
When starting a new project, one of the things developers can struggle with is choosing a stack. Zeroing in on the right technology to solve a problem can be a nerve-wracking experience. Databases in particular can be challenging to settle on, especially if you’re unclear about how your data will be used.
Since databases are a basic foundation of software development and they serve various purposes for building projects of all types and sizes, it helps to understand the importance of databases to choose an appropriate database structure for your stack.
This article will help you pick the right open-source database by exploring the differences between two great database management systems: MongoDB and PostgreSQL.
What Is MongoDB?
MongoDB is a cross-platform, open-source non-relational database released on February 11, 2009. It’s known for using JSON-like documents with optional schemas.
MongoDB is considered one of the market’s most advanced cloud database services with unparalleled data mobility and distribution across Azure, AWS, and Google Cloud, built-in automation for workload and resource optimization.
It also allows you to create a cloud database in minutes using the Atlas CLI, UI, or an infrastructure-as-a-service (IaaS) resource provider.
With MongoDB Atlas, you can keep your application running to keep up with your surging traffic as new features make their way into your pipeline. MongoDB Atlas provides its users with advanced database optimization tools so that you always possess the database resources you need to keep building.
Main Features
Here are a few key features of MongoDB that earn it a spot among the best non-relational databases in the market:
- Performance advice: As your applications evolve, MongoDB assists you with the best on-demand schema design practices for peak efficiency.
- Multi-cloud clusters: With MongoDB, you can enable resilient and powerful applications that leverage two or more clouds at the same time.
- Load balancing: MongoDB facilitates control concurrency to take care of multiple client requests in parallel to other servers. This can help decrease the load on every server while ensuring data consistency and uptime and allows for scalable applications.
Use Cases
MongoDB is wielded by thousands of organizations worldwide for data storage needs or as their applications’ database service.
MongoDB plays a pivotal role in:
- Content management: With MongoDB, you can serve and store any type of content, construct any feature, and weave in any kind of data within a single database. MongoDB sets you up for success with commodity hardware and more productive teams to make your project cost 10% of what they should while offering all the features needed to build content-rich apps.
- Payments: If you’re developing a new payments product, MongoDB’s data agility will allow that new product to reach the market quickly, without you having to worry about unnecessary complexity like data fragmentation. Even if you’re leading a mature enterprise trying to modernize its payment ecosystem, you can leverage MongoDB’s flexibility to use it as a consolidated operational data layer, allowing you to build new products and services using existing data without a risky cookie-cutter solution.
- Personalization: MongoDB allows you to personalize the experiences of millions of customers in real-time, with features such as targeted offers, customized home pages, and social media network sign-on. You can even run complex queries directly against your data without worrying about transforming, extracting, and loading.
- Mainframe offloading: You can easily move workloads off the mainframe with MongoDB. Mainframe offloading is the process of replicating commonly accessed mainframe data to an operational data layer (ODL) built on MongoDB, against which operations can be redirected from consuming applications.
What Is PostgreSQL?
Despite the popularity of NoSQL databases, relational databases continue to be relevant for various applications because of their robustness and strong querying abilities.
Relational databases are great at running complex queries and data-based reporting in cases where the data structure doesn’t change frequently. Open-source databases like PostgreSQL offer a cost-effective alternative as a stable production-grade database compared to its licensed contemporaries like SQL Server and Oracle.
PostgreSQL is a highly stable database management system, backed by over 20 years of community development that has led to its high levels of integrity, resilience, and correctness. You can use PostgreSQL as the primary data warehouse or data source for various mobile, geospatial, analytics, and web applications.
PostgreSQL also carries no licensing cost, eliminating the risk of over-deployment. Its dedicated group of enthusiasts and contributors regularly find bugs and solutions, chipping in for the overall security of the database system.
Main Features
Here are a few salient features of PostgreSQL that make it one of the most widely used databases today:
- Non-atomic columns: One of the primary constraints of a relational model is that columns need to be atomic. PostgreSQL, however, doesn’t have this constraint and allows columns to have sub-values that queries can easily access.
