
ウェブサイトの高速化が不可欠な今日、表示速度のミリ秒がビジネスの勝敗を決めると言っても過言ではありません。Kinstaは販売、コンバージョン、ユーザー体験、そしてユーザーエンゲージメントにいかにサイト速度が影響を与えるかについて、独自に調査を行いました。
前置きとして、サイトの高速化はオンサイトオプティマイゼーションが鍵を握りますが、サイトを支え、サイトと訪問者をつなぐハードウェアとネットワークインフラも非常に重要であることは念頭においてください。
Googleがネットワークインフラストラクチャに多額の投資を行っている理由、そしてGoogle Cloudのプレミアムティアネットワークとスタンダードティアネットワークの違いについてご紹介します。
帯域幅とレイテンシ(サーバーにおけるパフォーマンスの主要指標)
Google Cloudのネットワークについて掘り下げる前に、キーワードとなる「帯域幅」と「レイテンシ」について理解しておきましょう。
帯域幅は、ネットワークのスループットの容量であり、Mbpsで測定します。レイテンシは、リクエストからデータを転送するまでの間に発生する遅延を意味します。
帯域幅やスループットをわかりやすく例えるなら、帯域幅は一定の時間(秒)に一定の水量が流れるホース。レイテンシは、水道管の蛇口をひねってから水が流れ出るまでの時間です。
異なるルーター間での接続の確立には小さな負荷がかかることから、「経由」が増えるたびに、レイテンシは少しずつ大きくなっていきます。
そのため、訪問者とサイトをホストするサーバーの距離が長いほど、またネットワークの断片化が進むほど、レイテンシは大きくなります。
これは、traceroute(Windowsではtracert)を使って見ることができます。以下のスクリーンショットは、このツールを利用してヨーロッパからの2つのリクエストのルーティングのレイテンシを調べた結果です。
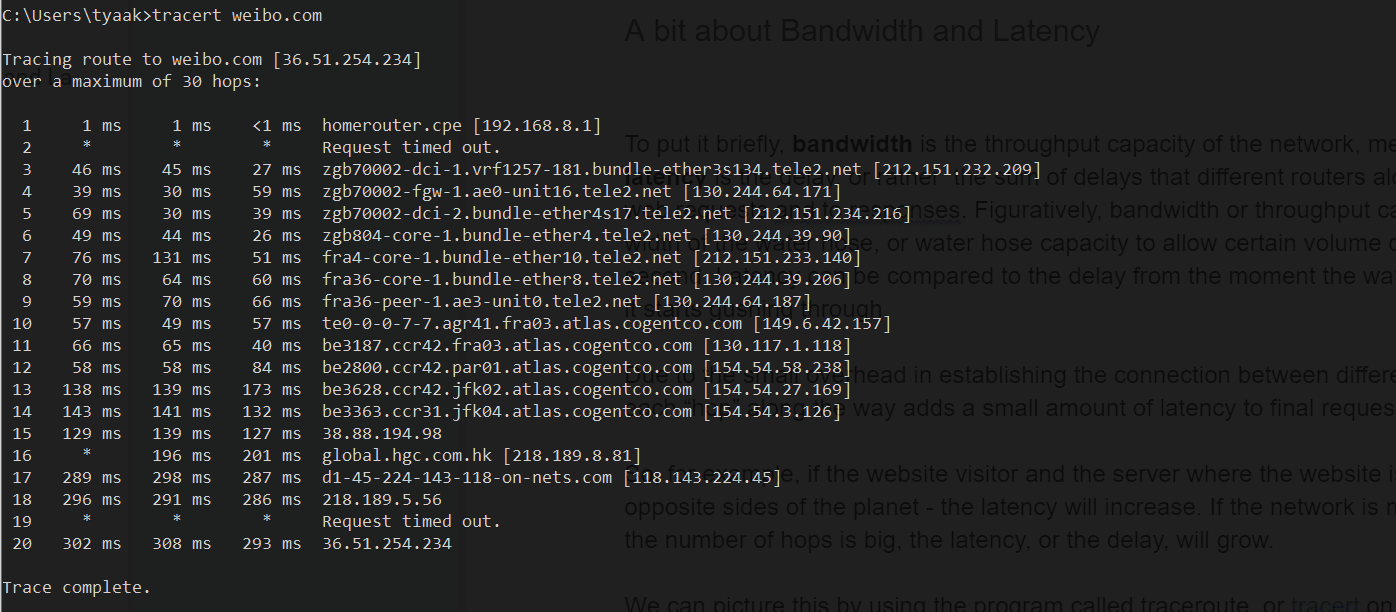
weibo.com(中国)へのリクエスト
bbc.co.uk(イギリス)へのリクエスト
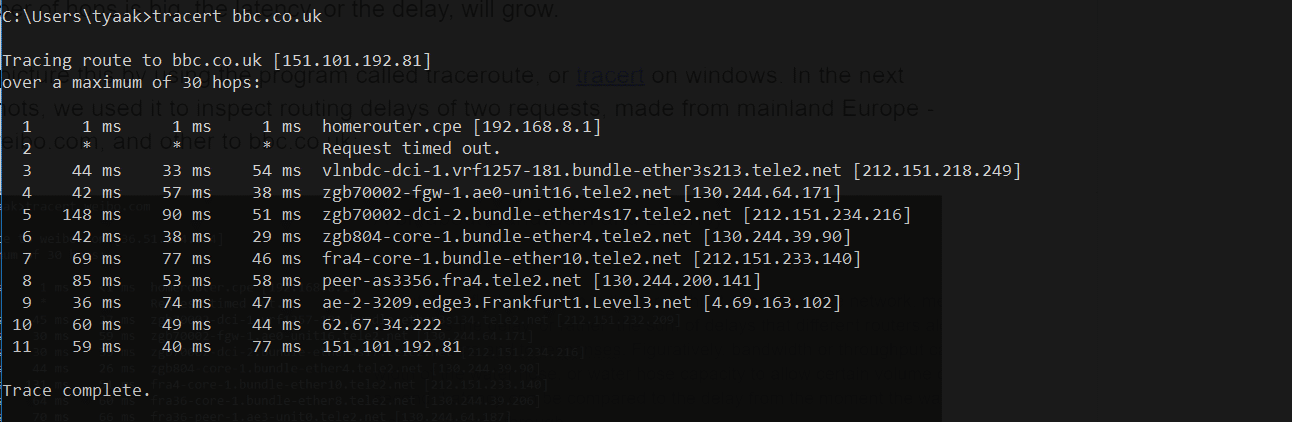
予想どおり、中国のサイトまでのホップ数は、イギリスのほぼ2倍になりました。したがって、前者のサイトは後者のイギリスでホストされているサイトのリクエストに比べて、待ち時間が長くなります。
tracertにある3つの列は、3つのRTT(ラウンドトリップタイム)を表しています。各行は、途中の異なるルーターまたはホップの数を表しており、多くの場合、一定のルーターの場所を特定するのに役立つURLも提供されます。
中国/香港のルーターとの間の往復時間は3分の1秒近くかかります。
pingdom toolsを使用して、Pingdomのオーストラリアのロケーションから、ロンドンでホストされているサイトを読み込み、サイト全体の読み込み時間の内訳を見てみると、以下のようになります。
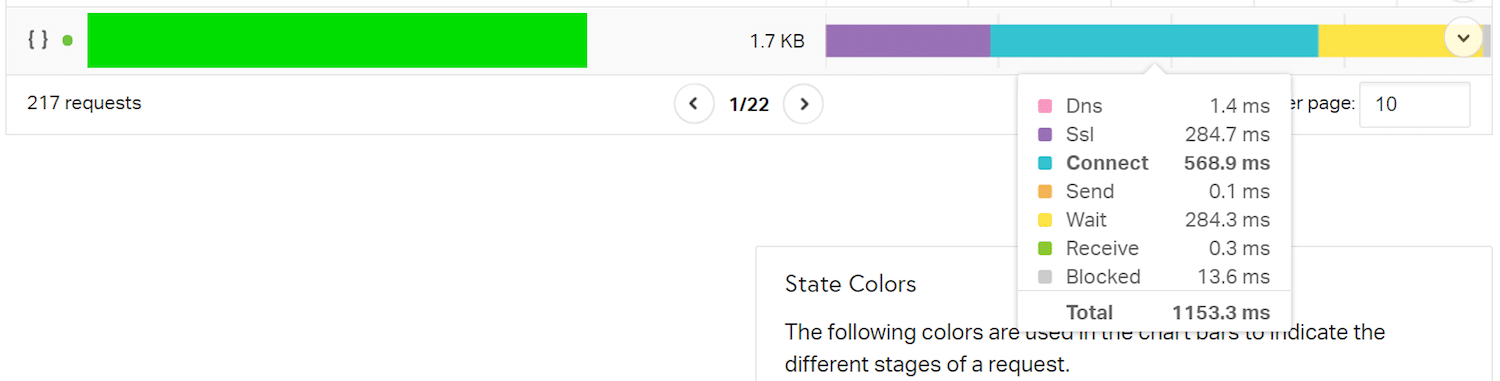
このリソースの読み込みで最も多くの時間を占めているのが「Connect」(接続)。「SSL」と「Wait」(待機)がこれに続きます。接続から待機までのすべての時間は、Time To First Byte(TTFB)と呼ばれ、これにはネットワークレイテンシも含まれます。
