di mercato, confronti di prezzi, monitoraggio dei contenuti e altro ancora.
Ma che cosa estrae esattamente il web scraping e come è possibile? È legale? Un sito web non vorrebbe che qualcuno venisse a estrarre i suoi dati?
Le risposte dipendono da diversi fattori. Prima di addentrarci nei metodi e nei casi d’uso, però, diamo un’occhiata più da vicino a cosa sia il web scraping e se sia etico o meno.
Che Tipo di Dati Possiamo Estrarre Automaticamente dal Web?
È possibile fare lo scraping di tutti i tipi di dati web. Dai motori di ricerca ai feed RSS, fino alle informazioni governative, la maggior parte dei siti web rende i propri dati pubblicamente disponibili a scraper, crawler e altre forme di raccolta automatica dei dati.
Ecco alcuni esempi comuni.
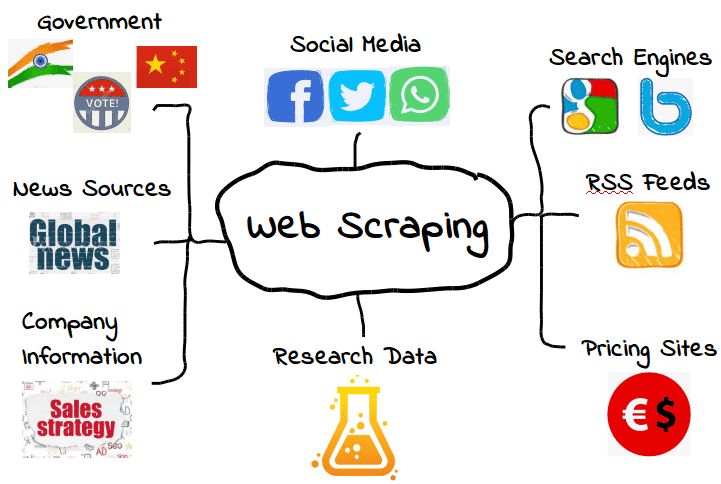
Tuttavia, ciò non significa che questi dati siano sempre disponibili. A seconda del sito web, potrebbe essere necessario usare alcuni strumenti e trucchi per ottenere esattamente ciò che vi serve, ammesso che i dati siano accessibili. Per esempio, molti web scraper non sono in grado di estrarre dati significativi da contenuti visivi.
Nei casi più semplici, il web scraping può essere effettuato attraverso l’API, detta anche application programming interface di un sito web . Quando un sito web rende disponibile la sua API, chi lavora nello sviluppo web può usarla per estrarre automaticamente dati e altre informazioni utili in un formato conveniente. È come se l’host del sito web vi fornisse la vostra “pipeline” personale per accedere ai suoi dati. Un’ospitalità che si può definire tale!
Naturalmente, non è sempre così: molti siti web che volete estrarre non hanno un’API che potete utilizzare. Inoltre, anche i siti web che hanno un’API non sempre forniscono i dati nel formato giusto.
Di conseguenza, il web scraping è necessario solo quando i dati web che desiderate non sono disponibili nella forma che vi serve. Sia che si tratti di formati non disponibili, sia che il sito web non fornisca l’intera gamma di dati, lo scraping web permette di ottenere ciò che desiderate.
Se da un lato questo è fantastico, dall’altro solleva una questione importante: Se alcuni dati web sono limitati, è legale farne lo scraping? Come vedremo tra poco, la questione può essere un po’ grigia.
Lo Scraping del Web È Legale?
Per alcune persone, l’idea di fare scraping sul web può sembrare quasi un furto. Dopo tutto, chi siete voi per “prendere” i dati di qualcun altro?
Per fortuna non c’è nulla di illegale nel web scraping. Quando un sito web pubblica dei dati, questi sono solitamente disponibili al pubblico e, di conseguenza, liberi di essere “scrappati”.
Per esempio, dal momento che Amazon rende pubblici i prezzi dei prodotti, è perfettamente legale effettuare lo scraping dei dati sui prezzi. Molte popolari app di shopping ed estensioni del browser usano il web scraping proprio per questo scopo, in modo che gli utenti sappiano che stanno ottenendo il prezzo giusto.
