Ever wanted to compare prices from multiple sites all at once? Or maybe automatically extract a collection of posts from your favorite blog? It’s all possible with web scraping.
Web scraping refers to the process of extracting content and data from websites using software. For example, most price comparison services use web scrapers to read price information from several online stores. Another example is Google, which routinely scrapes or “crawls” the web to index websites.
Of course, these are only two of many web scraping use cases. In this article, we’ll dive into the world of web scrapers, learn how they work, and see how some websites try to block them. Read on to learn more and start scraping!
What Is Web Scraping?
Web scraping is a collection of practices used to automatically extract — or “scrape” — data from the web.
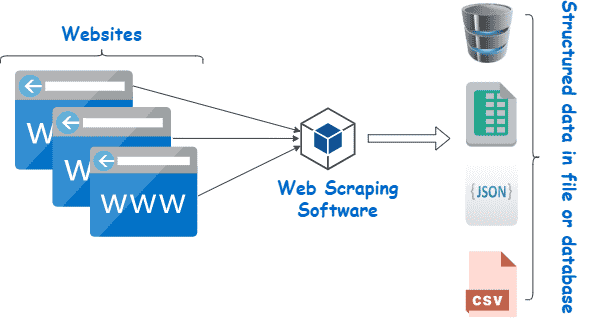
Other terms for web scraping include “content scraping” or “data scraping.” Regardless of what it’s called, web scraping is an extremely useful tool for online data gathering. Web scraping applications include market research, price comparisons, content monitoring, and more.
But what exactly does web scraping “scrape” — and how is it possible? Is it even legal? Wouldn’t a website not want someone to come along and scrape their data?
The answers depend on several factors. Before we dive into methods and use cases, however, let’s take a closer look at what web scraping is and whether it’s ethical or not.
What Can We “Scrape” From The Web?
It’s possible to scrape all kinds of web data. From search engines and RSS feeds to government information, most websites make their data publicly available to scrapers, crawlers, and other forms of automated data gathering.
Here are some common examples.
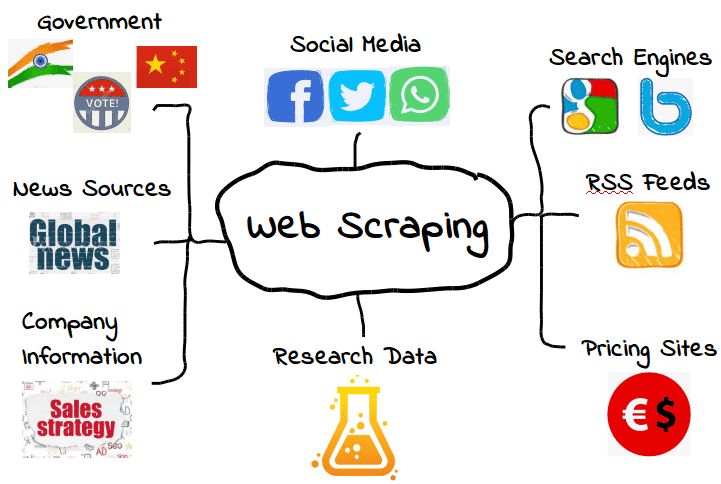
However, that doesn’t mean this data is always available. Depending on the website, you may need to employ a few tools and tricks to get exactly what you need — assuming the data is even accessible in the first place. For example, many web scrapers can’t extract meaningful data from visual content.
In the simplest cases, web scraping can be done through a website’s API or application programming interface. When a website makes its API available, web developers can use it to automatically extract data and other useful information in a convenient format. It’s almost like the web host is providing you with your very own “pipeline” into their data. Talk about hospitality!
Of course, that’s not always the case — and many websites you want to scrape won’t have an API you can use. Plus, even websites that do have an API won’t always provide you with data in the right format.
As a result, web scraping is only necessary when the web data you want isn’t available in the form(s) you need. Whether that means the formats you want aren’t available, or the website simply isn’t providing the full scope of data, web scraping makes it possible to get what you want.
While that’s great and all, it also raises an important question: If certain web data is restricted, is it legal to scrape it? As we’ll see shortly, it can be a bit of a gray area.
Is Web Scraping Legal?
For some people, the idea of web scraping can almost feel like stealing. After all, who are you to just “take” someone else’s data?
Thankfully, there’s nothing inherently illegal about web scraping. When a website publishes data, it’s usually available to the public and, as a result, free to scrape.
