
Secondo la maggior parte degli esperti di marketing, è necessario tenere il sito costantemente aggiornato per mantenere i contenuti sempre attuali e migliorare le classifiche SEO.
Tuttavia, alcuni siti hanno centinaia o addirittura migliaia di pagine, il che rende la cosa difficile per i team che inviano manualmente gli aggiornamenti ai motori di ricerca. Se i contenuti vengono aggiornati così spesso, come fare per fare in modo che questi miglioramenti abbiano un impatto sulle classifiche SEO?
È qui che entrano in gioco i bot crawler. Un bot web crawler scansiona la sitemap del sito alla ricerca di aggiornamenti e indicizza i contenuti nei motori di ricerca.
In questo post, forniremo un elenco completo di crawler con tutti i bot web crawler che è bene conoscere. Prima di immergerci nella lettura, diamo una definizione di bot crawler e spieghiamo come funzionano.
Guarda la nostra Video Guida sui Crawler Web più Comuni
Cos’è un Web Crawler?
Un web crawler è un programma informatico che scansiona automaticamente e legge sistematicamente le pagine web per indicizzarle per i motori di ricerca. I web crawler sono noti anche come spider o bot.
Affinché i motori di ricerca presentino pagine web aggiornate e pertinenti agli utenti che fanno una ricerca, è necessario che avvenga una scansione da parte di un bot web crawler. Questo processo può essere eseguito in automatico (a seconda delle impostazioni del crawler e del sito) oppure può essere avviato direttamente.
Molti fattori influiscono sul posizionamento SEO delle pagine web, tra cui la rilevanza, i backlink, l’hosting web e altro ancora. Tuttavia, nessuno di questi fattori ha degli effetti se le pagine non vengono scansionate e indicizzate dai motori di ricerca. Per questo motivo è fondamentale assicurarsi che il sito consenta di effettuare correttamente le scansioni e rimuovere qualsiasi ostacolo.
