
In today’s race to speed up website loading time, every millisecond matters. The team at Kinsta tested and studied the impact of website speed on sales, conversions, user experience, and user engagement.
But there’s a caveat. While on-site optimization is important for improved speed, it’s not the only aspect we should look at. The hardware and network infrastructure supporting our website and connecting it to our visitors also matter. A lot.
Today we’ll discuss why Google’s investing a lot of money into their networking infrastructure, and some of the differences in Google Cloud Platform’s premium tier network and standard tier network.
Bandwidth and Latency (Key Criteria for Hosting Infrastructure Performance)
Before diving into specifics about Google Cloud’s networking, it’s important to first understand the following two concepts: bandwidth and latency.
Bandwidth is the throughput capacity of the network, measured in Mbps; while latency is the delay or the sum of all delays that different routers along the way add to our web requests and responses.
Figuratively, bandwidth or throughput can be pictured as water hose capacity to allow a certain volume of water through per second. Latency can be compared to the delay from the moment the water pipe is opened until it starts gushing through.
Due to the small overhead in establishing the connection between different routers, each “hop” along the way adds a small amount of latency to the final requests and responses.
So, the farther the visitor and the server where the website is hosted are, the greater the latency will be. Also, the more fragmented the network, the bigger the latency.
We can picture this by using a tool called traceroute, or tracert on windows. In the next screenshots, we used it to inspect routing delays of two requests, made from Europe. Specifically:
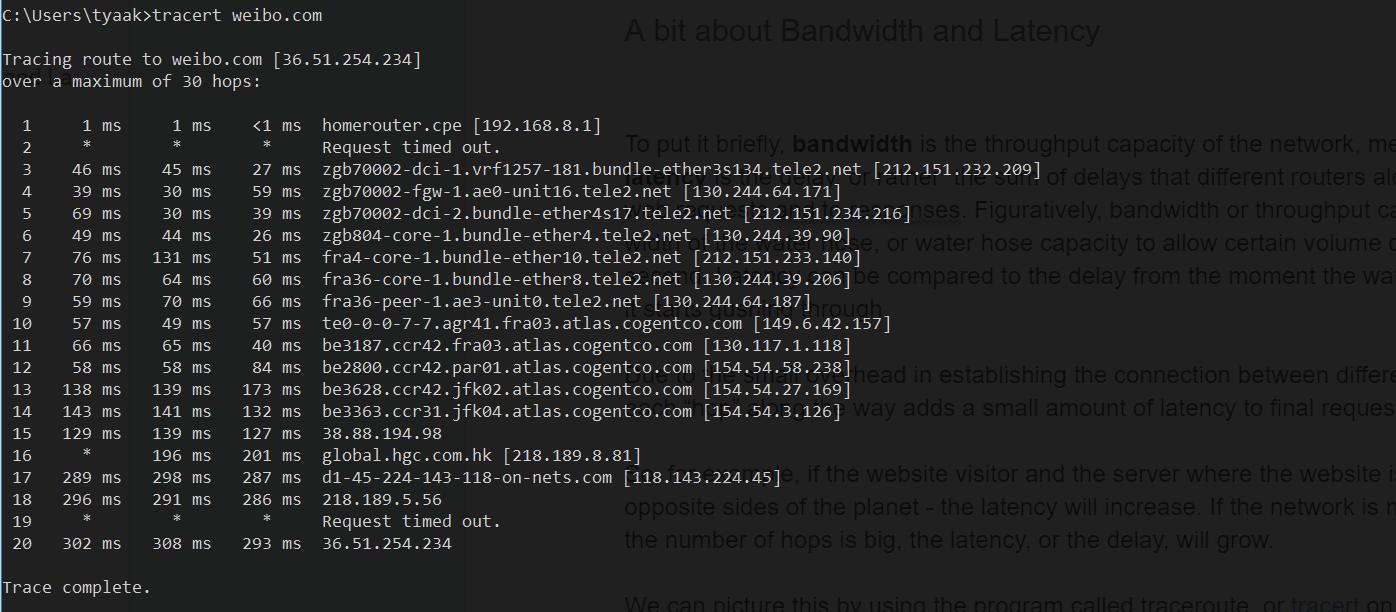
one to weibo.com:
and another to bbc.co.uk:
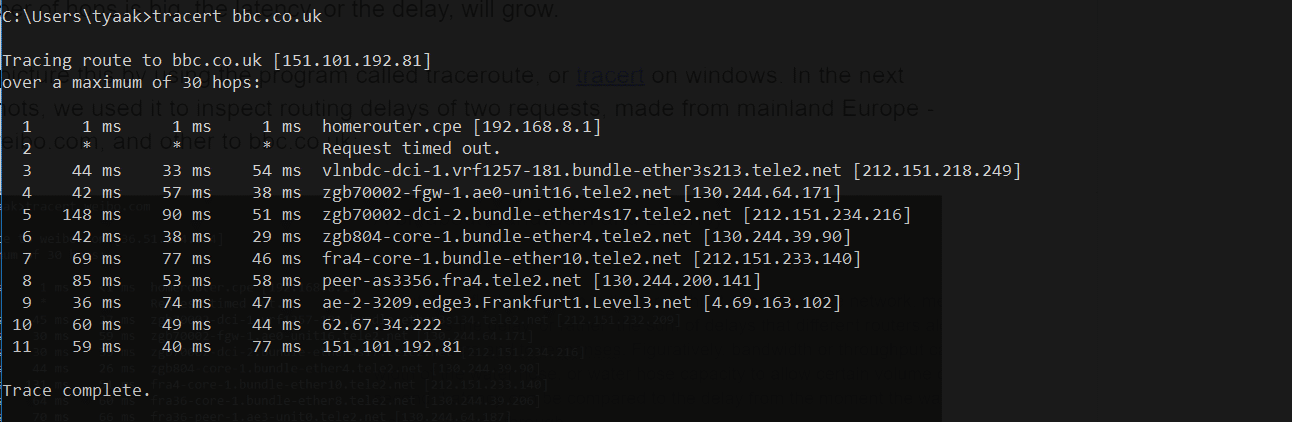
As we expected, the number of hops to the website in China is almost 2x bigger than to the European one. So it’s the added latency compared to a request to a website hosted in the United Kingdom.