Tuttavia, non tutti i dati web sono destinati al pubblico, quindi non tutti i dati web si possono estrarre legamente. Quando si tratta di dati personali e di proprietà intellettuale, il web scraping può trasformarsi rapidamente in web scraping malevolo, con conseguenti sanzioni come un avviso di rimozione DMCA.
Cos’È il Web Scraping Malevolo?
Il web scraping malevolo consiste nello scraping di dati che l’editore non intendeva o non aveva acconsentito a condividere. Anche se di solito si tratta di dati personali o di proprietà intellettuale, lo scraping malevolo può riguardare qualsiasi cosa non destinata al pubblico.
Come potete immaginare, questa definizione presenta un’area grigia. Mentre molti tipi di dati personali sono protetti da leggi come il General Data Protection Regulation (GDPR) e il California Consumer Privacy Act (CCPA), altri non lo sono. Ma questo non significa che non ci siano situazioni in cui non sia legale effettuare lo scraping.

Per esempio, supponiamo che un host web renda “accidentalmente” disponibili al pubblico le informazioni sui propri utenti. Queste potrebbero includere un elenco completo di nomi, email e altre informazioni che tecnicamente sono pubbliche ma che forse non erano destinate a essere condivise.
Anche se sarebbe tecnicamente legale raccogliere questi dati, probabilmente non è l’idea migliore. Il fatto che i dati siano pubblici non significa necessariamente che l’host web abbia acconsentito al loro scraping, anche se la sua mancanza di sorveglianza li ha resi pubblici.
Questa “zona grigia” ha dato al web scraping una reputazione piuttosto contrastante. Sebbene il web scraping sia sicuramente legale, può essere facilmente utilizzato per scopi malevoli o non etici. Di conseguenza, molti web host non apprezzano il fatto che i loro dati vengano sottoposti a scraping, indipendentemente dal fatto che sia legale o meno.
Un altro tipo di scraping dannoso è l'”over-scraping”, quando gli scraper inviano un numero eccessivo di richieste in un determinato periodo. Un numero eccessivo di richieste può mettere a dura prova i web host, che preferirebbero impiegare le risorse del server per le persone reali piuttosto che per i bot di scraping.
Come regola generale, usate il web scraping con parsimonia e solo quando siete sicuri al 100% che i dati siano destinati all’uso pubblico. Ricordate che solo perché i dati sono disponibili pubblicamente non significa che sia legale o etico farne lo scraping.
A Cosa Serve il Web Scraping?
Al meglio, il web scraping serve a molti scopi utili in molti settori. Nel 2021, quasi la metà di tutto il web scraping è utilizzato per sostenere le strategie di ecommerce.
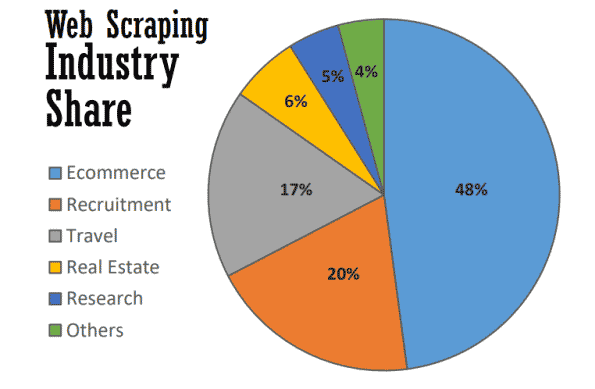
Il web scraping è diventato la spina dorsale di molti processi basati sui dati, dal monitoraggio dei marchi al confronto aggiornato dei prezzi, fino alla realizzazione di preziose ricerche di mercato. Ecco alcuni dei più comuni.
Ricerche di Mercato
Cosa fanno i vostri clienti? E i vostri contatti? Come sono i prezzi dei vostri concorrenti rispetto ai vostri? Avetele informazioni necessarie per creare una campagna di inbound marketing o di content marketing di successo?
Queste sono solo alcune delle domande che costituiscono la base delle ricerche di mercato e che possono trovare risposta grazie al web scraping. Poiché molti di questi dati sono disponibili pubblicamente, il web scraping è diventato uno strumento prezioso per i team di marketing che vogliono tenere d’occhio il proprio mercato senza dover effettuare ricerche manuali che richiedono molto tempo.
