
Wenn du ein neues Projekt beginnst, ist es für Entwickler/innen oft schwierig, sich für einen Stack zu entscheiden. Die Wahl der richtigen Technologie zur Lösung eines Problems kann eine nervenaufreibende Erfahrung sein. Vor allem bei Datenbanken kann es schwierig sein, sich zu entscheiden, vor allem wenn du dir nicht sicher bist, wie deine Daten verwendet werden sollen.
Da Datenbanken ein grundlegendes Fundament der Softwareentwicklung sind und verschiedene Zwecke für Projekte aller Art und Größe erfüllen, ist es hilfreich, die Bedeutung von Datenbanken zu verstehen, um eine geeignete Datenbankstruktur für deinen Stack auszuwählen.
Dieser Artikel hilft dir bei der Auswahl der richtigen Open-Source-Datenbank, indem er die Unterschiede zwischen zwei großartigen Datenbankmanagementsystemen untersucht: MongoDB und PostgreSQL.
Was ist MongoDB?
MongoDB ist eine plattformübergreifende, nicht-relationale Open-Source-Datenbank, die am 11. Februar 2009 veröffentlicht wurde. Sie ist dafür bekannt, dass sie JSON-ähnliche Dokumente mit optionalen Schemata verwendet.
MongoDB gilt als einer der fortschrittlichsten Cloud-Datenbankdienste auf dem Markt und bietet eine beispiellose Datenmobilität und -verteilung in Azure, AWS und Google Cloud sowie eine integrierte Automatisierung zur Optimierung von Arbeitslast und Ressourcen.
Außerdem kannst du mit der Atlas CLI, der Benutzeroberfläche oder einem Infrastructure-as-a-Service (IaaS)-Ressourcenanbieter in wenigen Minuten eine Cloud-Datenbank erstellen.
Mit MongoDB Atlas kannst du deine Anwendung am Laufen halten, um mit dem steigenden Datenverkehr Schritt zu halten, wenn neue Funktionen in deine Pipeline aufgenommen werden. MongoDB Atlas bietet seinen Nutzern fortschrittliche Datenbankoptimierungstools, damit du immer über die Datenbankressourcen verfügst, die du für die Weiterentwicklung deiner Anwendung brauchst.
Hauptmerkmale
Hier sind einige der wichtigsten Merkmale von MongoDB, die sie zu einer der besten nicht-relationalen Datenbanken auf dem Markt machen:
- Leistungsberatung: Wenn sich deine Anwendungen weiterentwickeln, unterstützt dich MongoDB mit den besten On-Demand-Schema-Design-Praktiken für höchste Effizienz.
- Multi-Cloud-Cluster: Mit MongoDB kannst du belastbare und leistungsstarke Anwendungen entwickeln, die zwei oder mehr Clouds gleichzeitig nutzen.
- Lastausgleich: MongoDB ermöglicht eine kontrollierte Gleichzeitigkeit, um mehrere Client-Anfragen parallel zu anderen Servern zu bearbeiten. Dies kann dazu beitragen, die Last auf jedem Server zu verringern und gleichzeitig die Datenkonsistenz und Betriebszeit zu gewährleisten.
Anwendungsfälle
MongoDB wird von Tausenden von Unternehmen weltweit zur Datenspeicherung oder als Datenbankdienst für ihre Anwendungen genutzt.
MongoDB spielt eine zentrale Rolle bei:
- Content Management: Mit MongoDB kannst du jede Art von Inhalt bereitstellen und speichern, jede Funktion konstruieren und jede Art von Daten in eine einzige Datenbank einflechten. MongoDB macht dich mit Standard-Hardware und produktiveren Teams erfolgreich, so dass dein Projekt nur 10 % der Kosten verursacht, während du alle Funktionen für die Erstellung von inhaltsreichen Anwendungen nutzen kannst.
- Zahlungsverkehr: Wenn du ein neues Produkt für den Zahlungsverkehr entwickelst, wird die Datenagilität von MongoDB dafür sorgen, dass das neue Produkt schnell auf den Markt kommt, ohne dass du dich um unnötige Komplexität wie Datenfragmentierung kümmern musst. Auch wenn du ein reifes Unternehmen führst, das sein Zahlungssystem modernisieren will, kannst du die Flexibilität von MongoDB nutzen, um es als konsolidierte operative Datenschicht zu verwenden.
- Personalisierung: MongoDB ermöglicht es dir, die Erfahrungen von Millionen von Kunden in Echtzeit zu personalisieren, z. B. durch gezielte Angebote, angepasste Homepages und die Anmeldung bei sozialen Netzwerken. Du kannst sogar komplexe Abfragen direkt mit deinen Daten durchführen, ohne dich um das Transformieren, Extrahieren und Laden kümmern zu müssen.
- Mainframe-Offloading: Mit MongoDB kannst du Workloads ganz einfach vom Mainframe weg verlagern. Beim Mainframe-Offloading werden häufig genutzte Mainframe-Daten in eine auf MongoDB aufbauende operative Datenschicht (ODL) repliziert, auf die Operationen von konsumierenden Anwendungen umgelenkt werden können.
Was ist PostgreSQL?
Trotz der Beliebtheit von NoSQL-Datenbanken sind relationale Datenbanken aufgrund ihrer Robustheit und ihrer starken Abfragefähigkeiten weiterhin für verschiedene Anwendungen relevant.