- Support for JSON data: The ability to query and store JSON allows PostgreSQL to run NoSQL workloads as well — say, if you’re designing a database to store data from multiple sensors and you’re not sure about the specific columns that you will need to support all kinds of sensors. In this scenario, you can construct a table such that one of the columns is JSON to store the continually changing or unstructured data.
- Window functions: PostgreSQL window functions play an integral role in making them a favorite for analytics applications. With Window functions, you can execute functions spanning over multiple rows and return the same number of rows. Window functions differ from aggregate functions in the sense that aggregate functions only can return a single row after aggregation.
Use Cases
Here are a few use cases where PostgreSQL comes in handy:
- Federated hub database: PostgreSQL’s JSON support and foreign data wrappers allow it to connect with other data stores — including NoSQL types — and serve as a federated hub for polyglot database systems.
- Scientific data: Scientific and research projects can generate terabytes of data, which have to be managed most efficiently and beneficially. PostgreSQL offers a wonderful SQL engine with robust analytical capabilities, which makes processing large amounts of data a piece of cake.
- Manufacturing: Various world-class industrial manufacturers leverage PostgreSQL to speed up innovation and propel growth through customer-centric processes while optimizing supply chain performance by using PostgreSQL as a storage backend.
- LAPP open-source stack: PostgreSQL can run dynamic apps and websites as part of a robust alternative to the LAMP stack. LAPP stands for Linux, Apache, PostgreSQL, Python, PHP, and Perl.
MongoDB vs PostgreSQL: Head-to-Head Comparison
The real question isn’t MongoDB vs PostgreSQL, but rather the best document database vs the best relational database.
Quite often, at the beginning of a development project, project leaders have a good grasp of the use case but don’t have clarity regarding the specific application features their users and business would need. They end up having to bet on a choice and hope that it’s the best fit.
In the next section, we’ll elucidate the differences between MongoDB and PostgreSQL to help you make that decision easily. Our information is based on key factors like architecture, ACID compliance, extensibility, replication, security, and support to name a few.
Let’s dive in!
ACID Compliance
One of the most pivotal features of relational databases that make writing applications simpler is ACID transactions. As far as the isolation levels within database transactions are concerned, PostgreSQL uses the read committed isolation level, by default. It also allows users to tune the read committed isolation level up to the serializable isolation level.
The important thing to note here is that transactions allow various changes to a database to either be made or rolled back in a group. Therefore, in a relational database, the data would be modeled across independent parent-child tables in a tabular schema.
Comparatively, document databases have an easier time executing transactions because they collate data in a document and since reading and writing is an atomic operation, it doesn’t need a multi-document transaction.
MongoDB supports complete isolation while a document is being updated. Any errors would trigger the update operation to roll back, reversing the change and ensuring that the clients get a consistent view of the document.
MongoDB also supports database transactions across multiple documents allowing bits of related changes to be rolled back or committed as a group. Owing to its multi-document transactions capability, MongoDB is one of the few databases to coalesce the flexibility, speed, and power of the document model with the ACID guarantees of traditional databases.
Architecture/Document Model
MongoDB’s document model allows a user to naturally map to objects within application code, making it easier for full-stack developers to learn and use. Documents provide you with the ability to depict hierarchical relationships to store arrays and other more sophisticated structures easily.
By storing data in fields such as nested subdocuments and arrays, related information in JSON documents can be stored together for quick query access through the MongoDB query language.
With MongoDB, you can store data as documents in a binary representation known as binary JSON (BSON). Fields can differ based on the document it is catering to, therefore, there’s no need to declare the structure of documents to the system — documents are self-describing.
If you need to add a new field to a document, then the field can be generated without impacting other documents in the collection or updating an ORM or a central system catalog.
MongoDB also provides you with the option of schema validation to enforce data governance controls over every collection. This flexibility comes in handy when collating information from multiple disparate sources or accommodating modifications in documents over time, especially as the new application functionality is consistently deployed.
PostgreSQL houses a client-server model of architecture that consists of the following two processes:
- Client-side process: These are the applications leveraged by users to interact with the database. Usually, it has a simple user interface and is used to communicate between the user and the database through APIs.