Automazione Aziendale
Molti dei vantaggi del web scraping per le ricerche di mercato si applicano anche all’automazione aziendale.
Se molte attività di automazione aziendale richiedono la raccolta e l’elaborazione di grandi quantità di dati, il web scraping può rivelarsi prezioso, soprattutto se l’operazione risulta altrimenti complessa.
Per esempio, supponiamo che dobbiate raccogliere dati da dieci siti web diversi. Anche se state raccogliendo lo stesso tipo di dati da ciascuno di essi, ogni sito web potrebbe richiedere un metodo di estrazione diverso. Piuttosto che passare manualmente attraverso processi interni diversi per ogni sito web, potreste usare un web scraper per farlo automaticamente.
Generazione di Lead
Come se le ricerche di mercato e l’automazione aziendale non fossero sufficienti, il web scraping può anche generare preziose liste di contatti con poco sforzo.
Anche se dovrete definire i vostri obiettivi con una certa precisione, potete usare il web scraping per generare abbastanza dati sugli utenti per creare elenchi di lead strutturati. I risultati possono variare, ovviamente, ma è più conveniente (e più promettente) che creare liste di contatti per conto vostro.
Tracciamento dei Prezzi
L’estrazione dei prezzi, nota anche come price scraping, è una delle applicazioni più comuni del web scraping.
Ecco un esempio tratto dalla popolare applicazione di tracciamento dei prezzi di Amazon , Camelcamelcamel. L’applicazione effettua regolarmente lo scraping dei prezzi dei prodotti e li confronta su un grafico nel tempo.
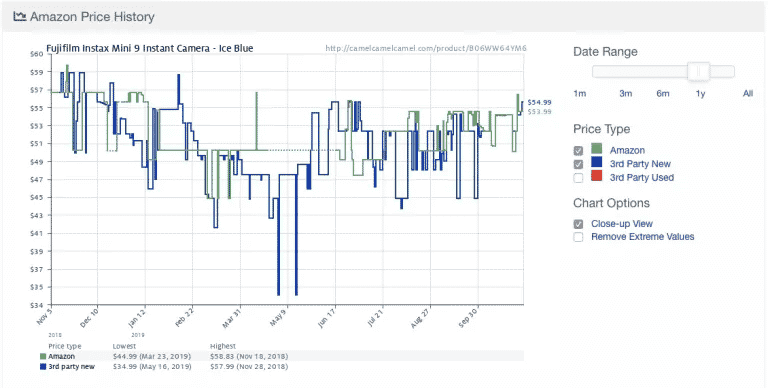
I prezzi possono subire fluttuazioni enormi, anche giornaliere (guardate l’improvviso calo dei prezzi intorno al 9 maggio!). Grazie all’accesso all’andamento storico dei prezzi, gli utenti possono verificare se il prezzo che stanno pagando è corretto. In questo esempio, l’utente potrebbe scegliere di aspettare una settimana o poco più nella speranza di risparmiare 10 dollari.
Nonostante la sua utilità, il price scraping comporta alcune controversie. Poiché molte persone desiderano aggiornamenti sui prezzi in tempo reale, alcune app di monitoraggio dei prezzi fanno in fretta a diventare dannose, sovraccaricando alcuni siti web con richieste al server.
Di conseguenza, molti siti di ecommerce hanno iniziato ad adottare misure aggiuntive per bloccare del tutto i web scraper, di cui parleremo nella prossima sezione.
Notizie e Contenuti
Non c’è niente di più prezioso che rimanere informati. Dal monitoraggio della reputazione alle tendenze del settore, il web scraping è uno strumento prezioso per rimanere informati.
Sebbene alcuni siti web di notizie e blog forniscano già feed RSS e altre interfacce semplici, non sono sempre la norma, né sono così comuni come un tempo. Di conseguenza, aggregare le notizie e i contenuti di cui avete bisogno richiede spesso una forma di scraping del web.