Relationale Datenbanken eignen sich hervorragend für komplexe Abfragen und datenbasierte Berichte, wenn sich die Datenstruktur nicht häufig ändert. Open-Source-Datenbanken wie PostgreSQL sind im Vergleich zu ihren lizenzierten Kollegen wie SQL Server und Oracle eine kostengünstige Alternative als stabile Produktionsdatenbank.
PostgreSQL ist ein äußerst stabiles Datenbankmanagementsystem, das in über 20 Jahren gemeinschaftlicher Entwicklung ein hohes Maß an Integrität, Ausfallsicherheit und Korrektheit erreicht hat. Du kannst PostgreSQL als primäres Data Warehouse oder als Datenquelle für verschiedene mobile, geospatiale, analytische und Web-Anwendungen nutzen.
PostgreSQL ist außerdem lizenzkostenfrei, so dass das Risiko eines übermäßigen Einsatzes entfällt. Die engagierte Gruppe von Enthusiasten und Mitwirkenden findet regelmäßig Bugs und Lösungen und trägt so zur allgemeinen Sicherheit des Datenbanksystems bei.
Hauptmerkmale
Hier sind einige der wichtigsten Merkmale von PostgreSQL, die es zu einer der am häufigsten verwendeten Datenbanken machen:
- Nicht-atomare Spalten: Eine der Haupteinschränkungen eines relationalen Modells ist, dass Spalten atomar sein müssen. PostgreSQL kennt diese Einschränkung jedoch nicht und erlaubt Spalten mit Subwerten, auf die Abfragen leicht zugreifen können.
- Unterstützung für JSON-Daten: Die Fähigkeit, JSON abzufragen und zu speichern, ermöglicht es PostgreSQL, auch NoSQL-Workloads auszuführen – zum Beispiel, wenn du eine Datenbank entwirfst, um Daten von mehreren Sensoren zu speichern, und du dir nicht sicher bist, welche spezifischen Spalten du brauchst, um alle Arten von Sensoren zu unterstützen. In diesem Fall kannst du eine Tabelle so konstruieren, dass eine der Spalten JSON ist, um die sich ständig ändernden oder unstrukturierten Daten zu speichern.
- Fensterfunktionen: Die Fensterfunktionen von PostgreSQL spielen eine wichtige Rolle und machen sie zu einem Favoriten für Analyseanwendungen. Mit Window-Funktionen kannst du Funktionen ausführen, die sich über mehrere Zeilen erstrecken und die gleiche Anzahl von Zeilen zurückgeben. Fensterfunktionen unterscheiden sich von Aggregatfunktionen in dem Sinne, dass Aggregatfunktionen nach der Aggregation nur eine einzige Zeile zurückgeben können.
Anwendungsfälle
Hier sind ein paar Anwendungsfälle, in denen PostgreSQL nützlich ist:
- Föderierte Hub-Datenbank: Die JSON-Unterstützung und die Wrapper für Fremddaten ermöglichen es PostgreSQL, sich mit anderen Datenspeichern zu verbinden – einschließlich NoSQL-Typen – und als föderierter Knotenpunkt für polyglotte Datenbanksysteme zu dienen.
- Wissenschaftliche Daten: Wissenschaftliche und Forschungsprojekte können Terabytes an Daten erzeugen, die möglichst effizient und nutzbringend verwaltet werden müssen. PostgreSQL bietet eine wunderbare SQL-Engine mit robusten analytischen Fähigkeiten, die die Verarbeitung großer Datenmengen kinderleicht machen.
- Fertigung: Zahlreiche Industrieunternehmen von Weltrang nutzen PostgreSQL als Speicher-Backend, um Innovationen zu beschleunigen und das Wachstum durch kundenorientierte Prozesse voranzutreiben und die Leistung der Lieferkette zu optimieren.
- LAPP Open-Source Stack: PostgreSQL kann dynamische Anwendungen und Webseiten als Teil einer robusten Alternative zum LAMP-Stack ausführen. LAPP steht für Linux, Apache, PostgreSQL, Python, PHP und Perl.
MongoDB vs. PostgreSQL: Kopf-an-Kopf-Vergleich
Die eigentliche Frage ist nicht MongoDB vs. PostgreSQL, sondern vielmehr die beste Dokumentendatenbank vs. die beste relationale Datenbank.
Oft haben die Projektleiter zu Beginn eines Entwicklungsprojekts ein gutes Verständnis für den Anwendungsfall, sind sich aber nicht im Klaren darüber, welche spezifischen Anwendungsfunktionen ihre Nutzer und ihr Unternehmen benötigen. Am Ende müssen sie sich auf eine Entscheidung festlegen und hoffen, dass sie die beste Lösung ist.
Im nächsten Abschnitt erläutern wir die Unterschiede zwischen MongoDB und PostgreSQL, damit du die Entscheidung leichter treffen kannst. Unsere Informationen basieren auf Schlüsselfaktoren wie Architektur, ACID-Konformität, Erweiterbarkeit, Replikation, Sicherheit und Support, um nur einige zu nennen.
Lass uns eintauchen!
ACID-Konformität
Eine der wichtigsten Eigenschaften von relationalen Datenbanken, die das Schreiben von Anwendungen vereinfachen, sind ACID-Transaktionen. Was die Isolationsebenen innerhalb von Datenbanktransaktionen angeht, so verwendet PostgreSQL standardmäßig die Isolationsebene „Read Committed“. PostgreSQL ermöglicht es den Nutzern auch, die Read-Committed-Isolation-Level bis hin zur Serializable-Isolation-Level einzustellen.
