
Quando si inizia a sviluppare un nuovo progetto, una delle difficoltà che si possono incontrare è la scelta dello stack. Individuare la tecnologia giusta per risolvere un problema può essere un’esperienza snervante. In particolare, i database possono essere difficili da scegliere, soprattutto se non vi è chiaro come verranno usati i dati.
Poiché i database sono una base fondamentale per lo sviluppo del software e servono a vari scopi per la realizzazione di progetti di ogni tipo e dimensione, è utile capire l’importanza dei database per scegliere una struttura di database appropriata per il vostro stack.
Questo articolo vi aiuterà a scegliere il giusto database open-source esplorando le differenze tra due grandi sistemi di gestione di database: MongoDB e PostgreSQL.
Cos’È MongoDB?
MongoDB è un database non relazionale multipiattaforma e open-source rilasciato l’11 febbraio 2009. È noto per l’utilizzo di documenti di tipo JSON con schemi opzionali.
MongoDB è considerato uno dei servizi di database cloud più avanzati del mercato, con una mobilità e una distribuzione dei dati senza precedenti su Azure, AWS e Google Cloud e un’automazione integrata per l’ottimizzazione dei carichi di lavoro e delle risorse.
Inoltre, vi permette di creare un database cloud in pochi minuti usando la CLI Atlas, l’interfaccia utente o un provider di risorse IaaS (infrastructure-as-a-service).
Con MongoDB Atlas, potete mantenere la vostra applicazione in funzione per tenere il passo con il traffico in aumento mentre le nuove funzionalità si fanno strada nella vostra pipeline. MongoDB Atlas offre ai suoi utenti strumenti avanzati per l’ottimizzazione del database, in modo che possiate sempre disporre delle risorse di database necessarie per il vostro lavoro.
Caratteristiche Principali
Ecco alcune delle caratteristiche principali di MongoDB che gli valgono un posto tra i migliori database non relazionali del mercato:
- Consigli sulle prestazioni: Man mano che le vostre applicazioni si evolvono, MongoDB vi assiste con le migliori pratiche di progettazione dello schema on-demand per ottenere la massima efficienza.
- Cluster multi-cloud: Con MongoDB potete creare applicazioni resilienti e potenti che sfruttano due o più cloud contemporaneamente.
- Load balancing: MongoDB facilita il controllo della concorrenza per gestire le richieste di più clienti in parallelo ad altri server. In questo modo è possibile diminuire il carico su ogni server, garantendo la coerenza e l’operatività dei dati e consentendo la creazione di applicazioni scalabili.
Casi d’Uso
Sono migliaia le organizzazioni in tutto il mondo che usano MongoDB per l’archiviazione dei dati o come servizio di database per le loro applicazioni.
MongoDB svolge un ruolo fondamentale per:
- Gestione dei contenuti: Con MongoDB potete servire e archiviare qualsiasi tipo di contenuto, costruire qualsiasi funzione e inserire qualsiasi tipo di dati in un unico database. Con MongoDB potete ottenere i risultati che volete grazie a hardware di base, a team più produttivi e a progetti che costano il 10% di quanto dovrebbero, offrendo al contempo tutte le funzionalità necessarie per creare applicazioni ricche di contenuti.
- Pagamenti: Se state sviluppando un nuovo prodotto per i pagamenti, l’agilità dei dati di MongoDB vi permetterà di raggiungere rapidamente il mercato, senza dovervi preoccupare di inutili complessità come la frammentazione dei dati. Anche se siete a capo di un’azienda matura che sta cercando di modernizzare il proprio ecosistema di pagamenti, potete sfruttare la flessibilità di MongoDB per usarlo come livello di dati operativi consolidati, consentendovi di creare nuovi prodotti e servizi grazie ai dati esistenti senza una rischiosa soluzione “cookie-cutter”.
- Personalizzazione: MongoDB vi permette di personalizzare l’esperienza di milioni di clienti in tempo reale, grazie a offerte mirate, home page personalizzate e accesso ai social network. Potete anche eseguire query complesse direttamente sui vostri dati senza preoccuparvi di trasformarli, estrarli e caricarli.
- Mainframe Offloading: Con MongoDB potete spostare facilmente i carichi di lavoro dal mainframe. Il Mainframe Offloading è il processo di replica dei dati del mainframe a cui si accede comunemente in un livello di dati operativi (ODL) costruito su MongoDB, rispetto al quale le operazioni possono essere reindirizzate dalle applicazioni di consumo.
Cos’È PostgreSQL?