Monitoraggio del Marchio
Mentre fate scraping delle notizie, perché non controllate il vostro marchio? Per i marchi che ricevono molte notizie, il web scraping è uno strumento prezioso per rimanere aggiornati senza dover consultare innumerevoli articoli e siti di notizie.
Il web scraping è utile anche per verificare il prezzo minimo disponibile (MAP) di un prodotto o servizio di un marchio. Anche se tecnicamente si tratta di una forma di price scraping, è un’informazione fondamentale che può aiutare i brand a determinare se i loro prezzi sono in linea con le aspettative dei clienti.
Immobili
Se avete mai cercato un appartamento o comprato una casa, sapete bene quanto ci sia da fare una cernita. Con migliaia di annunci sparsi su diversi siti web immobiliari, può essere difficile trovare esattamente quello che state cercando.
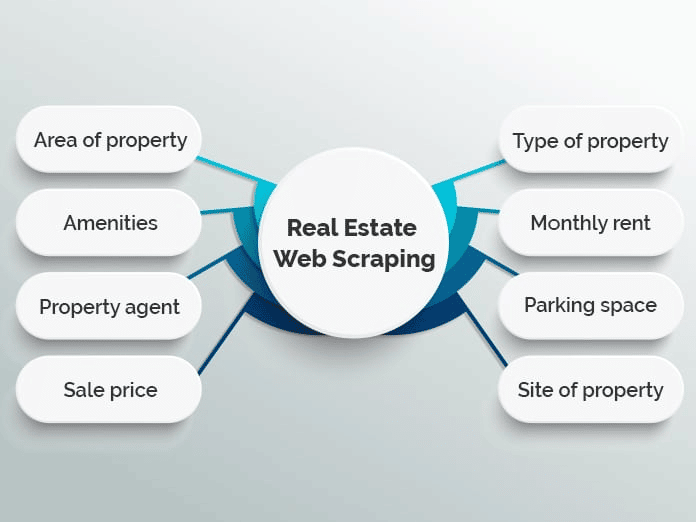
Molti siti web usano il web scraping per aggregare gli annunci immobiliari in un unico database e rendere il processo più semplice. Esempi famosi sono Zillow e Trulia, ma ce ne sono molti altri che seguono un modello simile.
Tuttavia, l’aggregazione degli annunci non è l’unico utilizzo del web scraping nel settore immobiliare. Per esempio, gli agenti immobiliari possono usare le applicazioni di scraping per tenere sotto controllo i prezzi medi di affitto e di vendita, i tipi di immobili venduti e altre tendenze importanti.
Come Funziona il Web Scraping?
Il web scraping può sembrare complicato, ma in realtà è molto semplice.
Anche se i metodi e gli strumenti possono variare, tutto ciò che dovete fare è trovare un modo per (1) navigare automaticamente sul sito web di destinazione e (2) estrarre i dati una volta sul posto. Di solito, queste fasi vengono eseguite con scraper e crawler.
Scraper e Crawler
In linea di principio, il web scraping funziona quasi come un cavallo e un aratro.

Mentre il cavallo guida l’aratro, quest’ultimo si gira e spacca la terra, aiutando a far spazio a nuovi semi e a rielaborare le erbacce indesiderate e i residui del raccolto nel terreno.
A parte il cavallo, il web scraping e non è molto diverso. In questo caso, un crawler svolge il ruolo del cavallo, guidando lo scraper – di fatto il nostro aratro – attraverso i nostri campi digitali.
Ecco cosa fanno entrambi.
- I crawler (talvolta noti come spider) sono programmi di base che navigano sul web alla ricerca e all’indicizzazione dei contenuti. I crawler guidano i web scraper, ma non sono utilizzati esclusivamente per questo scopo. Per esempio, i motori di ricerca come Google usano i crawler per aggiornare gli indici e le classifiche dei siti web. I crawler sono solitamente disponibili come strumenti precostituiti che vi permettono di specificare un determinato sito web o un termine di ricerca.
- Gli scraper fanno il lavoro sporco di estrarre rapidamente le informazioni rilevanti dai siti web. Poiché i siti web sono strutturati in HTML, gli scraper utilizzano espressioni regolari (regex), XPath, selettori CSS e altri localizzatori per trovare ed estrarre rapidamente determinati contenuti. Per esempio, potreste dare al vostro scraper un’espressione regolare che specifichi il nome di un marchio o una parola chiave.
