
With its growing market share, WordPress has been — and continues to be — the most popular CMS to create, manage, and develop websites.
Still, WordPress represents just a fraction of development done on the web. What about all the developers who aren’t using WordPress? They also create, run, and manage web applications for their company, clients, customers, or themselves.
At Kinsta, we’ve been working with thousands of developers and hundreds of agencies whose clients have projects built on WordPress. Many also have projects that are not powered by the famous CMS.
Until today, Kinsta focused on building managed WordPress hosting solutions — meaning customers (and their clients) weren’t able to leverage the benefits of our platform for non-WordPress projects and host all projects under “one roof.” This made their work harder and less efficient.
So we started looking for ways we could make their lives easier.
The more feedback we received and the more we talked with our customers and beta testers about their projects, the more we came to realize that our customers were struggling with one underlying pain point.
But there’s a plot twist: It wasn’t just our customers.
We realized that this pain point is experienced by almost every developer, DevOps team, and agency that manages web projects. Everyone struggles with it and is eager to find a better solution.
Developers Shouldn’t Waste Time Worrying About Hosting; They Should Focus on Development
What’s the issue?
Lack of simplicity in a cloud hosting platform.
Developers want to ship their applications fast. Developers need a platform that allows them to have everything in one place, under one roof.
A platform that’s simple, clear, and easy to use in a way that’s not confining development work to a single technology, framework, or library.
A platform that is easy to learn and use from the very first day without the need for special courses or platform-specific certifications.
A platform with a simple and transparent pricing model. (Have you ever tried to understand AWS’s pricing? Challenging!)
We knew Kinsta’s containerized architecture would allow us to address these needs and deliver the platform and tools for developers to do their best work.
On top of this, we knew we have:
- 8+ years of experience in the hosting industry
- Unmatched support
- Talented developers and engineering teams who are capable of solving any technical issue
- DevOps teams that are second to none when it comes to orchestrating, managing, and scaling our hosting platform
That’s why we built our new, enhanced hosting solutions on top of the same platform that makes our WordPress services so powerful. Now, after more than a year of hard work involving 320+ Kinstanians, 750+ beta testers, and countless iterations, we have made it available to the public.
Introducing Application Hosting and Database Hosting Solutions
Kinsta’s vision is to change the status quo. We do this through our strong commitment to delivering the best experience for developers:
We are constantly evolving to offer industry-leading tools and services for the modern developer. We’re committed to the best experience for developers and businesses, building for performance and ease of use.
By adding new services to our offer, developers and DevOps teams of all shapes and sizes now have a plethora of hosting solutions to choose from for their applications, databases, services, and WordPress sites, with more flexibility than ever.
Specifically, Kinsta now offers:
Let’s take a closer look at each one.
Managed WordPress Hosting (In a Nutshell)
Powered by a powerful cloud infrastructure, we’ve built a managed WordPress hosting service that powers 25,000+ businesses and 100,000 websites with everything they need to keep running and growing.
Thanks to the usage of the highest-end CPUs and global availability of high-performance servers, 29 available data centers, and the blazing-fast Kinsta CDN with 300+ PoPs to serve static and dynamic content to a globally-distributed audience, customers migrating from any host to Kinsta notice an average of 20% faster load times almost instantly.
