
Both MySQL and MariaDB seamlessly leverage the efficiency of balanced tree (B-Tree) indexing to optimize data operations. This shared indexing mechanism ensures swift data retrieval, enhances query performance, and minimizes disk input/output (I/O), contributing to a more responsive and efficient database experience.
This article takes a closer look at indexing, guides you on creating indexes, and shares tips on using them more effectively in MySQL and MariaDB databases.
What is an index?
When you query a MySQL database for specific information, the query searches through each row in a database table until it locates the correct one. This may take a long time, particularly in cases where the database is extensive.
Database managers use indexing to expedite data retrieval processes and optimize query efficiency. Indexing builds a data structure that minimizes the quantity of data that must be searched by organizing it systematically, leading to quicker and more effective query execution.
Say you want to find a customer whose first name is Ava in the following Customer table:
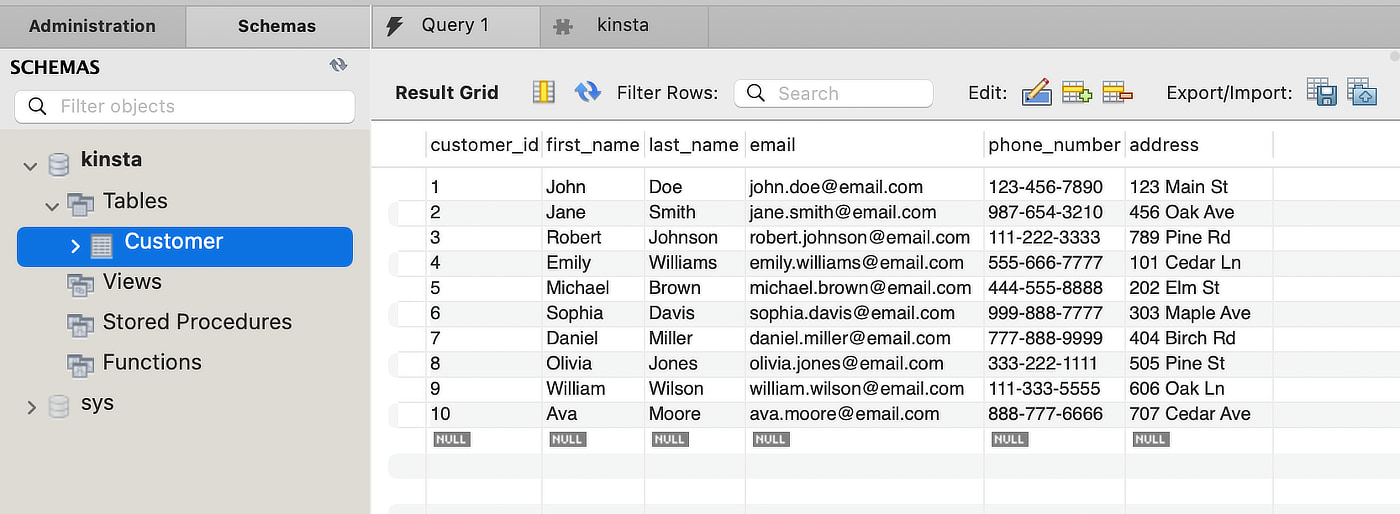
Adding a B-Tree index to the first_name column creates a structure that facilitates a more efficient search for the desired information. The structure resembles a tree with the root node at the top, branching down to leaf nodes at the bottom.
It’s similar to a well-organized tree, where each level guides the search based on the sorted order of the data.
This image shows a B-Tree index search path:
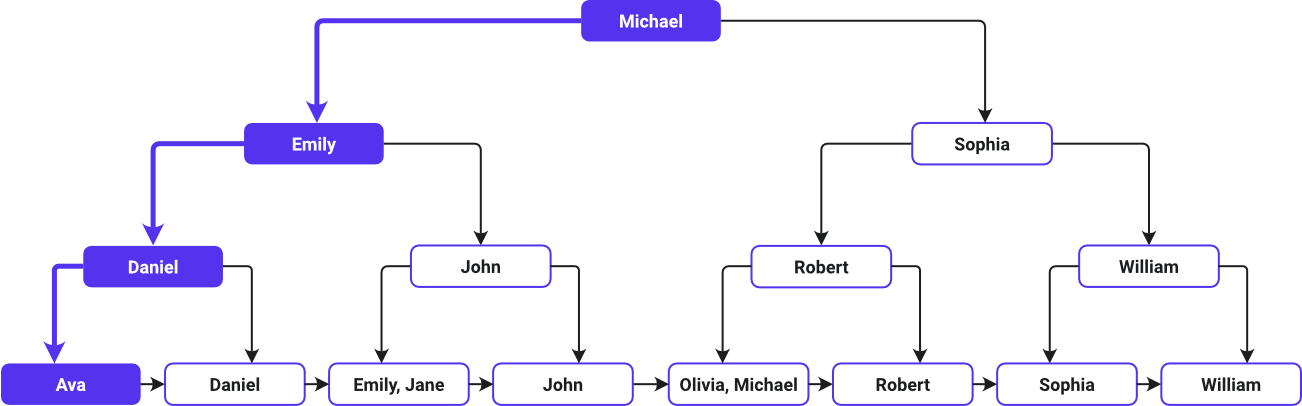
Ava is listed first, and William last in ascending alphabetical order — how the B-Tree arranged the names. The B-Tree system designates the middle value in the list as a root node. Since Michael is in the middle of the alphabetical list, it’s the root node. The tree then branches out, with values to Michael‘s left and right.