Nonostante la popolarità dei database NoSQL, i database relazionali continuano a essere importanti per diverse applicazioni grazie alla loro robustezza e alle loro capacità di interrogazione.
I database relazionali sono ottimi per l’esecuzione di query complesse e di report basati sui dati nei casi in cui la struttura dei dati non cambia frequentemente. I database open-source come PostgreSQL offrono un’alternativa economica come database stabile di livello produttivo rispetto ai suoi contemporanei con licenza come SQL Server e Oracle.
PostgreSQL è un sistema di gestione di database stabile, supportato da oltre 20 anni di sviluppo della comunità che ha portato ad alti livelli di integrità, resilienza e correttezza. Potete usare PostgreSQL come data warehouse principale o come fonte di dati per diverse applicazioni mobili, geospaziali, analitiche e web.
Inoltre, PostgreSQL non ha costi di licenza, e questo elimina il rischio di una distribuzione eccessiva. Il suo gruppo di appassionati e collaboratori trova regolarmente bug e soluzioni, contribuendo alla sicurezza generale del sistema di database.
Caratteristiche Principali
Ecco alcune caratteristiche salienti di PostgreSQL che lo rendono uno dei database più usati:
- Colonne non atomiche: Uno dei vincoli principali di un modello relazionale è che le colonne devono essere atomiche. PostgreSQL, invece, non ha questo vincolo e permette alle colonne di avere dei sottovalori a cui le query possono accedere facilmente.
- Supporto per i dati JSON: La possibilità di interrogare e memorizzare JSON permette a PostgreSQL di gestire anche carichi di lavoro NoSQL: per esempio, immaginate di star progettando un database per memorizzare i dati di più sensori e di non sapere con certezza di che colonne specifiche avete bisogno per supportare tutti i tipi di sensori. In questo caso, potete costruire una tabella in cui una delle colonne sia JSON per memorizzare i dati in continua evoluzione o non strutturati.
- Funzioni finestra: Le funzioni finestra di PostgreSQL svolgono un ruolo fondamentale che lo rende uno dei preferiti per le applicazioni di analisi. Con le funzioni finestra potete eseguire funzioni che coprono più righe e restituire lo stesso numero di righe. Le funzioni finestra differiscono dalle funzioni aggregate nel senso che le funzioni aggregate possono restituire solo una singola riga dopo l’aggregazione.
Casi d’Uso
Ecco alcuni casi d’uso in cui PostgreSQL si rivela utile:
- Federated hub database: Il supporto JSON di PostgreSQL e i wrapper per i dati estranei gli permettono di connettersi con altri archivi di dati, compresi i tipi NoSQL, e di fungere da federated hub per sistemi di database poliglotti.
- Dati scientifici: I progetti scientifici e di ricerca possono generare terabyte di dati che devono essere gestiti in modo efficiente e vantaggioso. PostgreSQL offre un ottimo motore SQL con solide capacità analitiche, che rendono l’elaborazione di grandi quantità di dati un gioco da ragazzi.
- Produzione: Diversi produttori industriali di livello mondiale sfruttano PostgreSQL per accelerare l’innovazione e favorire la crescita attraverso processi incentrati sul cliente, ottimizzando al contempo le prestazioni della supply chain grazie all’utilizzo di PostgreSQL come backend di archiviazione.
- Stack open-source LAPP: PostgreSQL può eseguire applicazioni e siti web dinamici come parte di una solida alternativa allo stack LAMP. LAPP sta per Linux, Apache, PostgreSQL, Python, PHP e Perl.
MongoDB vs PostgreSQL: Confronto Testa a Testa
La vera questione non è MongoDB vs PostgreSQL, ma piuttosto il miglior database documentale vs il miglior database relazionale.
Molto spesso, all’inizio di un progetto di sviluppo, i responsabili del progetto hanno una buona conoscenza del caso d’uso ma non hanno ben chiare le caratteristiche specifiche dell’applicazione di cui gli utenti e l’azienda hanno bisogno. Alla fine devono puntare su una scelta e sperare che sia la più adatta.
Nella prossima sezione, chiariremo le differenze tra MongoDB e PostgreSQL per aiutarvi a prendere facilmente questa decisione. Le nostre informazioni si basano su fattori chiave come l’architettura, la conformità ACID, l’estensibilità, la replica, la sicurezza e il supporto, per citarne alcuni.
Cominciamo!