The three columns that tracert shows represent three roundtrips (RTT). Each row represents different routers or hops along the way. They often have URLs that help us determine where that specific router is located.
The round-trip time to routers in China / Hong Kong takes close to one-third of a second.
We used pingdom tools to load a website hosted in London from Pingdom’s Australia location, to try to establish the share that the network has in the overall load times of a website.
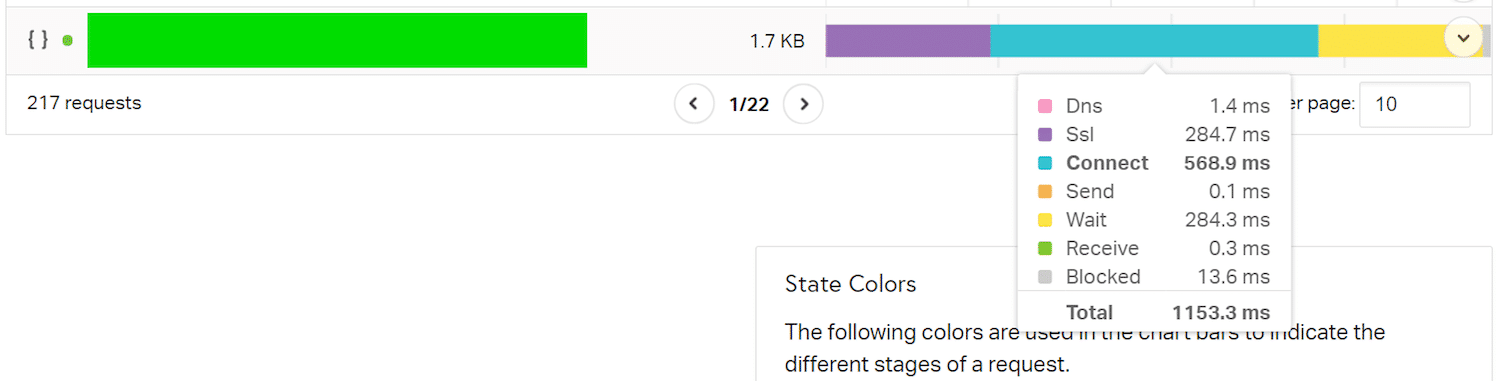
This is the data for a small CSS file loaded in this testing scenario. The Connect part has the highest share in loading this resource, followed by SSL and Wait. All the time up to, and including the Wait time, together, is also known as time to first byte (TTFB), which includes network latency.
When Internet Service Providers advertise the speed of the internet connection, they usually advertise on their bandwidth (the “width of the hose” remember?) which is really not a measure of speed. Increasing the width of the pipe can increase the website speed only to a certain degree. It is more useful when we need a big amount of data sent through per second, like when we stream high-definition video content. But for users who may be playing real-time multiplayer games online, latency will matter much more.
Mike Belshe, one of the coauthors of the HTTP/2 specification and the SPDY protocol, did an analysis of the impact of increased bandwidth on website loading speed vs the effect of decreasing latency on the website load speed.
Here are Belshe’s findings curated in a nice chart :
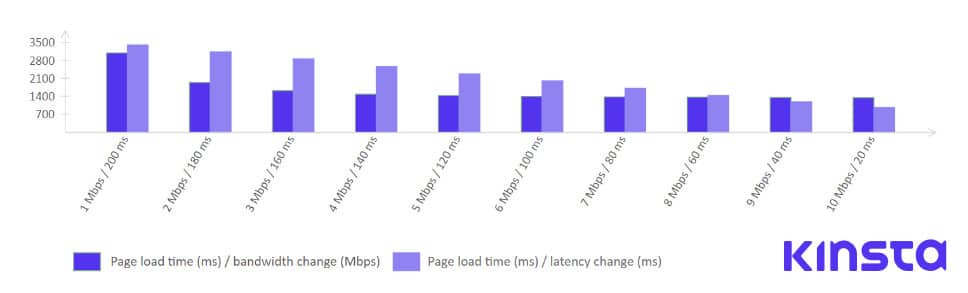
It’s should be clear that improving website speed by increasing bandwidth isn’t the most effective way to reach better performance. On the other hand, by reducing RTT (round-trip-time) or latency, we can see consistent improvements of the page load time.
Networks vs Internet Peering vs Transit
To understand our topic a bit better, we need to explain the basics of the internet topology. At its core, the global internet consists of multiple global, regional, and local networks.
As of 2018, there are more than 60,000 AS (Autonomous Systems). These networks belong to governments, universities, ISPs.
Among these, we distinguish Tier 1, Tier 2 and Tier 3 networks. These tiers represent the independence of each network on the internet as a whole.
- Tier 1 networks are independent, in the sense that they don’t have to pay to connect to any other point on the internet.
- Tier 2 networks have peering agreements with other ISPs, but they also pay for transit.
- Tier 3 networks, the lowest level, connect to the rest of the internet by buying transit from higher levels. They are virtually like consumers who have to pay to access the internet.
Peering relationship means that two networks exchange traffic on an equal basis, so that none of them pay the other for the transit, and return the same for free.
The main benefit of peering is drastically lower latency.