Se tutto questo vi sembra un po’ troppo complicato, non preoccupatevi. La maggior parte degli strumenti di web scraping include crawler e scraper integrati, che rendono facile anche i lavori più complicati.
Processo di Base del Web Scraping
Al livello più elementare, il web scraping si riduce a pochi semplici passi:
- Specificate gli URL dei siti web e delle pagine su cui volete fare scraping
- Lanciate una richiesta HTML agli URL (cioè “visitate” le pagine)
- Usate localizzatori come le espressioni regolari per estrarre le informazioni desiderate dall’HTML
- Salvate i dati in un formato strutturato (come CSV o JSON)
Come vedremo nella prossima sezione, è possibile usare un’ampia gamma di strumenti di web scraping per eseguire questi passaggi in modo automatico.
Tuttavia, non è sempre così semplice, soprattutto quando si tratta di eseguire il web scraping su larga scala. Una delle sfide più grandi del web scraping è quella di mantenere aggiornato il vostro scraper quando i siti web cambiano layout o adottano misure anti-scraping (non tutto può essere evergreen). Sebbene questo non sia troppo difficile se state effettuando lo scraping solo di alcuni siti web alla volta, lo scraping di un numero maggiore di siti può diventare rapidamente una seccatura.
Per ridurre al minimo il lavoro extra, è importante capire come i siti web tentano di bloccare gli scraper: lo scopriremo nella prossima sezione.
Strumenti di Web Scraping
Molte funzioni di web scraping sono disponibili sotto forma di strumenti di web scraping. Sebbene siano disponibili molti strumenti, essi variano notevolmente in termini di qualità, prezzo e (purtroppo) etica.
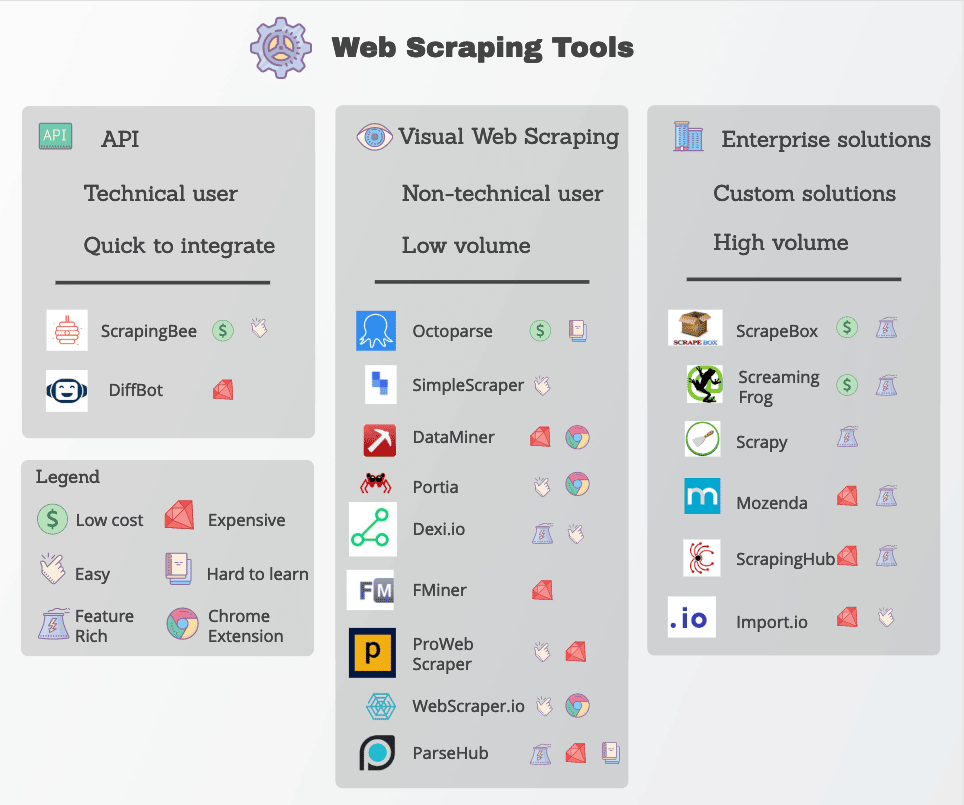
In ogni caso, un buon web scraper sarà in grado di estrarre in modo affidabile i dati di cui avete bisogno senza incorrere in troppe misure anti-scraping. Ecco alcune caratteristiche chiave da ricercare.