For example, since Amazon makes product prices available to the public, it’s perfectly legal to scrape price data. Many popular shopping apps and browser extensions use web scraping for this exact purpose, so users know they’re getting the right price.
However, not all web data is made for the public, meaning not all web data is legal to scrape. When it comes to personal data and intellectual property, web scraping can quickly turn into malicious web scraping, resulting in penalties such as a DMCA takedown notice.
What Is Malicious Web Scraping?
Malicious web scraping is web scraping data that the publisher didn’t intend or consent to share. Though this data is usually either personal data or intellectual property, malicious scraping can apply to anything that’s not meant for the public.
As you might imagine, this definition has a gray area. While many types of personal data are protected by laws such as the General Data Protection Regulation (GDPR) and California Consumer Privacy Act (CCPA), others aren’t. But that doesn’t mean there aren’t situations where they aren’t legal to scrape.

For example, let’s say a web host “accidentally” makes its user information available to the public. That might include a complete list of names, emails, and other information that’s technically public but maybe not intended to be shared.
While it would also be technically legal to scrape this data, it’s probably not the best idea. Just because data is public doesn’t necessarily mean that the web host has consented to it being scraped, even if its lack of oversight has made it public.
This “gray area” has given web scraping a somewhat mixed reputation. While web scraping is definitely legal, it can easily be used for malicious or unethical purposes. As a result, many web hosts don’t appreciate having their data scraped — regardless of whether it’s legal.
Another type of malicious web scraping is “over-scraping,” where scrapers send too many requests over a given period. Too many requests can put a massive strain on web hosts, who’d much rather spend server resources on actual people than scraping bots.
As a general rule, use web scraping sparingly and only when you’re completely sure that the data is meant for public use. Remember, just because data is publicly available doesn’t mean it’s legal or ethical to scrape it.
What Is Web Scraping Used For?
At its best, web scraping serves many useful purposes in many industries. As of 2021, almost half of all web scraping is used to bolster ecommerce strategies.
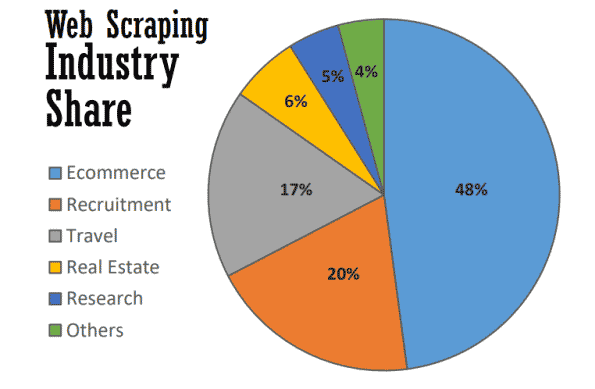
Web scraping has become the backbone of many data-driven processes, from tracking brands and providing up-to-date price comparisons to performing valuable market research. Here are some of the most common.
Market Research
What are your customers doing? What about your leads? How’s your competitors’ pricing compared to yours? Do you have information to create a successful inbound marketing or content marketing campaign?
These are just a few of the questions that form the cornerstones of market research — and the very same that can be answered with web scraping. As much of this data is publicly available, web scraping has become an invaluable tool for marketing teams looking to keep an eye on their market without having to perform time-consuming manual research.
Business Automation
Many of the benefits of web scraping for market research also apply to business automation.
Where many business automation tasks require gathering and crunching large amounts of data, web scraping can be invaluable — especially if doing so would otherwise be cumbersome.
For example, let’s say you need to gather data from ten different websites. Even if you’re gathering the same type of data from each, each website might require a different extraction method. Rather than manually going through different internal processes on each website, you might use a web scraper to do it automatically.
Lead Generation
As if market research and business automation weren’t enough, web scraping can also generate valuable lead lists with little effort.
Though you’ll need to set your targets with some precision, you can use web scraping to generate enough user data to create structured lead lists. Results may vary, of course, but it’s more convenient (and more promising) than building lead lists on your own.
Price Tracking
Extracting prices — also known as price scraping — is one of the most common applications for web scraping.
Here’s an example from the popular Amazon price-tracking app Camelcamelcamel. The app regularly scrapes product prices and then compares them on a graph over time.
