
Persistent storage refers to the retention of data in a non-volatile manner so that it remains available even after a device or application powers off or restarts. Storage and retrieval of data allow web applications to save user information and states and operate reliably.
In monolithic applications, storage access is straightforward because the server and storage live together. However, geographically distributed systems make access more complex, as the storage system must remain available to all components worldwide.
Containerization further complicates the issue because containers are lightweight, stateless, and ephemeral — unsuitable characteristics for storing data. Therefore, any persistent storage solution must be able to work seamlessly with containers, adding another layer of complexity.
This article takes a platform-independent look at persistent storage by exploring its types, architecture, and use cases. It also provides a hands-on demonstration illustrating the difference between volume storage and persistent volume storage in Docker.
Types of Persistent Storage
There are several types of non-volatile storage, including traditional spinning disks (hard disk drives or HDDs), solid-state drives (SSDs), network-attached storage (NAS), and storage area networks (SANs).
- HDDs are electro-mechanical data storage devices that store and retrieve digital data using spinning disks of magnetic media. The disks use magnetic heads on a movable actuator arm that read and write data.
- SSDs, sometimes called semiconductor storage devices, solid-state devices, or solid-state disks, use integrated circuit assemblies to store data persistently, usually using interconnected flash devices containing no moving parts. Their stationary nature makes them faster and more reliable than HDDs.
- Network-attached storage is a group of HDDs, SSDs, or both, connected through a local network using a file system like the New Technology File System (NTFS) or the fourth extended filesystem (EXT4).
- SANs are networked high-speed, block-level storage devices, like tape libraries or disk arrays. Their connection appears to the operating system as local storage and is not accessible through the local area network (LAN).
Persistent Storage Architecture
There are three approaches to persistent storage, each with unique use cases and limitations.
Object Persistent Architecture
The object persistent architecture approach uses object-relational mapping (ORM) to store data as objects in a relational or key-value database. This approach is useful when the data does not have a defined schema, as the ORM handles its storage and retrieval.
Block Persistent Architecture
Block persistent architecture uses block-level storage devices, which are useful when storing large files. This approach is beneficial when storing large amounts of data, as you can use multiple blocks to increase storage capacity.
Filestore Persistent Architecture
As the name suggests, the filestore persistent architecture approach uses a file system to store data. One method involves using database servers, which provide a centralized way of storing data. Many cloud hosting solutions use database servers that are easily attached to applications and offer persistence.
Filestore persistent architecture is helpful in applications requiring frequent retrieval of files and when you need an interface to manage them.
Persistent Storage Use Cases
This section discusses some of the use cases of each storage type.
Object Persistent Storage
- Cloud storage: Object persistent storage is commonly used in cloud storage solutions to store and retrieve large amounts of unstructured data, such as images, videos, and documents. Cloud providers use object storage to provide customers with scalable, highly available, and durable storage services.
- Big data analytics: Object persistent storage is used in big data analytics to store and manage large data sets often used for data analysis, machine learning, and AI. Object storage allows data to be accessed quickly and efficiently, making it a key component of big data architectures.
- Content delivery networks: Object persistent storage is used in content delivery networks (CDNs) to store and distribute content, such as images, videos, and static files, across a global network of servers. Object storage allows CDNs to deliver high-speed content to users worldwide, regardless of location.
Block Persistent Storage
- High-performance computing (HPC): HPC environments rapid and efficient processing of sizable volumes of data. Block persistent storage allows HPC clusters to store and retrieve large datasets, such as scientific simulations, weather modeling, and financial analysis. Block storage is often preferred for HPC because it provides high-performance, low-latency access to data, and allows for parallel input/output (I/O) operations, which can significantly improve processing times.
- Video editing: Video editing applications require high-performance and low-latency access to large video files. They must also accommodate significant numbers of I/O operations per second and low latency to render and edit video files in real-time. Block storage provides these capabilities, making it an ideal solution for video editing workflows.
- Gaming: Gaming applications also demand high performance and low latency to access game assets and player data. Block storage quickly stores and retrieves large amounts of data, ensuring that game environments load promptly and remain responsive during gameplay.
Filestore Persistent Storage
- Media and entertainment: Video editing, animation, and rendering applications commonly use persistent storage. These applications require high-performance and low-latency access to large media files, such as video, audio, and images. Filestore provides a shared file system that can be accessed by multiple clients, making it an ideal storage solution for these applications.
- Web content management: Web content management systems (CMSs) use filestore persistent storage in shared file systems to store and manage website content, such as text, images, and multimedia files. Filestore provides a central location for website content, making managing and updating it easier. It also enables multiple users to simultaneously work on the same content, improving collaboration and productivity.
Persistent Storage in Containers
Containers are lightweight, portable, secure, and straightforward, offering a fusion between different applications. They must have a mechanism to persist data between container restarts and removal. Containers have file storage or a file system like traditional applications, but whenever you rebuild them with new changes, you lose all non-persistent data.