- Localizzatori precisi: I web scraper usano localizzatori come le espressioni regolari e i selettori CSS per estrarre dati specifici. Lo strumento che sceglierete dovrebbe consentirvi diverse opzioni per specificare ciò che state cercando.
- Qualità dei dati: La maggior parte dei dati web non è strutturata, anche se viene presentata in modo chiaro all’occhio umano. Lavorare con dati non strutturati non solo è disordinato, ma raramente porta a buoni risultati. Cercate strumenti di scraping che puliscano e ordinino i dati grezzi prima di consegnarli.
- Consegna dei dati: A seconda degli strumenti o dei flussi di lavoro esistenti, probabilmente avrete bisogno dei dati estratti in un formato specifico come JSON, XML o CSV. Invece di convertire i dati grezzi da soli, cercate strumenti con opzioni di consegna dei dati nei formati che vi servono.
- Gestione anti-scraping: Il web scraping è tanto efficace quanto la sua capacità di aggirare i blocchi. Sebbene sia necessario utilizzare strumenti aggiuntivi come proxy e VPN per sbloccare i siti web, molti strumenti di scraping web riescono a farlo apportando piccole modifiche ai loro crawler.
- Prezzi trasparenti: Sebbene alcuni strumenti di web scraping siano gratuiti, le opzioni più robuste hanno un prezzo. Prestate molta attenzione allo schema dei prezzi, soprattutto se volete scalare e scansionare molti siti.
- Assistenza clienti: Sebbene l’utilizzo di uno strumento precostituito sia estremamente comodo, non sempre sarete in grado di risolvere i problemi da soli. Di conseguenza, assicuratevi che il vostro fornitore offra anche un’assistenza clienti affidabile e risorse per la risoluzione dei problemi.
Tra gli strumenti di scraping web più diffusi ci sono Octoparse, Import.io e Parsehub.
Protezione Contro il Web Scraping
Cambiamo un po’ le carte in tavola: Supponiamo che voi sia un host web ma che non vogliate che altri usino tutti questi metodi intelligenti per estrarre automaticamente i vostri dati. Cosa potete fare per proteggervi?
Oltre ai plugin di sicurezza di base, esistono alcuni metodi efficaci per bloccare i web scraper e i crawler.
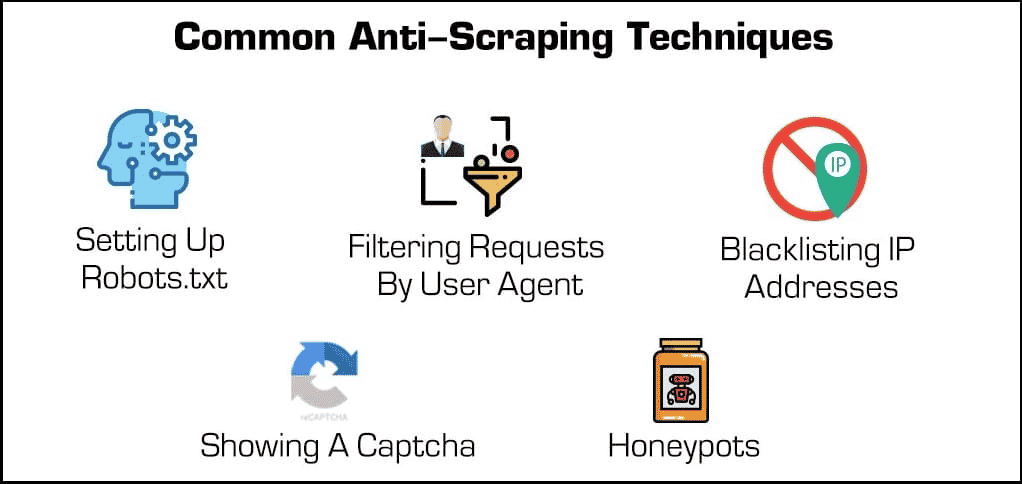
- Blocco degli indirizzi IP: Molti web host tengono traccia degli indirizzi IP dei loro visitatori. Se un host nota che un particolare visitatore genera molte richieste al server (come nel caso di alcuni web scraper o bot), potrebbe bloccare completamente l’IP. Tuttavia, gli scraper possono superare questi blocchi cambiando il loro indirizzo IP attraverso un proxy o una VPN.