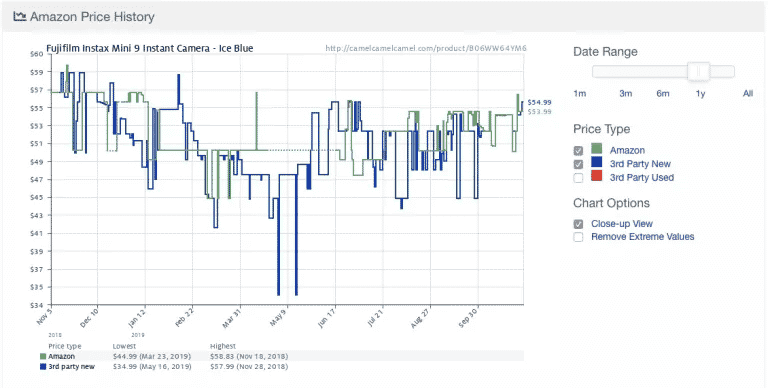
Prices can fluctuate wildly, even daily (look at the sudden drop in prices around May 9!). With access to historical price trends, users can check whether the price they’re paying is ideal. In this example, the user might choose to wait a week or so in hopes of saving $10.
Despite its usefulness, price scraping comes with some controversy. Since many people want real-time price updates, some price tracking apps quickly become malicious by overloading certain websites with server requests.
As a result, many e-commerce websites have begun taking extra measures to block web scrapers altogether, which we’ll cover in the next section.
News and Content
There’s nothing more valuable than staying in the know. From monitoring reputations to tracking industry trends, web scraping is a valuable tool for staying informed.
While some news websites and blogs already provide RSS feeds and other easy interfaces, they aren’t always the norm — nor are they as common as they used to be. As a result, aggregating the exact news and content you need often requires some form of web scraping.
Brand Monitoring
While you’re scraping the news, why not check on your brand? With brands that get a lot of news coverage, web scraping is an invaluable tool for staying up to date without having to pour through countless articles and news sites.
Web scraping is also useful for checking a brand’s product or service’s minimum available price (MAP). Though this is technically a form of price scraping, it’s a key insight that can help brands determine whether their pricing aligns with customer expectations.
Real Estate
If you’ve ever searched for an apartment or bought a house, you know how much there is to sort through. With thousands of listings scattered across multiple real estate websites, it can be hard to find exactly what you’re looking for.
Many websites use web scraping to aggregate real estate listings into a single database to make the process easier. Popular examples include Zillow and Trulia, though there are many others that follow a similar model.
However, aggregating listings isn’t the only use for web scraping in real estate. For example, realtors can use scraping applications to stay on top of average rent and sales prices, types of properties being sold, and other valuable trends.
How Does Web Scraping Work?
Web scraping may sound complicated, but it’s actually very simple.
While methods and tools can vary, all you have to do is find a way to (1) automatically browse your target website(s) and (2) extract the data once you’re there. Usually, these steps are performed with scrapers and crawlers.
Scrapers and Crawlers
In principle, web scraping works almost the same as a horse and plow.

As the horse guides the plow, the plow turns and breaks the earth, helping make way for new seeds while re-working unwanted weeds and crop residue back into the soil.
Apart from the horse, web scraping isn’t much different. Here, a crawler plays the role of the horse, guiding the scraper — effectively our plow — through our digital fields.
Here’s what both of them do.
- Crawlers (sometimes known as spiders) are basic programs that browse the web while searching for and indexing content. While crawlers guide web scrapers, they aren’t exclusively used for this purpose. For example, search engines like Google use crawlers to update website indexes and rankings. Crawlers are usually available as pre-built tools that allow you to specify a given website or search term.
- Scrapers do the dirty work of quickly extracting relevant information from websites. Since websites are structured in HTML, scrapers use regular expressions (regex), XPath, CSS selectors, and other locators to quickly find and extract certain content. For example, you might give your web scraper a regular expression specifying a brand name or keyword.
If that sounds a little overwhelming, don’t worry. Most web scraping tools include built-in crawlers and scrapers, making it easy to do even the most complicated jobs.
Basic Web Scraping Process
At its most basic level, web scraping boils down to just a few simple steps:
- Specify URLs of websites and pages you want to scrape
- Make an HTML request to the URLs (i.e., “visit” the pages)
- Use locators such as regular expressions to extract the desired information from the HTML
- Save the data in a structured format (such as CSV or JSON)
As we’ll see in the next section, a wide range of web scraping tools can be used to perform these steps automatically.