Conformità ACID
Una delle caratteristiche principali dei database relazionali che rendono più semplice la scrittura delle applicazioni è la conformità ACID delle transazioni. Per quanto riguarda i livelli di isolamento all’interno delle transazioni di database, PostgreSQL usa per impostazione predefinita il livello di isolamento read committed. Inoltre, consente agli utenti di regolare il livello di isolamento in lettura fino al livello di isolamento serializzabile.
La cosa importante da notare è che le transazioni consentono di apportare o annullare varie modifiche a un database in un gruppo. Pertanto, in un database relazionale, i dati sarebbero modellati su tabelle indipendenti genitore-figlio in uno schema tabellare.
In confronto, i database documentali hanno una maggiore facilità di esecuzione delle transazioni perché raccolgono i dati in un documento e, poiché la lettura e la scrittura sono operazioni atomiche, non necessitano di una transazione multi-documento.
MongoDB supporta il completo isolamento durante l’aggiornamento di un documento. Eventuali errori fanno sì che l’operazione di aggiornamento venga annullata, invertendo la modifica e garantendo ai clienti una visione coerente del documento.
MongoDB supporta anche le transazioni di database su più documenti, consentendo di eseguire il rollback o il commit di gruppi di modifiche correlate. Grazie alla capacità di effettuare transazioni su più documenti, MongoDB è uno dei pochi database a combinare la flessibilità, la velocità e la potenza del modello documentale con le garanzie ACID dei database tradizionali.
Architettura/Modello Documentale
Il modello documentale di MongoDB consente all’utente di mappare in modo naturale gli oggetti all’interno del codice dell’applicazione, rendendo più facile l’apprendimento e l’utilizzo da parte di chi fa sviluppo full-stack. I documenti offrono la possibilità di rappresentare relazioni gerarchiche per memorizzare facilmente array e altre strutture più sofisticate.
Memorizzando i dati in campi come sottodocumenti e array annidati, le informazioni correlate nei documenti JSON possono essere memorizzate insieme per un rapido accesso alle query attraverso il linguaggio di interrogazione MongoDB.
Con MongoDB, potete archiviare i dati come documenti in una rappresentazione binaria nota come JSON binario (BSON). I campi possono differire in base al documento a cui si riferiscono, pertanto non è necessario dichiarare la struttura dei documenti al sistema: i documenti sono autodescrittivi.
Se avete bisogno di aggiungere un nuovo campo a un documento, il campo può essere generato senza impattare sugli altri documenti della collezione o aggiornare un ORM o un catalogo centrale del sistema.
MongoDB vi offre anche la possibilità di convalidare lo schema per imporre controlli sulla governance dei dati in ogni raccolta. Questa flessibilità si rivela utile quando si raccolgono informazioni da più fonti disparate o si adattano le modifiche ai documenti nel corso del tempo, soprattutto quando le nuove funzionalità dell’applicazione vengono distribuite in modo costante.
PostgreSQL ha un modello di architettura client-server che consiste nei seguenti due processi:
- Processo lato client: Sono le applicazioni usate dagli utenti per interagire con il database. Di solito hanno un’interfaccia utente semplice e vengono utilizzate per comunicare tra l’utente e il database attraverso le API.
- Processo lato server: Si tratta dell’applicazione “Postgres” che gestisce le operazioni, le connessioni, le risorse dinamiche e statiche. Un sito PostgreSQL in esecuzione è gestito da un Postmaster, un processo di coordinamento centrale. Il demon Postmaster è responsabile di:
- Esecuzione del recupero
- Inizializzazione del server
- Spegnimento del server
- Esecuzione di processi in background
- Gestione delle richieste di connessione da parte di nuovi clienti
.
Estensibilità
Con estensibilità si intende il fatto che la progettazione consente l’aggiunta di nuove capacità o funzionalità.
PostgreSQL supporta l’estensibilità in diversi modi, tra cui le funzioni e le procedure memorizzate. Ciò che rende PostgreSQL estensibile sono le sue operazioni guidate dal catalogo.
I database relazionali spesso conservano le informazioni su tabelle, database, colonne, ecc. nei cataloghi di sistema. Questi “dizionari di dati” appaiono all’utente come tabelle, ma contengono informazioni memorizzate internamente dal sistema di database.
PostgreSQL memorizza le informazioni sulle colonne e sulle tabelle, insieme alle informazioni sui tipi di dati, sulle funzioni e sui metodi di accesso presenti.
C’è di più: PostgreSQL può anche incorporare il codice scritto dall’utente tramite il caricamento dinamico. Spesso gli utenti possono richiedere alcune funzionalità che possono essere implementate tramite librerie condivise. Gli utenti possono semplicemente specificare il file di codice e PostgreSQL lo caricherà come richiesto, rendendolo così unico per la prototipazione rapida di nuove applicazioni.