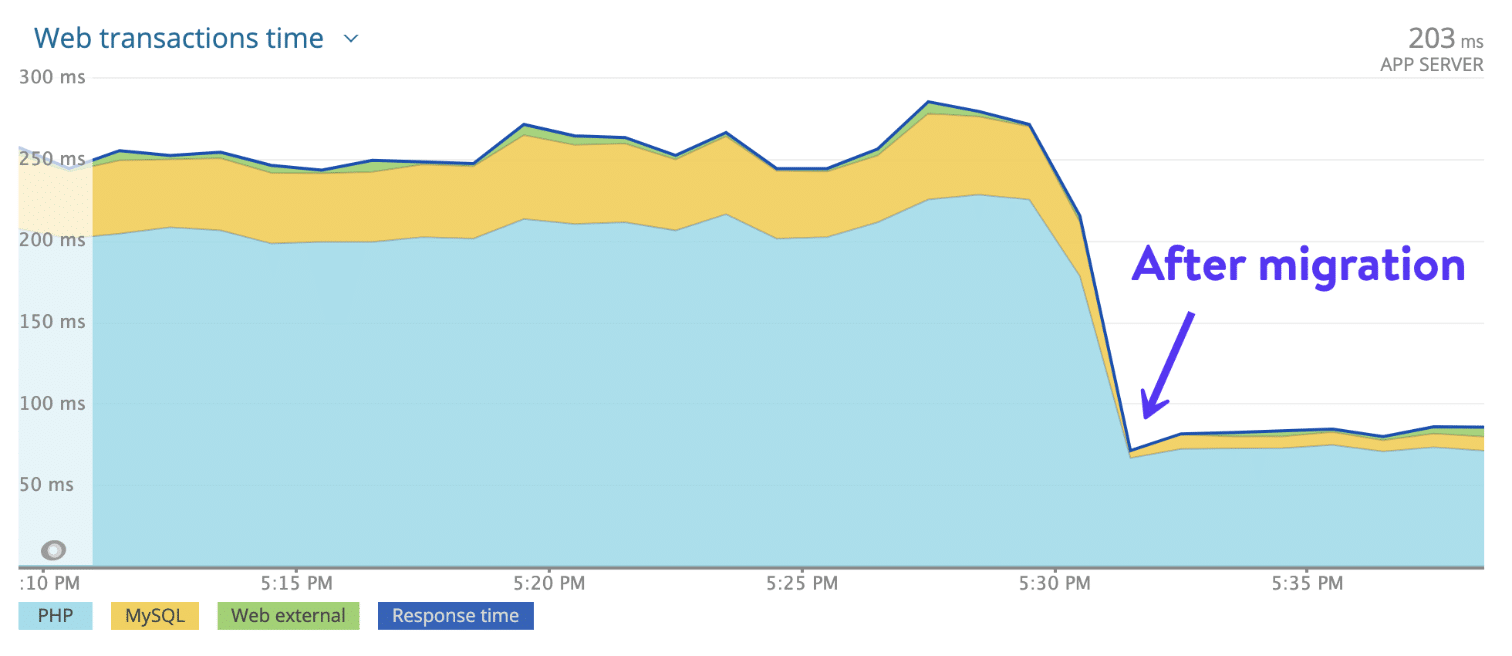
But the benefits don’t stop there.
Thanks to automatic backups, MyKinsta (our custom and easy-to-use dashboard for site management), built-in application monitoring tool, and enterprise-level firewall and DDoS protection powered by Cloudflare, our managed WordPress hosting solution helps site managers and developers sleep well at night knowing that their sites are safe.
They also know Kinsta saves them hours of work every month. Less time spent doing repetitive yet critical tasks means less overhead and less maintenance cost for your business.
Does your business run on WordPress? Are you a WordPress developer looking for a host with tools that can help you streamline your work? Check out our Managed WordPress Hosting solutions.
Application Hosting (In a Nutshell)
Web development is living an interesting moment that shows how articulate, nuanced, and complex this world is today. Our new Application Hosting solution simplifies the work of modern web developers.
We make it simple by freeing you from setting up containers, managing servers, worrying about the OS, managing backups, installing SSL certificates, and adding custom domains — everything that might prevent you from focusing exclusively on development.
We’ve built a development platform designed to help you get your applications in front of users as quickly as possible.
Kinsta’s Application Hosting is what the market usually refers to as a Platform-as-a-Service (PaaS), with tools that make deployment of your applications from code-hosting services like GitHub fast and easy and the capacity for running them smoothly in an optimized environment that’s built to scale.
How To Deploy an Application to Kinsta
Our engineers and product managers have focused on building a streamlined process for your deployments. The process requires just 3 steps:
- Connect to your GitHub account and choose a repository
- Automatically (on every commit) or manually deploy your application
- Build, scale, and run your processes separately
It’s that easy!
You don’t have to worry about setting up container images because we automatically detect and deploy applications built in this growing list of languages or frameworks:
- Node.js
- PHP
- Django
- Rails
- Java
- Scala
- Go
(Note: We’re curating a list of basic “Hello World” repositories you can fork and deploy on Kinsta to take the service for a spin.)
If you prefer having more control with a custom Docker image, you can use your own Dockerfile in the repository. This will allow you to use almost any language/framework and won’t limit you to those supported by our current Buildpacks.