- Impostazione del file robots.txt: Un file robots.txt consente all’host web di indicare a scraper, crawler e altri bot quali sono gli accessi possibili e quelli non possibili. Per esempio, alcuni siti web usano un file robots.txt per mantenere la propria riservatezza, indicando ai motori di ricerca di non indicizzarli. Mentre la maggior parte dei motori di ricerca rispetta questi file, molte forme malevole di web scraper non lo fanno.
- Filtrare le richieste: Ogni volta che qualcuno visita un sito web, “richiede” una pagina HTML al server web. Queste richieste sono spesso visibili agli host web, che possono visualizzare alcuni fattori identificativi come gli indirizzi IP e gli user agent come i browser web. Abbiamo già parlato del blocco degli IP, ma gli host web possono anche filtrare in base allo user agent.
Per esempio, se un host web nota molte richieste da parte dello stesso utente che usa una versione obsoleta di Mozilla Firefox, può semplicemente bloccare quella versione e, così facendo, bloccare il bot. Queste funzionalità di blocco sono disponibili nella maggior parte dei piani di hosting gestito.
- Mostrare un Captcha: Avete mai dovuto digitare una strana stringa di testo o cliccare su almeno sei foto di semafori prima di accedere a una pagina? Allora sapete cosa sono i “Captcha“, acronimo di completely automated public Turing test for telling computer e humans aapart (test di Turing pubblico completamente automatizzato per distinguere computer e umani).
Nonostante la loro semplicità, sono incredibilmente efficaci nel filtrare i web scraper e altri bot. - Honeypots: Una “honeypot” è un tipo di trappola utilizzata per attirare e identificare i visitatori indesiderati. Nel caso dei web scraper, un web host potrebbe inserire dei link invisibili nella sua pagina web. Sebbene gli utenti umani non se ne accorgano, i bot li visiteranno automaticamente durante lo scorrimento, consentendo agli host web di raccogliere (e bloccare) i loro indirizzi IP o user agent.