- Server-side process: This is the “Postgres” application that tackles operations, connections, dynamic, and static assets. A running PostgreSQL site is handled by a Postmaster, a central coordinating process. The postmaster daemon is responsible for:
- Performing recovery
- Initializing the server
- Shutting down the server
- Running background processes
- Managing connection requests from new clients
.
Extensibility
Extensibility is simply the quality of being designed to allow the addition of new capabilities or functionalities.
PostgreSQL supports extensibility in several ways, including stored functions and procedures. What makes PostgreSQL extensive is its catalog-driven operations.
Relational databases often store information about tables, databases, columns, etc. in system catalogs. These “data dictionaries” appear to the user as tables, but they do have information stored internally by the database system.
PostgreSQL stores the information about the columns, and tables, along with information regarding the data types, functions, and access methods present.
There’s more: PostgreSQL can also incorporate user-written code into itself via dynamic loading. Often, users may require certain functionality that can be implemented via shared libraries. Users can simply specify the code file and PostgreSQL will load it as required, thus making it uniquely suited for rapid prototyping of new applications.
On the other hand, MongoDB has eventually become extensible allowing users to create their functions and use them within the framework. It’s equivalent to user-defined functions (UDF) which allow users of relational databases (like PostgreSQL) to extend SQL statements.
Moreover, both PostgreSQL and MongoDB support several extensions and plugins like Adminer for database management.
Collaboration and Agility
MongoDB has a document model, making collaboration and development easier and faster to implement. MongoDB essentially uses JSON or BSON to store its data as documents.
BSON includes several data types not present in JSON data such as DateTime, long, int, and byte array that help handle data more efficiently as it would be more specific according to the data type instead of handling everything like a universal “number” type. It makes queries execute faster as it’s in a serialization format that effectively archives JSON-like documents.
BSON skips the keys that aren’t useful for the query, thus making it faster to retrieve data. A user could further define the document’s structure and undertake some development by introducing new fields, reworking data, or developing it whenever they see fit.
This flexibility is a huge advantage for MongoDB as it helps avoid delays caused by asking the administrator to restructure the data definition language statements and then starting from scratch by recreating or reloading a database.
MongoDB also makes it easy to collaborate between developers or teams, therefore, there’s no need for intermediation or complicated communication between teams.
When it comes to collaboration, PostgreSQL includes user-level privileges, role inheritance, and table-level privileges. You can manage users and grant them read and write privileges.
Furthermore, you can also review various groups or users’ data access activities with the auditing option which grants an extra layer of security. However, PostgreSQL is not as fast as MongoDB, as it’s a relational database that stores data in rows and columns.
Foreign Key Support
A key feature that sets MongoDB apart from PostgreSQL is its approach to storing its data.
Since it’s non-relational, MongoDB uses collections instead of tables. A foreign key is simply a set of attributes in a table that refers to the primary key of another table. The foreign key links these two tables to each other.
Since there are no tables in MongoDB, there are no foreign keys in MongoDB either; hence no foreign key constraints. However, MongoDB does have a DBRef standard which helps standardize the creation of the references.
On the other hand, PostgreSQL supports foreign keys as it’s SQL-compliant. By enabling foreign key constraints, PostgreSQL can stop the insertion of invalid data into foreign key columns.
Partitioning and Sharding
Partitioning and sharding are essentially about breaking up large datasets into smaller subsets. Sharding implies that the data is stored across multiple computers while partitioning groups this data within a single database instance.
MongoDB is scalable because of partitioning data across instances within the cluster. It doesn’t split the documents into pieces as they are independent units making it easier to distribute them across various servers while data is locally preserved.
Data can be distributed across different regions with ease via the MongoDB Atlas cloud service. You can also choose to constantly store them in specific regions or global regions to ensure reduced latency.
Since version 5.0, MongoDB has included a “live” resharding feature that comes as a major time-saver since you only need to set a policy. The database can automatically redistribute the data when the time comes.
Previously, you could do so without taking the system down, but the process was complicated and risky. While MongoDB did have global geo-partitioning for some time, data was growing in different countries at different rates. Live resharding could be beneficial for data that must stay local within a country.
On the other hand, PostgreSQL supports declarative partitioning, which is essentially a way to specify how to divide a table into partitions. The table that is divided is called the partitioned table, the specification consists of the partitioning method, and the list of columns or expressions to be used is called the partition key.