I bot devono continuamente scansionare e analizzare il web per garantire che vengano presentate le informazioni più accurate. Google è il sito web più visitato negli Stati Uniti e circa il 26,9% delle ricerche proviene da utenti americani:
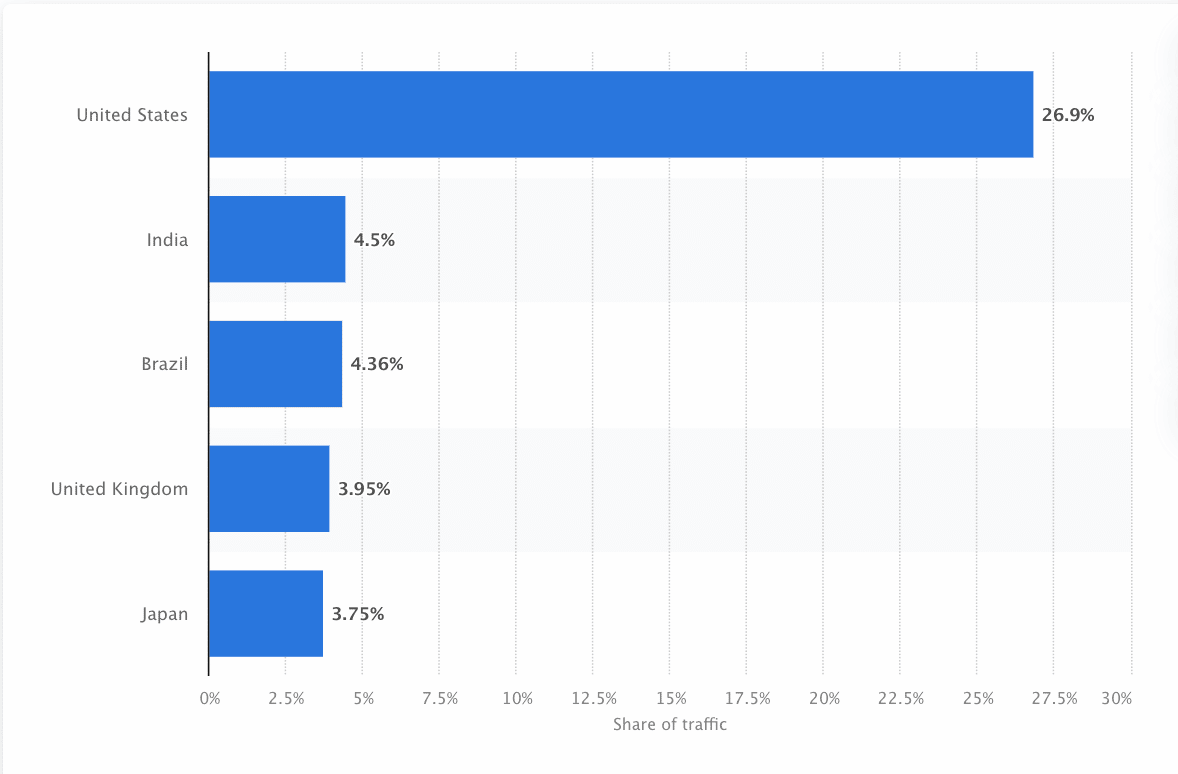
Tuttavia, non esiste un unico web crawler che effettua il crawling per tutti i motori di ricerca. Ogni motore di ricerca ha dei punti di forza specifici, quindi gli sviluppatori e gli addetti al marketing a volte compilano un “elenco di crawler”. Questo elenco di crawler li aiuta a individuare i diversi crawler da accettare o bloccare nei log del loro sito.
Gli operatori di marketing devono compilare una lista di crawler completa dei diversi web crawler e capire come valutano il loro sito (a differenza dei content scrapers che rubano i contenuti) per ottimizzare le landing page per i motori di ricerca.
Come Funziona un Web Crawler?
Un web crawler scansiona automaticamente la pagina web dopo che è stata pubblicata e indicizza i dati.
I web crawler cercano parole chiave specifiche associate alla pagina e indicizzano le informazioni per i motori di ricerca come Google, Bing e altri.
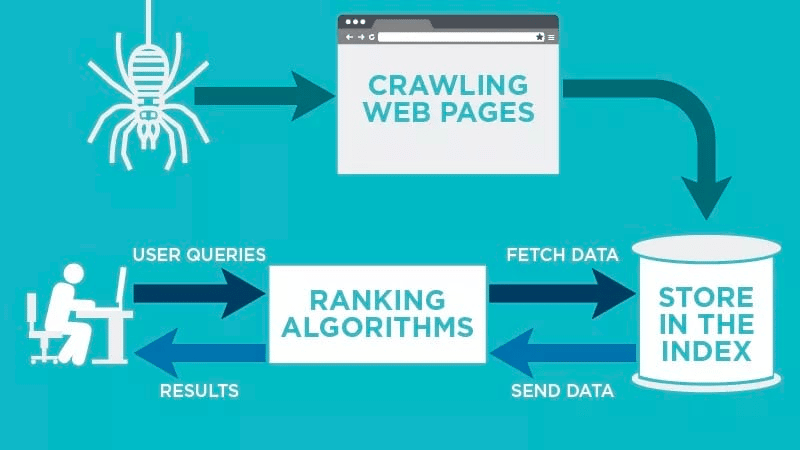
Quando un utente invia una richiesta per la parola chiave pertinente, gli algoritmi dei motori di ricerca recuperano questi dati.
Le ricerche iniziano con gli URL conosciuti. Si tratta di pagine web consolidate con vari segnali che indirizzano i web crawler verso quelle pagine. Questi segnali possono essere:
- Backlink: il numero di volte che un sito si collega
- Visitatori: la quantità di traffico si dirige verso quella pagina
- Autorità del dominio: la qualità complessiva del dominio
Poi memorizzano i dati nell’indice del motore di ricerca. Quando l’utente avvia una ricerca, l’algoritmo recupera i dati dall’indice e li fa apparire nella pagina dei risultati di ricerca. Questo processo può impiegare pochi millisecondi, motivo per cui i risultati appaiono spesso rapidamente.
