
When you visit a website, your browser makes dozens or hundreds of requests to its server in the background. The server responds to those requests by delivering all of the data and files that the site needs to load. However, the real process is more complex than that.
Understanding how HTTP requests work is essential if you want to boost your website’s performance. Some of these optimization measures involve minimizing and compressing requests. Essentially, you’re optimizing your server to better respond to HTTP requests.
In this article, we’ll take a closer look at how HTTP requests work. We’ll also show you the structure of HTTP requests and how to troubleshoot them if necessary. Let’s get to work!
What Is HTTP?
HTTP is a protocol. In fact, the acronym stands for HyperText Transfer Protocol. This protocol governs the structure and language of the requests and responses that take place between clients and servers. The clients are usually web browsers, but they can come in many forms, such as search engine robots.
When you visit websites through a browser, the entire connection takes place via HTTP. The protocol enables you to receive data, including text, images, videos, stylesheets, scripts, and more.
HTTP has been one of the backbones of the web since the early 90s. In the last decades, it has evolved to become more efficient. The second half of the 2010s saw the development of HTTP/2, which enables clients to load resources simultaneously instead of asynchronously. This results in a massive performance boost.
In 2022, 46 percent of the web is using HTTP/2. Now, there are already discussions about adopting HTTP/3, which is also known as HTTP-over-QUIC. HTTP/3 works with the UDP protocol, which gives it an advantage over traditional TCP connections (which is what HTTP and HTTP/2 use).
What Is an HTTP Request (and How Does It Work)?
Think about an HTTP request as your browser connecting to the server and either asking for a specific resource or sending data to it. There are several types of HTTP request methods, which completely alter the type of response that you get from the server. The most common ones are:
- GET. This is the most frequently used HTTP request method by far. A GET request asks the server for a specific piece of information or resource. When you connect to a website, your browser usually sends several GET requests to receive the data that it needs for the page to load.
- HEAD. With a HEAD request, you only receive the header information of the page that you want to load. You can use this type of HTTP request to find out the size of a document before you download it using GET.
- POST. Your browser uses the POST HTTP request method when it needs to send data to the server. For example, if you fill out a contact form on a website and submit it, you’re using a POST request so the server receives that information.
- PUT. PUT requests are similar in functionality to the POST method. However, instead of submitting data, you use PUT requests to update information that already exists on the end server.
There are some other types of HTTP requests that you can use, including the DELETE, PATCH, and OPTIONS methods. However, they’re relatively uncommon in day-to-day use.
Submitting an HTTP request involves sending a message to the receiving server in a specific format. The server returns a response and the client takes action accordingly. For instance, it may load resources or re-direct you to another page.
When you get an HTTP error, it’s usually because the server can’t fulfill your request. The error code that you get should explain why. Some of the most common causes of HTTP errors include being unable to connect to the server and find the resources that have been requested.
Try out our HTTP header Checker tool to review the status of any page.
An Introduction to HTTP Request and Response Structures
HTTP requests and responses share similar structures. If you want to be able to analyze HTTP requests and responses to understand potential errors with your site, it’s important that you understand those structures.
Generally speaking, HTTP requests are divided into three sections. Let’s take a close look at each one.
HTTP Request Line
Every HTTP request starts with a line that indicates what type of method you’re using and the version of the HTTP protocol. For example, the start of an HTTP GET request could look like this:
GET /XXX HTTP/1.1In this case, the “XXX” paremeter after the GET method indicates the file that you want to receive.
The start of an HTTP response re-iterates the version of the protocol both parties are using. It also includes an HTTP code that corresponds to the status of the response.
If you visit a website and it loads successfully, you’ll see a 2XX HTTP success message:
HTTP/1.1 200 OKThis part of the HTTP response will display error codes if the resource fails to load for any reason. If the server can’t find the page, you’ll see a response header like this one:
HTTP/1.1 400 OKIf you understand request methods and HTTP status codes, the starting line tells you exactly what kind of transaction is going on between the client and the server. Overall, this is the simplest part of the request to understand.
Request Headers
Request headers come right after request lines and they provide additional information on the transaction. The header specifies information about the host, the web server software the end-client uses, what the client’s user agent is, and more.
Here’s what an HTTP request header looks like:
Host: website.com
User-Agent: Chrome/5.0 (Windows 10)
Accept-Language: en-US
Accept-Encoding: gzip, deflate
Connection: keep-alive</code.Those are just some examples of the HTTP header parameters that you can use. Here’s what each line in that header means:
- Host: This is the IP or URL of the server that you’re making the request to.
- User-agent: This parameter contains information about the client and its Operating System (OS). Typically, this outlines the browser that you’re using and its version.
- Accept-language: This line tells the server what language the client prefers, in case there are multiple versions of the file that you’re requesting.
- Accept-encoding: This line indicates the type of encoding or compression that the client can process.
- Connection: This parameter tells the server whether to keep the connection alive or set a timeout for it. If the connection times out before completing the request, you’ll receive an error.
Let’s put together the request line and the headers to get an idea of the overall structure that you’ll need to use:
GET /XXX HTTP/1.1
Host: website.com
User-Agent: Chrome/5.0 (Windows 10)
Accept-Language: en-US
Accept-Encoding: gzip, deflate
Connection: keep-alive</code.In the above example, you’re submitting a GET request to the website.com host for a specific resource. Now, let’s see how the header in the response might look:
HTTP/1.1 200 OK
Date: Mon, 27 Jul 2022 12:28:53 GMT
Server: Apache/2.2.14 (Win32)
Last-Modified: Wed, 22 Jul 2022 19:15:56 GMT
Content-Length: 88
Content-Type: text/html
Connection: Closed</code.The response header starts from the second line and it includes the date of the connection and information about what web server and OS the host uses. If you’re requesting a file, the header will also show information about its last modification date, how long the file is, and what type of content you’re dealing with. The final line tells you that the connection is closed since the request is complete.