D’altro canto, MongoDB è diventato estensibile, consentendo agli utenti di creare le proprie funzioni e di usarle all’interno del framework. È equivalente alle funzioni definite dall’utente (UDF) che permettono agli utenti dei database relazionali (come PostgreSQL) di estendere le istruzioni SQL.
Inoltre, sia PostgreSQL che MongoDB supportano diverse estensioni e plugin come Adminer per la gestione dei database.
Collaborazione e Agilità
MongoDB ha un modello documentale che rende la collaborazione e lo sviluppo più facili e veloci da implementare. MongoDB usa essenzialmente JSON o BSON per memorizzare i dati come documenti.
BSON include diversi tipi di dati non presenti nei dati JSON, come DateTime, long, int e byte, che aiutano a gestire i dati in modo più efficiente, in quanto sono più specifici in base al tipo di dati, invece di gestire tutto come un tipo universale di “numero”. L’esecuzione delle query è più veloce grazie al formato di serializzazione che archivia efficacemente i documenti simili a JSON.
BSON salta le chiavi che non sono utili per la query, rendendo così più veloce il recupero dei dati. L’utente può definire ulteriormente la struttura del documento e intraprenderne lo sviluppo introducendo nuovi campi, rielaborando i dati o sviluppandolo in qualsiasi momento.
Questa flessibilità è un enorme vantaggio per MongoDB, in quanto consente di evitare i ritardi causati dalla richiesta all’amministratore di ristrutturare le dichiarazioni del linguaggio di definizione dei dati e di ripartire da zero ricreando o ricaricando un database.
MongoDB facilita anche la collaborazione tra sviluppatori o team, quindi non c’è bisogno di intermediazioni o di comunicazioni complicate tra i team.
Per quanto riguarda la collaborazione, PostgreSQL prevede privilegi a livello di utente, ereditarietà dei ruoli e privilegi a livello di tabella. Potete gestire gli utenti e concedere loro privilegi di lettura e scrittura.
Inoltre, potete controllare le attività di accesso ai dati di vari gruppi o utenti grazie all’opzione di auditing che garantisce un ulteriore livello di sicurezza. Tuttavia, PostgreSQL non è veloce come MongoDB, poiché è un database relazionale che memorizza i dati in righe e colonne.
Supporto alle Chiavi Esterne
Una caratteristica fondamentale che distingue MongoDB da PostgreSQL è il suo approccio alla memorizzazione dei dati.
Essendo un database non relazionale, MongoDB usa collezioni invece di tabelle. Una chiave esterna è semplicemente un insieme di attributi di una tabella che fa riferimento alla chiave primaria di un’altra tabella. La chiave esterna collega le due tabelle tra loro.
Poiché in MongoDB non ci sono tabelle, non ci sono nemmeno chiavi esterne e quindi non ci sono vincoli di chiave esterna. Tuttavia, MongoDB dispone di uno standard DBRef che aiuta a standardizzare la creazione dei riferimenti.
D’altra parte, PostgreSQL supporta le chiavi esterne in quanto è conforme a SQL. Abilitando i vincoli delle chiavi esterne, PostgreSQL può impedire l’inserimento di dati non validi nelle colonne delle chiavi esterne.
Partizionamento e Sharding
Il partizionamento e lo sharding consistono essenzialmente nel suddividere grandi insiemi di dati in sottoinsiemi più piccoli. Lo sharding implica che i dati siano archiviati su più computer, mentre il partizionamento raggruppa questi dati all’interno di un’unica istanza di database.
MongoDB è scalabile grazie al partizionamento dei dati tra le istanze del cluster. Non suddivide i documenti in parti, ma li rende unità indipendenti, facilitando la distribuzione dei dati su diversi server e preservando i dati a livello locale.
I dati possono essere distribuiti in diverse regioni con facilità grazie al servizio cloud MongoDB Atlas. Potete anche scegliere di archiviarli costantemente in regioni specifiche o globali per garantire una latenza ridotta.
Dalla versione 5.0, MongoDB ha incluso una funzione di resharding “live” che consente un notevole risparmio di tempo in quanto è sufficiente impostare una policy. Il database può ridistribuire automaticamente i dati quando è il momento.
In precedenza era possibile farlo senza disattivare il sistema, ma il processo era complicato e rischioso. Sebbene MongoDB abbia avuto per qualche tempo un geo-partizionamento globale, i dati crescevano in Paesi diversi a ritmi diversi. Il resharding live potrebbe essere utile per i dati che devono rimanere locali all’interno di un Paese.
