
For most marketers, constant updates are needed to keep their site fresh and improve their SEO rankings.
However, some sites have hundreds or even thousands of pages, making it a challenge for teams that manually push the updates to search engines. If the content is being updated so frequently, how can teams ensure that these improvements are impacting their SEO rankings?
That’s where crawler bots come into play. A web crawler bot will scrape your sitemap for new updates and index the content into search engines.
In this post, we’ll outline a comprehensive crawler list that covers all the web crawler bots you need to know. Before we dive in, let’s define web crawler bots and show how they function.
Check Out Our Video Guide On The Most Common Web Crawlers
What Is a Web Crawler?
A web crawler is a computer program that automatically scans and systematically reads web pages to index the pages for search engines. Web crawlers are also known as spiders or bots.
For search engines to present up-to-date, relevant web pages to users initiating a search, a crawl from a web crawler bot must occur. This process can sometimes happen automatically (depending on both the crawler’s and your site’s settings), or it can be initiated directly.
Many factors impact your pages’ SEO ranking, including relevancy, backlinks, web hosting, and more. However, none of these matter if your pages aren’t being crawled and indexed by search engines. That is why it is so vital to make sure that your site is allowing the correct crawls to take place and removing any barriers in their way.
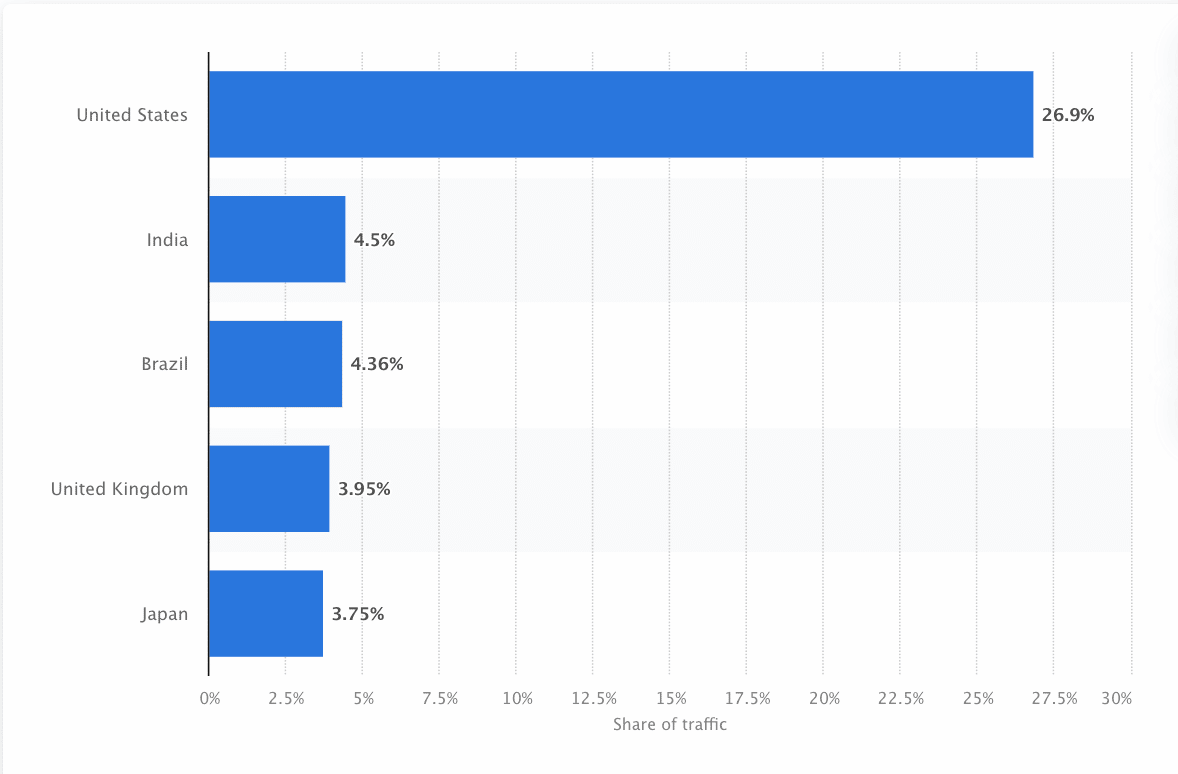
Bots must continually scan and scrape the web to ensure the most accurate information is presented. Google is the most visited website in the United States, and approximately 26.9% of searches come from American users:
However, there isn’t one web crawler that crawls for every search engine. Each search engine has unique strengths, so developers and marketers sometimes compile a “crawler list.” This crawler list helps them identify different crawlers in their site log to accept or block.