You can implement partitioning via a range, where the table can be partitioned by ranges defined by a key column or set of columns, with no overlap between the ranges of values assigned to different partitions.
You can also implement list partitioning where the table is partitioned according to the key values specified.
Replication
Replication is the process of creating a copy of the same dataset on more than one server. It enables database administrators to provide high data redundancy and high availability of data.
For MongoDB, this is achieved by using a “replica set” — a synchronized cluster consisting of three or more servers that keep replicating data between them. This provides redundancy and protection against any downtime that might occur in the event of a scheduled break for maintenance or a system failure, thus increasing the fault tolerance of the database.
Replica sets can be implemented across various data centers too, as they would come in handy in case of regional outages. This can be done by MongoDB Atlas, which makes building and configuring these clusters simpler and quicker.
PostgreSQL offers primary-secondary replication. Write-ahead logs enable sharing the changes made with the replica nodes, hence making asynchronous replication possible. Other kinds of replications include logical replication, streaming replication, and physical replication.
Indexes
Indexes are objects or structures that allow us to retrieve specific rows or data faster.
PostgreSQL delivers a range of unique index types to match any query workload efficiently. Its indexing techniques include B-tree, multicolumn, and expressions. Furthermore, partial and advanced indexing techniques such as GiST, KNN Gist, SP-Gist, GIN, BRIN, covering indexes, and bloom filters can also be implemented in PostgreSQL.
On the other hand, MongoDB allows you to store data in any structure that can be quickly accessed by indexing, no matter how deeply nested in arrays or subdocuments.
Language & Syntax
Both MongoDB and PostgreSQL support a variety of languages.
MongoDB provides driver support for some of the best database languages like Python, R, Java, Scala, C, C++, C#, Node.js, and many more. These MongoDB libraries and drivers support all of MongoDB’s features, giving high performance and scalability in all applications.
PostgreSQL supports several procedural languages with a base distribution like PL/pgSQL, PL/Python, PL/Perl, and PL/Tcl along with other languages developed and maintained outside the core PostgreSQL distribution like PL/Java, PL/PHP, and PL/Ruby.
Normalization
Normalization is the process of structuring a relational database to reduce data redundancy, minimize anomalies in data modification, and improve data integrity.
MongoDB can deal with both normalized and denormalized data models (also known as embedded models).
Embedded models allow applications to store related pieces of information in the same database record which would provide better performance for read operations and the ability to retrieve related data in a single database operation.
Furthermore, you can also update related data in a single atomic write operation while applications issue fewer queries to complete common operations. Documents in MongoDB for the embedded data model must be smaller than the maximum BSON document size (16 MB).
Normalized data models describe relationships using references between documents. This would be beneficial to use when embedding may result in data duplication but insufficient read performance advantages outweigh the implications of the duplications.
However, the denormalization process usually causes high memory consumption when previously normalized data in a database is grouped to increase performance.
PostgreSQL schemas have an identified relationship. The structure can be identified with a 1:1, 1:many, or many:1 relationship. The normalization of data could be very beneficial as it removes redundant copies of data, thus also ensuring integrity.
Performance
Assessing the performance of two different database systems is challenging since both MongoDB and PostgreSQL have different ways of storing and retrieving the data.
MongoDB was built to scale out horizontally, as it often combines its power with additional machines and doesn’t rely on processing power. It’s capable of powering massive applications regardless of it being measured by data sizes or users.
MongoDB can also accommodate use cases that require the fast execution of queries and can handle a large amount of data. It could incorporate hundreds of machines overall.
Since MongoDB 4.4, queries implemented against replica sets produce improved and predictable performance through “hedged” reads. These reads are directed to multiple nodes within the replica set until the fastest node replies.
PostgreSQL, while not as fast as MongoDB in terms of its raw insertion speed, excels in terms of ACID compliance. Transactions are processed safely and reliably, allowing an entire transaction to fail instead of executing a write that partially succeeded.
MongoDB has only recently (with version 4) started to support ACID transactions similar to SQL databases.
Unlike MongoDB, PostgreSQL depends on a scale-up strategy (vertical scaling) for data volumes and scaling writes. It’s performed by adding more hardware resources like disks, CPUs, and memory to an existing database node.