However, it’s not always so simple — especially when performing web scraping on a larger scale. One of the biggest challenges of web scraping is keeping your scraper updated as websites change layouts or adopt anti-scraping measures (not everything can be evergreen). While that’s not too hard if you’re only scraping a few websites at a time, scraping more can quickly become a hassle.
To minimize the extra work, it’s important to understand how websites attempt to block scrapers — something we’ll learn in the next section.
Web Scraping Tools
Many web scraping functions are readily available in the form of web scraping tools. Though many tools are available, they vary widely in quality, price, and (unfortunately) ethics.
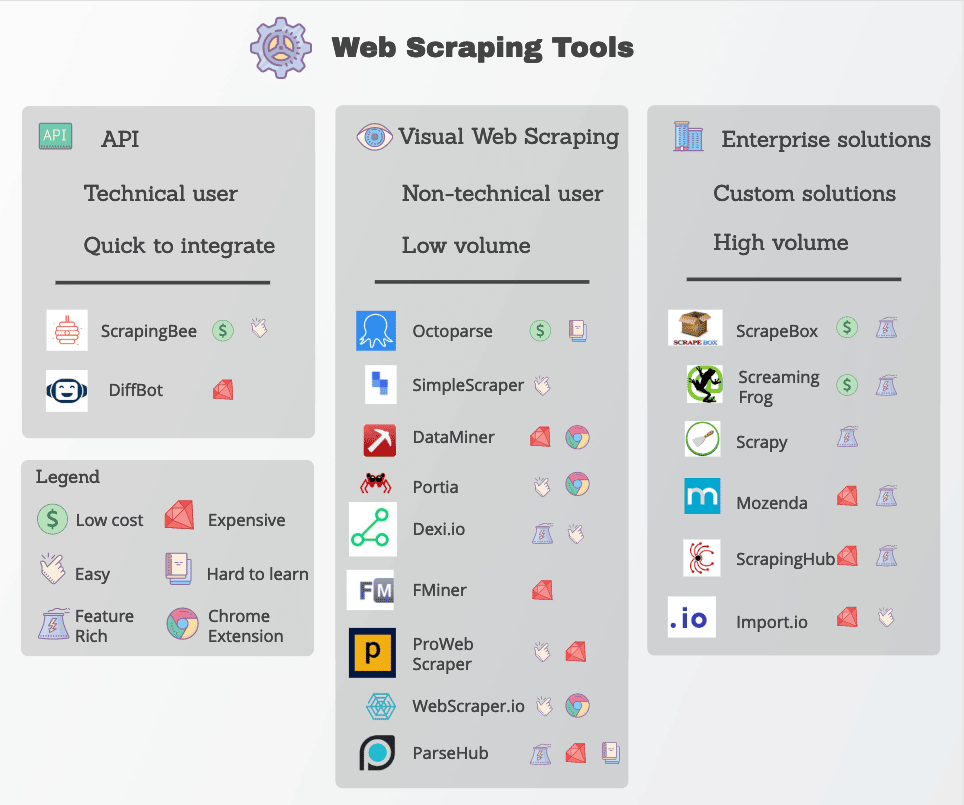
In any case, a good web scraper will be able to reliably extract the data you need without running into too many anti-scraping measures. Here are some key features to look for.
- Precise locators: Web scrapers use locators such as regular expressions and CSS selectors to extract specific data. The tool you choose should allow you several options for specifying what you’re looking for.
- Data quality: Most web data is unstructured — even if it’s presented clearly to the human eye. Working with unstructured data isn’t only messy, but it rarely delivers good results. Be sure to look for scraping tools that clean and sort raw data before delivery.
- Data delivery: Depending on your existing tools or workflows, you’ll probably need scraped data in a specific format such as JSON, XML, or CSV. Instead of converting the raw data yourself, look for tools with data delivery options in the formats you need.
- Anti-scraping handling: Web scraping is only as effective as its ability to bypass blocks. While you may need to employ additional tools such as proxies and VPNs to unblock websites, many web scraping tools do this by making small modifications to their crawlers.
- Transparent pricing: Though some web scraping tools are free to use, more robust options come at a price. Pay close attention to the pricing scheme, especially if you intend to scale and scrape many sites.
- Customer support: While using a pre-built tool is extremely convenient; you won’t always be able to fix problems yourself. As a result, be sure your provider also offers reliable customer support and troubleshooting resources.