インターネットサービスプロバイダーが提示する接続速度は、帯域幅をベースとしていますが、これは実際の速度の尺度ではありません。ホース(帯域幅)の太さによって、サイトの速度をある程度まで改善することはできます(高解像度の動画コンテンツを配信する場合など、1秒間に多くのデータを送信する必要があるときに便利)。しかし、同時マルチプレイヤーゲームをオンラインでプレイしているユーザーにとっては、待機時間(レイテンシ)の方がはるかに重要になります。
HTTP/2の仕様、そしてSPDYプロトコルの開発者の1人であるMike Belshe氏は、帯域幅の増加がサイト速度に与える影響と、レイテンシがサイト速度に与える影響を分析しています。
以下のようなわかりやすい図にまとめられています。
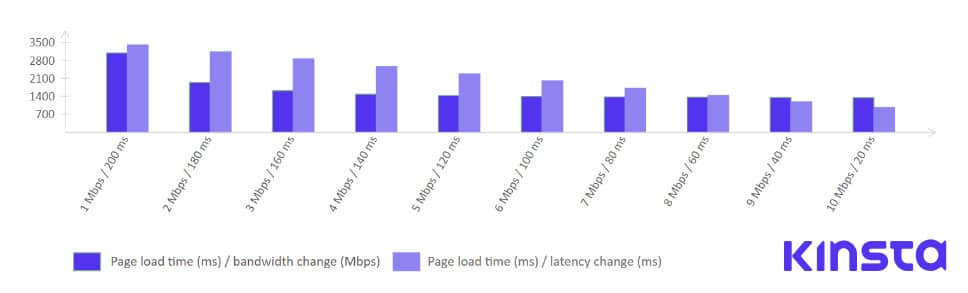
このグラフから、帯域幅を増やしてサイトの速度を改善することは、パフォーマンスを向上させるのに最も効果的な方法ではないというのは明らか。その一方で、RTTやレイテンシを短縮することで、ページの読み込み時間に一貫した改善が見られます。
ネットワーク、ピアリング、およびトランジット
このトピックについて掘り下げる前に、ネットワークトポロジーの基礎を把握しましょう。中核となるグローバルインターネットは、複数のグローバル、リージョナル、ローカルなネットワークで構成されています。
2018年現在、インターネット上で独自にネットワークを管理し、他のネットワークと通信を行う自律システム(Autonomous System、通称AS)は6万以上あります。これらのネットワークは政府、大学、ISPに属します。
ネットワークは、Tier1、Tier 2、そしてTier 3の3つの階層に分かれており、各層がインターネット全体における各ネットワークの独立性を表しています。
- Tier1ネットワーク─インターネット上のすべての経路情報を有する(日本ではNTTコミュニケーションズがこれに当たる)
- Tier2ネットワーク─同じTier2のISPとピアリングを行い、トランジットはTier1ネットワークから購入する
- Tier3ネットワーク─上位2つの層からトランジットを購入し、インターネットの残りの部分に接続する(インターネットを利用するために料金を支払う消費者のようなもの)
ピアリングは、2つのネットワークが直接トラフィックを同等に交換することを意味します。通常は双方同意の上で接続を行い、支払いは発生しません。
ピアリングを行う利点は、レイテンシの大幅な短縮にあります。
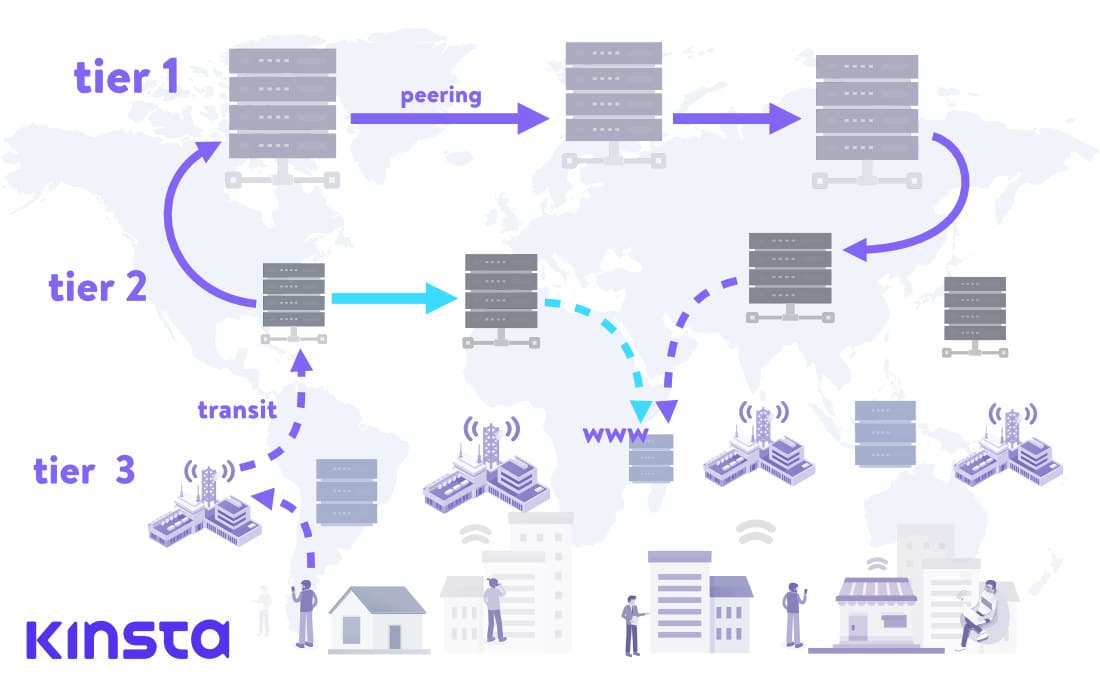
上の画像では、リモートロケーションのデータセンターでホストされているウェブサイトを取得するため、リクエストがTier1、Tier2、Tier3のネットワークを通過する従来の一般的な流れを表しています。破線の矢印はトランジット接続、実線の矢印はピアリング接続です。
Tier1ネットワークに到達すると、同じ階層の他のネットワークとピアリングを行い、ピアリングの関係にあるネットワークのみを介してリクエストを転送します。これにより、トランジットに対して支払いを行うことなく、インターネット上のすべてのネットワークに到達することができます。
また、水色の矢印はTier2ネットワークのピアリングを示しています。このシナリオでは、ホップ数が少なくなり、サイトの読み込み時間が大幅に短縮されます。
Border Gateway Protocol(BGP)