However, PostgreSQL has made some efforts towards performance optimizations, including a mature query planner, just-in-time (JIT) compilation of expressions, table partitioning, and parallelization of read queries.
Price
PostgreSQL is completely free of cost and open-source. Hence anyone can use its features and make modifications to the code with ease when necessary.
MongoDB is also an open-source tool. However, MongoDB does have other options like the enterprise and Atlas (for the cloud), which have varying prices. An on-premise pricing model is offered for the MongoDB enterprise edition.
Mongo RealmDB is available free of charge to all Atlas users for evaluation and light usage, enabling developers to build and release mobile applications.
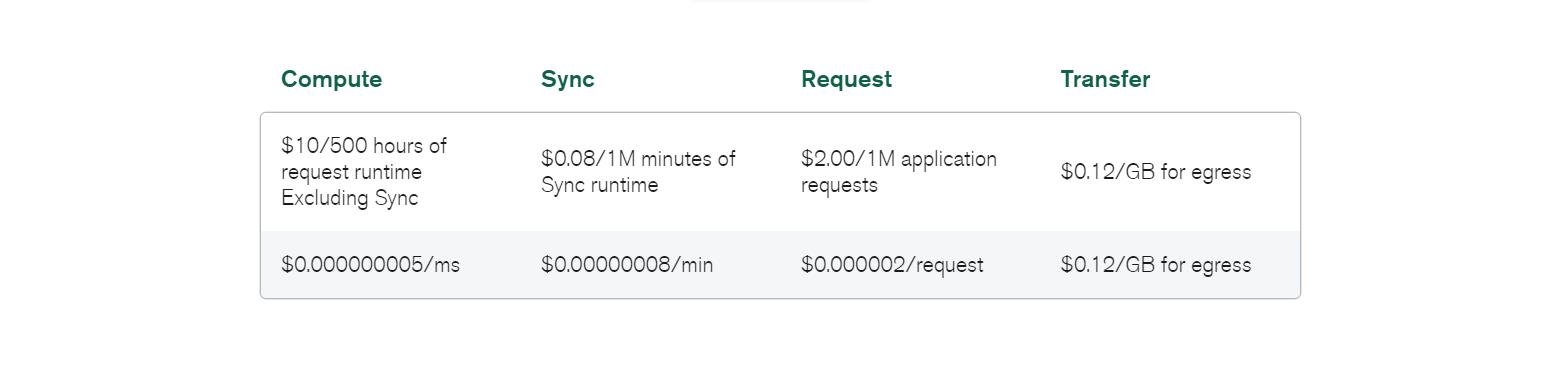
Data migration may also generate overhead; however, this is standard irrespective of the database you have implemented in your system.
Query Processing
PostgreSQL uses the relational database model that depends on storing data within tables and utilizing the structured query language (SQL) for database access. SQL commands can be entered using the PostgreSQL terminal psql. It has a large object facility, which provides stream-style access to user data that is stored in a special large-object structure.
Before adding the data, the database schema must be built to get a clear understanding of the data relationships to process the queries. Related information can be stored in separate tables in the database. This can be accessed via foreign keys and joins.
It can be difficult to adjust the structure of the database once it’s loaded. It needs several teams in development, ops, and the database administrator to coordinate the changes made in the structure carefully.
On the other hand, the data structure of MongoDB doesn’t need to be planned out in advance as it essentially deals with unstructured data. The data structure is also far easier to adjust.
Developers can choose what’s essential in the application and make the changes required. MongoDB uses MQL, which can be used to work with documents in MongoDB and take out data while delivering the flexibility and power that SQL does.
MongoDB processes data as JSON documents. You can query for the fields inside the JSON document as well. Thus, MongoDB is quite useful in cases where you want to store documents within a flexible data field.
While PostgreSQL uses the GROUP_BY function to process and run aggregate queries MongoDB typically uses aggregation pipelines to process its queries.
One major drawback of MongoDB, however, is that you can’t easily join tables. In PostgreSQL, it’s made simple with a JOIN statement.