That’s why containers offer the option to include volume storage or mount a storage volume. Containers treat storage volumes as a directory. Any data written to the volume goes into the host file system.
Persistent storage for containers must work in this way because restarting a container creates a new instance and discard the old instance. If a container does not have a consistent view of the data, the data will disappear when the container restarts. A storage volume preserves the data across sessions and container restarts, allowing the container to maintain its state even if it is moved or restarted.
Volume vs Persistent Volume
Containers provide 2 ways of storing persistent data: using volumes and persistent volumes. There is a significant difference between them. A container manages the data in volume storage. When you stop a container, the data remains and is available when you restart the container. However, when you delete or remove a container, the data is lost as you also delete the underlying volume storage.
Persistent volume storage or bind mounts is a way of storing the data outside the container’s file system. This way, the data is not lost even when you delete the container. It is persistent until manually deleted.
The following section demonstrates both volume types with examples.
Container Persistent Storage Demo
We’ve created a small web application to demonstrate persistent storage with Docker containers. You can follow along by installing Docker and grabbing the code from this GitHub repository.
The application is an elementary form with 2 fields for user input:
- Title
- Document Text
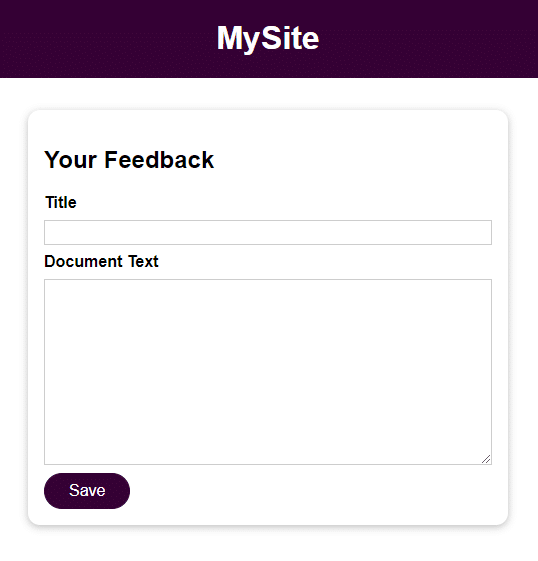
Once you save the user input, you can access it by opening the file in the feedback directory with the name provided in the Title field. The input from the Document Text field is the file’s content.
How To Use Volume Storage
Once you have installed the application on your own machine, it can use volume storage as shown in the Dockerfile.
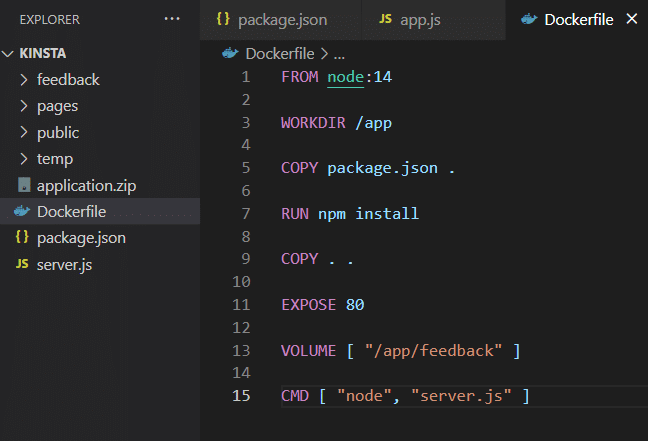
Now, you build the image and run the container. To do so, execute the following commands.
docker build -t feedback-node:volumes .
docker run -d -p 3000:80 --name feedback-app feedback-node:volumes
Once the application runs, navigate to localhost:3000 to submit feedback.
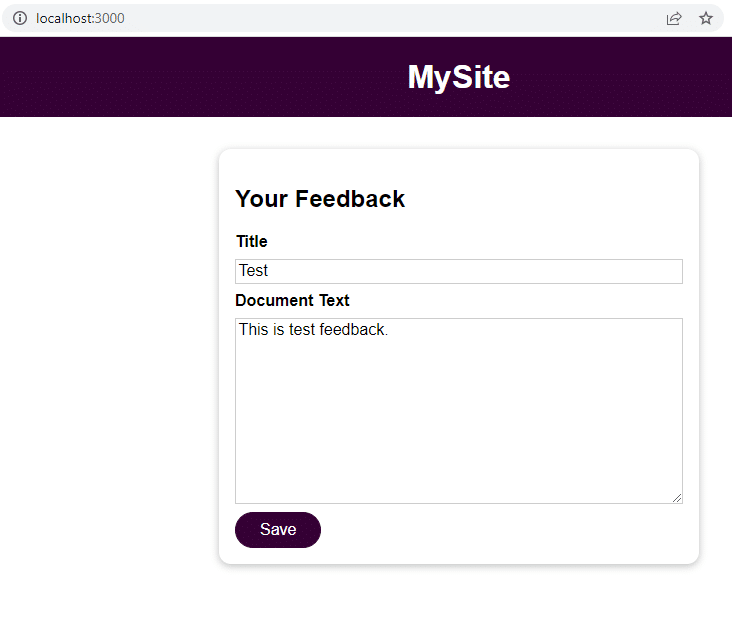
Click Save and navigate to localhost:3000/feedback/test.txt to see if the input is stored successfully or not.