高度に専門的な文脈以外では語られることはほぼありませんが、BGPはインターネットの中心に位置する通信プロトコルです。インターネット上のほぼすべてにアクセスするための基本プロトコルであり、インターネット最大の脆弱性の1つでもあります。
BGPは、2006年のIETFのRequest For Comments #4271(RFC)で以下のように定義され、その後も複数回更新されています(以下原文の日本語訳)。
BGPスピーキングシステムの主な機能は、ネットワーク到達可能性情報を他のBGPシステムと交換すること
簡単に言えば、BGPは数百、数千のノードを経由し、ネットワークリクエストの正確なルートを決定する役割を担うプロトコルです。
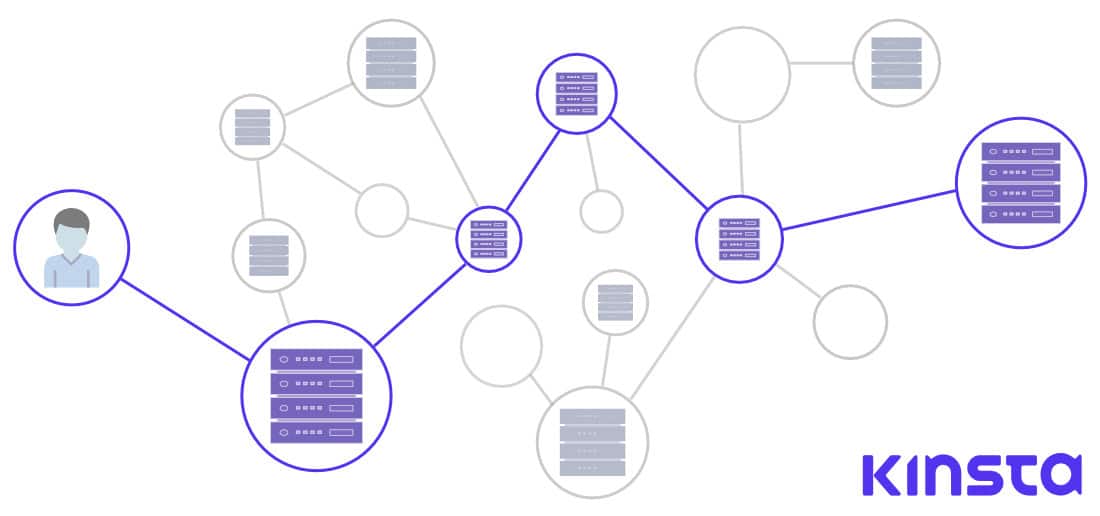
それぞれのノードは自律システム、または複数のノードまたはルーター、サーバー、それに接続したシステムで構成されるネットワークと見なすことができます。
BGPには、自動検出アルゴリズム(新たに接続されたノードが、隣接するノードを検出して接続する仕組みやプロトコル)がないため、BGPピアが手動でピアを指定しなければなりません。パスのアルゴリズムに関しては、Ciscoが以下のように説明しています(原文の日本語訳)。
BGPには、適切なパスを決定するシンプルな指標はありません。代わりに、各ルートに関する広範な属性を有し、最大13段階で構成される複雑なアルゴリズムを用いて適切なパスを判断します
自律システムは、ピアにルーティングデータを送信しますが、パスの選択に関しては厳格なルールを持ちません。BGPは信頼に基づいた暗黙のシステムであり、これこそが今日のインターネットにおけるセキュリティの欠陥になり得る理由です。2018年には、EMyEtherWallet.comのトラフィックがハイジャックされ、200を超えるイーサリアム(15万2,000ドル相当)が盗まるという事件が発生し、この脆弱性が広く認識されるようになりました。
BGPのこの欠点により、エンドユーザーの効率性やスピードよりも他の要素が優先され、さまざまなネットワーク(自律システム)がBGPデータを送信することが一般化されています。優先事項には、有料トラフィックなどの商業的利益、政治的またはセキュリティ上の配慮などが挙げられます。
クラウドコンピューティング、CDN、エッジマーケットの開発
ウェブ業界、オンラインゲーム、モノのインターネット(IoT)など、IT市場の成長に伴い、レイテンシの問題を解消するサービスや製品の需要も必然的に高まりました。
近年、訪問者の近くで静的リソースをキャッシュするコンテンツデリバリネットワーク(CDN)や、または実際のコンピューティングをエンドユーザーに近づけるクラウドベースの製品が増え続けています。代表的な製品の1つがCloudflare Workersで、CloudflareのエッジノードのネットワークでV8(JavaScriptエンジン)互換コードを実行します。これは、WebAssemblyまたはGOのコードでさえ、訪問者の近くで実行できることを意味します。
AmazonのLambda@Edge、そして、IoT市場を対象としたJoint Edge Computing Platform(JECP)を提供するIntelとAlibabaの提携もこの傾向を示唆しています。
また、Googleのキャッシュノードのグローバルネットワークが、子会社であるYouTubeのCDNと動画のキャッシュ/デリバリネットワークとして機能していることも特筆に値します。
クラウド業界がいかに洗練され、高度に進化したのか、そして訪問者のネットワークレイテンシをどれだけ短縮可能なのかを理解するため、GaaSについて考えてみましょう。