Come webmaster, potete controllare quali bot effettuano il crawling del vostro sito. Ecco perché è importante avere un elenco di crawler. È il protocollo robots.txt che vive all’interno dei server di ogni sito e che indirizza i crawler verso i nuovi contenuti da indicizzare.
In base a quello che inserite nel protocollo robots.txt su ogni pagina web, potete dire a un crawler di scansionare o evitare di indicizzare quella pagina in futuro.
Sapendo cosa cerca un crawler nella sua scansione, potrete capire come posizionare al meglio i vostri contenuti per i motori di ricerca.
Compilazione dell’Elenco dei Crawler: Quali Sono i Diversi Tipi di Web Crawler?
Quando si inizia a pensare di compilare una lista di crawler, ci sono tre tipi principali di crawler da cercare:
- Crawler interni: si tratta di crawler progettati dal team di sviluppo di un’azienda per analizzare il sito. In genere vengono utilizzati per la verifica e l’ottimizzazione del sito.
- Crawler commerciali: si tratta di crawler personalizzati, come Screaming Frog, che le aziende possono utilizzare per effettuare il crawling e valutare in modo efficiente i propri contenuti.
- Crawler Open-Source: si tratta di crawler gratuiti creati da diversi sviluppatori e hacker di tutto il mondo.
È importante sapere quali sono i diversi tipi di crawler esistenti, in modo da sapere quale sfruttare per i propri obiettivi commerciali.
I 14 Web Crawler più Comuni da Aggiungere alla Lista di Crawler
Non esiste un unico crawler che svolge tutto il lavoro per ogni motore di ricerca.
Esiste invece una serie di web crawler che valutano le pagine web e scansionano i contenuti per tutti i motori di ricerca disponibili per gli utenti di tutto il mondo.
Vediamo alcuni dei web crawler più comuni.
1. Googlebot
Googlebot è il web crawler generico di Google, responsabile della scansione dei siti che verranno visualizzati sul motore di ricerca di Google.

Sebbene tecnicamente esistano due versioni di Googlebot – Googlebot Desktop e Googlebot Smartphone (Mobile) – la maggior parte degli esperti considera Googlebot un unico crawler.
Questo perché entrambi seguono lo stesso token di prodotto unico (noto come user agent token) scritto nel robots.txt di ogni sito. Lo user agent di Googlebot è semplicemente “Googlebot“.
Googlebot si mette al lavoro e in genere accede al sito ogni pochi secondi (a meno che non lo abbiate bloccato nel robots.txt del vostro sito). Un backup delle pagine scansionate viene salvato in un database unificato chiamato Google Cache. Questo permette di consultare le vecchie versioni del sito.
Inoltre, Google Search Console è un altro strumento che i webmaster utilizzano per capire come Googlebot sta effettuando il crawling del sito e per ottimizzare le pagine per i motori di ricerca.
| User Agent | Googlebot |
| Full User Agent String | Mozilla/5.0 (compatible; Googlebot/2.1; +http://www.google.com/bot.html) |
2. Bingbot
Bingbot è stato creato nel 2010 da Microsoft per scansionare e indicizzare gli URL al fine di garantire che Bing offra risultati pertinenti e aggiornati alle ricerche degli utenti della piattaforma.
Come per il Googlebot, gli sviluppatori o gli operatori di marketing possono stabilire nel robots.txt del loro sito se approvare o meno l’identificazione dell’agente “bingbot” per la scansione del sito.