As you proceed down the tree’s tiers, each node offers more keys (direct links to the original rows of data) to guide the search through the alphabetically ordered names. Then, you find the data for every customer’s first name at the leaf nodes.
The search starts by comparing Ava to the root node Michael. It moves to the left after determining that Ava appears before Michael alphabetically. It travels down to the left child (Emily), then left again to Daniel, and left once more to Ava before arriving at the leaf node that contains Ava’s information.
The B-Tree functions as a simplified navigation system, effectively guiding the search to a particular place without checking every name in the dataset. It’s like navigating a carefully ordered directory by following strategically placed signposts that take you straight to the destination.
Types of indexes
There are different types of indexes for various purposes. Let’s discuss these different types below.
1. Single-level indexes
Single-level indexes, or flat indexes, map index keys to table data. Every key in the index corresponds to a single table row.
The customer_id column is a primary key in the Customer table, serving as a single-level index. The key identifies each customer and links their information in the table.
| Index (customer_id) | Row Pointer |
| 1 | Row 1 |
| 2 | Row 2 |
| 3 | Row 3 |
| 4 | Row 4 |
| … | … |
The relationship between customer_id keys and individual customer details is straightforward. Single-level indexes excel in scenarios with tables containing a few rows or columns with few distinct values. Columns like status or category, for example, are good candidates.
Use a single-level index for simple queries that locate a specific row based on a single column. Its implementation is simple, straightforward, and efficient for smaller datasets.
2. Multi-level indexes
Unlike single-level indexes for organized data retrieval, multi-level indexes use a hierarchical structure. They have multiple levels of guidance. The top-level index directs the search to a lower-level index, and so on until it reaches the leaf level, which stores the data. This structure decreases the number of comparisons required during searches.
Consider a multi-level index with address and customer_id columns.
| Index (address) | Sub-Index (customer_id) | Row Pointer |
| 123 Main St | 1 | Row 1 |
| 456 Oak Ave | 2 | Row 2 |
| 789 Pine Rd | 3 | Row 3 |
| … | … | … |
The first level organizes addresses. The second level, within each address, further organizes customer IDs.
This organization is excellent for more extensive datasets that require an organized search hierarchy. It’s also helpful for columns like last_name with a moderate cardinality (the uniqueness of data values in a particular column).
3. Clustered indexes
Clustered indexes in MySQL dictate the index’s logical order and the data’s order in the table. If you apply a clustered index to the customer_id column in the Customer table, the rows are sorted based on the column’s values. This means that the order of the data in the table reflects the order of the clustered index, enhancing data retrieval performance for specific patterns by reducing disk I/O.
This strategy is effective when the data retrieval pattern aligns with the order of customer IDs. It’s also suitable for columns with high cardinality, like customer_id.
While clustered indexes offer advantages regarding data retrieval performance for specific patterns, it’s important to note a potential drawback. Sorting rows based on the clustered index can impact the performance of insert and update operations, especially if the insert or update pattern doesn’t align with the order of the clustered index. This is because new data must be inserted or updated in a way that maintains the sorted order, resulting in additional overhead.
4. Non-clustered indexes
Non-clustered indexes give database structures more flexibility. Assume you use a non-clustered index on an email column. Unlike a clustered index, it doesn’t change the order of the entries in the table.
Instead, it builds a new structure that maps keys — in this case, email addresses — to data rows. When you query the database for a specific email address, the non-clustered index guides the search directly to the relevant row without relying on the table’s order.
The flexibility of non-clustered indexes is their primary advantage. They enable efficient searches of multiple columns without imposing an order on the stored data. This system makes non-clustered indexes versatile, as they can accommodate queries that don’t follow the primary order of the table.
Non-clustered indexes are helpful when the data retrieval pattern differs from alphabetical order and for columns with moderate to high cardinality, like email.
How to create indexes
Now that we’ve reviewed what indexes are from a high level let’s review some practical examples of creating indexes using MySQL Workbench.
Prerequisites
To follow along, you need:
- A MySQL database (compatible with MariaDB)
- Some SQL and MySQL experience
- MySQL Workbench
How to create the customer table
- Launch MySQL Workbench and connect to your MySQL server.