Marketers need to assemble a crawler list full of the different web crawlers and understand how they evaluate their site (unlike content scrapers that steal the content) to ensure that they optimize their landing pages correctly for search engines.
How Does a Web Crawler Work?
A web crawler will automatically scan your web page after it is published and index your data.
Web crawlers look for specific keywords associated with the web page and index that information for relevant search engines like Google, Bing, and more.
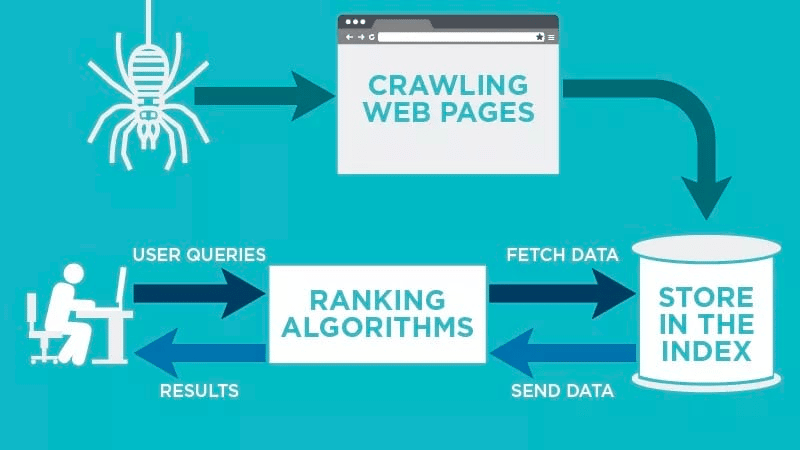
Algorithms for the search engines will fetch that data when a user submits an inquiry for the relevant keyword that is tied to it.
Crawls start with known URLs. These are established web pages with various signals that direct web crawlers to those pages. These signals could be:
- Backlinks: The number of times a site links to it
- Visitors: How much traffic is heading to that page
- Domain Authority: The overall quality of the domain
Then, they store the data in the search engine’s index. As the user initiates a search query, the algorithm will fetch the data from the index, and it will appear on the search engine results page. This process can occur within a few milliseconds, which is why results often appear quickly.
As a webmaster, you can control which bots crawl your site. That’s why it’s important to have a crawler list. It’s the robots.txt protocol that lives within each site’s servers that directs crawlers to new content that needs to be indexed.
Depending on what you input into your robots.txt protocol on each web page, you can tell a crawler to scan or avoid indexing that page in the future.
By understanding what a web crawler looks for in its scan, you can understand how to better position your content for search engines.
Compiling Your Crawler List: What Are the Different Types of Web Crawlers?
As you start to think about compiling your crawler list, there are three main types of crawlers to look for. These include:
- In-house Crawlers: These are crawlers designed by a company’s development team to scan its site. Typically they are used for site auditing and optimization.
- Commercial Crawlers: These are custom-built crawlers like Screaming Frog that companies can use to crawl and efficiently evaluate their content.
- Open-Source Crawlers: These are free-to-use crawlers that are built by a variety of developers and hackers around the world.
It’s important to understand the different types of crawlers that exist so you know which type you need to leverage for your own business goals.
The 14 Most Common Web Crawlers to Add to Your Crawler List
There isn’t one crawler that does all the work for every search engine.
Instead, there are a variety of web crawlers that evaluate your web pages and scan the content for all the search engines available to users around the world.
Let’s look at some of the most common web crawlers today.
1. Googlebot
Googlebot is Google’s generic web crawler that is responsible for crawling sites that will show up on Google’s search engine.

Although there are technically two versions of Googlebot—Googlebot Desktop and Googlebot Smartphone (Mobile)—most experts consider Googlebot one singular crawler.
This is because both follow the same unique product token (known as a user agent token) written in each site’s robots.txt. The Googlebot user agent is simply “Googlebot.”
Googlebot goes to work and typically accesses your site every few seconds (unless you’ve blocked it in your site’s robots.txt). A backup of the scanned pages is saved in a unified database called Google Cache. This enables you to look at old versions of your site.