Inoltre, è possibile distinguere tra crawler per l’indicizzazione mobile-first e crawler per desktop, dato che Bingbot è recentemente passato a un nuovo tipo di agente. Questo, insieme agli Strumenti per i Webmaster di Bing, offre ai webmaster la possibilità di capire come il loro sito viene scoperto e messo in evidenza nei risultati di ricerca.
| User Agent | Bingbot |
| Full User Agent String | Desktop – Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko; compatible; bingbot/2.0; +https://www.bing.com/bingbot.htm) Chrome/W.X.Y.Z Safari/537.36
Mobile – Mozilla/5.0 (Linux; Android 6.0.1; Nexus 5X Build/MMB29P) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/W.X.Y.Z Mobile Safari/537.36 (compatible; bingbot/2.0; +https://www.bing.com/bingbot.htm) “W.X.Y.Z” will be substituted with the latest Microsoft Edge version Bing is using, for eg. “100.0.4896.127″ |
3. Yandex Bot
Yandex Bot è un crawler specifico per il motore di ricerca russo Yandex. Si tratta di uno dei motori di ricerca più grandi e popolari della Russia.

I webmaster possono rendere accessibili le pagine del loro sito a Yandex Bot attraverso il file robots.txt.
Inoltre, possono aggiungere un tag Yandex.Metrica a pagine specifiche, reindicizzare le pagine in Yandex Webmaster o emettere un protocollo IndexNow, un report specifico che indica pagine nuove, modificate o disattivate.
| User Agent | YandexBot |
| Full User Agent String | Mozilla/5.0 (compatible; YandexBot/3.0; +http://yandex.com/bots) |
4. Apple Bot
Apple ha affidato all’Apple Bot il crawling e l’indicizzazione delle pagine web per i suggerimenti di Siri e Spotlight.
Apple Bot prende in considerazione diversi fattori per stabilire quali contenuti valorizzare nei Suggerimenti di Siri e Spotlight. Questi fattori includono il coinvolgimento degli utenti, la pertinenza dei termini di ricerca, il numero/la qualità dei link, i segnali basati sulla posizione e persino il design della pagina web.
| User Agent | Applebot |
| Full User Agent String | Mozilla/5.0 (Device; OS_version) AppleWebKit/WebKit_version (KHTML, like Gecko) Version/Safari_version Safari/WebKit_version (Applebot/Applebot_version) |
5. DuckDuck Bot
DuckDuckBot è il web crawler di DuckDuckGo, che offre “protezione della privacy continua sul tuo browser web”.
I webmaster possono utilizzare l’API di DuckDuckBot per verificare se il DuckDuck Bot ha effettuato il crawling del loro sito. Man mano che effettua il crawling, aggiorna il database di DuckDuckBot API con gli indirizzi IP e gli user agent più recenti.
Questo aiuta i webmaster ad individuare eventuali impostori o bot maligni che cercano di essere associati a DuckDuck Bot.
| User Agent | DuckDuckBot |
| Full User Agent String | DuckDuckBot/1.0; (+http://duckduckgo.com/duckduckbot.html) |
6. Baidu Spider
Baidu è il principale motore di ricerca cinese e Baidu Spider è l’unico crawler.

Google è vietato in Cina, quindi è importante abilitare Baidu Spider al crawling del sito se si vuole raggiungere il mercato cinese.
Per identificare il Baidu Spider che sta effettuando il crawling del vostro sito, cercate i seguenti user agent: baiduspider, baiduspider-image, baiduspider-video e altri simili.
Se non fate affari in Cina, potrebbe essere utile bloccare Baidu Spider nel vostro script robots.txt. In questo modo, lo spider di Baidu non potrà effettuare il crawling del sito, evitando così che le vostre pagine appaiano nelle SERP (Search Engine Results Page) di Baidu.
| User Agent | Baiduspider |
| Full User Agent String | Mozilla/5.0 (compatible; Baiduspider/2.0; +http://www.baidu.com/search/spider.html) |
7. Spider Sogou
Sogou è un motore di ricerca cinese che, a quanto pare, è il primo motore di ricerca con 10 miliardi di pagine cinesi indicizzate.

Se fate affari nel mercato cinese, questo è un altro popolare crawler di ricerca da conoscere. Sogou Spider segue il testo di esclusione del robot e i parametri del ritardo di crawling.