D’altra parte, PostgreSQL supporta il partizionamento dichiarativo, che è essenzialmente un modo per specificare come dividere una tabella in partizioni. La tabella che viene divisa è chiamata tabella partizionata, la specifica consiste nel metodo di partizionamento e l’elenco di colonne o espressioni da usare è chiamato chiave di partizione.
Potete implementare il partizionamento tramite un intervallo, dove la tabella può essere suddivisa per intervalli definiti da una colonna chiave o da un insieme di colonne, senza sovrapposizioni tra gli intervalli di valori assegnati alle diverse partizioni.
Potete anche implementare un partizionamento a elenco in cui la tabella viene suddivisa in base ai valori delle chiavi specificate.
Replica
La replica è il processo di creazione di una copia dello stesso set di dati su più server. Consente a chi amministra database di fornire una elevata ridondanza dei dati e un’alta disponibilità degli stessi.
Per MongoDB, ciò si ottiene utilizzando un “set di replica”, ovvero un cluster sincronizzato composto da tre o più server che replicano i dati tra loro. In questo modo si ottiene una ridondanza e una protezione contro i tempi di inattività che potrebbero verificarsi in caso di interruzione programmata della manutenzione o di un guasto del sistema, aumentando così la tolleranza agli errori del database.
I set di repliche possono essere implementati anche in diversi data center, in quanto sarebbero utili in caso di interruzioni regionali. Questo può essere fatto con MongoDB Atlas, che rende la costruzione e la configurazione di questi cluster più semplice e veloce.
PostgreSQL offre la replica primaria-secondaria. I registri Write-ahead consentono di condividere le modifiche apportate con i nodi di replica, rendendo così possibile la replica asincrona. Altri tipi di replica sono la replica logica, la replica in streaming e la replica fisica.
Gli Indici
Gli indici sono oggetti o strutture che permettono di recuperare più velocemente righe o dati specifici.
PostgreSQL offre una serie di tipi di indici unici per rispondere in modo efficiente a qualsiasi carico di lavoro delle query. Le sue tecniche di indicizzazione includono B-tree, multicolonna ed espressioni. Inoltre, in PostgreSQL è possibile implementare tecniche di indicizzazione parziali e avanzate come GiST, KNN Gist, SP-Gist, GIN, BRIN, indici di copertura e filtri bloom.
D’altra parte, MongoDB permette di archiviare i dati in qualsiasi struttura a cui sia possibile accedere rapidamente tramite indicizzazione, indipendentemente dalla profondità degli array o dei sottodocumenti.
Linguaggio e Sintassi
Sia MongoDB che PostgreSQL supportano diversi linguaggi.
MongoDB fornisce il supporto di driver per alcuni dei migliori linguaggi per database come Python, R, Java, Scala, C, C++, C#, Node.js e molti altri. Queste librerie e driver MongoDB supportano tutte le funzionalità di MongoDB, garantendo elevate prestazioni e scalabilità in tutte le applicazioni.
PostgreSQL supporta diversi linguaggi procedurali con una distribuzione di base come PL/pgSQL, PL/Python, PL/Perl e PL/Tcl oltre ad altri linguaggi sviluppati e mantenuti al di fuori della distribuzione principale di PostgreSQL come PL/Java, PL/PHP e PL/Ruby.
Normalizzazione
La normalizzazione è il processo di strutturazione di un database relazionale per ridurre la ridondanza dei dati, minimizzare le anomalie nella modifica dei dati e migliorare l’integrità dei dati.
MongoDB può gestire sia modelli di dati normalizzati che denormalizzati (noti anche come modelli incorporati).
I modelli incorporati consentono alle applicazioni di memorizzare informazioni correlate nello stesso record di database, il che garantisce migliori prestazioni per le operazioni di lettura e la possibilità di recuperare dati correlati con un’unica operazione di database.
Inoltre, è possibile aggiornare i dati correlati con un’unica operazione di scrittura atomica, mentre le applicazioni eseguono meno query per completare le operazioni più comuni. I documenti in MongoDB per il modello di dati incorporato devono essere più piccoli della dimensione massima del documento BSON (16 MB).
I modelli di dati normalizzati descrivono le relazioni tramite riferimenti tra i documenti. Questa soluzione è utile quando l’incorporazione può comportare la duplicazione dei dati, ma i vantaggi in termini di prestazioni di lettura superano le implicazioni delle duplicazioni.