In addition, Google Search Console is also another tool webmasters use to understand how Googlebot is crawling their site and to optimize their pages for search.
| User Agent | Googlebot |
| Full User Agent String | Mozilla/5.0 (compatible; Googlebot/2.1; +http://www.google.com/bot.html) |
2. Bingbot
Bingbot was created in 2010 by Microsoft to scan and index URLs to ensure that Bing offers relevant, up-to-date search engine results for the platform’s users.
Much like Googlebot, developers or marketers can define in their robots.txt on their site whether or not they approve or deny the agent identifier “bingbot” to scan their site.
In addition, they have the ability to distinguish between mobile-first indexing crawlers and desktop crawlers since Bingbot recently switched to a new agent type. This, along with Bing Webmaster Tools, provides webmasters with greater flexibility to show how their site is discovered and showcased in search results.
| User Agent | Bingbot |
| Full User Agent String | Desktop – Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko; compatible; bingbot/2.0; +https://www.bing.com/bingbot.htm) Chrome/W.X.Y.Z Safari/537.36
Mobile – Mozilla/5.0 (Linux; Android 6.0.1; Nexus 5X Build/MMB29P) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/W.X.Y.Z Mobile Safari/537.36 (compatible; bingbot/2.0; +https://www.bing.com/bingbot.htm) “W.X.Y.Z” will be substituted with the latest Microsoft Edge version Bing is using, for eg. “100.0.4896.127″ |
3. Yandex Bot
Yandex Bot is a crawler specifically for the Russian search engine, Yandex. This is one of the largest and most popular search engines in Russia.

Webmasters can make their site pages accessible to Yandex Bot through their robots.txt file.
In addition, they could also add a Yandex.Metrica tag to specific pages, reindex pages in the Yandex Webmaster or issue an IndexNow protocol, a unique report that points out new, modified, or deactivated pages.
| User Agent | YandexBot |
| Full User Agent String | Mozilla/5.0 (compatible; YandexBot/3.0; +http://yandex.com/bots) |
4. Apple Bot
Apple commissioned the Apple Bot to crawl and index webpages for Apple’s Siri and Spotlight Suggestions.
Apple Bot considers multiple factors when deciding which content to elevate in Siri and Spotlight Suggestions. These factors include user engagement, the relevance of search terms, number/quality of links, location-based signals, and even webpage design.
| User Agent | Applebot |
| Full User Agent String | Mozilla/5.0 (Device; OS_version) AppleWebKit/WebKit_version (KHTML, like Gecko) Version/Safari_version Safari/WebKit_version (Applebot/Applebot_version) |
5. DuckDuck Bot
The DuckDuckBot is the web crawler for DuckDuckGo, which offers “Seamless privacy protection on your web browser.”
Webmasters can use the DuckDuckBot API to see if the DuckDuck Bot has crawled their site. As it crawls, it updates the DuckDuckBot API database with recent IP addresses and user agents.
This helps webmasters identify any imposters or malicious bots trying to be associated with DuckDuck Bot.
| User Agent | DuckDuckBot |
| Full User Agent String | DuckDuckBot/1.0; (+http://duckduckgo.com/duckduckbot.html) |
6. Baidu Spider
Baidu is the leading Chinese search engine, and the Baidu Spider is the site’s sole crawler.

Google is banned in China, so it’s important to enable the Baidu Spider to crawl your site if you want to reach the Chinese market.
To identify the Baidu Spider crawling your site, look for the following user agents: baiduspider, baiduspider-image, baiduspider-video, and more.
If you’re not doing business in China, it may make sense to block the Baidu Spider in your robots.txt script. This will prevent the Baidu Spider from crawling your site, thereby removing any chance of your pages appearing on Baidu’s search engine results pages (SERPs).
| User Agent | Baiduspider |
| Full User Agent String | Mozilla/5.0 (compatible; Baiduspider/2.0; +http://www.baidu.com/search/spider.html) |
7. Sogou Spider
Sogou is a Chinese search engine that is reportedly the first search engine with 10 billion Chinese pages indexed.

If you’re doing business in the Chinese market, this is another popular search engine crawler you need to know about. The Sogou Spider follows the robot’s exclusion text and crawl delay parameters.