GaaSは「Gaming as a Service」の略で、クラウドでホストおよび実行されるゲームをユーザーがプレイできるようにする製品です。
ゲーム用のテレビやビデオプロジェクターを購入したり、テレビと別のデバイス間でMiracastやその他のキャスト接続を設定したりしたことのあるゲーム好きの方なら、レイテンシがいかに重要であるかお分かりのはず。中には、4kの解像度と60Hzのリフレッシュレートでゲーム配信を提供するGaaSサービスもあり、このようなサービスを利用すればハードウェアに投資する必要がありません。
また、米国が中国の大手通信機器HUAWEIの販売を禁止した一件により、5Gネットワークの問題、および世界のネットワークインフラストラクチャをアップグレードする明確なロードマップの必要性が明らかになりました。
スマートシティ、スマートハウス、自動運転車を調整するため、最小限のレイテンシでリアルタイムに大量の情報を中継するセンサーは、エッジデバイスの高密度ネットワークに依存します。レイテンシは、さまざまなセンサー情報、LIDARデータ、そして他の車両データを処理する必要のある自動運転自動車などにおいて、現在深刻なボトルネックになっています。
この競争の最前線にいるのが、コンテンツデリバリネットワークとクラウドコンピューティングです。業界を牽引する大手企業が導入し、リクエスト/レスポンスのサイクルを制御できるQUIC/HTTP3プロトコルについてはこちらでご紹介しています。
クラウドサービスのレイテンシへの対処
最大の市場シェアを占めるクラウドコンピューティングサービスは、AWSでしょう。2016年には、ハワイ、オーストラリア、ニュージーランド間の帯域幅の拡大とレイテンシ削減を目指し、ハワイキ海底ケーブルへの投資を行っています。これは海底インフラストラクチャへの最初の投資であり、2018年に稼働を開始しました。

しかしその頃、Googleはすでに海底ケーブルの敷設において競合他社と大きく差をつけていました。AWSが最初の投資を行う1年前に、ITWorldが「Google’s data centers grow too fast for normal networks, so it builds its own」(Googleは自社データセンターの急速な成長に対応するため、ネットワークを独自に構築)という記事を公開しています。
実際、ITジャーナリストであるMark Stephens氏(別名Robert X Cringely氏)は、2015年に公開されたPBS.orgのコラムで、Googleのダークファイバー(設置されているが未使用の光ファイバーインフラストラクチャ)の買い占めについて以下のように述べています(原文の日本語訳)。
(ダークファイバーを買い占めたGoogleは)Akmaiどころか、ステロイドを服用したAkamai以上の存在。例えるなら、専用のバックチャネルとアプリケーション固有のハードウェアを備え、動的に駆動するインテリジェントかつ熱核融合レベルのAkamaiで、インターネットの上にGoogleのインターネットが乗っかっている状態である
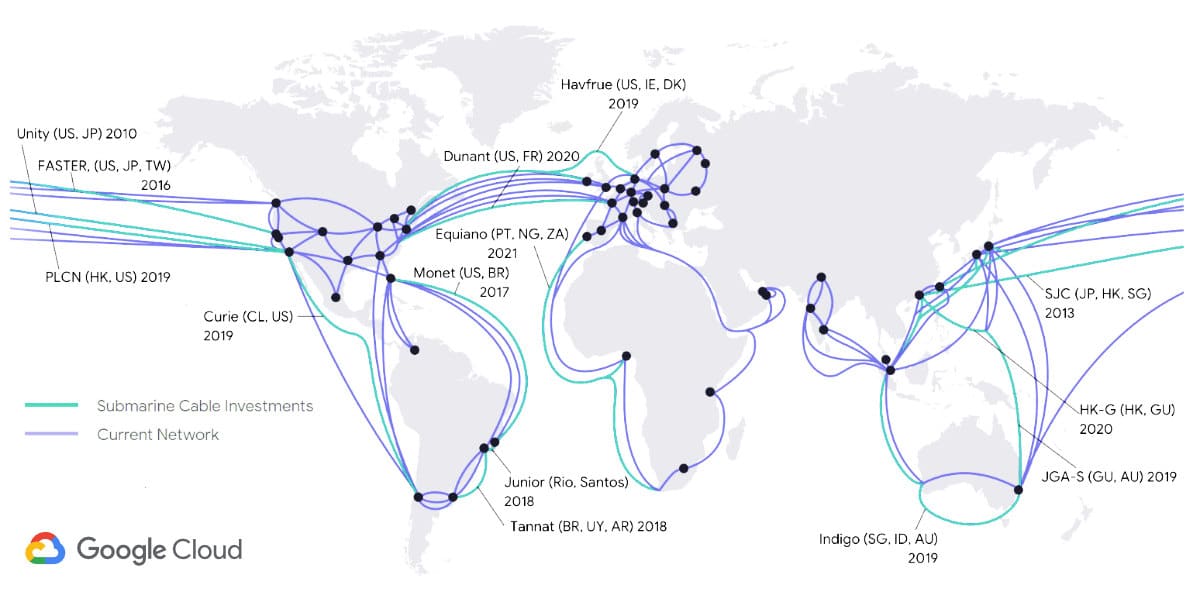
2010年のzdnet.comの記事では、Tom Foremski氏が以下のように述べています(原文の日本語訳)。