The information and parameters in the headers can vary depending on what kind of request you’re making. However, the overall structure remains the same.
HTTP Message Body
The message body is the most straightforward part of an HTTP request. This contains the data that you’re either sending or receiving, depending on what request method you’re using.
If you request an HTML file using the GET method, you might receive a response that’s structured like this:
HTTP/1.1 200 OK
Date: Mon, 27 Jul 2022 12:28:53 GMT
Server: Apache/2.2.14 (Win32)
Last-Modified: Wed, 22 Jul 2022 19:15:56 GMT
Content-Length: 88
Content-Type: text/html
Connection: Closed
<!DOCTYPE HTML PUBLIC “-//IETF//DTD HTML 2.0//EN”></code.The rest of the file goes here
The body of an HTTP request or response is separated from the header using a single empty line. We did not include a full HTML file in the above example to avoid confusion.
How To Monitor and Troubleshoot HTTP Requests
There are several ways to monitor HTTP requests on your website, such as by using Application Performance Management (APM) tools. These enable you to monitor “transactions” on your websites, such as PHP tasks, HTTP errors, database requests, and more.
If you’re a Kinsta user, you have access to a built-in APM tool that you can enable from the MyKinsta dashboard. The Kinsta APM tool will let you check what type of external HTTP requests your website is receiving and monitor their statuses:
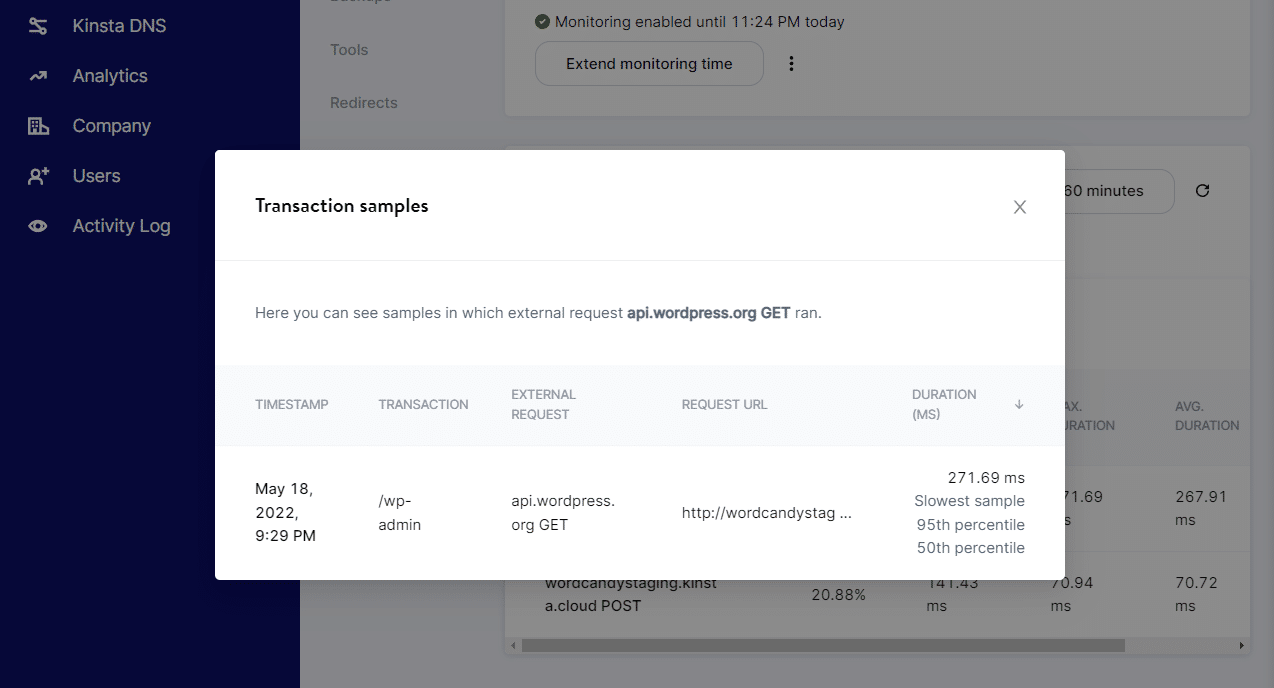
It also enables you to monitor recurring HTTP errors, which comes in handy when troubleshooting your website. If you’re seeing an HTTP status error within your site, you can enable the Kinsta APM, replicate the error, and get access to details from the request.
The APM tool can also help you identify DDoS attacks, which should be fairly easy to spot as you’ll see a barrage of HTTP requests. Knowing whether you’re dealing with a DDoS attack or a spike in traffic will help you figure out how to deal with the situation.
Summary
Understanding what HTTP requests are and how they work can help you troubleshoot issues with your website. When you run into HTTP errors, it means that the server couldn’t fulfill the request the client made. If you know what that request was and understand the error code in the HTTP response, you have more than enough information to fix the problem.
To understand an HTTP request, you’ll need to know what methods it can use. Additionally, you’ll need to know how HTTP requests and responses are structured, and understand the different HTTP status codes.
If you use Kinsta’s application, database, and managed WordPress hosting, you automatically get access to an APM tool that you can use to monitor HTTP requests for your website.
Sign up for Kinsta today and get access to this essential feature!