As with the Baidu Spider, if you don’t want to do business in the Chinese market, you should disable this spider to prevent slow site load times.
| User Agent | Sogou Pic Spider/3.0( http://www.sogou.com/docs/help/webmasters.htm#07) Sogou head spider/3.0( http://www.sogou.com/docs/help/webmasters.htm#07) Sogou web spider/4.0(+http://www.sogou.com/docs/help/webmasters.htm#07) Sogou Orion spider/3.0( http://www.sogou.com/docs/help/webmasters.htm#07) Sogou-Test-Spider/4.0 (compatible; MSIE 5.5; Windows 98) |
8. Facebook External Hit
Facebook External Hit, otherwise known as the Facebook Crawler, crawls the HTML of an app or website shared on Facebook.

This enables the social platform to generate a sharable preview of each link posted on the platform. The title, description, and thumbnail image appear thanks to the crawler.
If the crawl isn’t executed within seconds, Facebook will not show the content in the custom snippet generated before sharing.
| User Agent | facebot facebookexternalhit/1.0 (+http://www.facebook.com/externalhit_uatext.php) facebookexternalhit/1.1 (+http://www.facebook.com/externalhit_uatext.php) |
9. Exabot
Exalead is a software company created in 2000 and headquartered in Paris, France. The company provides search platforms for consumer and enterprise clients.
Exabot is the crawler for their core search engine built on their CloudView product.
Like most search engines, Exalead factors in both backlinking and the content on web pages when ranking. Exabot is the user agent of Exalead’s robot. The robot creates a “main index” which compiles the results that the search engine users will see.
| User Agent | Mozilla/5.0 (compatible; Konqueror/3.5; Linux) KHTML/3.5.5 (like Gecko) (Exabot-Thumbnails) Mozilla/5.0 (compatible; Exabot/3.0; +http://www.exabot.com/go/robot) |
10. Swiftbot
Swiftype is a custom search engine for your website. It combines “the best search technology, algorithms, content ingestion framework, clients, and analytics tools.”
If you have a complex site with many pages, Swiftype offers a useful interface to catalog and index all your pages for you.
Swiftbot is Swiftype’s web crawler. However, unlike other bots, Swiftbot only crawls sites that their customers request.
| User Agent | Swiftbot |
| Full User Agent String | Mozilla/5.0 (compatible; Swiftbot/1.0; UID/54e1c2ebd3b687d3c8000018; +http://swiftype.com/swiftbot) |
11. Slurp Bot
Slurp Bot is the Yahoo search robot that crawls and indexes pages for Yahoo.
This crawl is essential for both Yahoo.com as well as its partner sites including Yahoo News, Yahoo Finance, and Yahoo Sports. Without it, relevant site listings wouldn’t appear.
The indexed content contributes to a more personalized web experience for users with more relevant results.
| User Agent | Slurp |
| Full User Agent String | Mozilla/5.0 (compatible; Yahoo! Slurp; http://help.yahoo.com/help/us/ysearch/slurp) |
12. CCBot

CCBot is a Nutch-based web crawler developed by Common Crawl, a non-profit organization focused on providing (at no cost) a copy of the internet to businesses, individuals, and anyone interested in online research. The bot uses MapReduce, a programming framework that allows it to condense large volumes of data into valuable aggregate results.
Thanks to CCBot, people can use Common Crawl’s data to improve language translation software and predict trends. As a matter of fact, GPT-3 was trained largely on the data from their dataset.
| User Agent | CCBot/2.0 (https://commoncrawl.org/faq/) CCBot/2.0 CCBot/2.0 (http://commoncrawl.org/faq/) |
13. GoogleOther
This is a fresh one. GoogleOther was launched by Google in April 2023 and it works just like Googlebot.
They both share the same infrastructure and have the same features and limitations. The only difference is that GoogleOther will be used internally by Google teams to crawl publicly accessible content from sites.
The reason behind the creation of this new crawler is to take some strain off of Googlebot’s crawl capacity and optimize its web crawling processes.
GoogleOther will be used, for example, for research and development (R&D) crawls, allowing Googlebot to focus on tasks directly related to search indexing.
| User Agent | GoogleOther |
14. Google-InspectionTool
People looking at the crawling and bot activity in their log files are going to stumble upon something new.
A month after the launch of GoogleOther, we have a new crawler among us that also mimics Googlebot: Google-InspectionTool.