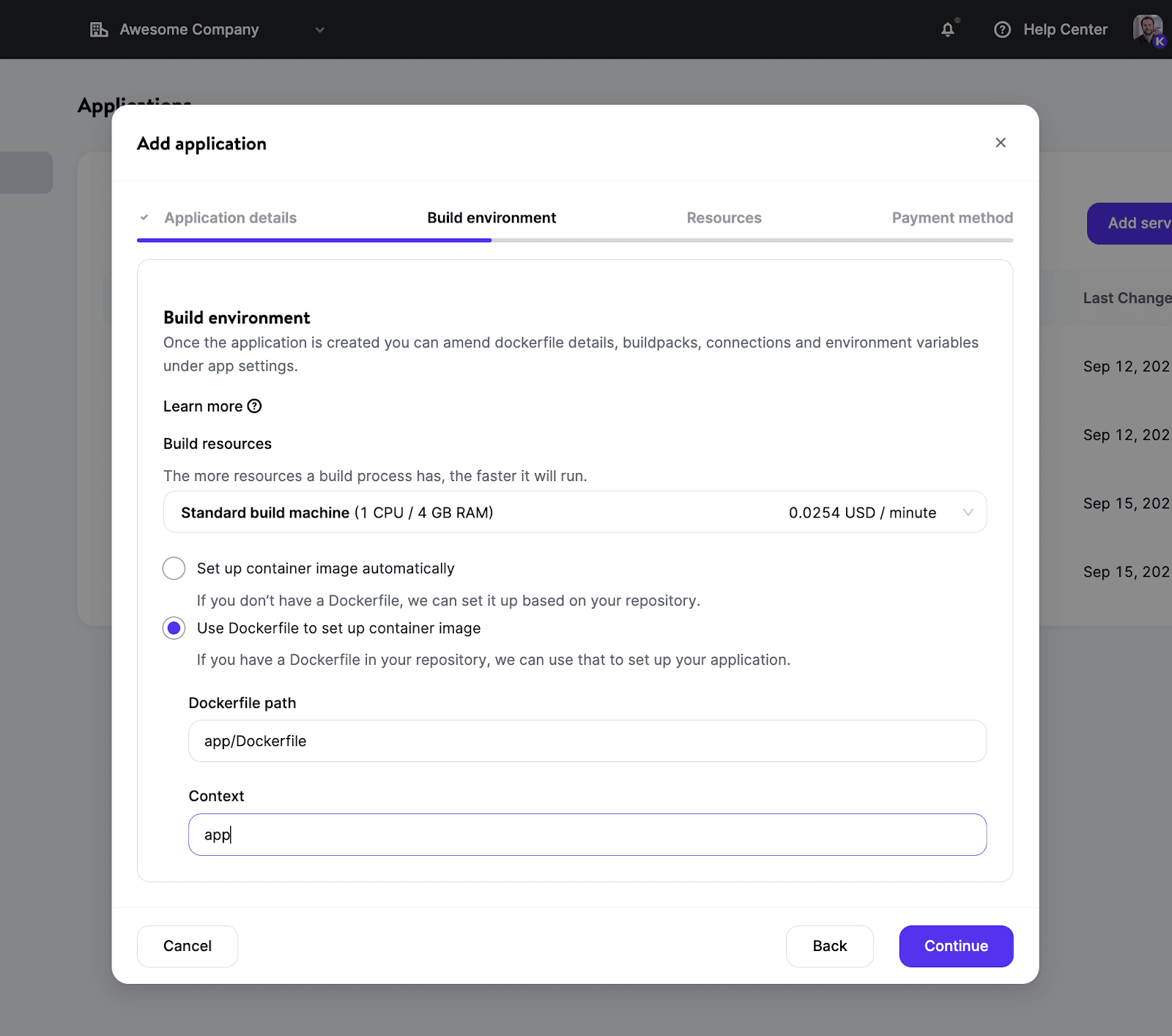
Once your build environment is set up, you’ll have plenty of options to choose resource sizes (thanks to different pod types) that match your needs and define the instance number for better scalability.
For an in-depth look at all the features, make sure to read our documentation on Application Hosting.