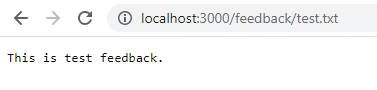
Remove and restart the container to see if the input persists.
docker stop feedback-app
docker start feedback-appIf you now visit the same URL, you see that the feedback is still there. But what happens if you remove the container and restart it?
docker stop feedback-app
docker rm feedback-app
docker run -d -p 3000:80 --name feedback-app feedback-node:volumesOnce restarted, if you return to that URL, it no longer exists because the data was lost when you removed the container. Volume data persists only when stopping the container, not when removing it.
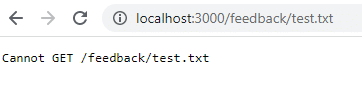
To mitigate this problem and persist the data even when you remove the container, you must use persistent volume storage or named storage. First, you should clean up the containers and images.
docker stop feedback-app
docker rm feedback-app
docker rmi feedback-node:volumesHow to Use Persistent Volume Storage
Before testing this, you must remove the VOLUME attribute from the Dockerfile and rebuild the image.
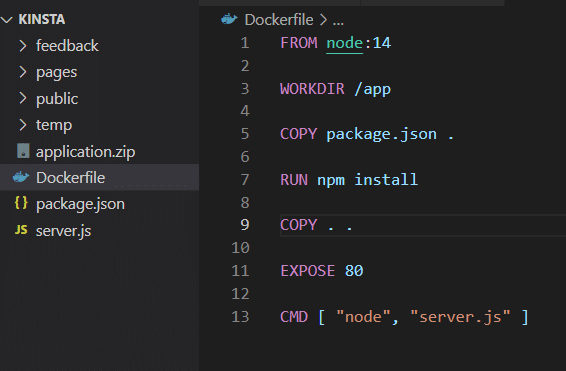
docker build -t feedback-node:volumes .
docker run -d -p 3000:80 --name feedback-app -v feedback:/app/feedback feedback-node:volumesAs you can see, in the second command, you use the -v flag to define the persistent volume outside the container, which persists even when you remove the container.
Like the previous step, try adding feedback and access it once you stop, remove, and restart the container.
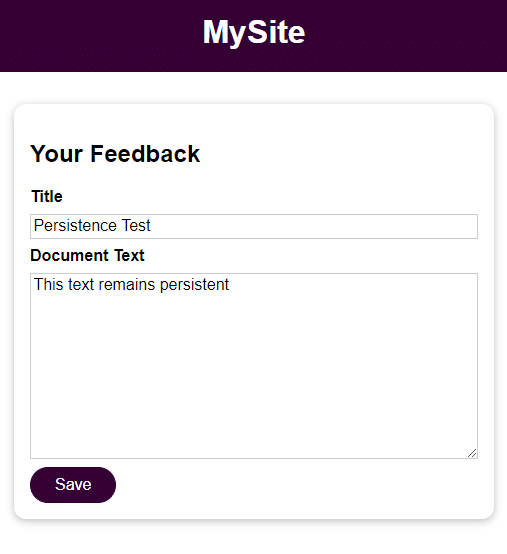
docker stop feedback-app
docker rm feedback-app
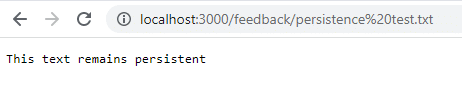
docker run -d -p 3000:80 --name feedback-app -v feedback:/app/feedback feedback-node:volumesAs you see, even after stopping and removing the container, the data is accessible and it remains.
Summary
Persistent storage is vital for containerized applications because it allows persisting data outside a container’s lifecycle. The 2 main types of persistent storage for containerized applications are volumes and bind mounts, each with its benefits and use cases.
Volumes are stored within the container’s file system, while bind mounts are directly accessible on the host machine.
Persistent storage enables data to be shared between containers, making it possible to build complex, multi-tier applications. Persistent storage is essential for ensuring the stability and continuity of containerized applications, providing a reliable and flexible way to store crucial data.

Steve Bonisteel is a Technical Editor at Kinsta who began his writing career as a print journalist, chasing ambulances and fire trucks. He has been covering Internet-related technology since the late 1990s.