This crawler is used by Search testing tools in Search Console, like URL inspection, and other Google properties, such as the Rich Result Test.
| User Agent | Google-InspectionTool Googlebot |
| Full User Agent String | Mozilla/5.0 (Linux; Android 6.0.1; Nexus 5X Build/MMB29P) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/W.X.Y.Z Mobile Safari/537.36 (compatible; Google-InspectionTool/1.0) Mozilla/5.0 (compatible; Google-InspectionTool/1.0) |
The 8 Commercial Crawlers SEO Professionals Need to Know
Now that you have 14 of the most popular bots on your crawler list, let’s look at some of the common commercial crawlers and SEO tools for professionals.
1. Ahrefs Bot
The Ahrefs Bot is a web crawler that compiles and indexes the 12 trillion link database that popular SEO software, Ahrefs, offers.
The Ahrefs Bot visits 6 billion websites every day and is considered “the second most active crawler” behind only Googlebot.
Much like other bots, the Ahrefs Bot follows robots.txt functions, as well as allows/disallows rules in each site’s code.
2. Semrush Bot
The Semrush Bot enables Semrush, a leading SEO software, to collect and index site data for its customers’ use on its platform.
The data is used in Semrush’s public backlink search engine, the site audit tool, the backlink audit tool, link building tool, and writing assistant.
It crawls your site by compiling a list of web page URLs, visiting them, and saving certain hyperlinks for future visits.
3. Moz’s Campaign Crawler Rogerbot
Rogerbot is the crawler for the leading SEO site, Moz. This crawler is specifically gathering content for Moz Pro Campaign site audits.

Rogerbot follows all rules set forth in robots.txt files, so you can decide if you want to block/allow Rogerbot from scanning your site.
Webmasters will not be able to search for a static IP address to see which pages Rogerbot has crawled due to its multifaceted approach.
4. Screaming Frog
Screaming Frog is a crawler that SEO professionals use to audit their own site and identify areas of improvement that will impact their search engine rankings.

Once a crawl is initiated, you can review real-time data and identify broken links or improvements that are needed to your page titles, metadata, robots, duplicate content, and more.
In order to configure the crawl parameters, you must purchase a Screaming Frog license.
5. Lumar (formerly Deep Crawl)
Lumar is a “centralized command center for maintaining your site’s technical health.” With this platform, you can initiate a crawl of your site to help you plan your site architecture.
Lumar prides itself as the “fastest website crawler on the market” and boasts that it can crawl up to 450 URLs per second.
6. Majestic
Majestic primarily focuses on tracking and identifying backlinks on URLs.

The company prides itself on having “one of the most comprehensive sources of backlink data on the Internet,” highlighting its historic index which has increased from 5 to 15 years of links in 2021.
The site’s crawler makes all of this data available to the company’s customers.
7. cognitiveSEO
cognitiveSEO is another important SEO software that many professionals use.
The cognitiveSEO crawler enables users to perform comprehensive site audits that will inform their site architecture and overarching SEO strategy.
The bot will crawl all pages and provide “a fully customized set of data” that is unique for the end user. This data set will also have recommendations for the user on how they can improve their site for other crawlers—both to impact rankings and block crawlers that are unnecessary.
8. Oncrawl
Oncrawl is an “industry-leading SEO crawler and log analyzer” for enterprise-level clients.