Googleは、インターネットの大部分を所有している企業の1つで、最も効率的で低コストのプライベートインターネットの構築に注力している。このインフラストラクチャがGoogleの強みであり、Googleを理解する鍵でもある
先ほどのMark Stephens氏の記事には、Googleがインターネット全体を乗っ取るという懸念が記されていましたが、その後Googleが米国最大の各都市におけるISP市場を独占するべく、Google Fiberを立ち上げた際、その懸念が顕在化することに。このプロジェクトはその後失速しましたが、(TechRepublicは2016年にプロジェクトの事後分析を公開)、世界規模で見れば、Googleのインフラストラクチャへの投資は減速していません。
Google最新の投資は、今年稼働予定のアメリカ、ロサンゼルスとチリ、バルパライソを結ぶ海底ケーブルで、将来的にはパナマへの接続も検討されています(以下原文の日本語訳)。
インターネットは一般的にクラウドと呼ばれるが、実際には水中にある脆いチューブの集合体。Googleは驚くほど多くのチューブを消しようとしている─VentureBeat
Googleがネットワークインフラストラクチャに多額の投資を行う理由
Googleが世界最大の検索エンジンであることは周知の事実。しかしGoogleには、以下のような側面もあります。
- 世界最大の動画配信プラットフォームを所有
- 世界最大のメールサービス(GmailとGoogle Workspace)
- クラウドコンピューティング製品で莫大な収益を得る(年間80億ドル以上、日本円にしておよそ約1兆1,700億円)
このような点を考慮すれば、Googleがレイテンシの削減と帯域幅の拡大を徹底的に追求しているのも合点がいきます。また、AmazonやMicrosoftのような競合他社と同じように、独自に開発したハードウェアやソフトウェアの考案しなければならない立場にあることから、インフラストラクチャの独占を視野に入れています。
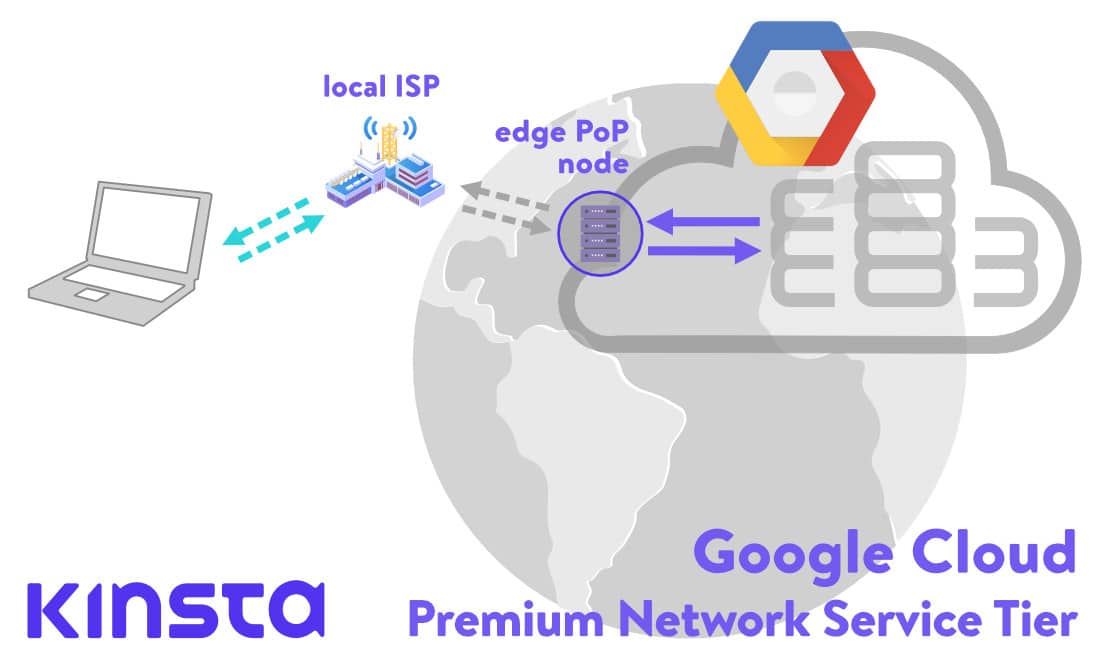
PoP(ポイントオブプレゼンス)は、Googleのグローバルプライベートケーブルネットワークの末端にあり、Googleのデータセンターに接続するトラフィックの入口と出口として機能しています。
Intelの共同設立者であるGordon Moore氏は、「2年ごとに集積回路に搭載できるトランジスタの数が2倍になる」というムーアの法則を提唱しました。何十年もの間この予測は正しいものでしたが、現在のコンピューティング業界はというと、これが疑問視されるようになり、近い将来に終わりを迎える可能性も。実際、NVIDIAのCEOはすでにムーアの法則は死んでいると述べているほどです。
このムーアの法則が、クラウド業界やGoogleのネットワークインフラストラクチャとどのように関係しているのかが気になるところ。
Googleのテックリード兼VPであるAmin Vahdat氏は、Foundation Connectイベントでムーアの法則の終結を認め、同社の課題について触れています(以下原文の日本語訳)
私たち(Google)のコンピューティングに対する需要は驚くべき速度で成長し続けており、アクセラレータとより緊密に結合されたコンピューティングが必要になります。ネットワークファブリックは、この2つを結び付ける上で重要な役割を果たすことになります