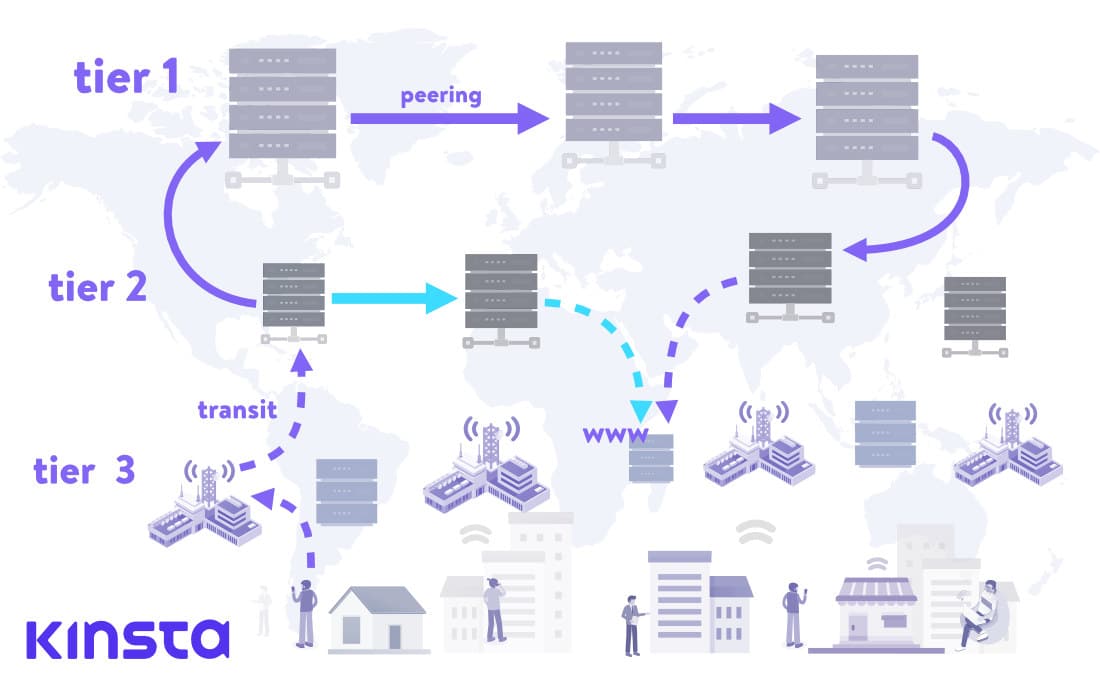
In the image above, we see a classic scenario, where the web request goes through the hierarchical network of ISPs on tier 1, tier 2, and tier 3 level in order to retrieve a website hosted in a data center in a remote location.
Arrows represent the web request journey. Dashed arrows represent the transit connections, and full-line arrows represent peering connections.
Once the tier 1 provider is reached, its relation to another provider on the same level is a peer relation. Tier 1 networks connect to others and relay their requests exclusively through peering partners. They can reach all other networks on the internet without paying for transit.
We can also see an alternate scenario, where two tier 2 providers have a peering agreement, designated with turquoise color. The number of hops in this scenario is lower and the website will take much less time to load.
Border Gateway Protocol
BGP is a protocol that is rarely talked about, except in very technical contexts. However, this protocol sits at the very core of the internet as we know it today. It is fundamental to our ability to access just about everything on the internet and it is one of the vulnerable links in the internet protocol stack.
Border Gateway Protocol is defined in IETFs Request For Comments #4271 from 2006 and has since had several updates. As the RFC says:
“The primary function of a BGP speaking system is to exchange network reachability information with other BGP systems.”
To put it simply, BGP is a protocol responsible for deciding the exact route of a network request, over hundreds and thousands of possible nodes to its destination.
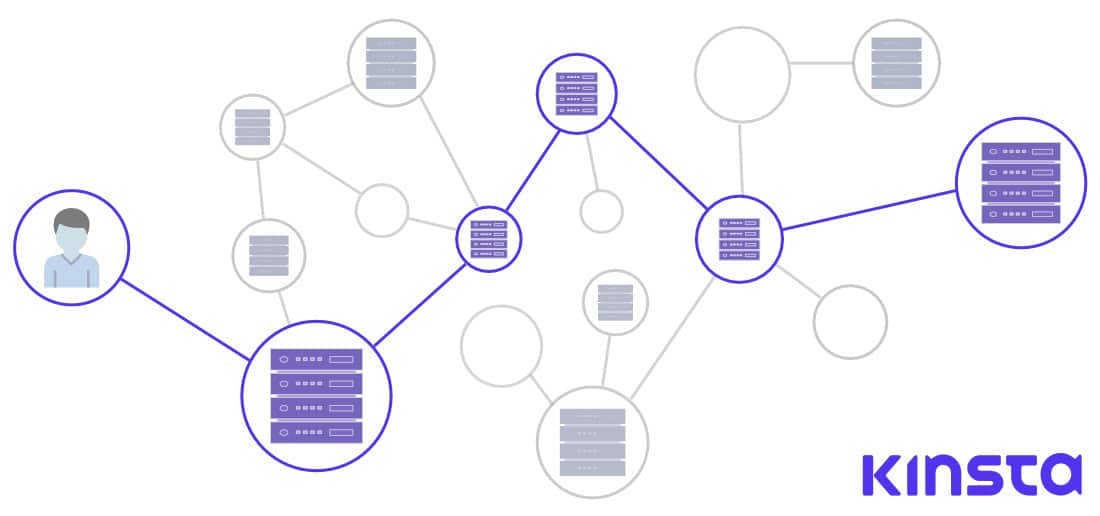
We can picture every node as an Autonomous System or a network that would consist of multiple nodes or routers, servers, and systems connected to it.
In BGP protocol, there is no auto-discovery algorithm (a mechanism or protocol by which every newly connected node can discover adjacent nodes to connect through), instead, every BGP peer has to have its peers specified manually. As for the path algorithm, to quote a Cisco expert:
“BGP does not have a simple metric to decide which path is the best. Instead, it advertises an extensive set of attributes with each route and uses a complex algorithm consisting of up to 13 steps to decide which path is the best.”
Autonomous Systems transmit routing data to their peers, however, there are no hard rules which would be enforced regarding the path selection. BGP is a system implicitly based on trust and this may be one of the greatest security flaws of today’s internet. Theft in 2018, when MyEtherWallet.com traffic was hijacked, and more than 200 Ether were stolen (value of $152,000) exposed this vulnerability.
In reality, this weakness of BGP more often results in various networks (AS) emitting BGP data with other interests in mind than the efficiency and speed for end users. These can be commercial interests, like paid transit, or even political or security considerations.
Development of Cloud Computing, CDN, and the Edge Market
Due to the growing needs of the IT market, from web industry, online gaming, to the Internet of Things and others, the market space for service providers and products that solve the latency problem became obvious.
Year after year we see more cloud-based products that cache static resources close to the visitors (Content Delivery Networks) or bring the actual computing closer to end-users. One such product is Cloudflare’s Workers, which executes V8 javascript engine-compatible code on Cloudflare’s network of edge nodes. This means that even WebAssembly or GO code can be executed very close to the visitor.