Wichtig dabei ist, dass Transaktionen es ermöglichen, verschiedene Änderungen an einer Datenbank in einer Gruppe vorzunehmen oder rückgängig zu machen. In einer relationalen Datenbank würden die Daten daher in unabhängigen Eltern-Kind-Tabellen in einem tabellarischen Schema modelliert werden.
Im Vergleich dazu haben es Dokumentendatenbanken leichter, Transaktionen auszuführen, weil sie die Daten in einem Dokument zusammenfassen und da das Lesen und Schreiben ein atomarer Vorgang ist, ist keine Transaktion für mehrere Dokumente erforderlich.
MongoDB unterstützt eine vollständige Isolierung, während ein Dokument aktualisiert wird. Bei Fehlern wird der Aktualisierungsvorgang zurückgesetzt, sodass die Änderung rückgängig gemacht wird und die Clients eine konsistente Ansicht des Dokuments erhalten.
MongoDB unterstützt auch Datenbanktransaktionen über mehrere Dokumente hinweg, so dass zusammengehörige Änderungen als Gruppe zurückgesetzt oder bestätigt werden können. Dank der Fähigkeit zu dokumentenübergreifenden Transaktionen ist MongoDB eine der wenigen Datenbanken, die die Flexibilität, Geschwindigkeit und Leistungsfähigkeit des Dokumentenmodells mit den ACID-Garantien herkömmlicher Datenbanken verbindet.
Architektur/Dokumentenmodell
Das Dokumentenmodell von MongoDB ermöglicht eine natürliche Zuordnung von Benutzern zu Objekten innerhalb des Anwendungscodes, wodurch es für Full-Stack-Entwickler einfacher zu erlernen und zu nutzen ist. Dokumente bieten dir die Möglichkeit, hierarchische Beziehungen darzustellen, um Arrays und andere komplexere Strukturen einfach zu speichern.
Durch die Speicherung von Daten in Feldern wie verschachtelten Unterdokumenten und Arrays können zusammengehörige Informationen in JSON-Dokumenten für einen schnellen Abfragezugriff über die MongoDB-Abfragesprache zusammen gespeichert werden.
Mit MongoDB kannst du Daten als Dokumente in einer binären Darstellung speichern, die als binäres JSON (BSON) bekannt ist. Die Felder können sich je nach Dokument unterscheiden. Daher ist es nicht nötig, dem System die Struktur der Dokumente mitzuteilen – Dokumente sind selbstbeschreibend.
Wenn du ein neues Feld zu einem Dokument hinzufügen möchtest, kann dieses Feld generiert werden, ohne dass sich dies auf andere Dokumente in der Sammlung auswirkt oder ein ORM oder ein zentraler Systemkatalog aktualisiert werden muss.
MongoDB bietet dir auch die Möglichkeit der Schema-Validierung, um Data Governance-Kontrollen für jede Sammlung durchzusetzen. Diese Flexibilität ist praktisch, wenn du Informationen aus verschiedenen Quellen zusammenstellst oder Änderungen an Dokumenten im Laufe der Zeit berücksichtigst, vor allem, wenn die neue Anwendungsfunktionalität konsequent eingesetzt wird.
PostgreSQL verfügt über ein Client-Server-Architekturmodell, das aus den folgenden zwei Prozessen besteht:
- Client-seitiger Prozess: Dies sind die Anwendungen, mit denen die Benutzer mit der Datenbank interagieren. In der Regel haben sie eine einfache Benutzeroberfläche und kommunizieren über APIs zwischen dem Benutzer und der Datenbank.
- Serverseitiger Prozess: Dies ist die „Postgres“-Anwendung, die sich um Operationen, Verbindungen, dynamische und statische Werte kümmert. Eine laufende PostgreSQL-Site wird von einem Postmaster verwaltet, einem zentralen koordinierenden Prozess. Der Postmaster-Daemon ist verantwortlich für:
- Durchführen der Wiederherstellung
- Initialisierung des Servers
- Herunterfahren des Servers
- Ausführen von Hintergrundprozessen
- Verbindungsanfragen von neuen Clients verwalten
.
Erweiterbarkeit
Erweiterbarkeit ist einfach die Eigenschaft, dass sie so konzipiert ist, dass neue Fähigkeiten oder Funktionalitäten hinzugefügt werden können.
PostgreSQL unterstützt die Erweiterbarkeit auf verschiedene Arten, einschließlich gespeicherter Funktionen und Prozeduren. Was PostgreSQL umfangreich macht, sind seine kataloggesteuerten Operationen.
Relationale Datenbanken speichern Informationen über Tabellen, Datenbanken, Spalten usw. oft in Systemkatalogen. Diese „Datenverzeichnisse“ erscheinen dem Benutzer als Tabellen, aber sie enthalten auch Informationen, die intern vom Datenbanksystem gespeichert werden.
PostgreSQL speichert die Informationen über die Spalten und Tabellen zusammen mit den Informationen über die vorhandenen Datentypen, Funktionen und Zugriffsmethoden.
Das ist noch nicht alles: PostgreSQL kann auch vom Benutzer geschriebenen Code durch dynamisches Laden in sich selbst einbinden. Oft benötigen die Benutzer bestimmte Funktionen, die über gemeinsam genutzte Bibliotheken implementiert werden können. Die Benutzer können einfach die Codedatei angeben und PostgreSQL lädt sie nach Bedarf.