増大するコンピューティングパワーの需要にクラウドサービスが対応する1つの方法として、クラスタ化が挙げられます。クラスタ化とは、簡単に言えば、複数のコンピューターをまとめて単一の問題を処理し、単一のアプリケーションのプロセスを実行することを意味します。このようなセットアップから利益を得るための前提条件は、低いレイテンシまたは膨大なネットワーク容量であることは言うまでもありません。
Googleが独自のハードウェアの設計を開始した2004年には、ネットワークハードウェアベンダーは、コマンドラインを使用してルーターとスイッチを個別に管理する必要がありました。当時GoogleはCiscoなどの企業からスイッチをまとめて購入し、1台のスイッチに高額の費用を充てていましたが、それでもコンピューティングの需要の成長には追いつかず。
Googleのインフラストラクチャに対する需要は飛躍的に伸び続け、別のネットワークアーキテクチャが必要になるほどでした(2015年のGoogleの調査論文によれば、ネットワーク容量は10年で100倍に増加)。このような状況を受け、既存のハードウェアを購入する費用の観点からも、独自のソリューション開発が急がれました。そしてGoogleは、汎用のシリコンチップから独自のスイッチ構築に着手し、よりモジュール化された別のネットワークトポロジを採用することに。
Googleのエンジニアは、 Clos Networkと呼ばれる古いテレフォニーネットワークモデルの構築を始めました。これは、スイッチごとに必要なポート数を削減することが目的です(以下原文の日本語訳)。
クロスネットワークの利点は、同一の安価なデバイスをまとめて使用してツリーを作成し、他の方法では構築するのに費用がかかる高いパフォーマンスと回復力を獲得できることです— Clos Networks: What’s Old Is New Again, Network World
この新たなモジュール式ハードウェアについて、Googleは既存のプロトコルを再定義し、独自のネットワークオペレーティングシステムを構築する必要もありました。そこで直面した課題は、膨大な数のスイッチとルーターを取り、それらを単一のシステムのごとく操作することでした。
独自のネットワーキングスタックと再定義したプロトコルの必要性から、GoogleはSoftware Defined Networking(SDN)へと移行。以下は、GoogleのVP、エンジニア、そしてネットワークインフラストラクチャチームのリーダーであるAmin Vahdat氏は、2015年の基調講演で同社が抱えている解決策とそれに対する解決策を説明しましました。
関連して、興味のある方はこちらのブログ記事もご覧ください。
Espresso
Espressoは、GoogleのSDNにおける最新の柱と言えます。Espressoにより、Googleのネットワークは物理的ルーターの制約を超え、ピアリングパートナーとの間で送受信されるトラフィックを学習、調整することができます。
また、接続のパフォーマンスをリアルタイムで測定し、特定の訪問者に適したPoPをリアルタイムデータに基づき決定。これによって、Googleのネットワークは、ピアリング/ISPパートナーのさまざまな混雑、減速、停止に柔軟に対応できるようになります。
さらにEspressoは、Googleの分散コンピューティングパワーを利用し、すべてのピアネットワークデータを分析することも可能です。すべてのルーティング制御とロジックは、個々のルーターやボーダーゲートウェイプロトコルに存在するのではなく、Googleのコンピューティングネットワークに転送されます(以下原文の日本語訳)。
