
Content scraping, or what we like to refer to as “content stealing,” has been a problem since the internet began. For anyone publishing on a regular basis or working with search engine optimization (SEO), it actually can be downright infuriating. 😠 The bigger you grow, the more you notice just how many content scraping farms are out there. We publish a lot of content here at Kinsta and content scraping is an issue we deal with on a regular basis. The question is, should you try to fight back or simply ignore them and move on? Today we’ll dive into some of the pros and cons of both sides.
What is Content Scraping?
Content scraping is basically when someone takes your content and uses it on their own site (either manually or automatically with a plugin or bot) without giving you attribution or credit. This is usually done in hopes of somehow gaining traffic, SEO, or new users. This is actually against copyright laws in the United States and some other countries. Google also doesn’t condone this and recommends that you should be creating your own unique content.
Here are a couple of examples of scraped content that Google mentions:
- Sites that copy and republish content from other sites without adding any original content or value
- Sites that copy content from other sites, modify it slightly (for example, by substituting synonyms or using automated techniques), and republish it
- Sites that reproduce content feeds from other sites without providing some type of unique organization or benefit to the user
- Sites dedicated to embedding content such as video, images, or other media from other sites without substantial added value to the user
This is not to be confused with content syndication, which is typically when you republish your own content for broader reach. Syndicate content could also be done by a third-party, but there is a fine line between this and content scraping. If someone is syndicating content, special tags such as rel=canonical or noindex should always be used.
There are a lot of third-party WordPress plugins now that allow you to automatically grab third-party RSS feeds. And while the developers have good intentions, unfortunately, these are sometimes abused and used for content scraping. One of the reasons WordPress is so popular is for ease of use, but sometimes that can also backfire.
Live Example of Content Scraping Farm
We call them “farms” when the same owner scrapes content across dozens of sites. These are typically easy to spot as the site owner usually uses the same theme across all sites and even just a slight variation between domain names.
We are using a live example in today’s post! We have no shame in calling out these types of sites as they don’t provide any value and only negate the hard work done by content publishers. Here is an example of a content scraping farm. We archived each link in case the sites go down in the future. You can click on each one of them and see they are all using the same theme, and same scraped content. Typically a scraper will grab content from a lot of different sources, our blog is one of them.
- thetechworld.xyz (archived link)
- mytechnewstoday.org (archived link)
- mytechcrunch.com (archived link)
- technewssites.xyz (archived link)
- technewssites.info (archived link)
- www.thetechworld.info (archived link)
- www.mytechnewstoday.xyz (archived link)
- www.futuretechnologynews.info (archived link)
- futuretechnologynews.xyz (archived link)
You can see below, they are simply scraping our blog posts word for word, along with all of our articles across all of the domains above.
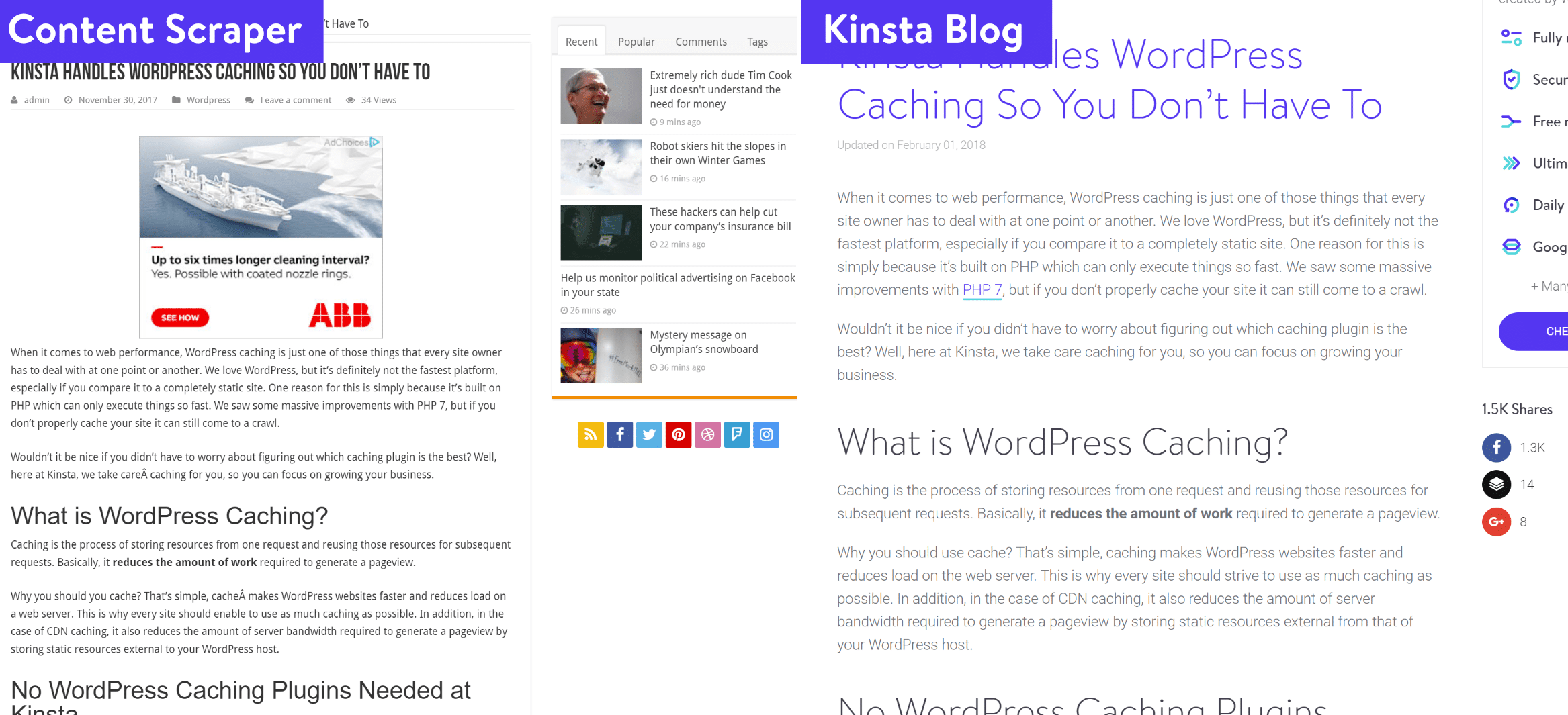
How to Find Them?
One of the easiest ways to find them is to utilize a tool like Copyscape or Ahrefs (if they are also copying your internal links). Copyscape even allows you to submit your sitemap file and have it automatically notify you as it scans the web and finds content.