Andererseits ist MongoDB inzwischen erweiterbar, so dass die Nutzer/innen eigene Funktionen erstellen und innerhalb des Frameworks verwenden können. Das entspricht den benutzerdefinierten Funktionen (UDF), mit denen Nutzer von relationalen Datenbanken (wie PostgreSQL) SQL-Anweisungen erweitern können.
Außerdem unterstützen sowohl PostgreSQL als auch MongoDB verschiedene Erweiterungen und Plugins wie Adminer für die Datenbankverwaltung.
Kollaboration und Agilität
MongoDB hat ein Dokumentenmodell, das die Zusammenarbeit und Entwicklung einfacher und schneller macht. MongoDB verwendet im Wesentlichen JSON oder BSON, um seine Daten als Dokumente zu speichern.
BSON enthält mehrere Datentypen, die in JSON-Daten nicht vorkommen, wie DateTime, long, int und byte array, die eine effizientere Datenverarbeitung ermöglichen, da sie spezifischer auf den Datentyp abgestimmt sind, anstatt alles wie ein universeller „Zahlentyp“ zu behandeln. Abfragen werden schneller ausgeführt, da sie in einem Serialisierungsformat vorliegen, das JSON-ähnliche Dokumente effektiv archiviert.
BSON überspringt die Schlüssel, die für die Abfrage nicht nützlich sind, und ermöglicht so ein schnelleres Abrufen der Daten. Ein Nutzer kann die Struktur des Dokuments weiter definieren und es weiterentwickeln, indem er neue Felder einführt, Daten überarbeitet oder es nach eigenem Ermessen weiterentwickelt.
Diese Flexibilität ist ein enormer Vorteil für MongoDB, da sie dazu beiträgt, Verzögerungen zu vermeiden, die dadurch entstehen, dass der Administrator aufgefordert wird, die Anweisungen der Datendefinitionssprache umzustrukturieren und dann mit der Neuerstellung oder dem Neuladen einer Datenbank von vorne zu beginnen.
MongoDB erleichtert auch die Zusammenarbeit zwischen Entwicklern oder Teams, so dass keine Zwischenschaltung oder komplizierte Kommunikation zwischen den Teams erforderlich ist.
Für die Zusammenarbeit bietet PostgreSQL Berechtigungen auf Benutzerebene, Rollenvererbung und Berechtigungen auf Tabellenebene. Du kannst Benutzer verwalten und ihnen Lese- und Schreibrechte erteilen.
Außerdem kannst du mit der Auditing-Option die Datenzugriffsaktivitäten verschiedener Gruppen oder Benutzer/innen überprüfen, was eine zusätzliche Sicherheitsebene darstellt. PostgreSQL ist jedoch nicht so schnell wie MongoDB, da es eine relationale Datenbank ist, die Daten in Zeilen und Spalten speichert.
Unterstützung von Fremdschlüsseln
Eine wichtige Eigenschaft, die MongoDB von PostgreSQL unterscheidet, ist die Art und Weise, wie die Daten gespeichert werden.
Da es sich um eine nicht-relationale Datenbank handelt, verwendet MongoDB Sammlungen anstelle von Tabellen. Ein Fremdschlüssel ist einfach eine Gruppe von Attributen in einer Tabelle, die auf den Primärschlüssel einer anderen Tabelle verweist. Der Fremdschlüssel verbindet diese beiden Tabellen miteinander.
Da es in MongoDB keine Tabellen gibt, gibt es in MongoDB auch keine Fremdschlüssel und somit auch keine Fremdschlüssel-Beschränkungen. Allerdings gibt es in MongoDB einen DBRef-Standard, mit dem die Erstellung der Referenzen standardisiert wird.
PostgreSQL hingegen unterstützt Fremdschlüssel, da es SQL-kompatibel ist. Durch die Aktivierung von Fremdschlüssel-Beschränkungen kann PostgreSQL das Einfügen von ungültigen Daten in Fremdschlüsselspalten verhindern.
Partitionierung und Sharding
Beim Partitionieren und Sharding geht es im Wesentlichen darum, große Datensätze in kleinere Teilmengen aufzuteilen. Sharding bedeutet, dass die Daten auf mehreren Computern gespeichert werden, während Partitioning diese Daten in einer einzigen Datenbankinstanz zusammenfasst.
MongoDB ist skalierbar, weil es die Daten auf mehrere Instanzen innerhalb des Clusters aufteilt. Die Dokumente werden nicht in Teile aufgeteilt, da sie unabhängige Einheiten sind, was es einfacher macht, sie auf verschiedene Server zu verteilen, während die Daten lokal erhalten bleiben.
Über den Cloud-Dienst MongoDB Atlas können die Daten problemlos über verschiedene Regionen verteilt werden. Du kannst auch wählen, ob du sie ständig in bestimmten Regionen oder in globalen Regionen speichern willst, um eine geringere Latenz zu gewährleisten.
Seit Version 5.0 verfügt MongoDB über eine „Live“-Resharding-Funktion, die dir viel Zeit spart, da du nur eine Richtlinie festlegen musst. Die Datenbank kann die Daten automatisch umverteilen, wenn es soweit ist.