大規模なコンピューティングインフラストラクチャとアプリケーションそのものからの信号を活用、エンドユーザーの質に対する認識に基づき、個々のフローがどのように実行されているかを学習する─Espresso makes Google cloud faster
Google Cloudネットワークとの関連性
ここまででご紹介した内容は、すべてGoogleが現在提供する最高のグローバルプライベートネットワークを構築するために乗り越えてきた問題と課題(ハードウェアベースとソフトウェアベースの両方)を強調するものでした。
市場占有率に関しては、Google Cloudは、AWS、Microsoft Azureに次いで世界3位。しかし、プレミアムプライベートネットワークインフラストラクチャに関しては、BroadBand Nowのデータによると、Googleが他を大きく引き離しています。
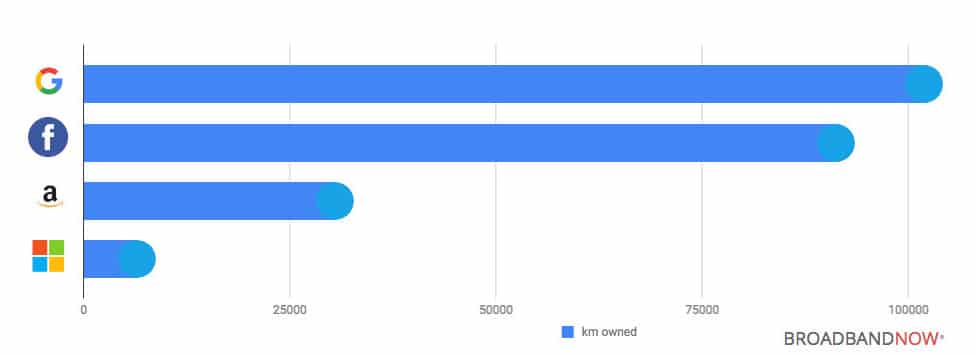
2014年、GigaOMはAWSとGoogle Cloudの比較記事を公開したものの、そのわずか1週間後、別の記事では「GoogleとAmazonのクラウドサービスの比較検討でファイバーという大事な点を見逃していたと述べています。同記事の中では、Googleがインフラストラクチャの面で何年も先を行っていることが記されています(以下原文の日本語)。
巨大かつ高速なパイプを顧客、そしてその顧客の顧客のトラフィックのために提供できるということは、非常に大きな意味を持つ—Barb Darrow氏
プレミアムティアとスタンダードティアネットワーク
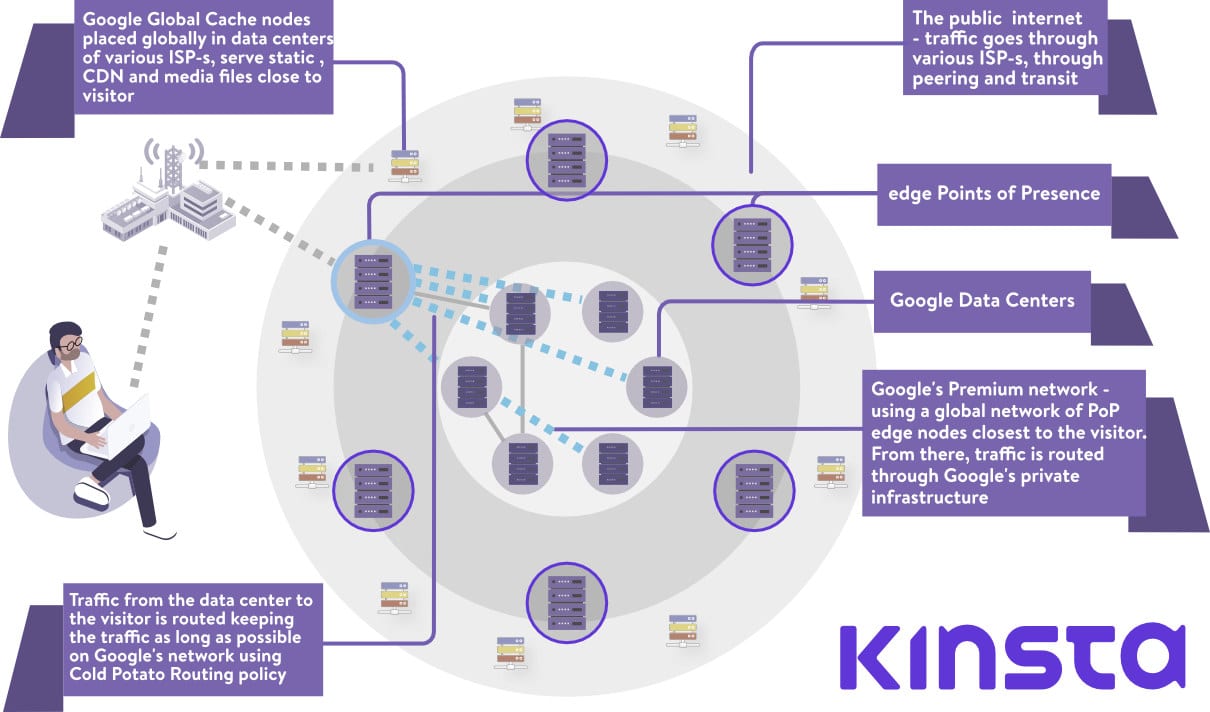
Google Cloudは、価格とパフォーマンスの両方が異なる2つのネットワークティアを提供しています。
プレミアムティアネットワーク
Googleのプレミアムティアネットワークを使用すると、世界各地に分散されたPoPからグローバルファイバーネットワークを利用できるようになります。利用者からGoogleのデータセンターへのすべてのイングレス(流入)トラフィックは、最も近いPoPにルーティングされ、その後リクエストは、100%Googleのプライベートバックボーンを介してルーティングされます。こちらの記事でも触れていますが、これはレイテンシの30%短縮、または帯域幅が50%拡大されることを意味します。
逆にデータセンターから利用者に送信されるすべてのデータは、 Cold Potatoポリシーに基づいてルーティングされます。スタンダードティアネットワークで使用されるHot Potatoルーティングでは、トラフィックは可能な限り早期に他のISPに渡され(またはドロップされ)ますが、プレミアムティアルーティングでは対照的に、出力トラフィックがGoogleのファイバーで可能な限り保持され、できる限り訪問者に近いピア、中継ISPへと渡されます。
簡単に言えば、プレミアムティアは、できる限りGoogleのネットワークを使用し、あちこち経由する必要性が削減されるため、パフォーマンスに優れています(しかし当然、その分料金が上がる)。
例えるなら、宇宙空間をただ漂うのではなく、目的地まで運んでくれるワームホールのようなもの(ややマニアックな表現ですが)。
Kinstaでは、すべてのプランにGoogle Cloudのプレミアムティアネットワークを採用。これにより距離とホップが最小限に抑えられ、データをより安全かつ高速に配信することができます。
スタンダードティアネットワーク