You can also manually search Google using the “allintitle” tag. Simply input the tag along with your post’s title. Example: allintitle: Kinsta Handles WordPress Caching So You Don’t Have To

The allintitle keyword prompts Google to search for those words in the titles of posts only. The second and more effective way is to search for some text within your post, with the search term in double-quotes. Putting the double quotes tells Google to search for the exact same text. You may get false positives with your title search, as someone might use the same title, but the second way is far more effective because it’s highly unlikely that someone will have the exact same sentences or paragraphs.
Does Content Scraping Affect SEO?
The next question you probably have is, how does this affect SEO? Because in the example above, the content scraping farm isn’t using rel=canonical tags, giving credit, or noindex tags. This means that when Google bot crawls it, it’s going to think that it’s their original content. That’s not fair you might think. You’re right, it’s not. We published the content and then they just scrape it. However, before you start panicking, it’s important to understand what really goes on behind the scenes.
First off, even though the Google crawler might see it as their content, most likely the Google algorithm doesn’t. Google isn’t stupid and has many rules and checks in place to ensure original content owners still get the credit. How do we know this? Well, let’s take a look at each of these posts from an SEO perspective.
This person scraped our blog post back in November 2017, so it’s had plenty of time to rank if it was going to. So we pull up our handy Ahrefs tool and check to see what current keywords their post is ranking for. And we can see it’s not ranking for any keywords. So as far as organic traffic goes, they don’t benefit from this post at all.
If we pull up our original blog post in Ahrefs we can see we rank for 96 keywords.