Tuttavia, il processo di denormalizzazione di solito causa un elevato consumo di memoria quando i dati precedentemente normalizzati in un database vengono raggruppati per aumentare le prestazioni.
Gli schemi di PostgreSQL hanno una relazione identificata. La struttura può essere identificata con una relazione 1:1, 1 a molti o molti a 1. La normalizzazione dei dati può essere molto vantaggiosa perché elimina le copie ridondanti dei dati, garantendo così l’integrità.
Prestazioni
Valutare le prestazioni di due diversi sistemi di database è una sfida, poiché sia MongoDB che PostgreSQL hanno modi diversi di memorizzare e recuperare i dati.
MongoDB è stato costruito per scalare orizzontalmente, in quanto spesso combina la sua potenza con altre macchine e non si basa sulla potenza di elaborazione. È in grado di alimentare applicazioni massive indipendentemente dalle dimensioni dei dati o dagli utenti.
MongoDB può anche adattarsi a casi d’uso che richiedono l’esecuzione rapida di query e può gestire una grande quantità di dati. Può incorporare centinaia di macchine in tutto.
A partire da MongoDB 4.4, le query implementate contro gli insiemi di repliche producono prestazioni migliori e prevedibili grazie alle letture “coperte”. Queste letture vengono indirizzate a più nodi all’interno dell’insieme di repliche fino a quando il nodo più veloce risponde.
PostgreSQL, pur non essendo veloce come MongoDB in termini di velocità di inserimento, eccelle in termini di conformità ACID. Le transazioni vengono elaborate in modo sicuro e affidabile, permettendo a un’intera transazione di fallire invece di eseguire una scrittura parzialmente riuscita.
Solo di recente (con la versione 4) MongoDB ha iniziato a supportare transazioni ACID simili a quelle dei database SQL.
A differenza di MongoDB, PostgreSQL dipende da una strategia di scale-up (vertical scaling) per i volumi di dati e la scalabilità delle scritture. Viene eseguita aggiungendo altre risorse hardware come dischi, CPU e memoria a un nodo di database esistente.
Tuttavia, PostgreSQL ha compiuto alcuni sforzi per ottimizzare le prestazioni, tra cui un query planner maturo, la compilazione just-in-time (JIT) delle espressioni, il partizionamento delle tabelle e la parallelizzazione delle query di lettura.
Prezzo
PostgreSQL è completamente gratuito e open-source. Pertanto, chiunque può usare le sue funzionalità e apportare modifiche al codice con facilità quando necessario.
Anche MongoDB è uno strumento open-source. Tuttavia, MongoDB ha altre opzioni come Enterprise e Atlas (per il cloud), che hanno prezzi variabili. Per l’edizione enterprise di MongoDB è previsto un modello di prezzo on-premise.
Mongo RealmDB è disponibile gratuitamente per tutti gli utenti di Atlas per la valutazione e l’utilizzo leggero, consentendo agli sviluppatori di creare e rilasciare applicazioni mobile.
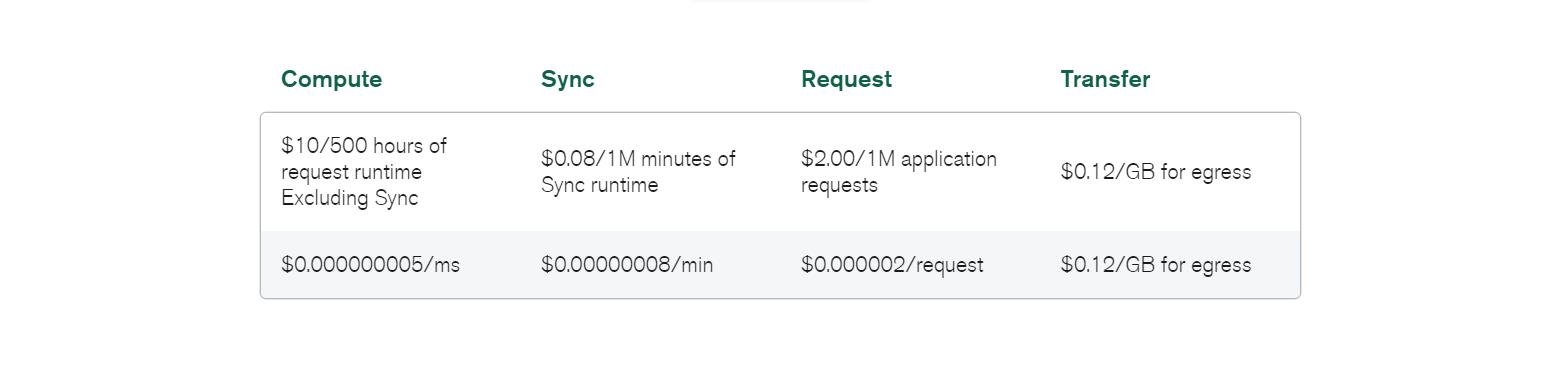
Anche la migrazione dei dati può generare costi aggiuntivi; tuttavia, si tratta di un’operazione standard a prescindere dal database implementato nel sistema.