Popular web scraping tools include Geekflare, Octoparse, Apify, Import.io, and Parsehub.
Protecting Against Web Scraping
Let’s turn the tables a bit: Suppose you’re a web host but don’t want other people to use all these clever methods to scrape your data. What can you do to protect yourself?
Beyond basic security plugins, there are a few effective methods for blocking web scrapers and crawlers.
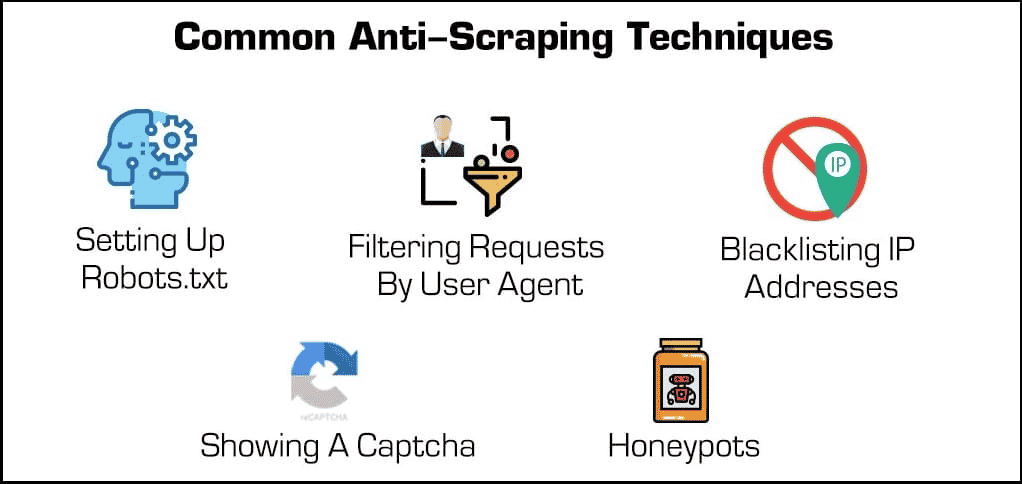
- Blocking IP addresses: Many web hosts keep track of their visitor’s IP addresses. If a host notices that one particular visitor is generating many server requests (such as in the case of some web scrapers or bots), then they might block the IP entirely. However, scrapers can surpass these blocks by changing their IP address through a proxy or VPN.
- Setting up robots.txt: A robots.txt file lets a web host tell scrapers, crawlers, and other bots what they can and cannot access. For example, some websites use a robots.txt file to stay private by telling search engines not to index them. While most search engines respect these files, many malicious forms of web scrapers don’t.
- Filtering requests: Whenever someone visits a website, they’re “requesting” an HTML page from the web server. These requests are often visible to web hosts, who can view certain identifying factors such as IP addresses and user agents such as web browsers. While we’ve already covered blocking IPs, web hosts can also filter by user agent.
For example, if a web host notices many requests from the same user running a long-outdated version of Mozilla Firefox, then they could simply block that version and, in doing so, block the bot. These blocking capabilities are available in most managed hosting plans.
- Showing a Captcha: Have you ever had to type an odd string of text or click on at least six sailboats before accessing a page? Then you’ve encountered a “Captcha” or completely automated public Turing test for telling computers and humans apart. Though they may be simple, they’re incredibly effective at filtering out web scrapers and other bots.
- Honeypots: A “honeypot” is a type of trap used to attract and identify unwanted visitors. In the case of web scrapers, a web host might include invisible links on their web page. Though human users won’t notice, bots will automatically visit them as they scroll through, allowing web hosts to collect (and block) their IP addresses or user agents.
Now let’s turn the tables back again. What can a scraper do to overcome these protections?
While some anti-scraping measures are hard to bypass, there are a couple of methods that tend to work often. These involve changing your scraper’s identifying features in some way.