Lambda@Edge by Amazon is another example of this trend, as well as the Intel and Alibaba Cloud partnership to deliver Joint Edge Computing Platform targeting the IoT market.
Another one worth mentioning is Google’s global network of caching nodes serves both as a CDN and as a video caching & delivery network for its subsidiary YouTube.
To illustrate how refined and advanced the cloud industry has become, and how much it has managed to reduce the network latency for end-users, let’s have a look at GaaS.
GaaS is short for Gaming as a Service. It is a cloud offering that gives users the ability to play games hosted and executed in the cloud.
Everyone who has ever shopped for a TV or a video projector for gaming, or spent some time setting up Miracast or other casting connection between a TV and another device, will know just how critical the latency is. Yet, there are GaaS providers who now offer game streaming at 4k resolution and 60Hz refresh rate…and the players don’t have to invest in hardware.
The drama of the recent Huawei ban by the US brought to attention the issue of 5G networks and the urgent need for a clear path to upgrade the world’s networking infrastructure.
Sensors that relay huge amounts of information in real-time, with minimum latency, to coordinate smart cities, smart houses, autonomous vehicles will depend on dense networks of edge devices. Latency is the current ceiling for things like self-driving cars, with different sensors information, LIDAR data, processing of this data vs data of other vehicles.
Content Delivery Networks and Cloud Computing Providers are at the forefront of this race. We already talked about the QUIC / HTTP3 protocol being rolled out by the industry leaders able to control the request-response cycle.
How Do Cloud Providers Solve the Latency Problem?
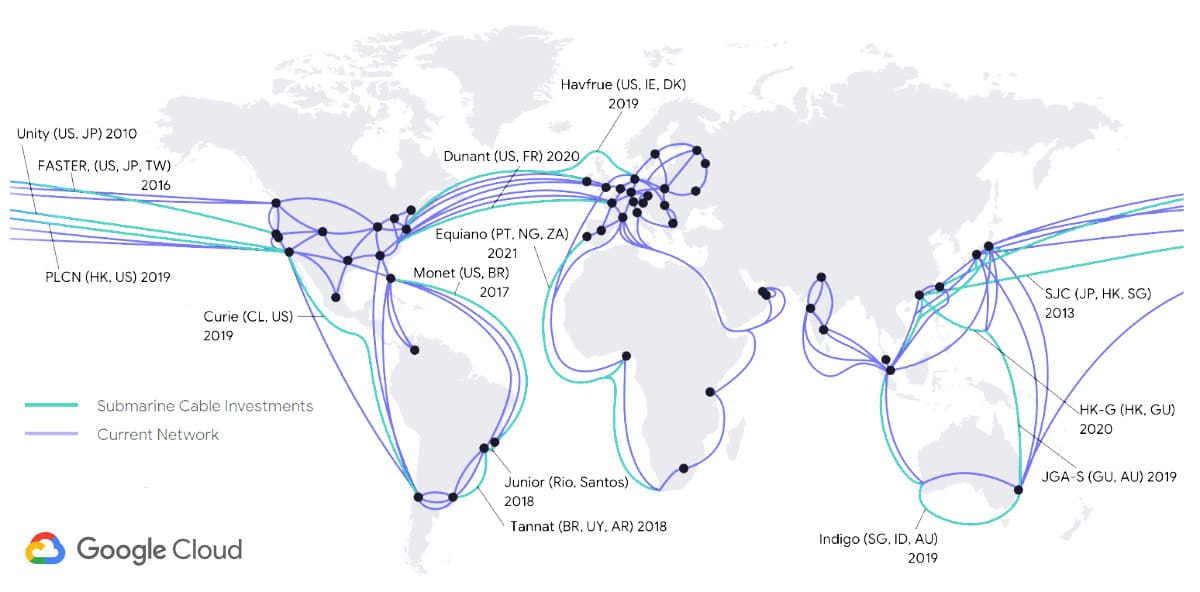
AWS may be the biggest cloud provider by market share. In 2016, they invested in Hawaiki Transpacific Submarine Cable System aiming at providing bigger bandwidth and decrease latency between Hawaii, Australia, and New Zealand, which was their first investment in submarine infrastructure. It went live in 2018.

By that time, Google was already way ahead of its competition in laying out submarine backbones. A year before Amazon’s first investment, ITWorld published an article titled: “Google’s data centers grow too fast for normal networks, so it builds its own”.
In fact, it was in 2005 that a tech journalist Mark Stephens, aka Robert X Cringely wrote in his column for PBS.org, commenting about Google’s shopping spree of the dark fiber (laid out but unused fiber-optic infrastructure):
“This is more than another Akamai or even an Akamai on steroids. This is a dynamically-driven, intelligent, thermonuclear Akamai with a dedicated back-channel and application-specific hardware. There will be the Internet, and then there will be the Google Internet, superimposed on top.”
In 2010, in an article on zdnet.com, Tom Foremski says:
“Google is one of those companies that own a large chunk of the Internet”, and continues: “Google has focused on building the most efficient, lowest cost to operate, private Internet. This infrastructure is key to Google, and it’s key to understanding Google.”
At that time, Cringley’s article raised some concerns about Google trying to take over the internet but things became clearer when the company launched Google Fiber, Google’s attempt to conquer the ISP market in the biggest US cities. The project has since slowed down, so much that TechRepublic published a post-mortem of the project in 2016, but investments in the infrastructure, now on a global scale, did not slow down.
Google’s latest investment, set to go live this year is a backbone connecting Los Angeles in the US and Valparaiso in Chile, with a branch for the future connection to Panama.
“The internet is commonly described as a cloud. In reality, it’s a series of wet, fragile tubes, and Google is about to own an alarming number of them.” — VentureBeat
Why Is Google Investing so Much into Its Network Infrastructure?
We all know that Google is the number one search engine, but it also:
- Owns the largest video platform
- Is the biggest email provider (Gmail and Google Workspace)
- Makes quite a bit of money on its cloud-computing products (annual run rate of over $8 billion dollars)
That’s why it needs the smallest possible latency and maximum bandwidth possible. Google also wants to own the actual infrastructure, because its “insatiable hunger” for more bandwidth and latency puts Google, and its peer large scale companies like Amazon or Microsoft, in a position where they need to come up with completely custom hardware and software solutions.