Elaborazione delle Query
PostgreSQL usa il modello di database relazionale che prevede l’archiviazione dei dati all’interno di tabelle e l’utilizzo del linguaggio di interrogazione strutturato (SQL) per l’accesso al database. I comandi SQL possono essere inseriti con il terminale PostgreSQL psql. Dispone di una funzione di oggetti di grandi dimensioni, che fornisce un accesso di tipo stream ai dati dell’utente memorizzati in una speciale struttura di oggetti di grandi dimensioni.
Prima di aggiungere i dati, è necessario costruire lo schema del database per avere una chiara comprensione delle relazioni tra i dati per elaborare le query. Le informazioni correlate possono essere archiviate in tabelle separate del database. È possibile accedervi tramite chiavi esterne e join.
Può essere difficile modificare la struttura del database una volta caricato. È necessario che diversi team di sviluppo, operativi e di amministrazione del database coordinino attentamente le modifiche apportate alla struttura.
D’altra parte, la struttura dei dati di MongoDB non ha bisogno di essere pianificata in anticipo perché tratta essenzialmente dati non strutturati. Inoltre, la struttura dei dati è molto più facile da modificare.
Chi sviluppa può scegliere ciò che è essenziale per l’applicazione e apportare le modifiche necessarie. MongoDB usa MQL, che può essere utilizzato per lavorare con i documenti in MongoDB e prelevare i dati, offrendo la stessa flessibilità e potenza di SQL.
MongoDB elabora i dati come documenti JSON. È possibile effettuare query anche per i campi all’interno del documento JSON. Per questo motivo, MongoDB è molto utile nei casi in cui si desidera archiviare documenti all’interno di un campo dati flessibile.
Mentre PostgreSQL usa la funzione GROUP_BY per elaborare ed eseguire query aggregate, MongoDB usa tipicamente pipeline di aggregazione per elaborare le sue query.
Uno dei principali svantaggi di MongoDB, tuttavia, è che non è possibile unire facilmente le tabelle. In PostgreSQL, invece, è possibile farlo in modo semplice con un’istruzione JOIN.
MongoDB ha cercato di risolvere questo problema introducendo tipi di dati multidimensionali in cui è possibile incorporare un archivio di documenti all’interno di un altro. Tuttavia, è disorganizzato e non è elegante come la semplice funzione join che PostgreSQL incorpora.
Sicurezza
Per quanto riguarda la sicurezza, PostgreSQL ha la meglio su MongoDB. Le rigide regole che governano la struttura del database consentono a PostgreSQL di essere un database molto sicuro, quindi affidabile per i sistemi bancari.
PostgreSQL offre numerosi metodi di autenticazione, tra cui un modulo di autenticazione collegabile (PAM) e un protocollo di accesso alle directory leggero (LDAP), che riducono la superficie attaccabile dei server. Inoltre, garantisce una protezione a livello di server attraverso l’autenticazione basata sull’host e l’autenticazione tramite certificato.
Inoltre, PostgreSQL offre la crittografia dei dati e vi permette di usare i certificati SSL quando i vostri dati transitano sul web o sulle autostrade della rete pubblica. PostgreSQL vi permette anche di implementare gli strumenti di autenticazione dei certificati client (CCA) come opzione e di usare le funzioni crittografiche per memorizzare i dati criptati in PostgreSQL.
Tuttavia, il livello di sicurezza di PostgreSQL può variare da un sistema cloud all’altro, anche se si tratta dello stesso database.
MongoDB Atlas funziona allo stesso modo sui tre principali cloud provider, rendendo più semplice la migrazione tra più cloud.
Inoltre, MongoDB dispone di una crittografia lato client e a livello di campo, che consente agli utenti di crittografare i dati prima di inviarli al database tramite la rete. Tuttavia, poiché i dati sono memorizzati in coppie chiave-valore in un unico record, manca la sicurezza vantata da PostgreSQL; l’obiettivo principale di MongoDB rimane la velocità.