Früher konnte man das tun, ohne das System herunterzufahren, aber der Prozess war kompliziert und riskant. Während MongoDB eine Zeit lang über eine globale Geopartitionierung verfügte, wuchsen die Daten in den verschiedenen Ländern unterschiedlich schnell. Live Resharding könnte für Daten, die innerhalb eines Landes lokal bleiben müssen, von Vorteil sein.
PostgreSQL hingegen unterstützt die deklarative Partitionierung, d. h. eine Möglichkeit, die Aufteilung einer Tabelle in Partitionen festzulegen. Die Tabelle, die aufgeteilt wird, wird partitionierte Tabelle genannt, die Spezifikation besteht aus der Partitionierungsmethode und die Liste der zu verwendenden Spalten oder Ausdrücke wird Partitionsschlüssel genannt.
Du kannst die Partitionierung über einen Bereich implementieren, wobei die Tabelle durch Bereiche partitioniert werden kann, die durch eine Schlüsselspalte oder eine Reihe von Spalten definiert sind, ohne dass sich die den verschiedenen Partitionen zugewiesenen Wertebereiche überschneiden.
Du kannst auch eine Listenpartitionierung implementieren, bei der die Tabelle nach den angegebenen Schlüsselwerten partitioniert wird.
Replikation
Bei der Replikation wird eine Kopie desselben Datensatzes auf mehr als einem Server erstellt. Sie ermöglicht es Datenbankadministratoren, eine hohe Datenredundanz und eine hohe Verfügbarkeit der Daten zu gewährleisten.
Bei MongoDB wird dies durch die Verwendung eines „Replikatsets“ erreicht – ein synchronisierter Cluster, der aus drei oder mehr Servern besteht, zwischen denen die Daten ständig repliziert werden. Dies bietet Redundanz und Schutz vor Ausfallzeiten, die bei einer geplanten Wartungspause oder einem Systemausfall auftreten können, und erhöht so die Fehlertoleranz der Datenbank.
Replikatsätze können auch über verschiedene Rechenzentren hinweg implementiert werden, da sie bei regionalen Ausfällen sehr nützlich sind. Dies ist mit MongoDB Atlas möglich, der den Aufbau und die Konfiguration dieser Cluster vereinfacht und beschleunigt.
PostgreSQL bietet eine Primär-Sekundär-Replikation. Write-ahead Logs ermöglichen es, die Änderungen mit den Replikationsknoten zu teilen, wodurch eine asynchrone Replikation möglich wird. Andere Replikationsarten sind die logische Replikation, die Streaming-Replikation und die physische Replikation.
Indizes
Indizes sind Objekte oder Strukturen, die es uns ermöglichen, bestimmte Zeilen oder Daten schneller abzurufen.
PostgreSQL bietet eine Reihe einzigartiger Indextypen, um jede Abfrage effizient bearbeiten zu können. Zu den Indexierungstechniken gehören B-Bäume, Mehrspaltenindizes und Ausdrücke. Darüber hinaus können in PostgreSQL auch partielle und erweiterte Indexierungstechniken wie GiST, KNN Gist, SP-Gist, GIN, BRIN, abdeckende Indizes und Bloomfilter implementiert werden.
MongoDB hingegen ermöglicht es dir, Daten in jeder Struktur zu speichern, auf die durch Indizierung schnell zugegriffen werden kann, egal wie tief sie in Arrays oder Unterdokumenten verschachtelt sind.
Sprache und Syntax
Sowohl MongoDB als auch PostgreSQL unterstützen eine Vielzahl von Sprachen.
MongoDB bietet Treiberunterstützung für einige der besten Datenbanksprachen wie Python, R, Java, Scala, C, C++, C#, Node.js und viele mehr. Diese MongoDB-Bibliotheken und -Treiber unterstützen alle Funktionen von MongoDB und sorgen für hohe Leistung und Skalierbarkeit in allen Anwendungen.
PostgreSQL unterstützt mehrere prozedurale Sprachen mit einer Basisdistribution wie PL/pgSQL, PL/Python, PL/Perl und PL/Tcl sowie andere Sprachen, die außerhalb der PostgreSQL-Kerndistribution entwickelt und gepflegt werden, wie PL/Java, PL/PHP und PL/Ruby.
Normalisierung
Normalisierung ist der Prozess der Strukturierung einer relationalen Datenbank, um Datenredundanz zu reduzieren, Anomalien bei der Datenänderung zu minimieren und die Datenintegrität zu verbessern.
MongoDB kann sowohl mit normalisierten als auch mit denormalisierten Datenmodellen (auch als eingebettete Modelle bekannt) umgehen.
Eingebettete Modelle ermöglichen es Anwendungen, zusammenhängende Informationen im selben Datenbankdatensatz zu speichern, was zu einer besseren Leistung bei Lesevorgängen führt und die Möglichkeit bietet, zusammenhängende Daten in einem einzigen Datenbankvorgang abzurufen.
Außerdem kannst du zusammenhängende Daten in einer einzigen atomaren Schreiboperation aktualisieren, während Anwendungen weniger Abfragen stellen müssen, um gemeinsame Operationen durchzuführen. Dokumente in MongoDB für das eingebettete Datenmodell müssen kleiner sein als die maximale BSON-Dokumentgröße (16 MB).
Normalisierte Datenmodelle beschreiben Beziehungen durch Referenzen zwischen Dokumenten. Dies ist vorteilhaft, wenn die Einbettung zu Datenduplikaten führen kann, die Vorteile bei der Leseleistung aber nicht ausreichen, um die Auswirkungen der Duplikate zu überwiegen.