Come nel caso di Baidu Spider, se non volete fare affari nel mercato cinese, dovreste disabilitare questo spider per evitare di rallentare il caricamento del sito.
| User Agent | Sogou Pic Spider/3.0( http://www.sogou.com/docs/help/webmasters.htm#07) Sogou head spider/3.0( http://www.sogou.com/docs/help/webmasters.htm#07) Sogou web spider/4.0(+http://www.sogou.com/docs/help/webmasters.htm#07) Sogou Orion spider/3.0( http://www.sogou.com/docs/help/webmasters.htm#07) Sogou-Test-Spider/4.0 (compatible; MSIE 5.5; Windows 98) |
8. Facebook External Hit
Facebook External Hit, altrimenti noto come Facebook Crawler, esegue il crawling dell’HTML di un’applicazione o di un sito web condiviso su Facebook.

Questo permette alla piattaforma social di generare un’anteprima condivisibile di ogni link pubblicato. Il titolo, la descrizione e l’immagine di anteprima appaiono grazie al crawler.
Se il crawl non viene eseguito entro pochi secondi, Facebook non mostrerà il contenuto nello snippet personalizzato generato prima della condivisione.
| User Agent | facebot facebookexternalhit/1.0 (+http://www.facebook.com/externalhit_uatext.php) facebookexternalhit/1.1 (+http://www.facebook.com/externalhit_uatext.php) |
9. Exabot
Exalead è una società di software creata nel 2000 con sede a Parigi. L’azienda fornisce piattaforme di ricerca per clienti consumer e aziendali.
Exabot è il crawler del loro motore di ricerca principale basato sul prodotto CloudView.
Come la maggior parte dei motori di ricerca, Exalead tiene conto sia del backlinking che del contenuto delle pagine web. Exabot è lo user agent del robot di Exalead. Il robot crea un “indice principale” che raccoglie i risultati per gli utenti del motore di ricerca.
| User Agent | Mozilla/5.0 (compatible; Konqueror/3.5; Linux) KHTML/3.5.5 (like Gecko) (Exabot-Thumbnails) Mozilla/5.0 (compatible; Exabot/3.0; +http://www.exabot.com/go/robot) |
10. Swiftbot
Swiftype è un motore di ricerca personalizzato. Combina “le migliori tecnologie di ricerca, algoritmi, framework di ingestione dei contenuti, client e strumenti di analisi“.
Se avete un sito complesso con molte pagine, Swiftype offre un’utile interfaccia per catalogare e indicizzare tutte le vostre pagine.
Swiftbot è il web crawler di Swiftype. Tuttavia, a differenza di altri bot, Swiftbot effettua il crawling solo dei siti richiesti dai clienti.
| User Agent | Swiftbot |
| Full User Agent String | Mozilla/5.0 (compatible; Swiftbot/1.0; UID/54e1c2ebd3b687d3c8000018; +http://swiftype.com/swiftbot) |
11. Slurp Bot
Slurp Bot è il robot di ricerca che scansiona e indicizza le pagine per Yahoo.
Questo crawl è essenziale sia per Yahoo.com che per i suoi siti partner come Yahoo News, Yahoo Finance e Yahoo Sports. Senza di esso, gli elenchi dei siti rilevanti non apparirebbero.
I contenuti indicizzati contribuiscono a creare un’esperienza web personalizzata per gli utenti con risultati più pertinenti.
| User Agent | Slurp |
| Full User Agent String | Mozilla/5.0 (compatible; Yahoo! Slurp; http://help.yahoo.com/help/us/ysearch/slurp) |
12. CCBot

CCBot è un web crawler basato su Nutch sviluppato da Common Crawl, un’organizzazione non profit che si occupa di fornire (a costo zero) una copia di Internet alle aziende, ai privati e a chiunque sia interessato alla ricerca online. Il bot utilizza MapReduce, un framework di programmazione che gli permette di condensare grandi volumi di dati in risultati aggregati di valore.