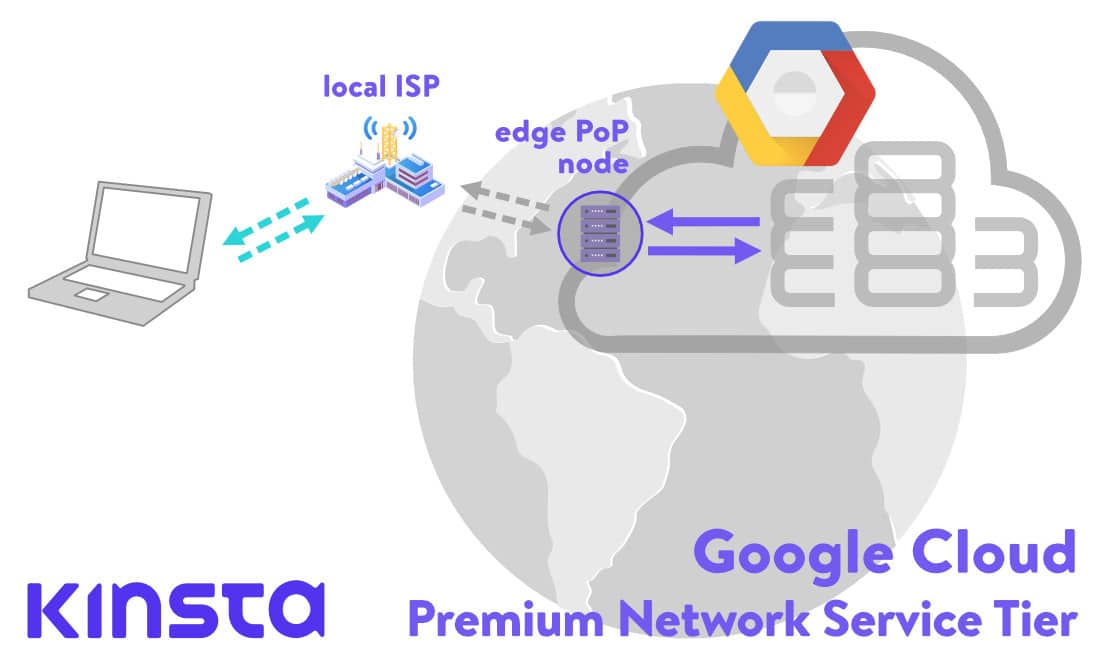
Points of Presence, or edge PoP nodes, are at the edges of Google’s global private cable network. There they serve as entry and exit points for traffic connecting to Google’s data centers.
Moore’s Law is an observation by Gordon Moore, co-founder of Intel, stating that every two years, the number of transistors we can put on an integrated circuit will double. For decades, this expectation held true, but now, the computing industry is about to put, Moore’s law to a hard test maybe signing its end in a close future. FYI, NVIDIA CEO proclaimed Moore’s law dead earlier this year.
So how does this relate to the cloud industry, and to Google’s network infrastructure?
At the Open Networking Foundation Connect Event on December 2018, Google’s Vice-President and TechLead for Networking, Amin Vahdat, admitted the ending of Moore’s law and explained the company’s conundrum:
“Our computing demand is continuing to grow at an astounding rate. We’re going to need accelerators and more tightly-coupled compute. The network fabric is going to play a critical role in tying those two together.”
One way for cloud providers to keep up with the increasing demand for computing power is clustering. Clustering, to put it simply, means putting together multiple computers to work on a single problem, to execute processes of a single application. Obviously, one precondition to benefit from such a setup is low latency or serious network capacity.
When Google started to design its own hardware, in 2004, network hardware vendors were thinking in terms of boxes, and routers and switches needed to be managed individually, via command line. Up until then, Google was buying clusters of switches from vendors like Cisco, spending a fortune per single switch. But the equipment still couldn’t keep up with the growth.
Google needed a different network architecture. Demand on Google’s infrastructure was growing exponentially (a research paper from Google from 2015 claims their network capacity grew 100x in ten years) and their growth was so rapid that the cost of buying the existing hardware also prodded them to create their own solutions. Google started building custom switches from commodity silicon chips, adopting a different network topology which was more modular.
Google’s engineers started to build on an old telephony network model called Clos Network, which reduces the number of ports required per switch:
“The advantage of the Clos network is you can use a set of identical and inexpensive devices to create the tree and gain high performance and resilience that would otherwise cost must more to construct.” — Clos Networks: What’s Old Is New Again, Network World
For this new, modular hardware, Google’s team had also to redefine existing protocols and build a custom Network Operating System. The challenge they were facing was to take vast numbers of switches and routers and operate them as if they were a single system.
The custom networking stack along with the need for redefined protocols led Google to turn to Software Defined Networking (SDN). Here’s a keynote by Amin Vahdat, Google Vice President, Engineering Fellow, and network infrastructure team lead, from 2015, explaining all the challenges and the solutions they came up with:
For the most curious ones, there is this interesting blog post worth reading.
Espresso
Espresso is the latest pillar of Google’s SDN. It allows Google’s network to go beyond the constraints of physical routers in learning and coordinating the traffic coming in and going out to Google’s peering partners.
Espresso enables Google to measure connections’ performance in real-time, and base the decision on the best Point of Presence for a specific visitor on real-time data. This way, Google’s network can respond dynamically to different congestions, slowdowns, or outages in it’s peering / ISP partners.
On top of that, Espresso makes it possible to utilize Google’s distributed computing power to analyze all of its peers’ network data. All the routing control and logic no longer resides with individual routers and Border Gateway Protocol but is instead transferred to Google’s computing network.
“We leverage our large-scale computing infrastructure and signals from the application itself to learn how individual flows are performing, as determined by the end user’s perception of quality.” — Espresso makes Google Cloud faster, 2017
How Is Any of This Relevant to Google Cloud Network?
What we covered so far goes to highlight all the issues and challenges (both hardware- and software-based) Google went through to assemble what is probably the best global private network today available.