Allerdings verursacht der Denormalisierungsprozess in der Regel einen hohen Speicherverbrauch, wenn zuvor normalisierte Daten in einer Datenbank gruppiert werden, um die Leistung zu erhöhen.
PostgreSQL-Schemas haben eine identifizierte Beziehung. Die Struktur kann mit einer 1:1, 1:many oder many:1 Beziehung identifiziert werden. Die Normalisierung von Daten kann sehr vorteilhaft sein, da sie redundante Kopien von Daten beseitigt und damit auch die Integrität gewährleistet.
Leistung
Die Bewertung der Leistung von zwei verschiedenen Datenbanksystemen ist eine Herausforderung, da sowohl MongoDB als auch PostgreSQL die Daten auf unterschiedliche Weise speichern und abrufen.
MongoDB wurde für die horizontale Skalierung entwickelt, da es seine Leistung oft mit zusätzlichen Maschinen kombiniert und nicht auf die Rechenleistung angewiesen ist. Sie ist in der Lage, riesige Anwendungen zu betreiben, unabhängig von der Größe der Daten oder der Anzahl der Nutzer.
MongoDB eignet sich auch für Anwendungsfälle, die eine schnelle Ausführung von Abfragen erfordern und eine große Datenmenge verarbeiten können. Sie kann insgesamt Hunderte von Maschinen umfassen.
Seit MongoDB 4.4 sorgen Abfragen, die gegen Replikatsätze ausgeführt werden, für eine verbesserte und vorhersehbare Leistung durch „abgesicherte“ Lesevorgänge. Diese Lesevorgänge werden an mehrere Knoten innerhalb des Replikatsets gerichtet, bis der schnellste Knoten antwortet.
PostgreSQL ist zwar nicht so schnell wie MongoDB, was die reine Einfügegeschwindigkeit angeht, aber dafür übertrifft es die ACID-Konformität. Transaktionen werden sicher und zuverlässig verarbeitet, so dass eine ganze Transaktion fehlschlagen kann, anstatt einen teilweise erfolgreichen Schreibvorgang auszuführen.
MongoDB hat erst vor kurzem (mit Version 4) damit begonnen, ACID-Transaktionen ähnlich wie SQL-Datenbanken zu unterstützen.
Im Gegensatz zu MongoDB ist PostgreSQL auf eine Skalierungsstrategie (vertikale Skalierung) für Datenvolumen und Schreibvorgänge angewiesen. Dazu werden einem bestehenden Datenbankknoten weitere Hardware-Ressourcen wie Festplatten, CPUs und Speicher hinzugefügt.
PostgreSQL hat jedoch einige Anstrengungen zur Leistungsoptimierung unternommen, z. B. einen ausgereiften Query Planner, Just-in-Time-Kompilierung (JIT) von Ausdrücken, Tabellenpartitionierung und Parallelisierung von Leseabfragen.
Preis
PostgreSQL ist völlig kostenlos und quelloffen. Daher kann jeder seine Funktionen nutzen und bei Bedarf problemlos Änderungen am Code vornehmen.
MongoDB ist ebenfalls ein Open-Source-Tool. Allerdings gibt es für MongoDB auch andere Optionen wie Enterprise und Atlas (für die Cloud), die unterschiedliche Preise haben. Für die MongoDB Enterprise Edition wird ein On-Premise-Preismodell angeboten.
Mongo RealmDB steht allen Atlas-Nutzern kostenlos zur Evaluierung und leichten Nutzung zur Verfügung und ermöglicht es Entwicklern, mobile Anwendungen zu erstellen und zu veröffentlichen.
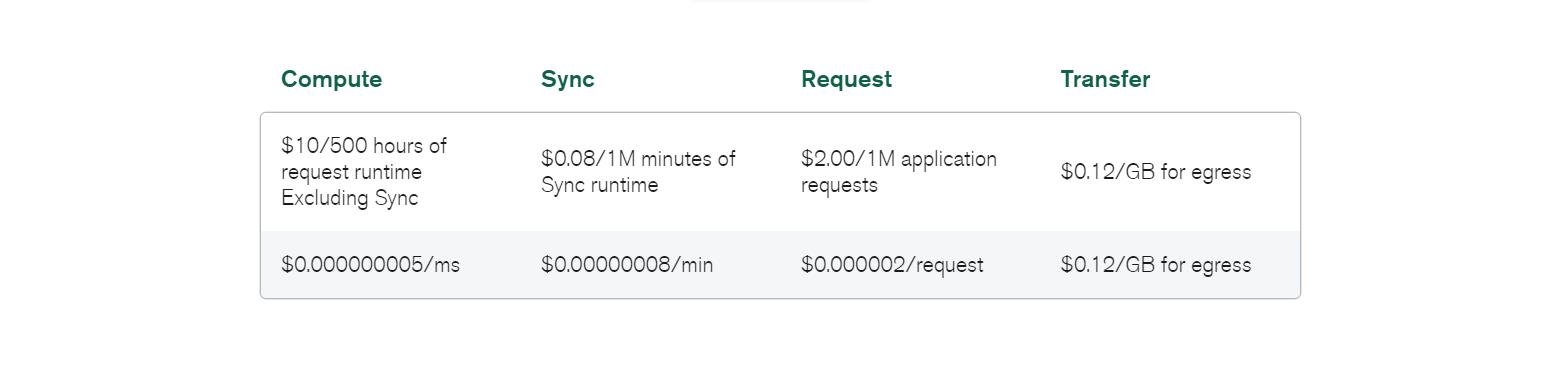
Auch bei der Datenmigration kann es zu einem Mehraufwand kommen; dies ist jedoch unabhängig von der Datenbank, die du in deinem System implementiert hast, Standard.