Grazie a CCBot, è possibile utilizzare i dati di Common Crawl per migliorare i software di traduzione linguistica e prevedere le tendenze. In effetti, GPT-3 è stato addestrato in gran parte sui dati del loro set di dati.
| User Agent | CCBot/2.0 (https://commoncrawl.org/faq/) CCBot/2.0 CCBot/2.0 (http://commoncrawl.org/faq/) |
13. GoogleOther
Questo è nuovo di zecca. GoogleOther è stato lanciato da Google nell’aprile 2023 e funziona proprio come Googlebot.
Entrambi condividono la stessa infrastruttura e hanno le stesse caratteristiche e limitazioni. L’unica differenza è che GoogleOther sarà utilizzato internamente dai team di Google per effettuare il crawling di contenuti accessibili pubblicamente dai siti.
Il motivo alla base della creazione di questo nuovo crawler è quello di alleggerire la capacità di crawling di Googlebot e ottimizzare i processi di crawling del web.
GoogleOther verrà utilizzato, ad esempio, per le scansioni di ricerca e sviluppo (R&S), consentendo a Googlebot di concentrarsi sulle attività direttamente correlate all’indicizzazione delle ricerche.
| User Agent | GoogleOther |
14. Google-InspectionTool
Chi osserva l’attività di crawling e bot nei propri file di log si imbatterà in una novità.
Un mese dopo il lancio di GoogleOther, abbiamo tra noi un nuovo crawler che imita Googlebot: Google-InspectionTool.
Questo crawler è utilizzato dagli strumenti di test di ricerca di Search Console, come ad esempio lo strumento di Controllo URL, e altre proprietà di Google, come il Rich Result Test.
| User Agent | Google-InspectionTool Googlebot |
| Full User Agent String | Mozilla/5.0 (Linux; Android 6.0.1; Nexus 5X Build/MMB29P) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/W.X.Y.Z Mobile Safari/537.36 (compatible; Google-InspectionTool/1.0) Mozilla/5.0 (compatible; Google-InspectionTool/1.0) |
Gli 8 Crawler Commerciali che un Professionista della SEO Deve Conoscere
Ora che avete 14 dei bot più popolari nella vostra lista di crawler, vediamo alcuni dei più comuni crawler commerciali e strumenti SEO per professionisti.
1. Ahrefs Bot
Il Bot di Ahrefs è un web crawler che compila e indicizza il database di 12 trilioni di link offerto dal popolare software SEO Ahrefs.
Il bot di Ahrefs visita 6 miliardi di siti web ogni giorno ed è considerato “il secondo crawler più attivo” secondo solo a Googlebot.
Come gli altri bot, il bot di Ahrefs segue le funzioni del robots.txt e le regole di autorizzazione/rifiuto nel codice di ogni sito.
2. Semrush Bot
Il Bot di Semrush consente a Semrush, un software SEO leader, di raccogliere e indicizzare i dati dei siti per l’utilizzo da parte dei clienti della sua piattaforma.
I dati vengono utilizzati nel motore di ricerca dei backlink pubblici di Semrush, nello strumento di verifica dei siti, nello strumento di verifica dei backlink, nello strumento di link building e nell’assistente di scrittura.
Esegue il crawling dei siti generando un elenco di URL di pagine web, visitandole e salvando determinati collegamenti ipertestuali per visite successive.
3. Rogerbot, il Crawler della Campagna di Moz
Rogerbot è il crawler del principale sito SEO, Moz. Questo crawler raccoglie in modo specifico i contenuti per le verifiche dei siti della Campagna Moz Pro.

Rogerbot segue tutte le regole stabilite nei file robots.txt, quindi potete decidere se bloccare/consentire a Rogerbot la scansione del vostro sito.
I webmaster non saranno in grado di cercare un indirizzo IP statico per vedere quali pagine Rogerbot ha scansionato per il suo approccio multiforme.
4. Screaming Frog
Screaming Frog è un crawler utilizzato dai professionisti SEO per verificare il proprio sito e individuare le aree di miglioramento per il posizionamento nei motori di ricerca.