- Run the following SQL query to create a Customer table:
CREATE TABLE Customer ( customer_id INT PRIMARY KEY, first_name VARCHAR(50), last_name VARCHAR(50), email VARCHAR(100), phone_number VARCHAR(15), address VARCHAR(255) ); - Insert the following data:
-- Adding Data to the Customer Table INSERT INTO Customer (customer_id, first_name, last_name, email, phone_number, address) VALUES (1, 'John', 'Doe', '[email protected]', '123-456-7890', '123 Main St'), (2, 'Jane', 'Smith', '[email protected]', '987-654-3210', '456 Oak Ave'), (3, 'Robert', 'Johnson', '[email protected]', '111-222-3333', '789 Pine Rd'), (4, 'Emily', 'Williams', '[email protected]', '555-666-7777', '101 Cedar Ln'), (5, 'Michael', 'Brown', '[email protected]', '444-555-8888', '202 Elm St'), (6, 'Sophia', 'Davis', '[email protected]', '999-888-7777', '303 Maple Ave'), (7, 'Daniel', 'Miller', '[email protected]', '777-888-9999', '404 Birch Rd'), (8, 'Olivia', 'Jones', '[email protected]', '333-222-1111', '505 Pine St'), (9, 'William', 'Wilson', '[email protected]', '111-333-5555', '606 Oak Ln'), (10, 'Ava', 'Moore', '[email protected]', '888-777-6666', '707 Cedar Ave');
Single-level indexes
One tactic for optimizing query performance in MySQL and MariaDB is to use single-level indexes.
To add a single-level index to the Customer table, use the CREATE INDEX statement:
-- Creating a Single-Level Index on "customer_id"
CREATE INDEX idx_customer_id ON Customer(customer_id);Upon successful execution, the database confirms index creation by returning the following code:
0 row(s) affected Records: 0 Duplicates: 0 Warnings: 0Now, queries that filter data based on values from the customer_id column are handled optimally by the database, greatly increasing efficiency.
Multi-level indexes
MySQL and MariaDB go beyond individual column indexing by providing multi-level indexes. These indexes span more than one level or column, combining values from multiple columns into one index to make executing queries more efficient.
Use the following code to create a multi-level index in MySQL or MariaDB, focusing on address and customer_id columns:
-- Creating a Multi-Level Index based on "address" and "customer_id"
CREATE INDEX idx_address_customer_id ON Customer(address, customer_id);Using multi-level indexes strategically results in significant improvements in query performance, especially when dealing with sets of columns.
Clustered indexes
Besides individual and multi-level indexing, MySQL and MariaDB use clustered indexes, a dynamic tool for enhancing database performance by aligning the data rows with the order of the index’s pointers.
For instance, applying a clustered index to the customer_id column in the Customer table aligns the order of customer IDs.
-- Creating a Clustered Index on "customer_id"
CREATE CLUSTERED INDEX idx_customer_id_clustered ON Customer(customer_id);Because of the optimized order of data, this strategy significantly improves the data retrieval of specific patterns while decreasing disk I/O.
Non-clustered indexes
Non-clustered indexes can optimize queries depending on the columns without forcing the data into a certain order. In MySQL and MariaDB, you don’t need to specify that an index is non-clustered.
The table architecture implies it. Only the primary key or the first non-null unique key can be a clustered index. The table’s other indexes are all implicitly non-clustered. As an example of a non-clustered index, consider the following:
-- Creating a Non-clustered Index on "email"
CREATE INDEX idx_email_non_clustered ON Customer(email);Non-clustered indexes allow for efficient searches of multiple columns, resulting in a more versatile and responsive database.
Best practices and key points
Choose single-level indexes when working with columns with a small range of differing values, like status or category. Use multi-level and non-clustered indexes with columns with a broader range of values, like email.
Your preferred data retrieval patterns are key when choosing between clustered and non-clustered indexes. For clustered indexes, choose columns with high cardinality, like customer ID. For non-clustered indexes, choose columns with moderate to high cardinality, like email.
How to optimize indexes
To boost the performance of your indexes, you can use some practical strategies, such as covering indexes and removing redundant indexes.
1. Cover indexes
Covering indexes improves query performance by creating indexes that cover all necessary data. The term covering index means an index includes all the columns required to fulfill a query, avoiding the need to access the data rows.
-- Create a Covering Index on "first_name" and "last_name"
CREATE INDEX idx_covering_name ON Customer(first_name, last_name);2. Remove redundancies
Remove redundant indexes, but exercise caution, as removing indexes may impact certain query performances.
-- Remove an Unnecessary Index
DROP INDEX idx_unnecessary_index ON Customer;Regularly review and remove redundant indices to ensure a streamlined and efficient database structure.
3. Avoid over-indexing
Avoid common pitfalls like over-indexing. While indexes enhance query performance, creating too many can diminish returns. It’s crucial to strike a balance and avoid over-indexing, which may result in increased storage requirements and potential performance degradation.
4. Analyze query patterns
It’s also a common pitfall to overlook the analysis of query patterns before creating indexes. Understanding the queries frequently executed and focusing on indexing columns used in WHERE clauses or JOIN conditions is essential for optimal performance.
Summary
This article explored MySQL and MariaDB indexing, emphasizing the efficiency of the B-Tree mechanism. It covered indexing fundamentals and various index types (single-level, multi-level, clustered, and non-clustered).
Whether you’re optimizing for read-heavy workloads or enhancing write performance, Kinsta’s database hosting service empowers MySQL and MariaDB users with a reliable and high-performance solution for their indexing needs. Try Kinsta’s database hosting to take advantage of MySQL and MariaDB and their indexing capabilities.