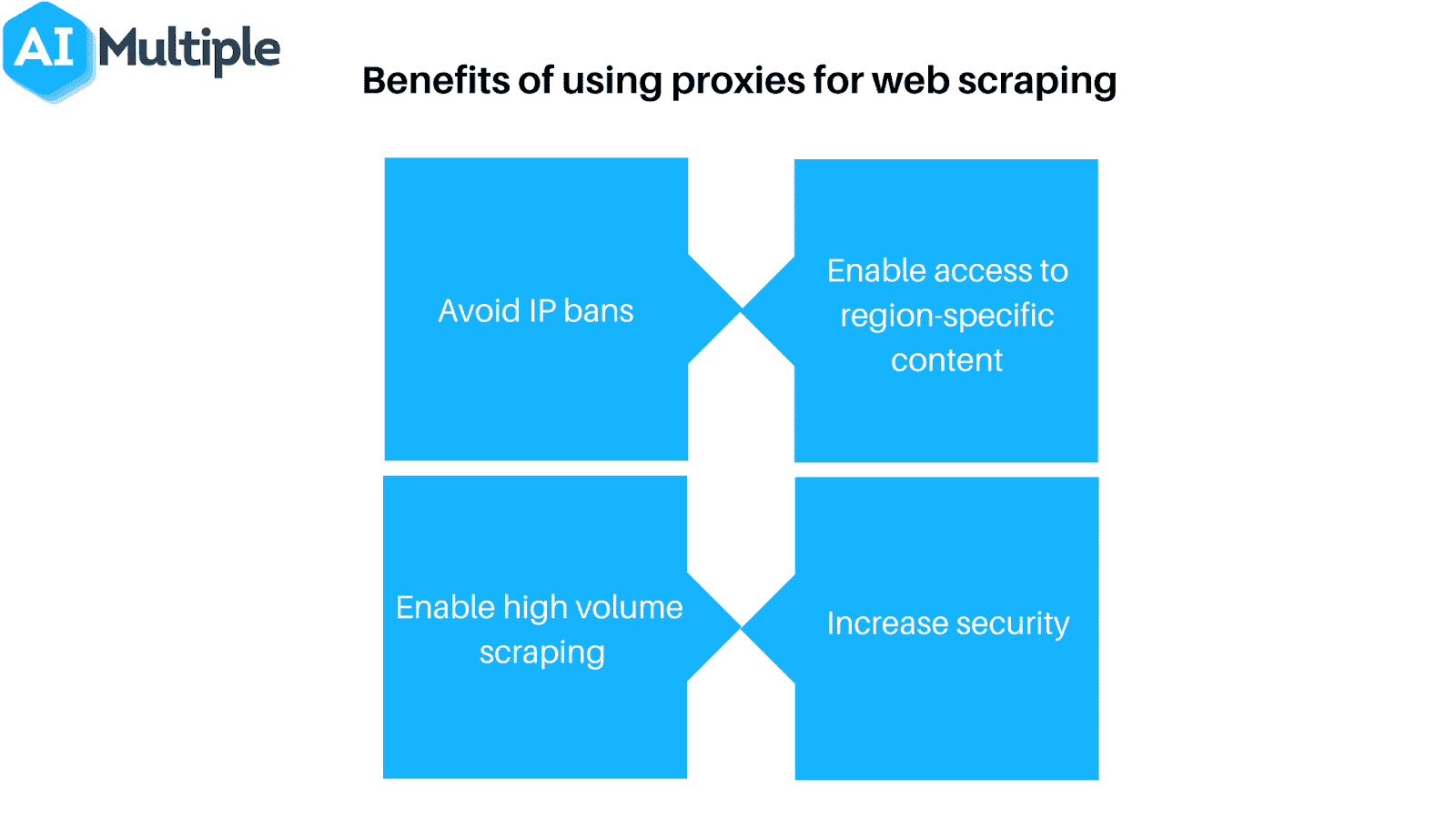
- Use a proxy or VPN: Since many web hosts block web scrapers based on their IP address, it’s often necessary to use a variety of IP addresses to guarantee access. Proxies and virtual private networks (VPNs) are ideal for this task, though they have a few key differences.
- Regularly visit your targets: Most (if any) web scrapers will tell you when they’ve been blocked. As a result, it’s important to regularly check where you’re scraping from to see whether you’ve been blocked or if the website’s formatting has changed. Note that one of these is virtually guaranteed at some point.
Of course, none of these measures are necessary if you use web scraping responsibly. If you decide to implement web scraping, remember to scrape sparingly and respect your web hosts!
Summary
While web scraping is a powerful tool, it also poses a powerful threat to many web hosts. No matter what side of the server you’re on, everyone has a vested interest in making sure that web scraping is used responsibly and, of course, for good.
If you’re a web host looking to control web scrapers, look no further than Kinsta’s managed hosting plans. You can limit bots and safeguard valuable data and resources with many access control tools available.
For more information, schedule a free demo or contact a web hosting expert from Kinsta today.