When Google sees what you might think is duplicate content, it uses a lot of different signals and data points to figure out who originally wrote the content and what should be ranked. Here are a couple of examples:
- Publish dates (although in this case the content was scraped on the same day)
- Domain authority and page rank. Yes, Google is probably still using page rank internally
- Social signals
- Traffic
- Backlinks
Again these are all safe assumptions, being that no one really knows what Google uses. But the point here is that you probably don’t need to lose sleep over someone scraping your content. However, you still might want to do something about it. It’s also not impossible for someone else to outrank you with your own content. We’ll go into this further below.
What We Do About Content Scraping
Creating useful, unique and share-worthy content is not easy, it takes a lot of your valuable time (and often costs a lot of money) so you should definitely protect it. But here are some additional reasons why you might not want to ignore scrapers.
- If a site with a significant amount of traffic is scraping your content and using it to supplement their other content, it could very well be that they are benefiting from it. This definitely isn’t right as you’re the original owner of the content.
- Things like this can seriously skew data in your reporting tools and make your life harder. For example, these will show up in backlink reports in tools such as Ahrefs or Majestic. The bigger you are, the messier it gets.
- Do you want to put your trust solely in Google to figure out if theirs or yours is the original content? Even though they are pretty smart about this, we surely don’t. Also, even though their post has no search engine rankings for any keywords, it actually is indexed by Google (as seen below).

Contact Website Owner and File DMCA Complaint
To ensure we get credit where credit is due, we usually first contact the owner of the website and request removal. We recommend creating a few email templates you can reuse to speed this process up and not waste your time. If we don’t hear from them after a couple tries, we take this a step further and file a DMCA complaint.
DMCA complaints can be a little tricky as you’ll need to look up the IP of the site, find the host, etc. But not to worry, we have all the steps documented on how to easily file a DMCA complaint, as well as track down the owner. You can also file a legal removal request directly with Google.
As far as the live case study example above, it looks like it’s time to take that next step as we haven’t been able to reach the website owner. 😩
Update Disavow File
To ensure these don’t impact our site in any way (regardless of what happens with the DMCA complaint), we also add these entire domains in our disavow file. This tells Google we want nothing to do with them, and that we’re not trying to manipulate SERPs in any way.
If you’re doing this for a higher quality site, you can also just submit the URL for disavowal, instead of the entire domain. Although typically we don’t see high-quality sites scraping content.
Step 1
In Ahrefs we select the domain in question and click on “Disavow Domains.” This ensures everything from this content scraped website never impacts us.

The great thing about Ahrefs when dealing with these types of issues is their “Hide disavowed links” option. It then automatically hides the domains and URLs from showing up in your main report in the future. This is super helpful for organization and keeping your sanity, especially if you are exclusively using Ahrefs to manage your backlinks. 👍

Step 2
As you can see below we added all of the domains from the content scraping farm to our disavow links section in Ahrefs. The next step is to click on “Export” and get the disavow file (TXT) that we need to submit over in Google Search Console.

Step 3
Then head over to Google’s Disavow Tool. Select your Google Search Console profile and click on “Disavow Links.”

Step 4
Choose your disavow file you exported from Ahrefs and submit it. This will overwrite your previous disavow file. If you haven’t been using Ahrefs before in the past and a disavow file already exists, it’s recommended to download the current one, merge it with your new one, and then upload it. From then on, if you’re only using Ahrefs, you can simply upload and overwrite.

Block IPs of Scrapers
You could also take this a step further and block IPs of the scrapers. Once you have determined unusual traffic (which can sometimes be hard to do), you could block it on your server using .htaccess files or Nginx rules. If you’re a Kinsta client our support team can also block IPs for you. Or if you’re using a third-party WAF such as Sucuri or Cloudflare, these also have options to block IPs.
Summary
Content scraping farms might not always affect your SEO, but they definitely aren’t adding anything of value for users. We highly recommend taking a few moments to get them taken down. We have a whole Trello card devoted to “takedown” requests. This helps make the web a better place for everyone and ensures your unique content is only seen and ranked on your site.
What do you think about content scraping? Do you try and fight them or just ignore them? We would love to hear your thoughts down below in the comments.

Brian has a huge passion for WordPress, has been using it for over a decade, and even develops a couple of premium plugins. Brian enjoys blogging, movies, and hiking. Connect with Brian on Twitter.