Abfrageverarbeitung
PostgreSQL verwendet das relationale Datenbankmodell, bei dem die Daten in Tabellen gespeichert werden und die strukturierte Abfragesprache (SQL) für den Datenbankzugriff verwendet wird. SQL-Befehle können mit dem PostgreSQL-Terminal psql eingegeben werden. PostgreSQL verfügt über eine Large-Object-Funktion, die einen Stream-ähnlichen Zugriff auf Benutzerdaten ermöglicht, die in einer speziellen Large-Object-Struktur gespeichert sind.
Bevor die Daten hinzugefügt werden, muss das Datenbankschema erstellt werden, um ein klares Verständnis der Datenbeziehungen zu erhalten, damit die Abfragen bearbeitet werden können. Zusammenhängende Informationen können in separaten Tabellen in der Datenbank gespeichert werden. Auf diese kann über Fremdschlüssel und Joins zugegriffen werden.
Es kann schwierig sein, die Struktur der Datenbank anzupassen, sobald sie geladen ist. Es braucht mehrere Teams in der Entwicklung, im Betrieb und den Datenbankadministrator, um die Änderungen an der Struktur sorgfältig zu koordinieren.
Auf der anderen Seite muss die Datenstruktur von MongoDB nicht im Voraus geplant werden, da sie im Wesentlichen mit unstrukturierten Daten arbeitet. Die Datenstruktur lässt sich auch viel einfacher anpassen.
Die Entwickler können auswählen, was für die Anwendung wichtig ist, und die erforderlichen Änderungen vornehmen. MongoDB verwendet MQL, mit dem man mit Dokumenten in MongoDB arbeiten und Daten herausnehmen kann, während man gleichzeitig die Flexibilität und Leistungsfähigkeit von SQL hat.
MongoDB verarbeitet Daten als JSON-Dokumente. Du kannst auch nach den Feldern innerhalb des JSON-Dokuments fragen. MongoDB ist also sehr nützlich, wenn du Dokumente in einem flexiblen Datenfeld speichern willst.
Während PostgreSQL die Funktion GROUP_BY verwendet, um Aggregatabfragen zu verarbeiten und auszuführen, verwendet MongoDB in der Regel Aggregationspipelines, um seine Abfragen zu verarbeiten.
Ein großer Nachteil von MongoDB ist jedoch, dass du Tabellen nicht einfach verbinden kannst. In PostgreSQL ist das mit einer JOIN-Anweisung ganz einfach.
MongoDB hat versucht, dieses Problem zu lösen, indem es mehrdimensionale Datentypen eingeführt hat, mit denen du einen Dokumentenspeicher in einen anderen einbetten kannst. Das ist jedoch unübersichtlich und nicht so elegant wie die einfache join Funktion, die PostgreSQL integriert hat.
Sicherheit
Wenn es um die Sicherheit geht, übertrumpft PostgreSQL MongoDB. Die strengen Regeln für die Struktur der Datenbank machen PostgreSQL zu einer sehr sicheren Datenbank, so dass sie zuverlässig für Bankensysteme verwendet werden kann.
PostgreSQL bietet eine Vielzahl von Authentifizierungsmethoden, darunter ein Pluggable Authentication Module (PAM) und das Lightweight Directory Access Protocol (LDAP), die die Angriffsfläche der Server reduzieren. Außerdem wird der Schutz auf Serverebene durch hostbasierte Authentifizierung und Zertifikatsauthentifizierung gewährleistet.
Darüber hinaus bietet PostgreSQL Datenverschlüsselung und ermöglicht die Verwendung von SSL-Zertifikaten, wenn deine Daten über das Web oder öffentliche Netzwerke übertragen werden. PostgreSQL ermöglicht es dir auch, die Client-Zertifikat-Authentifizierungs-Tools (CCA) als Option zu implementieren und kryptogene Funktionen zu verwenden, um verschlüsselte Daten in PostgreSQL zu speichern.
Das Sicherheitsniveau von PostgreSQL kann sich jedoch von einem Cloud-System zum anderen unterscheiden, auch wenn es sich um dieselbe Datenbank handelt.
MongoDB Atlas funktioniert bei den drei größten Cloud-Anbietern auf die gleiche Weise, was die Migration zwischen mehreren Clouds erleichtert.
Außerdem verfügt MongoDB über eine clientseitige Verschlüsselung und eine Verschlüsselung auf Feldebene, die es den Nutzern ermöglicht, Daten zu verschlüsseln, bevor sie sie über das Netzwerk an die Datenbank senden. Da die Daten jedoch in Schlüssel-Wert-Paaren in einem Datensatz gespeichert werden, ist die Sicherheit nicht so hoch wie bei PostgreSQL; der Schwerpunkt von MongoDB liegt auf der Geschwindigkeit.