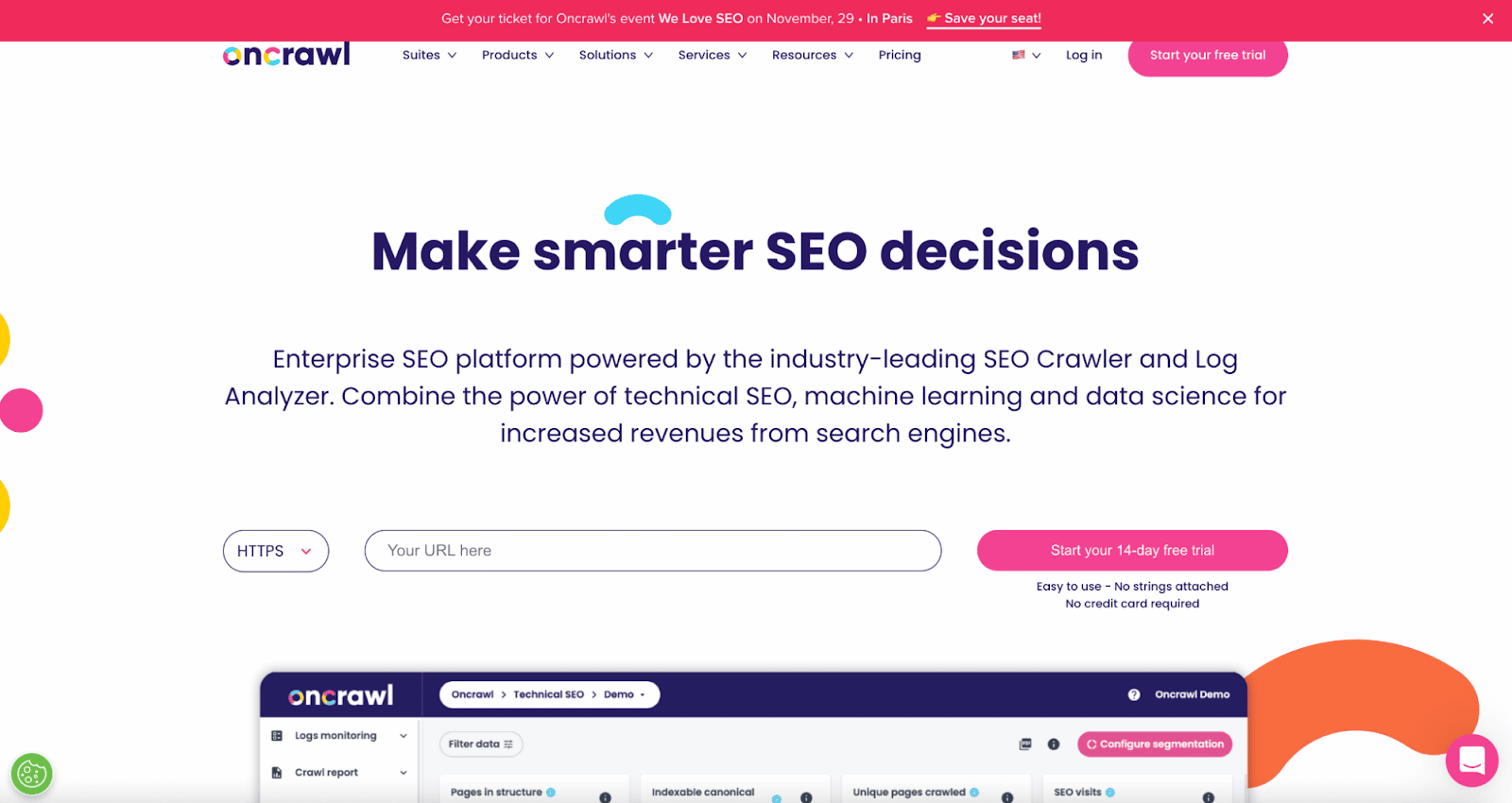
Users can set up “crawl profiles” to create specific parameters for the crawl. You can save these settings (including the starting URL, crawl limits, maximum crawl speed, and more) to easily run the crawl again under the same established parameters.
Do I Need to Protect My Site from Malicious Web Crawlers?
Not all crawlers are good. Some may negatively impact your page speed, while others may try to hack your site or have malicious intentions.
That’s why it’s important to understand how to block crawlers from entering your site.
By establishing a crawler list, you’ll know which crawlers are the good ones to look out for. Then, you can weed through the fishy ones and add them to your block list.
How To Block Malicious Web Crawlers
With your crawler list in hand, you’ll be able to identify which bots you want to approve and which ones you need to block.
The first step is to go through your crawler list and define the user agent and full agent string that is associated with each crawler as well as its specific IP address. These are key identifying factors that are associated with each bot.
With the user agent and IP address, you can match them in your site records through a DNS lookup or IP match. If they do not match exactly, you might have a malicious bot attempting to pose as the actual one.
Then, you can block the imposter by adjusting permissions using your robots.txt site tag.
Summary
Web crawlers are useful for search engines and important for marketers to understand.
Ensuring that your site is crawled correctly by the right crawlers is important to your business’s success. By keeping a crawler list, you can know which ones to watch out for when they appear in your site log.
As you follow the recommendations from commercial crawlers and improve your site’s content and speed, you’ll make it easier for crawlers to access your site and index the right information for search engines and the consumers seeking it.