Supporto e Comunità
PostgreSQL è completamente open-source e supportato dalla sua comunità, che lo rafforza come ecosistema completo. PostgreSQL rilascia regolarmente versioni aggiornate e professionisti dello sviluppo, appassionati o aziende di terze parti forniscono supporto e cercano di sviluppare il sistema correggendo i bug o apportando lievi modifiche al sistema di database.
Come PostgreSQL, anche MongoDB dispone di un forum della comunità che consente agli utenti di connettersi con altri utenti e di ottenere risposte alle loro domande generali. Il supporto aziendale di MongoDB può includere anche un’ampia documentazione con casi d’uso, tutorial dettagliati, note tecniche sulle ottimizzazioni e best practice.
Inoltre, esistono corsi online con formazione e certificazioni fornite da MongoDB, gratuitamente.
I Punti Deboli
Finora abbiamo parlato delle caratteristiche di MongoDB e PostgreSQL che li rendono popolari tra chi si occupa di sviluppo, ma hanno anche alcuni punti deboli.
MongoDB tende a concentrarsi sulla rapidità delle operazioni sui dati, ma non sembra offrire la stessa sicurezza di PostgreSQL. È piuttosto impegnativo per la memoria, in quanto il processo di denormalizzazione comporta un elevato consumo di memoria.
Inoltre, non avendo il supporto per le join, i database di MongoDB sono sovraccarichi di dati, a volte duplicati, e quindi appesantiscono la memoria. MongoDB ha anche cercato di includere l’interpretazione di altri linguaggi di interrogazione come parte della sua estensibilità; tuttavia, ciò può rallentare le sue prestazioni poiché il database non è stato inizialmente costruito per gestire modelli di dati relazionali.
La traduzione di query SQL in query MongoDB può richiedere del tempo aggiuntivo e potrebbe rallentare la distribuzione e lo sviluppo.
D’altra parte, mentre PostgreSQL è facile da installare e si adatta a quasi tutte le piattaforme, la sua efficienza può variare da piattaforma a piattaforma. Inoltre, non dispone di strumenti di revisione o di reportistica in grado di mostrare le condizioni attuali del database. Potreste dover controllare continuamente il database se qualcosa non va come previsto per evitare di accorgervi di un guasto quando ormai è troppo tardi.
PostgreSQL è anche un po’ più lento perché si concentra sulla compatibilità. Anche se sono stati fatti degli sforzi per migliorare la velocità di PostgreSQL, le modifiche richiedono ancora un po’ di lavoro.
MongoDB vs PostgreSQL: Quale Scegliere?
MongoDB è un database non relazionale, mentre PostgreSQL è un database relazionale. Se i database NoSQL lavorano sull’archiviazione dei dati in coppie chiave-valore come un unico record, i database relazionali archiviano i dati in tabelle diverse.
Se la vostra priorità è l’integrazione più rapida dei dati e la scalabilità su più server, MongoDB potrebbe essere la scelta giusta per la vostra azienda.
MongoDB può funzionare al meglio se integrato in una piattaforma di analisi, in quanto la sua velocità offre prestazioni dinamiche che possono aiutare a tracciare il comportamento degli utenti in tempo reale. Inoltre, può essere molto utile per la vostra attività se gestite un’applicazione web molto trafficata che non dipende da uno schema strutturato come il New York Times (che in effetti usa MongoDB), oppure per i cataloghi di prodotti in cui è necessario memorizzare più oggetti con varie collezioni di attributi.
D’altra parte, PostgreSQL è perfetto per l’analisi e l’archiviazione dei dati. Se state costruendo uno strumento di automazione di database o un’applicazione bancaria in cui preferite che vengano applicate garanzie di sicurezza dei dati e delle transazioni, PostgreSQL potrebbe fare al caso vostro.
Riepilogo
Per riassumere, finora abbiamo trattato i dettagli di base di PostgreSQL e MongoDB. Abbiamo parlato della loro storia, delle loro caratteristiche principali e di ciò che li differenzia.
Sebbene sia PostgreSQL che MongoDB siano database straordinari, alla fine si tratta di scegliere quello più adatto alla vostra azienda.
Tra PostgreSQL e MongoDB, quale database preferite? Fatecelo sapere nei commenti!

Salman Ravoof é uno sviluppatore web autodidatta, uno scrittore, un creatore e un grande ammiratore del Free and Open Source Software (FOSS). Oltre alla tecnologia, è appassionato di scienza, filosofia, fotografia, arte, gatti e cibo. Per saperne di più su di lui, visitate il suo sito web o contattate Salman su X.