When it comes to market share, Google Cloud Platform is the third global vendor (behind AWS market share and Microsoft’s Azure market share). But in terms of its premium private network infrastructure, it leaves its competitors far behind as this data from BroadBand Now shows:
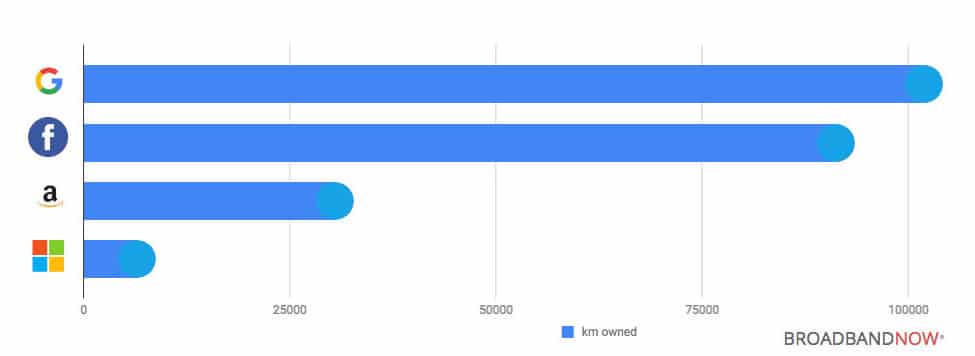
In 2014, GigaOM published an article comparing AWS and Google Cloud Platform but just one week later, they published another one titled: “What I missed in the Google vs. Amazon cloud debate — fiber!” where they recognize that Google is years ahead in terms of infrastructure.
“Having big, fast pipes available to your — and your customers’ traffic — is a huge deal.” — Barb Darrow, GIGAOM
Google’s Premium vs Standard Tier Networks
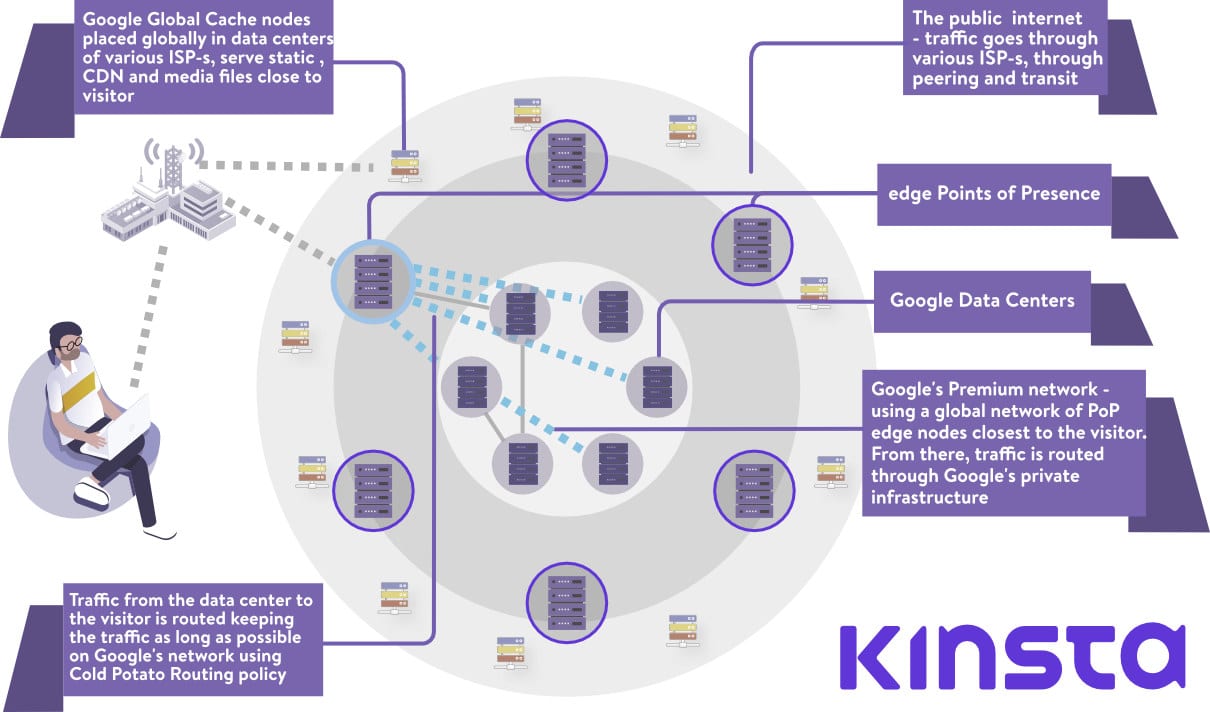
Google Cloud Platform offers two different network tiers which differ both on price and performance.
Google Premium Tier Network
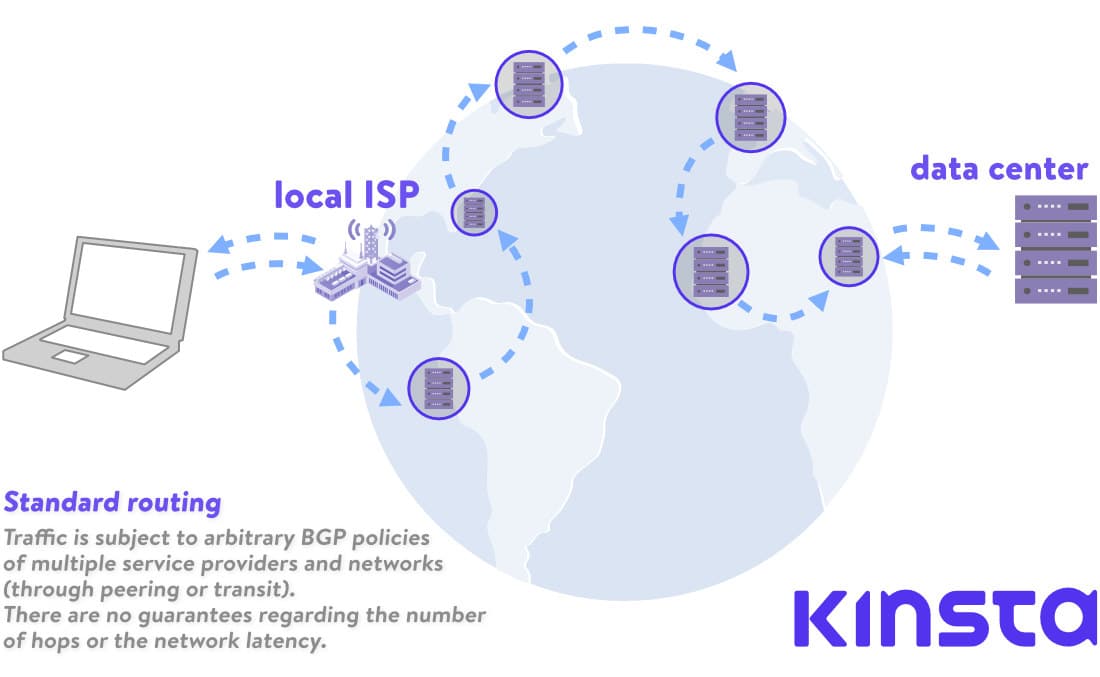
With Google’s Premium Tier Network, users can take advantage of the global fiber network, with globally distributed Points of Presence. All the ingress (inbound) traffic from the customer to Google’s data centers gets routed to the nearest Point of Presence, which are distributed globally, and then the request is routed 100% over Google’s private backbone. As we mentioned in an earlier article – that can mean 30% improved latency or 50% better bandwidth.