Powerful Analytics to Monitor Your Applications
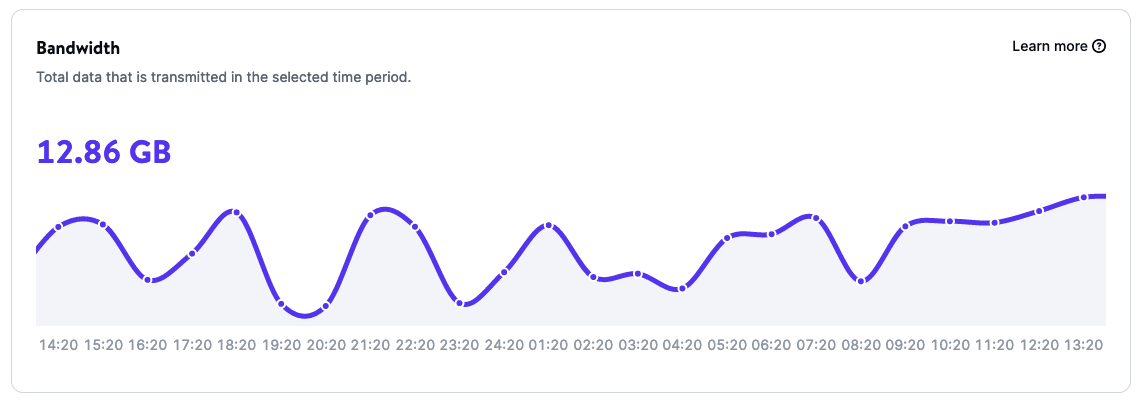
Thanks to the Analytics pages for your applications, you can get reports on application usage that include:
- Bandwidth
- Build time
- Runtime
- CPU usage
- Memory usage
What About Pricing?
Application Hosting offers resource-based options, which means you’ll be charged exclusively for your usage and nothing more. And the first $20 is on us for both new and existing customers.
Learn more about Application Hosting at Kinsta and deploy your first application to one of our 24 data center locations.
Database Hosting (In a Nutshell)
Databases are a key component of many web projects. Although there are applications that don’t need one, the vast majority require a database.
Thanks to Kinsta’s Database Hosting solution, you can set up a database with just a few clicks, and you can connect to your database with either a Kinsta-hosted application or an external service.
We currently support different database types, for which you’re able to select the version that best suits your project needs. Specifically, you can host:
- MySQL
- MariaDB
- Redis
- PostgreSQL
And we’re working on adding more in the near future!
How To Deploy a Database at Kinsta
You can set up a new database and have it available in a matter of minutes. You won’t be required to manage servers, handle clusters and containers, or worry about other tasks for which DevOps is usually responsible.
Here’s the process:
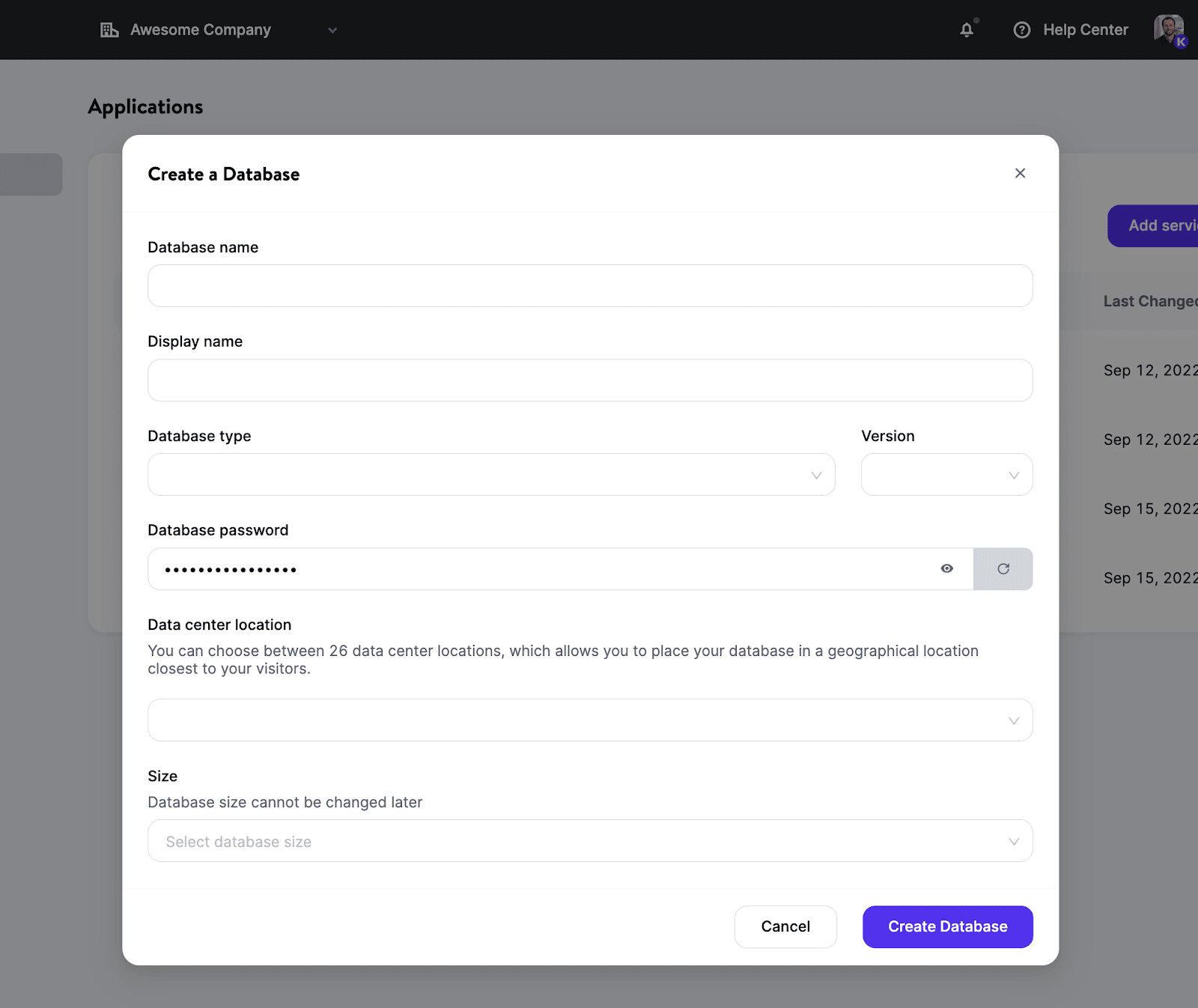
- Select the database type and the version you prefer.
- Pick a deployment location from the 24 data center locations currently available.
- Configure resources for your database.
Voilà: You now have a freshly created, containerized database (with no shared resources!) for your projects.
If you create an internal connection between your application and your database, they’ll both live in the same cluster and communicate over a secure connection, which provides better performance than external connections.
What’s more, you won’t be charged for internal traffic, as the requests remain within the same network!
For more information, be sure to read our documentation on Database Hosting.
Powerful Analytics to Monitor Your Database