Una volta avviato il crawling, potrete esaminare i dati in tempo reale e individuare i link non funzionanti o i miglioramenti da apportare ai titoli delle pagine, ai metadati, ai robot, ai contenuti duplicati e altro ancora.
Per configurare i parametri di crawling, è necessario acquistare una licenza.
5. Lumar (ex Deep Crawl)
Lumar è un “centro di comando centralizzato per mantenere la salute tecnica del tuo sito”. Con questa piattaforma potete avviare un crawl per pianificare l’architettura del vostro sito.
Lumar si vanta di essere il “crawler di siti web più veloce sul mercato” e di poter effettuare il crawling di 450 URL al secondo.
6. Majestic
Majestic si occupa principalmente di tracciare e individuare i backlink degli URL.

L’azienda si vanta di avere “una delle fonti più complete di dati sui backlink su Internet”, sottolineando il suo indice storico che è passato da 5 a 15 anni di link nel 2021.
Il crawler del sito mette tutti questi dati a disposizione dei clienti dell’azienda.
7. cognitiveSEO
cognitiveSEO è un altro importante software SEO utilizzato da molti professionisti.
Il crawler di cognitiveSEO consente agli utenti di eseguire verifiche complete del sito che informeranno l’architettura e la strategia SEO generale.
Il bot effettua il crawling di tutte le pagine e fornisce “un set di dati completamente personalizzato” unico per l’utente finale. Questo set di dati contiene anche raccomandazioni per l’utente per migliorare il proprio sito per gli altri crawler, sia per influenzare le classifiche che per bloccare i crawler non necessari.
8. Oncrawl
Oncrawl è un “crawler SEO e analizzatore di log leader del settore” per clienti di livello aziendale.
Gli utenti possono impostare “profili di crawl” per creare parametri specifici per il crawl. È possibile salvare queste impostazioni (tra cui l’URL di partenza, i limiti di crawl, la velocità massima di crawl e altro ancora) per eseguire facilmente il crawl di nuovo con gli stessi parametri stabiliti.
Devo Proteggere il Mio Sito da Crawler Malevoli?
Non tutti i crawler sono buoni. Alcuni possono avere un impatto negativo sulla velocità delle pagine, mentre altri possono cercare di hackerare il sito o avere intenzioni malevole.
Ecco perché è importante capire come bloccare i crawler impedendo loro di accedere al sito.
Compilando un elenco di crawler, saprete quali sono i crawler da tenere d’occhio. In seguito, potrete eliminare quelli sospetti e aggiungerli alla vostra blocklist.
Come Bloccare i Crawler Malevoli
Con la vostra lista di crawler in mano, sarete in grado di individuare i bot che volete approvare e quelli che dovete bloccare.
Il primo passo consiste nell’esaminare l’elenco dei crawler e definire lo user agent e la stringa dell’agente completo associati a ciascun crawler, nonché il suo indirizzo IP specifico. Questi sono i fattori chiave di identificazione associati a ciascun bot.
Con lo user agent e l’indirizzo IP, potete farli coincidere nei record del vostro sito attraverso una ricerca DNS o una corrispondenza di IP. Se non corrispondono esattamente, potreste avere un bot maligno che tenta di spacciarsi per quello reale.
In questo caso, potete bloccare l’impostore modificando i permessi tramite i tag del robots.txt del sito.
Riepilogo
I web crawler sono utili per i motori di ricerca e importanti per i marketer.
Assicurarsi che il sito venga caricato correttamente dai crawler giusti è importante per il successo di una attività. Tenendo un elenco di crawler, potete sapere quali sono quelli da tenere d’occhio quando compaiono nei log del vostro sito.
Seguendo le raccomandazioni dei crawler commerciali e migliorando i contenuti e la velocità del tuo sito, permetterete ai crowler di accedere facilmente al vostro sito e indicizzerete le informazioni giuste per i motori di ricerca e per i consumatori che effettuano le ricerche.