On the way back, all the data sent from the data-center to the visitor is routed using Cold Potato policy. As opposed to the Hot Potato routing, used on the Standard Tier network, where the traffic is, as early as possible, handed (or dropped) over to other ISP-s, Premium Tier routing means that the egress traffic is kept as long as possible on Google’s own fiber, and is given over to peers or transit ISP-s as close to the visitor as possible.
To put it in layman’s terms. Premium tier packets spend more time on Google’s network, with less bouncing around, and thus perform better (but cost more).
For the sci-fi fans among us, it could be compared to a cosmic wormhole, which transfers our traffic directly to our destination without roaming through the internet.
At Kinsta, we utilize Google Cloud’s Premium Tier Network with all of our hosting plans. This minimizes distance and hops, resulting in faster, more secure global transport of your data.
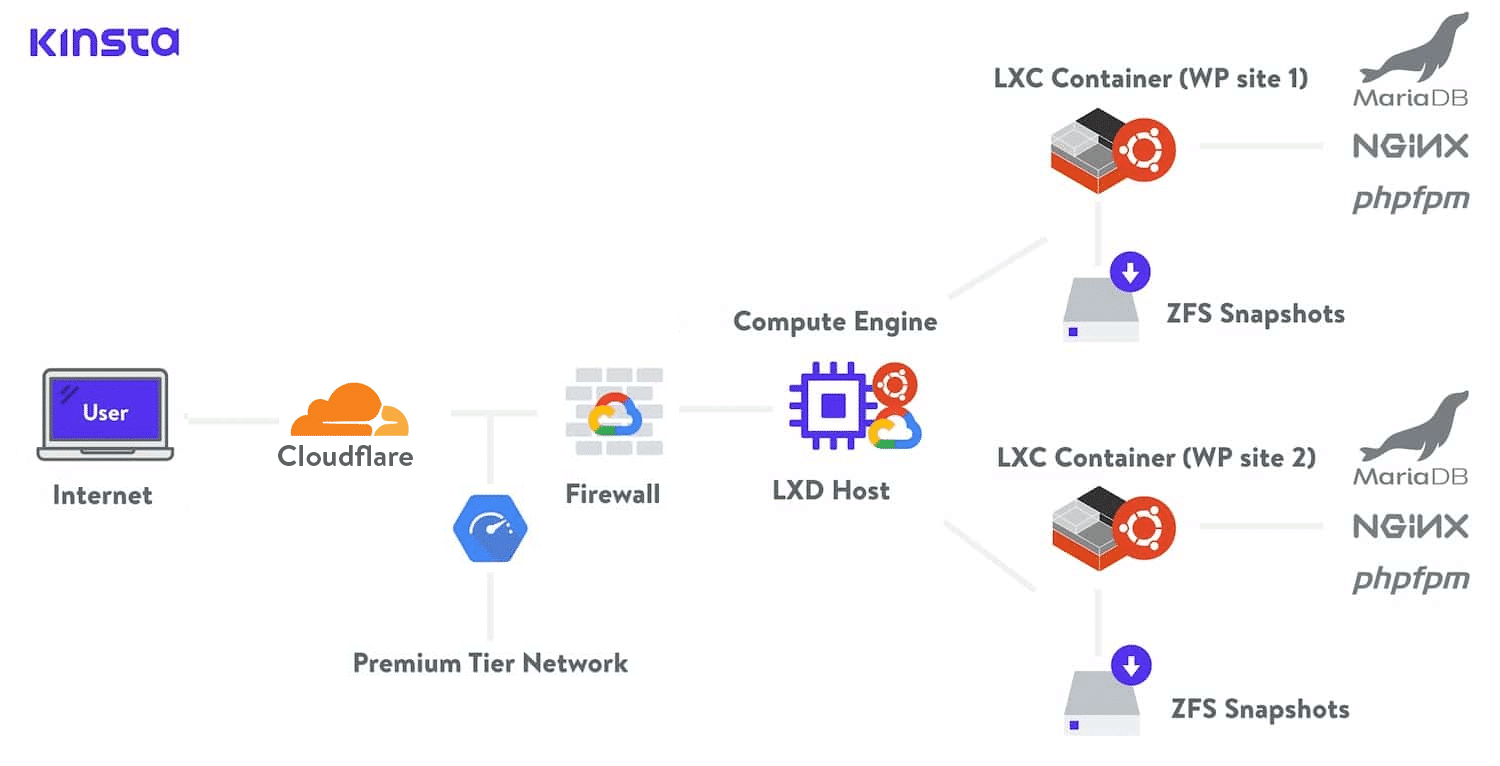
Google Standard Tier Network
On the other hand, Standard Tier Network uses Points of Presence near the data center where our content or web app resides. This means that our visitors’ traffic will travel through many different networks, Autonomous Systems, ISPs, and through many hops until it reaches its destination. In this scenario, speed is compromised.