Thanks to Database Analytics, you can get insights into your database’s usage data, including:
- Storage
- Runtime
- CPU usage
- Memory usage
What About Pricing?
As with Application Hosting, Database Hosting offers a per-usage billing system that charges you based on the size and runtime of your database.
Learn more about Database Hosting at Kinsta and deploy your first database to one of our 24 data center locations. Don’t forget: you get $20 off your first month.
What’s Next?
This is just the very beginning of Kinsta’s new era. Our development and engineering teams are working hard on new features, fixing bugs, and iterating by listening closely to the feedback you’ve been sharing.
Some of the new solutions we’re working on include static site hosting, machine learning, cloud applications, and Function-as-a-Service at the edge — to name just a few of the exciting things on our roadmap. On top of these, we’ll keep focusing on making our managed WordPress solutions even better and improving them with the release of features, such as edge caching, that cuts the time needed to serve cached WordPress HTML by an average of more than 50%!
These are great times to work as a developer, and we couldn’t be more excited about what’s coming down the road here at Kinsta!
Summary
By expanding Kinsta’s hosting solutions, we’re enriching the ways we support businesses and developers, regardless of the technology they work with. As the Chairman of Kinsta’s Board of Directors has summarized:
We’re building a platform where developers can find everything they need to run a web service with ease, so they can focus on creating and sharing their best work with the world.
To celebrate this new chapter in Kinsta’s history, everyone — new and existing customers — can try our Application Hosting and Database Hosting with $20 off your first month.
Welcome to the new Kinsta — the platform built for modern developers to turn ideas into live, scalable applications the way you’ve always imagined.
Simple, quick, with everything in one place.
Thanks to all our awesome customers for trusting us with your business and supporting us on this journey!

Head of Content at Kinsta and Content Marketing Consultant for WordPress plugin developers. Connect with Matteo on Twitter.