Ora ribaltiamo di nuovo la situazione. Cosa può fare uno scraper per superare queste protezioni?
Sebbene alcune misure anti-scraping siano difficili da aggirare, ci sono un paio di metodi che tendono a funzionare spesso. Si tratta di modificare in qualche modo le caratteristiche identificative del vostro scraper.
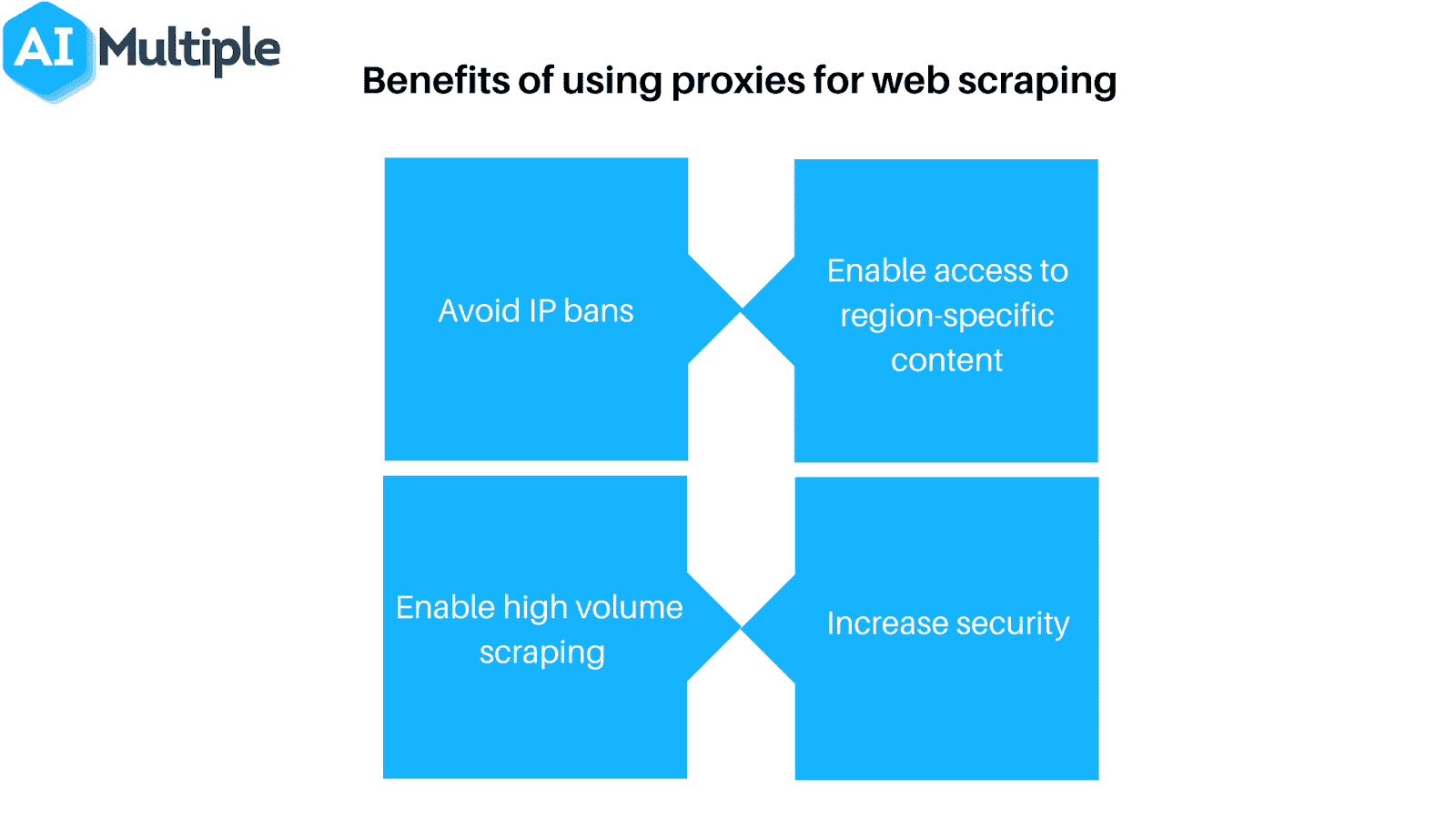
- Usate un proxy o una VPN: Poiché molti web host bloccano i web scraper in base al loro indirizzo IP, spesso è necessario usare diversi indirizzi IP per garantire l’accesso. I proxy e le Virtual Private Network (reti private virtuali o VPN) sono ideali per questo compito, anche se presentano alcune differenze fondamentali.
- Visitate regolarmente i vostri obiettivi: La maggior parte (se non tutti) i web scraper vi diranno quando sono stati bloccati. Di conseguenza, è importante controllare regolarmente da dove stai effettuando lo scraping per verificare se siete stati bloccati o se la formattazione del sito web è cambiata. Si noti che è quasi matematico che uno di questi casi si verifichi prima o poi.
Naturalmente, nessuna di queste misure è necessaria se usate il web scraping in modo responsabile. Se decidete di implementare il web scraping, ricordatevi di fare scraping con parsimonia e di rispettare i vostri host web!
Riepilogo
Sebbene il web scraping sia uno strumento potente, rappresenta anche una grave minaccia per molti host web. A prescindere dal lato del server in cui vi trovate, tutti hanno interesse ad assicurarsi che il web scraping venga utilizzato in modo responsabile e, ovviamente, a fin di bene.
Se gesite un web host e volete controllare i web scraper, i piani di hosting gestito di Kinsta fanno al caso vostro. Potete limitare i bot e salvaguardare dati e risorse preziose grazie ai numerosi strumenti di controllo degli accessi disponibili.
Per maggiori informazioni, prenotate una demo gratuita o contattate un esperto di web hosting di Kinsta oggi stesso.