Content traveling on Standard Tier will not be able to fully reap the benefits of Google’s SDN and the vast computing power to calculate the best routes dynamically. Traffic will be subject to BGP policies of all the systems in between Google and the visitor.
To put it in layman’s terms. Standard tier packets spend less time on Google’s network, and more time playing hot potato on public networks, and thus, perform worse (but cost less).
In addition, Premium Tier uses Global Load Balancing, while the Standard Tier offers only Regional Load Balancing, which brings more complexity, and more “footwork” for clients on Standard.
Premium Tier Network offers a global Service Level Agreement (SLA), which means that Google accepts contractual responsibility to deliver a certain level of service. It’s like a quality guarantee sign. Standard Network Tiers do not offer this level of SLA.
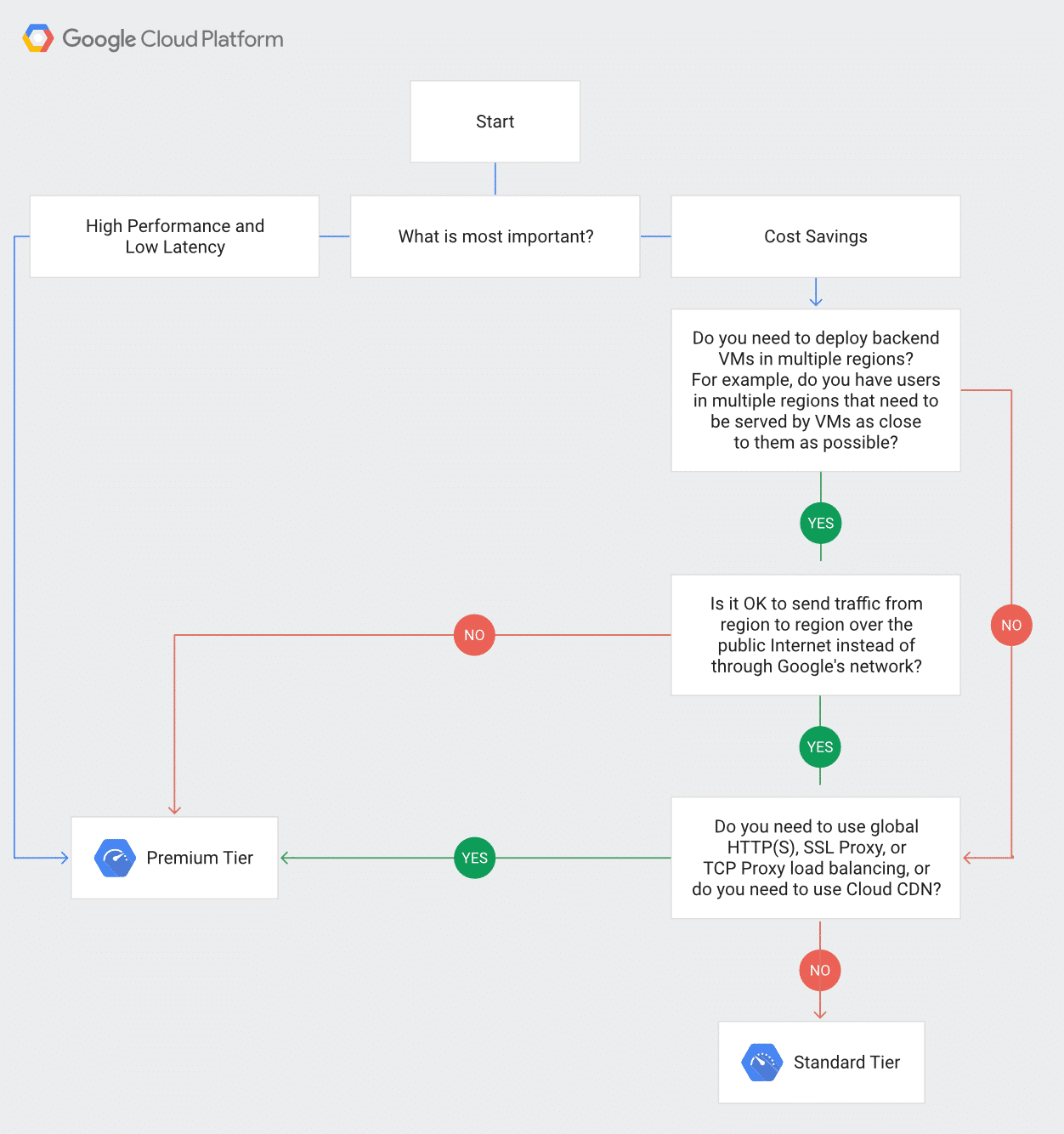
For those wanting to find out more, there is quite an extensive comparison and documentation of the two tiers on Google Cloud website. They even provide a handy chart to help you more easily determine which network tier you should be using:
Summary
For years, Google has invested in creating a global networking infrastructure, deploying its own protocols and custom hardware and software networking stacks. In times when Moore’s law seems to become weaker year after year, Google’s infrastructure enables the company to keep up with the ever-growing demand for cloud resources.
Although in terms of market share it is still behind Amazon Cloud and Microsoft’s Azure Cloud, Google has gained some crucial advantage for both the fiber it owns, as well as in the cutting-edge hardware and software solutions its engineers deployed.
We can expect Google to play a key role in the technology of IoT, smart cities, driverless cars, and the demand on edge computing continues to grow.
Google Cloud Network Premium Tier is the first product to make use of Google’s innovative networking achievements. It allows clients to take advantage of Google’s network and the entire stack for delivering content at premium speed. With Google’s guarantees regarding latency.
Kinsta is dedicated to providing the best Application Hosting, Database Hosting, and Managed WordPress Hosting performance on a global scale. That’s why Kinsta is powered with Google Cloud hosting and we use Google’s Premium Tier Network for all our hosting plans.

Tonino is an entrepreneur, Linux & OSS enthusiast, developer, and tech educator. He has over ten years of experience in development and has been in the blockchain space for 3+ years. When he's not coding, he writes for SitePoint and Alibaba Cloud, binge-watches the newest works of fiction on Netflix, and explores new travel destinations.