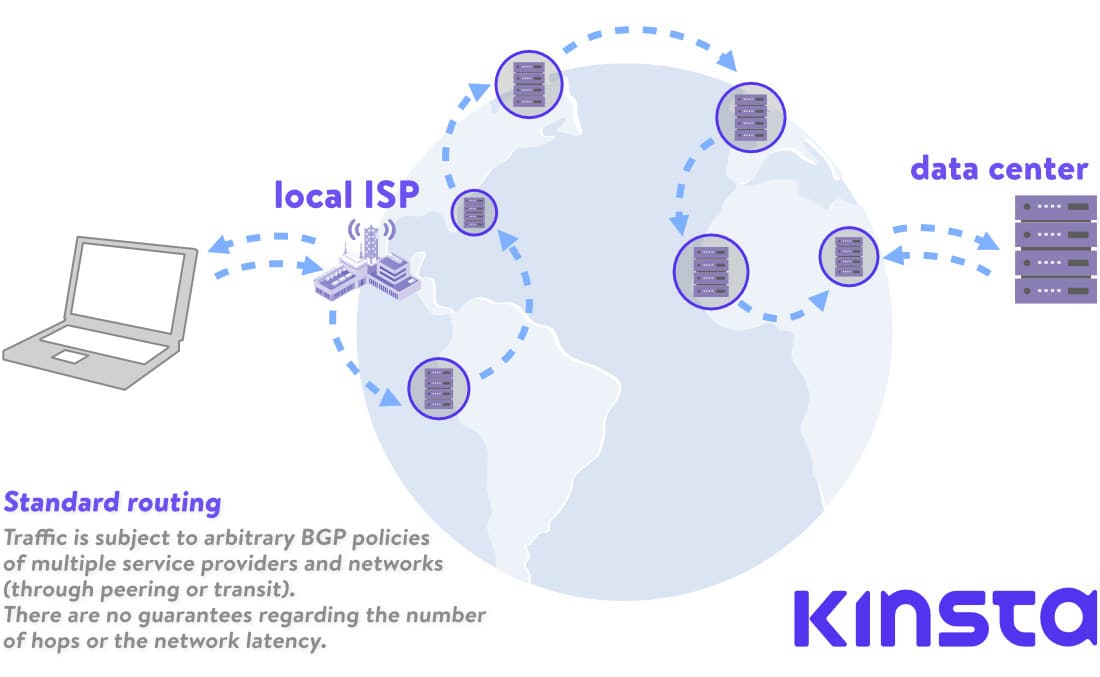
一方、スタンダードティアネットワークは、コンテンツまたはウェブアプリが存在するデータセンターの近くにあるPoPを使用します。訪問者のトラフィックは、目的地に到達するまで様々なネットワーク、自律システム、ISP、そして多くのホップを通過するため、速度は必然的に低下します。
スタンダードティアでは、GoogleのSDNと膨大なコンピューティングパワーの利点を最大限に活用し、適したルートを動的に計算されることはありません。トラフィックは、Googleと訪問者の間のすべてのシステムのBGPポリシーに左右されます。
簡単に言えば、スタンダードティアでは、Googleのネットワークを経由する時間が短くなり、パブリックネットワークでの処理時間が長くなるため、パフォーマンスが下がります(その分料金も下がる)。
さらに、プレミアムティアではグローバル負荷分散が行われますが、スタンダードティアではリージョナルに負荷を分散します。
プレミアムティアネットワークは、国際規模でのサービスレベル契約(SLA)を提供しており、Googleがある一定の質のサービスを提供する契約上の責任を負うことを意味します。これは品質保証のようなもので、スタンダードティアにはこのレベルのSLAは付随していません。
Google Cloudの公式サイトでは、この2つのティアのより詳しい比較を確認することができます。また、以下の図から自分に適したネットワークティアを簡単に見つけることも可能です。
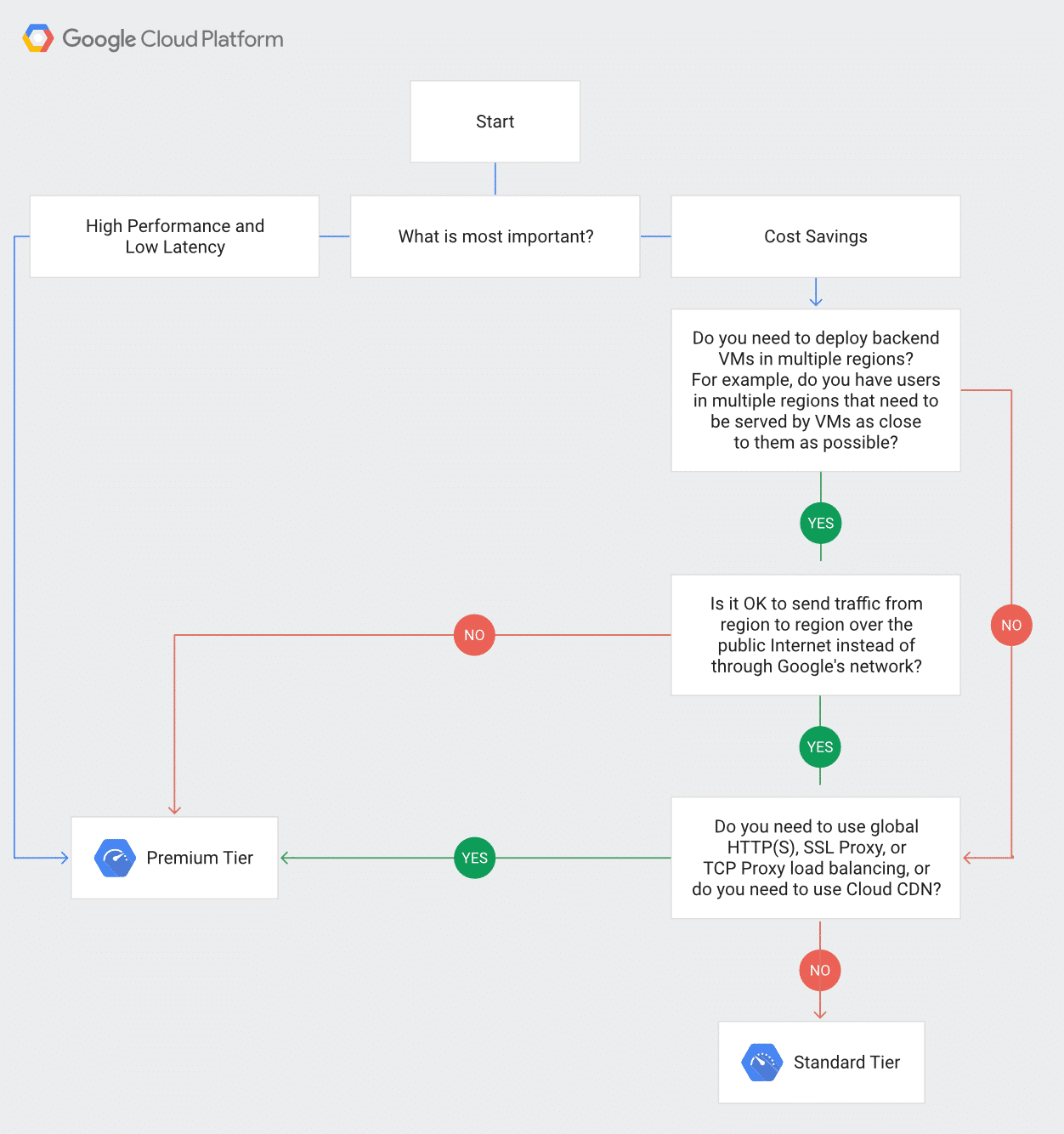
まとめ
Googleは長年にわたり、グローバルネットワーキングインフラストラクチャの作成、独自のプロトコルとハードウェア、ソフトウェアネットワーキングスタックの展開に投資しています。ムーアの法則が年々終焉に近づいていると思われる現在も、Googleのインフラストラクチャは、クラウドリソースに対する需要の高まりに対応しています。
市場シェアでは、AWSとMicrosoft Azureに遅れをとってはいるものの、Google Fiberとエンジニアによる最先端のハードウェア、およびソフトウェアソリューションの両方において、いくつかの面で決定的な優位性を持っています。
今後もGoogleがIoT、スマートシティ、自動運転といった技術で重要な役割を担い、エッジコンピューティングの需要は増え続けることが予想されます。
Google Cloudのプレミアムティアネットワークは、Googleの革新的なネットワーキングの成果を生かした最初の製品であり、Googleのネットワークとスタック全体を活用して、コンテンツを最高速度で配信することができます。SLAにより低レイテンシおよび高い稼働率が保証されています。
Kinstaは、世界規模で業界トップクラスのウェブアプリケーションサーバー、マネージドデータベースサーバー、およびWordPress専用マネージドクラウドサーバーを提供しています。Google Cloudのみを採用し、すべてのサーバープランにGoogleのプレミアムティアネットワークを使用しています。まずはリスクなしでその性能をお試しください。

起業家、LinuxとOSS愛好家、開発者、技術教育者。10年以上の開発経験を持ち、ブロックチェーンには3年以上携わる。コーディング以外には、SitePointとAlibaba Cloudに寄稿したり、Netflixで最新作を見たり、旅行先開拓に勤しんでいる。