Unterstützung & Gemeinschaft
PostgreSQL ist vollständig quelloffen und wird von seiner Community unterstützt, was es als vollständiges Ökosystem stärkt. PostgreSQL veröffentlicht regelmäßig aktualisierte Versionen, und Entwickler, Enthusiasten oder Drittfirmen bieten Unterstützung und versuchen, das System weiterzuentwickeln, indem sie Fehler beheben oder kleine Änderungen am Datenbanksystem vornehmen.
Wie PostgreSQL verfügt auch MongoDB über ein Community-Forum, in dem sich die Nutzer/innen mit anderen Nutzer/innen austauschen und ihre allgemeinen Fragen beantworten lassen können. Der MongoDB-Unternehmenssupport kann außerdem eine umfangreiche Wissensdatenbank mit Anwendungsfällen, detaillierten Tutorials, technischen Hinweisen zu Optimierungen und Best Practices umfassen.
Außerdem gibt es kostenlose Online-Kurse mit Schulungen und Zertifizierungen, die von MongoDB angeboten werden.
Herausforderungen
Wir haben zwar die Eigenschaften von MongoDB und PostgreSQL besprochen, die sie zu einem Hit bei den Entwicklern machen, aber sie haben auch ihre Schwächen.
MongoDB legt den Schwerpunkt auf schnelle Datenverarbeitung, hat aber nicht die Datensicherheit, die PostgreSQL zu bieten hat. MongoDB ist ziemlich speicherintensiv, da der Denormalisierungsprozess in der Regel einen hohen Speicherverbrauch verursacht.
Da es keine Unterstützung für Joins gibt, werden MongoDB-Datenbanken außerdem mit zu vielen Daten gefüllt – manchmal sogar doppelt – und belasten so den Speicher stark. MongoDB hat auch versucht, die Interpretation in andere Abfragesprachen als Teil seiner Erweiterbarkeit einzubeziehen; dies kann jedoch die Leistung beeinträchtigen, da die Datenbank ursprünglich nicht für relationale Datenmodelle entwickelt wurde.
Die Übersetzung von SQL- in MongoDB-Abfragen kann zusätzliche Zeit in Anspruch nehmen, was den Einsatz und die Entwicklung verzögern kann.
Auf der anderen Seite ist PostgreSQL zwar einfach zu installieren und an fast alle Plattformen anpassbar, aber seine Effizienz kann sich von Plattform zu Plattform unterscheiden. Außerdem gibt es keine Überprüfungswerkzeuge oder Berichtsinstrumente, die den aktuellen Zustand der Datenbank anzeigen könnten. Möglicherweise musst du die Datenbank ständig überprüfen, wenn etwas nicht so läuft wie geplant, damit du einen Fehler nicht erst bemerkst, wenn es zu spät ist.
PostgreSQL ist auch etwas langsamer, da es sich auf Kompatibilität konzentriert. Es wurden zwar Anstrengungen unternommen, um die Geschwindigkeit von PostgreSQL zu verbessern, aber die Änderungen sind noch nicht ganz ausgereift.
MongoDB vs. PostgreSQL: Wofür solltest du dich entscheiden?
MongoDB ist eine nicht-relationale Datenbank, während PostgreSQL eine relationale Datenbank ist. Während NoSQL-Datenbanken die Daten in Schlüssel-Wert-Paaren als einen Datensatz speichern, speichern relationale Datenbanken die Daten in verschiedenen Tabellen.
Wenn du Wert auf schnellere Datenintegration und Skalierbarkeit über mehrere Server hinweg legst, könnte MongoDB die richtige Wahl für dein Unternehmen sein.
MongoDB funktioniert am besten, wenn es in eine Analyseplattform integriert wird, denn die Geschwindigkeit von MongoDB sorgt für eine dynamische Leistung, mit der das Verhalten der Nutzer/innen in Echtzeit verfolgt werden kann. MongoDB kann auch von großem Nutzen für dein Unternehmen sein, wenn du eine viel genutzte Webanwendung hast, die nicht auf ein strukturiertes Schema angewiesen ist, wie z. B. die New York Times (die tatsächlich MongoDB nutzt), oder für Produktkataloge, in denen du mehrere Objekte mit verschiedenen Attributsammlungen speichern musst.
Andererseits ist PostgreSQL die perfekte Lösung für Datenanalyse und Warehousing. Wenn du ein Datenbank-Automatisierungstool oder eine Bankanwendung entwickelst, bei der du Wert auf Datensicherheit und Transaktionsgarantien legst, könnte PostgreSQL die richtige Lösung sein.
Zusammenfassung
Zusammenfassend haben wir bisher die grundlegenden Details von PostgreSQL und MongoDB behandelt. Wir haben ihre Geschichte, die wichtigsten Funktionen und die Unterschiede zwischen ihnen besprochen.
Obwohl sowohl PostgreSQL als auch MongoDB hervorragende Datenbanken sind, kommt es letztendlich auf dich an, die richtige Datenbank für dein Unternehmen zu wählen.
Welche der beiden Datenbanken, PostgreSQL oder MongoDB, bevorzugst du? Lass es uns in den Kommentaren wissen!

Salman Ravoof ist ein autodidaktischer Webentwickler, Autor, Kreativer und ein großer Bewunderer von Free and Open Source Software (FOSS). Neben Technik begeistert er sich für Wissenschaft, Philosophie, Fotografie, Kunst, Katzen und Essen. Erfahre mehr über ihn auf seiner Website und trete mit Salman auf X in Kontakt.