MongoDB has tried to solve this by introducing multi-dimensional data types where you can embed one document store inside another. However, it’s disorganized and not as elegant as the simple join function that PostgreSQL incorporates.
Security
When it comes to security, PostgreSQL trumps MongoDB. The tight rules governing the structure of the database allow PostgreSQL to be a very secure database, hence it can be reliable to be used for banking systems.
PostgreSQL offers tons of authentication methods including a pluggable authentication module (PAM) and lightweight directory access protocol (LDAP), which reduce the attack surface of the servers. It also ensures server-level protection through host-based authentication and certificate authentication.
Furthermore, PostgreSQL provides data encryption and allows you to use SSL certificates when your data transits through the web or public network highways. PostgreSQL also enables you to implement the client certificate authentication (CCA) tools as an option, and use cryptogenic functions to store encrypted data in PostgreSQL.
However, PostgreSQL’s level of security may differ from one cloud system to another, even if it’s the same database.
MongoDB Atlas performs the same way across the three biggest cloud providers, making migration between multiple clouds easier.
Additionally, MongoDB has client-side and field-level encryption, which enables users to encrypt data before sending it to the database via the network. However, as data is stored in key-value pairs in one record, it lacks the security boasted by PostgreSQL; MongoDB’s main focus remains on speed.
Support & Community
PostgreSQL is completely open-source and supported by its community, which strengthens it as a complete ecosystem. PostgreSQL frequently releases updated versions regularly, and developers, enthusiasts, or third-party companies provide support and try to develop the system by fixing bugs or making slight modifications to the database system.
Like PostgreSQL, MongoDB also has a community forum that enables users to connect with several other users and get their general queries answered. The MongoDB enterprise support can further include an extensive knowledge base with use cases, detailed tutorials, technical notes on optimizations, and best practices.
Additionally, there are online courses with training and certifications provided by MongoDB, for free.
Challenges
While we’ve discussed the features of both MongoDB and PostgreSQL that make them a hit with the developers, they do have their fair share of weaknesses as well.
MongoDB tends to focus on fast data operation but lacks the data security that PostgreSQL seems to possess. It’s quite tasking on the memory, as the denormalization process usually results in high memory consumption.
Additionally, as there’s no support for joins, MongoDB databases are oversupplied with data — sometimes duplicate — hence heavily burdening the memory. MongoDB has also tried to include interpretation into other query languages as part of its extensibility; however, it may slow down its performance as the database wasn’t initially built to deal with relational data models.
The translation of SQL to MongoDB queries may take additional time to use the engine which could delay the deployment and development.
On the other hand, while PostgreSQL is easy to install and is adaptable to almost all platforms, its efficiency may differ from platform to platform. Moreover, it doesn’t have revising tools or reporting instruments that could show the current condition of the database. You may have to check the database continuously if something doesn’t go as planned to avoid noticing a failure when it’s too late.
PostgreSQL is also a little slower as it focuses on compatibility. Though efforts have been made to improve PostgreSQL’s speed, the modifications still need a little more work.
MongoDB vs PostgreSQL: Which Should You Choose?
MongoDB is a non-relational database, while PostgreSQL is a relational database. While NoSQL databases work on storing data in key-value pairs as one record, relational databases store data on different tables.
If you prioritize faster data integration and scalability across several servers, MongoDB might be a suitable choice for your business.
MongoDB can work best when integrated into an analytics platform, as MongoDB’s speed provides dynamic performance that can help track the user’s behavior in real time. It can also be highly beneficial to your business if you happen to own a busy web application that doesn’t depend on a structured schema like New York Times (which does in fact, use MongoDB), or for product catalogs where you’d need to store multiple objects with various attribute collections.
On the other hand, PostgreSQL is a perfect match for data analysis and warehousing. If you’re building a database automation tool or a banking application where you prefer data security and transactional guarantees to be enforced, PostgreSQL could be the right fit.
Summary
To sum up, so far, we’ve covered the basic details of PostgreSQL and MongoDB alike. We’ve discussed their history, key features, and what makes them different.
While both PostgreSQL and MongoDB make amazing databases, it ultimately comes down to choosing what’s right for your business.
Between PostgreSQL and MongoDB, which database do you prefer? Let us know in the comments!


